一种基于YOLOv2的目标车辆跟踪算法
2018-02-25蔡永华庞智恒王宇宁
徐 乐,蔡永华,庞智恒,王宇宁
(1.武汉理工大学 现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070;2.武汉理工大学 汽车零部件技术湖北省协同创新中心,湖北 武汉 430070;3.武汉理工大学 汽车工程学院,湖北 武汉 430070)
目标跟踪为在一个连续的视频流中自动跟踪感兴趣的目标位置,从而形成目标运动轨迹[1]。目标跟踪广泛应用于智能交通、机器人导航及智能监控等领域[2]。
目标跟踪算法主要分为判别式和生成式两类,判别式跟踪算法采用在线训练的方法将跟踪问题转换为二分类问题,利用机器学习方法区分背景和前景,由于其考虑了背景信息,使得跟踪准确性更高,成为近几年的研究热点[3]。Kalal等[4]提出TLD(tracking learning dection)跟踪算法,引入重检测机制,将检测与跟踪有效地结合起来,实现对单目标的长时跟踪。Hare等[5]为了降低跟踪过程中的累积误差,提出了基于结构化输出预测的自适应跟踪框架,提升了跟踪性能,但该算法对于目标遮挡等情况适应能力差。基于相关滤波跟踪算法,如MOSSE(minimum output sum of squared error filter)[6]、KCF(kernel correlation filter)[7]等,实时性优势大,但对复杂交通场景的目标跟踪鲁棒性差,如车辆、行人跟踪等。
近年来,相关学者将神经网络引入目标跟踪领域,借助传统在线训练跟踪框架完成跟踪任务。然而,在线训练神经网络实时性能差,且未充分利用神经网络在大数据集上的优势,因此,基于深度学习的在线训练跟踪算法很难胜任实际应用[8]。目前,基于深度学习的离线训练目标检测方法已经取得了巨大成功,无论基于两阶段的RCNN(region with CNN)系列[9],还是基于单阶段的SSD(sum of square difference)、YOLO(you only look once)系列[10-11],实时性和准确性上均达到了较高水平。其中Redmon等[12]提出的YOLOv2算法表现最佳,其深层次的特征提取结构提高了图像的特征表达能力,并且使用了基于网格划分生成候选区域的方法。为了解决基于深度学习的在线训练跟踪算法实时性问题,Redmon等[13]提出GOTURN(generic object tracking using regression network)算法,采用离线训练方式大幅度提升了跟踪速度达100 fps,但该算法跟踪精度低。
笔者在GOTURN算法离线训练框架基础上提出了一种基于YOLOv2的车辆跟踪算法YOLOv2-tracker。①采用YOLOv2的网络结构作为跟踪算法的主体结构,用于特征提取与位置预测,将两阶段的跟踪问题简化为单阶段跟踪问题;②采用YOLOv2的网格划分方法,显著改善候选搜索区域的生成质量;③提出掩膜处理方法用于标记跟踪目标,该处理可以保留目标的位置信息,提高跟踪鲁棒性;④针对跟踪过程中存在的误跟踪与跟丢问题,提出加强目标特征信息的方法以解决误跟踪问题,并利用动态保存的方法重新找回目标;⑤针对缺乏大量的车辆跟踪数据集用于离线训练的问题,采集了330组城市交通场景视频制作数据集,用于此跟踪算法的训练及测试。
1 YOLOv2-tracker车辆跟踪算法原理
1.1 GOTURN算法原理
GOTURN算法采用离线训练的方式,学习到目标运动与目标外形之间的通用关系,使得该算法可以跟踪在数据集中没有出现的目标。其算法流程如图1所示。在测试时,首先输入两幅连续的图像,在前一帧裁剪出要跟踪的目标,而当前帧根据前一帧目标的位置确定搜索区域;然后将跟踪目标和搜索区域分别送入两个并行的深度为5的卷积层提取图像特征;最后将卷积层的输出送入深度为3的全连接层,该层的目的是比较跟踪目标和搜索区域的图像特征,进而找到当前帧的跟踪目标。在训练时,利用全连接层输出的预测框和标定框间的L1正则化损失,并使用SGD(stochastic gradient descent)算法训练网络。

图1 GOTURN算法流程
1.2 YOLOv2网络结构及基本原理
(1)YOLOv2网络结构。与GOTURN算法的5层卷积层相比,YOLOv2以Darknet-19作为基础模型,采用了22层卷积层提高了特征提取能力。每层卷积层后都加入批标准化处理。

图2 图像划分网格

图3 n个anchor box
(2)YOLOv2基本原理。如图2所示,YOLOv2将输入图像划分为S×S网格,根据每个网格的中心设定n个不同大小的anchor box,其中,n和anchor box通过对训练集中目标长宽比进行K均值k-means聚类得到,如图3所示。同时,每个anchor box对应5个偏移量(tx,ty,tw,th,to),其中,前4个为4个坐标补偿值,to为检测置信度。每个网格单元的输出神经元个数为n×(1+4+c),c为类别数,如图4所示。然后,对每个建议框利用式(1)进行位置修正:

图4 输出神经元
bw=pwetw,bh=pheth
Pr(object)*IoU(b,object)=σ(to)
(1)
式中:pw、ph为K-均值聚类得到的先验框的宽和高;bx、by、bw、bh为修正后区域建议框的质心坐标及相应的宽和高;σ为sigmiod函数,其作用是限制修正因子的大小;(cx,cy)为每个网格的尺度,Pr(object)表示目标落于网格单元时概率为1,否则为0;IoU(b,object)为区域建议框与标准框的交并比;σ(to)为预测目标的置信值。最后,得到每个区域建议框的位置信息及置信分数,再利用非极大值抑制及置信分数找到最优目标框,作为最终检测结果。
1.3 YOLOv2-tracker跟踪算法原理
笔者采用GOTURN网络结构的搭建思想,并将YOLOv2的网络结构巧妙地融合到笔者的跟踪网络中,提出了YOLOv2-tracker算法。
(1)YOLOv2-tracker算法中的掩膜处理。在训练时,首先标定目标车辆,采用如图5所示的掩膜处理方法,类似于GOTURN算法中的对连续两帧图像进行裁剪的作用。与传统的裁剪方法相比,掩膜处理具有两个优点:①保留了目标物体在
整张图像上的位置信息。②在训练过程和测试过程中,图像中目标车辆的大小会发生改变,但整张图像的大小却可以保持不变,因此便于将图像输入网络进行特征提取。

图5 掩膜处理过程
(2)YOLOv2-tracker算法的单双网络结构。基于Darknet-19网络框架通过修改输入输出层,笔者提出了YOLOv2-tracker算法的单双网络两种结构,双网络类似于GOTURN算法结构,如图6所示。首先对第一帧图像进行掩膜处理以标记跟踪目标。然后将该掩膜图像与第二帧图像分别输入YOLOv2的卷积层进行特征提取,其中,第二帧图像的搜索区域由YOLOv2算法的网格划分方法产生。最后,将卷积层的输出结果输入到YOLOv2输出层,并预测第二帧中跟踪目标的位置,依次规律完成其他帧的预测。而如图7所示的单网络结构,不同于双网络结构,它直接将掩膜图像与第二帧图像叠加形成6通道的输入,之后一起输入YOLOv2卷积网络进行跟踪目标预测。单网络与双网络相比,其网络结构更简单,参数更少,训练和测试耗时更低。
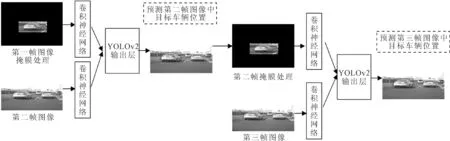
图6 双网络结构方案

图7 单网络结构方案
2 基于特征信息加强和动态保存的优化方案
2.1 基于特征信息加强的误跟优化
如图8所示,由于掩膜处理保存了车辆的位置信息,当网络对位置较为敏感时,即使目标车辆离开视频,网络仍然会在目标车辆离开的附近区域预测车辆,即出现误跟现象。

图8 误跟踪现象
针对此问题,提出一种如图9所示的特征信
息加强的优化方案,即加强网络学习目标车辆特征的能力。在训练过程中,除将连续两帧图像输入网络进行训练,还将取自两个视频组的图像输入网络进行训练产生负样本,即网络输出层中全部的置信度神经元预测值为0。
2.2 基于动态保存的跟丢优化
由于目标快速移动、遮挡等问题,导致缺少当前帧图像中目标车辆的位置信息,使得掩膜处理过程不能连续,最终导致跟丢目标。为了使算法在跟丢目标后能重新找回目标,提出了一种基于动态保存的优化方案。该方案动态保存最新一帧的掩膜处理所得的目标车辆标记图,当目标车辆跟丢时,用已保存的最新目标车辆标记图代替当前帧中失效的掩膜标记图,从而使算法重新找回跟踪目标,实现车辆长时间跟踪。

图9 加强的优化方案特征信息
3 实验结果
实验使用硬件配置为i5处理器、Nvidia Geforece GTX1080显卡及32 G内存的计算机,操作系统为Ubuntu16.04 64位,深度学习框架为Caffe。
3.1 交通场景跟踪数据集建立
跟踪数据集是笔者通过行车记录仪采集的330组交通视频制作而成,将其分为280组训练集,50组测试集。并人工标记每一帧图像中车辆的位置。图10为该数据集的部分数据,其中,方框为人工标记的车辆位置。

图10 部分数据集
为避免算法在训练过程中产生过拟合,通过4种方法扩充数据集。分别为:①光照、对比度及饱和度随机变化;②随机抖动,将掩膜处理的图像随机添加抖动;③在训练过程中对选取的连续两帧图像,随机改变其先后顺序;④随机间隔n帧(n小于10)选取两帧用于训练。
3.2 跟踪算法评价标准
采用OTB数据集[14-15]中的成功率及空间鲁棒性作为评价标准,其中,成功率表示OP(重叠率)大于某个阈值的视频帧数占视频总帧数的百分比;OP为跟踪预测目标框与标定目标框的重叠区域占两者交集的百分比,即:
(2)
式中:rt为第t帧的预测目标框;rlabel为第t帧标定的目标框。
空间鲁棒性方法,主要通过修改起始帧的标签位置完成算法的空间鲁棒性评价。例如,将起始帧中跟踪目标的参考标准框的位置移动10%,或者缩小、放大10%等。同时,实时性也是跟踪算法的一项重要指标,以每秒能处理的图像帧数来表示算法的实时性能。
此外,由于采集的数据集里部分视频中的目标车辆离开视频画面后,视频仍未结束,性能优越的跟踪算法不应该在随后的视频图像中标记出“目标”。因此,需要增加一个额外的评价因子,即当目标离开视频画面后,算法若没有预测出“目标”,则表示当前帧跟踪成功,反之则否。
3.3 双网络与单网络性能比较
(1)网络训练。整个训练过程使用SGD算法学习参数,且除输出层外,所有卷积层都使用批标准化处理,损失函数采用了YOLOv2算法的联合损失函数,其定义为:
lossbikl+losscikl)
(3)
式中:lossaikl为评价置信度神经元损失函数;lossbikl为坐标补偿值神经元损失函数;losscikl为类别神经元组损失函数,它们分别定义为:
lossaikl=λobjΨi(σ(poi)-1)2+
λnoobj(1-Ψi)(σ(poi)-0)2
(4)
lossbikl=λcoorψi[(σ(pxi)+cx-tx)2+
(σ(pyi)+cy-ty)2+
(cwepi-tw)2+(chephi-th)2]
(5)
(6)
式中:n为每个网格的anchor box数;S2为图片划分的网格数;B为小批量大小;Ψi为第i个anchor box,为正时取1,否则取0;poi为第i个anchor box对应的置信度神经元的预测值,λobj、λnoobj、λcoor分别为对应损失的权重值;σ为sigmoid函数;c为anchor box;t为参考标准框,x、y、w、h分别为anchor box的位置信息;m为类别数,即类别神经元组中神经元个数;pcij为类别神经元组中第j个神经元的预测值;tci为类别神经元组中第j类神经元的目标值。
由于仅有目标车辆(单类别)的跟踪,笔者采用与文献[11]和文献[13]相同的训练方法精调网络,具体的训练参数值如表1所示。
YOLOv2-tracker算法使用数据增强后的数据集进行网络训练,其训练结果如图11所示,从图中可知,单、双网络的总损失函数均随着训练次
数的增加而呈现总体下降趋势,最终趋于收敛,说明该网络训练有效,可用于测试。

表1 训练参数设置
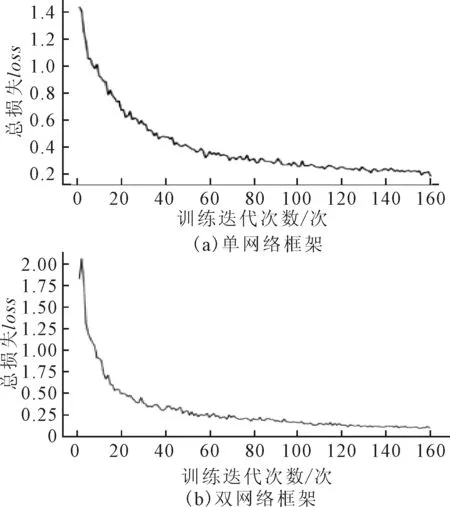
图11 YOLOv2-tracker算法训练结果
(2)网络测试。利用50组测试集进行网络测试,具体评价指标参数为:①重合率的阈值为0.5(记为OP0.5);②空间鲁棒性,即初始帧标签随机平移10%(记为shift10%)和随机缩放10%(记为scale10%);③跟踪速度。测试结果如表2所示。
由表2可知,单网络与双网络的重合率、空间鲁棒性较为接近,而单网络算法的跟踪速度与双网络算法相比优势明显,约达2倍的速度。因而选择单网络作为最终网络框架,其部分跟踪结果如图12所示,从图12中看出,在背景复杂的交通环境中,跟踪算法都能快速地跟踪上目标,且跟踪精度高。

表2 单、双网络测试结果
图12 部分跟踪结果
将本文算法实时性与在线训练算法[3,16,17]对比,结果如表3所示。对比可知该算法实时性远优于一般在线训练算法。这主要因为YOLOv2-tracker算法在有效的数据集上使用了离线训练方法,具备较强的特征提取能力及合理的候选区域生成方法。

表3 实时性对比
3.4 优化前后性能比较
为了测试提出的特征信息加强优化方案的有效性,分别将测试集分为“目标离开”及“目标未离开”两组测试集,并分别使用优化前后的单网络进行测试,测试结果如表4所示。

表4 优化前后单网络测试结果
从表4可知,在“目标离开”组中,经过优化的网络跟踪精度大幅提升,达86.7%,与未优化网络的精度相比,提升了4.7%,与“目标未离开”组的87.5%的跟踪精度很接近。而“目标未离开”组,网络优化前后,跟踪精度相差不大。因此,通过特征信息加强的方法,可以促使网络偏向于学习目标车辆的特征信息,从而减小误跟现象。
此外,使用的动态保存优化方案可以有效地解决目标跟丢问题。如图13所示在第125帧时,跟踪的目标车辆被其他目标遮挡,导致跟踪目标短时跟丢,而由于本文的跟踪算法保留了相邻帧间的上下文掩模图像信息,可有效地找回跟踪目标,因此,在之后的第142帧目标已经被重新跟踪。

图13 车辆跟丢部分结果
4 结论
笔者提出了一种基于YOLOv2的车辆跟踪算法YOLOv2-tracker,在复杂交通场景下跟踪算法准确率可达86%以上。在未来的工作中将继续从以下几方面研究以提高准确率。①进一步扩大实验数据集用于训练更优的模型;②使用车牌等先验知识,将车辆号牌识别技术应用于本研究;③利用颜色信息建立目标与背景区域的颜色直方图,有效地抑制背景干扰,同时颜色直方图忽略每个像素点的位置信息,可以减少目标形变问题;④加入视频帧间的运动信息,如光流等,进一步提高目标的特征表达。
