融合时空多特征表示的无监督视频分割算法
2018-01-08李雪君张开华宋慧慧
李雪君,张开华,宋慧慧
(江苏省大数据分析技术重点实验室(南京信息工程大学), 南京 210044)
融合时空多特征表示的无监督视频分割算法
李雪君,张开华*,宋慧慧
(江苏省大数据分析技术重点实验室(南京信息工程大学), 南京 210044)
针对视频分割的难点在于分割目标的无规则运动、快速变换的背景、目标外观的任意变化与形变等, 提出了一种基于时空多特征表示的无监督视频分割算法,通过融合像素级、超像素级以及显著性三类特征设计由细粒度到粗粒度的稳健特征表示。首先,采用超像素分割对视频序列进行处理以提高运算效率,并设计图割算法进行快速求解;其次,利用光流法对相邻帧信息进行匹配,并通过K-D树算法实现最近邻搜索以引入各超像素的非局部时空颜色特征,从而增强分割的鲁棒性;然后,对采用超像素计算得到的分割结果,设计混合高斯模型进行完善;最后,引入图像的显著性特征,协同超像素分割与混合高斯模型的分割结果,设计投票获得更加准确的视频分割结果。实验结果表明,所提算法是一种稳健且有效的分割算法,其结果优于当前大部分无监督视频分割算法及部分半监督视频分割算法。
超像素分割;K-D树;混合高斯模型;图割算法;光流法
0 引言
视频分割也称运动分割,是指按一定的度量标准把图像序列分割成多个时空一致的区域,从而从视频序列中分离出有意义的目标。图像与视频的分割作为图像处理中非常重要的低层处理技术是图像分析的基础,为高层应用提供重要的数据形式,例如:车辆识别、牌照识别、医学影像分析、人脸识别、目标检测跟踪和识别等。在所有这些应用中,分割通常是为了进一步对图像视频进行分析识别,其准确性直接影响后续任务的有效性。由于视频数据量大且存在较多的冗余信息, 同时视频内容复杂多变且有噪声及光照的变化等因素的干扰,容易造成目标分割的失败,导致目前存在的目标分割算法的准确率普遍不高, 因此,研究并实现一种准确的目标分割算法具有十分重要的意义。
视频分割不同于图像分割的最主要之处在于运动信息的引入。根据是否需要人工参与指导,视频分割可以分为无监督视频分割[1-2]和半监督视频分割[3-5]。根据所利用信息的不同,可以分为基于时间信息的视频分割[6-8]、基于空间信息的视频分割[9]以及联合时空信息的视频分割[10-11]等。本文提出一种基于融合多特征表观模型的无监督视频分割算法,分割过程中无需用户提供图像的先验信息,仅利用视频序列的颜色、位置等低层物理特性以及运动特征进行信息处理,自动地将目标与背景分割开来。分割过程中设计多层次图模型,利用超像素分割降低计算复杂度,并进一步设计高斯混合模型并融合显著性特征对分割结果进行细化。从实验结果来看,这种分割算法有良好的稳健性,其分割准确度高于大部分有代表性的视频目标分割算法。
1 预处理及初始化信息的选择
本文所提算法的具体实现流程如图1所示。在具体算法实施之前,首先需要对输入的视频序列作预处理以降低计算复杂度,并初始化图模型的输入信息。

图1 算法流程Fig. 1 Flow chart of the proposed method
光流法[12]通常被用于视频分割,它与运动检测以及运动估计紧密相关,利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来寻找上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息。由于目标位置、大小及运动方向的不确定性,光流法很难得到一个准确的目标位置;特别是对于快速运动的目标,光流法所得到的计算结果往往会有着较大的偏差。然而对于无监督视频分割,由于用户没有提供任何有效的先验信息,为了取得充分的初始化输入信息,利用光流法来判断运动目标的大致位置依然是当前最有效的方法之一。因此本文采取光流结合内外映射图[2]的方法获取分割目标的初始化位置。
为了降低运算复杂度,对于输入的视频序列,对所有帧首先利用Turbopixel算法[13]进行超像素分割。超像素是指由图像中具有相似的颜色、纹理、亮度等属性的相邻像素点构成的集合。超像素分割是计算机视觉领域常用的预处理手段,即利用像素之间的相似性对图像的各像素点进行聚类,可以有效降低图像数据的维度,进而降低图像处理的复杂度。
综合光流得出的大致运动目标范围和超像素分割结果,对分割得到的每个超像素进行初始化赋值:对于判定为前景范围的超像素,将其标记值赋为1,同样,对于判定为背景范围的超像素,其标记值赋为0,于是,可以得到初始化的前景与背景超像素的输入信息作为图模型的初始化输入。虽然利用光流法估计的超像素前后景标记可能存在较大的误差,但是可以保证运动目标基本涵盖于所判定的前景范围之中。在接下来的算法中,各超像素的特征值信息提取将作进一步优化。
2 本文提出的无监督视频分割算法
对输入的视频序列,本文提出的分割算法主要分为3个部分:超像素等级的视频分割、像素等级的视频分割和利用显著性特征对分割结果进行完善。
超像素分割部分着重研究了联合时空信息的特征值的选取。首先利用光流判断出运动目标的大致位置,初始化每个超像素的前后景标记,对于每个超像素,分别选取其颜色特征和位置特征,构成描述该超像素的特征向量。颜色特征的选取上,采用了RGB(Red, Green, Blue)和HSV(Hue, Saturation, Value)两种颜色特征量,并对其进行非局部特征值重构,利用K-D树搜索获取目标超像素所在帧之前多帧内的多个最近邻超像素,并按比例重构目标超像素的特征向量值,以此提高特征量的鲁棒性。利用重构后的特征值表示各超像素,并以此建立图模型,利用图割算法[14]获得超像素等级的分割结果。
像素等级的分割部分主要运用已有的超像素分割结果作为输入,训练混合高斯模型的各个参数,并利用训练完成的混合高斯模型重新对输入视频图像进行分割,得到新的像素等级的目标分割结果,利用像素点分割较为细致的特点弥补超像素分割边界粗糙的不足。
显著性特征的引入使得超像素分割的结果和像素点分割的结果联合使用提供了可能。利用显著性特征映射图得到一个鲁棒的分割结果,再通过投票的方式选取最终的分割结果,三选二的方案有效去除了像素点分割所产生的噪点,且运算效率极高。
3 超像素特征选取及目标分割
3.1 联合时空信息的超像素特征选取
近年来,不少学者对视频分割算法作出了一些全局性的优化改进,不少方案也考虑了非局部图像信息,即将非邻接区域的超像素特征纳入考虑范围,但大部分方案仅仅考虑了空间上的全局信息,而没有将时间的全局性信息也作为优化条件[15]。本算法所提出的超像素特征值选取方案同时考虑了时间、空间的全局性信息,利用长期的信息传递对所提取的特征值进行处理,以提高分割的鲁棒性。
对输入视频序列中的第t帧,选取该帧之前的F帧(t≤5时,F=t-1;t>5时,F=5)及当前帧内的所有超像素构成数据集S,每个超像素表示为一个8维特征向量,分别为颜色特征量R、G、B、H、S、V和位置特征量x、y。对于该帧中的第n个超像素,利用K-D树算法[16],在数据集S内进行最近邻搜索,寻找出与该超像素最近似的F个超像素,并利用搜寻得到的最近邻超像素对远距离范围的超像素特征进行优化,以增强原来超像素特征的鲁棒性。

(1)
权重ωi与搜索得到的最近邻超像素与目标超像素的颜色特征值的相似度相关,定义为:
(2)
其中Δd表示两颜色特征向量之间的欧几里得距离。
联合时空超像素特征选取的过程中,每一帧中的每个超像素都将作为目标超像素在该帧之前的F帧内作K-D树搜索,即计算该超像素特征值与之前F帧内所有超像素的欧氏距离,并找出其中距离最近的F个最近邻超像素,其算法复杂度为O(n2)。
3.2 基于图割方法的分割模型
图割算法近年来在图像分割领域得到了广泛的应用,它是一种基于能量最小化求解最优分割结果的交互式算法,其结果通常为全局最优解。因此在得到各超像素点的优化颜色特征向量之后,本文选择对视频序列建立一个图模型,并利用图割算法进行求解。
图割算法的能量函数由一元势函数和互势函数两部分组成:
(3)

互势函数V由时间平滑项和空间平滑项构成,其中时间平滑项定义为:
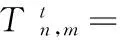
(4)
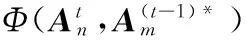
空间平滑项定义为:

(5)

互势函数中,用于表示各超像素颜色特征值的特征向量均为联合时空信息更新后的颜色特征值,位置特征则用各超像素的中心点坐标表示。由于代表示各超像素的颜色特征值较一般情况来说维度更高(六维),且利用了多帧的信息进行重构,因而以其代表各超像素进行计算有效提升了算法的鲁棒性,降低了噪点对分割的影响。
4 高斯混合模型及显著性特征的分割优化
4.1 高斯混合模型优化
在第2章中,本文利用超像素对输入视频序列进行了建模,并利用图割算法求得了目标分割的结果。超像素有效降低了运算复杂度,但同时也注意到,仅仅利用超像素进行视频目标分割仍然存在一些问题,特别是在分割目标的边缘部分,超像素块使目标边界的选取产生了较大的误差。
为了进一步提升分割的准确度,考虑引入混合高斯模型对分割结果进行像素级别的优化。本算法将第3章中所得的超像素级的分割结果作为先验条件输入模型,并对输入图像的颜色和位置特征分别建立混合高斯模型。对于输入图像的颜色特征,利用每个像素点的RGB颜色值构建特征向量,并使用10个分量的高斯混合模型对整体图片进行建模。而对于位置特征,则利用每个像素点的坐标位置以及已有的先验输入信息分别对前景和背景部分进行建模,其中前景部分选取一个高斯分量,背景部分选取4个高斯分量。最后利用期望最大化算法对模型进行求解,得到每个像素点分别属于前景和背景的概率值。选取其中属于前景概率远大于背景的像素点,即可得到一个新的像素点级别的分割结果。
利用混合高斯模型求得的分割结果如图2(b)所示。不难发现,利用混合高斯模型对目标进行分割,可以有效改善目标边缘的分割性能。但是由于混合高斯模型完全基于像素点进行运算,分割结果也不可避免地产生了较多的噪点,因此还需进一步对其进行完善。

图2 对SegTrack中girl第20帧利用投票方式 获得的最终分割结果的过程Fig. 2 Process of obtaining final segmentation results by voting for the 20th frame of video girl in SegTrack set
4.2 显著性特征引入
显著区域是图像中最能引起用户兴趣,并且最能表现图像内容的区域。图像显著性特征提取是一种模仿人类的视觉观察过程来提取人眼感兴趣区域的技术,即通过图像的某些底层特征近似地判断图像中显著区域的过程。此处本文选用文献[17]的显著性检测算法,得出每帧图片的显著性计算结果,如图2(c)所示。
4.3 投票的方式求取最终分割结果
在之前的算法中,已经分别得到了基于超像素的分割结果、基于混合高斯模型的分割结果和基于显著性特征的分割结果,即对于每个像素点,都已有了前景/背景的判别结果。最后,本算法将三者结合,并利用投票的方式融合得到最终的分割结果,其中,混合高斯模型的分割结果可以完善超像素分割结果的边缘,而利用显著性特征的分割结果又能够消除混合高斯模型产生的噪点,从而达到了优势互补的目的。
5 实验结果分析
为了验证本文提出的视频分割算法分割的有效性,在SegTrack测试集上对该算法作出评测。SegTrack测试集是一个常用的用于视频目标分割评测的数据集。该数据集由6个极具挑战性的视频序列(birdfall、cheetah、girl、monkey、parachute、penguin)组成,因penguin针对多目标,本文算法无法使用; 每个视频序列包含21~71帧不等的图片,涵盖了模糊、遮挡、无规则形变、快速运动的目标与复杂背景等多种易对分割结果产生不利影响的情形; 与此同时,该数据集也为其中的每一帧图片提供了准确的人工标注的分割目标结果,便于与算法分割结果比较。
图3分别展示了本文所提算法在测试集序列girl、cheetah、monkey和parachute中得到的分割结果。

图3 本文算法算法对girl,cheetah,monkey,parachute序列的分割结果Fig. 3 Segmentation results obtained by the proposed algorithm to girl,cheetah,monkey,parachute
由图3可以看出,SegTrack数据集所包含的输入视频序列,其分辨率普遍较低。在girl序列中,目标小女孩的手部、脚部以及视频背景均出现了明显的模糊情况,这极大地增加了分割的难度。而在cheetah数据集中,所需分割的运动目标与背景色调基本一致,且相对整个视频画面来说目标所占比例极小,这会导致大部分分割算法特别是没有提供人工标注的无监督视频分割算法无法判定目标位置,或在分割过程中丢失目标。monkey序列中目标运动速度极快,且有着大幅度且无规律的复杂形变。parachute序列则需要应对光线条件差背景复杂等情况。
由所给出的分割结果可以看出,本文所提出的分割算法在大部分情况下取得了不错的分割效果(所展示结果为第一帧到最后一帧等间隔选取的6张图片的分割结果),尤其是在目标边缘位置上,由于像素等级分割结果的引入,弥补了超像素分割边界粗糙的不足,使边缘的分割结果更接近于实际值;由monkey序列可以明显看出,虽然形变复杂且无规律,本文的分割结果基本完全拟合了目标边缘,分割过程中部分遗漏的目标部分也能在后续帧的分割运算中及时完善,达到较理想的分割结果。
另一个表现较突出的序列cheetah从另一个方面展现了本算法的优势。从图中不难看出,在初始几帧中,本方法的分割结果并不准确,由于目标与背景极其相似,且没有初始信息的输入,视频初始的几帧分割遗漏了大部分目标范围;但在接下来的分割过程中,本算法分割效果不断优化,在视频的后半部分中,分割结果基本完整覆盖了运动目标的全部范围。这是因为虽然没有初始值的输入,在后续分割过程中本算法不断引入非局部特征信息,随着信息量的增加,分割的效果也在不断提升。这也显示了本文所提出的无监督分割方案与其他监督学习方案相比的优势,监督学习分割在第一帧往往会提供人工标注的分割结果作为初始化信息,这往往使其在最初的分割过程中取得极佳的分割结果,但随着帧数的增加,初始输入信息逐步弱化,分割的结果也往往随时间的增加而变差。
为了进一步评测本文所提算法的有效性,对该算法进行量化评测,并与当下主要的一些分割算法作出对比。对于视频分割算法的评测,针对不同的数据集,通常采用的评测指标主要分为两类:平均误分割的像素点数(pixel errors)和重叠率(Intersection Over Union, IOU)。对于视频分辨率较高的数据集,每一帧图像所包含的像素点较多,较小的偏差都会导致极大的像素误差产生,因此使用平均误分割的像素点数来评测该类数据集往往会得到极大的数据值,无法有效判断实际的分割效果,因而对于这类数据集,通常选取重叠率作为评测指标。相反,对于分辨率较低的数据集,由于像素点数较少,对于近似但不同的分割结果,其重叠率在数值上将极为接近,同样无法有效评测,此时选用平均误分割的像素点数则会更加直观且准确地反映出分割的效果。
对于SegTrack数据集,该数据集内的所含的视频分辨率普遍较低,同时该数据库也为其中所含视频的每一帧均提供了一个像素点等级的准确人工标注目标范围,因而本文中选取每个序列的平均每帧误分割的像素点个数(average pixel errors per frame)来直观地评测所提出的分割算法有效性。表1显示了本文的分割评测结果以及当前一些有效的视频目标分割算法的分割评测结果(包括监督学习算法和无监督学习算法)。
其中,对比的文献[3,18-20]均为监督学习算法。监督学习算法在第一帧提供了准确的人工标注目标范围作为初始化输入,并利用所提供的目标范围结合光流推算出下一帧的目标大致位置,并利用所给的前后景位置、颜色等特征信息对图片进行建模,从而求得准确的分割结果。与单纯利用光流等运动特征进行目标位置判断的无监督分割方案相比,监督分割的方法往往能取得更好的分割结果。但是,实际运用中,监督分割算法初始化标注的准确度往往会对分割结果产生较大的影响,同时,对每一个输入视频的首帧进行标注处理也较为麻烦,与完全无需人工标注处理的无监督分割算法相比,监督分割算法的实用性较差。

表1 几种算法在SegTrack数据集上的分割评测结果Tab. 1 Segmentation results of several algorithms on SegTrack dataset
注:加粗为所有方案中最好的分割结果,下划线为排名第二的分割结果。
从实验结果来看,本文所提出视频分割算法的效果优于大部分无监督学习算法,在没有首帧标注的情况下取得了与监督学习算法近似的分割结果(值得注意的是,监督分割算法由于首帧给定,在视频的初始几帧中往往能取得极好的分割结果)。尤其是cheetah和monkey序列,虽然输入视频列的分割目标有着严重的模糊和形变,背景环境也较为复杂,本文所提算法依旧取得了较好的分割结果,其中cheetah序列在所有视频目标算法中取得了最好的成绩。与无监督视频分割算法相比,本文算法在分割结果上有着明显的优势。与文献[22]算法相比,本文算法在有视频序列上均有着更优的评测结果,与文献[2,15]算法相比,5个视频序列中有4个取得了更好的成绩,与文献[1]算法相比在3个视频序列上表现更好。
6 结语
本文提出了一种基于融合多特征表示的无监督视频分割算法,该算法利用超像素降低运算复杂度,利用非局部时空信息优化超像素特征值,并利用优化的特征信息对图像进行分割;随后利用已有的分割结果建立混合高斯模型,将利用超像素分割得到的视频分割结果边缘细化,最后引入显著性特征,并利用投票的方式筛选出最终的分割结果。由实验结果可知,该无监督视频分割算法是一种稳健的分割算法,在目标模糊、部分遮挡和目标快速运动的情况下是极其有效的。
References)
[1] YONG J L, KIM J, GRAUMAN K. Key-segments for video object segmentation[C]// Proceedings of the 2011 International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011:1995-2002.
[2] PAPAZOGLOU A, FERRARI V. Fast object segmentation in unconstrained video[C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2013:1777-1784.
[3] WEN L, DU D, LEI Z, et al. JOTS: joint online tracking and segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015:2226-2234.
[4] BROX T, MALIK J. Object segmentation by long term analysis of point trajectories[C]// Proceedings of the 11th European Conference on Computer Vision. Berlin: Springer-Verlag, 2010: 282-295.
[5] NAGARAGA N S, SCHMIDT F R, BROX T. Video segmentation with just a few strokes[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015:3235-3243.
[6] 于跃龙, 卢焕章. 基于背景构造的视频对象分割技术[J]. 计算机工程与科学, 2006, 28(1): 36-38.(YU Y L, LU H Z. Video object segmentation technology based on background construction[J]. Computer Engineering and Science, 2006, 28(1):36-38.)
[7] CULIBRK D, MARQUES O, SOCEK D, et al. Neural network approach to background modeling for video object segmentation[J]. IEEE Transactions on Neural Networks, 2007, 18(6):1614-1627.
[8] 纪腾飞,王世刚,周茜,等. 基于动静背景下的视频对象自适应提取算法[J].吉林大学学报(信息科学版), 2007, 25(1):73-77.( JI T F, WANG S G, ZHOU Q, et al. Adaptive algorithm of video object segmentation under moving and static background[J]. Journal of Jilin University (Information Science Edition), 2007, 25(1):73-77.)
[9] 马丽红, 张宇, 邓健平. 基于形态开闭滤波二值标记和纹理特征合并的分水岭算法[J]. 中国图象图形学报, 2003, 8(1):80-86.(MA L H, ZHANG Y, DENG J P. A target segmentation algorithm based on opening closing binary marker on watersheds and texture merging[J]. Journal of Image and Graphics, 2003, 8(1):80-86.)
[10] CHOI J G, LEE S W, KIM S D. Spatio-temporal video segmentation using a joint similarity measure[J]. IEEE Transactions on Circuits and Systems for Video Technology, 1997, 7(2): 279-286.
[11] 黄波, 杨勇, 王桥,等. 一种基于时空联合的视频分割算法[J]. 电子学报, 2001, 29(11):1491-1494.(HUANG B, YANG Y,WANG Q, et al. Video segmentation based on spatio-temporal information[J]. Acta Electronica Sinica, 2001, 29(11):1491-1494.)
[12] 维基百科. 光流法[EB/OL].[2017- 05- 01].http://zh.wikipedia.org/wiki/%E5%85%89%E6%B5%81%E6%B3%95.(Wikipedia. Optical Flow Method[EB/OL].[2017- 05- 01].http://zh.wikipedia.org/wiki/%E5%85%89%E6%B5%81%E6%B3%95.
[13] LEVINSHTEIN A, STERE A, KUTULAKOS K N, et al. TurboPixels: fast superpixels using geometric flows[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12):2290-2297.
[14] BOYKOV Y, VEKSLER O, ZABIH R. Fast approximate energy minimization via graph cuts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(11): 1222-1239.
[15] LI F, KIM T, HUMAYUN A, et al. Video segmentation by tracking many figure-ground segments[C]// Proceedings of the 2014 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2014:2192-2199.
[16] VEDALDI A, FULKERSON B. Vlfeat: an open and portable library of computer vision algorithms[C]// Proceedings of the 18th ACM International Conference on Multimedia. New York: ACM, 2010:1469-1472.
[17] GOFERMAN S, ZELINKMANOR L, TAL A. Context-aware saliency detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2012, 34(10):1915-1926.
[18] TSAI D, FLAGG M, NAKAZAWA A, et al. Motion coherent tracking using multi-label MRF optimization[J]. International Journal of Computer Vision, 2012, 100(2): 190-202.
[19] CAIZ, WEN L, LEI Z, et al. Robust deformable and occluded object tracking with dynamic graph[J]. IEEE Transactions on Image Processing, 2014, 23(12): 5497.
[20] JAIN S D, GRAUMAN K. Supervoxel-consistent foreground propagation in video[C]// Proceedings of the 13th European Conference on Computer Vision. Berlin: Springer, 2014:656-671.
[21] OCHS P, BROX T. Higher order motion models and spectral clustering[C]// Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012:614-621.
This work is partially supported by the National Natural Science Foundation of China (61402233, 41501377), the Natural Science Foundation of Jiangsu Province (BK20151529,BK20150906).
LIXuejun, born in 1993, M. S. candidate. Her research interests include video segmentation.
ZHANGKaihua, born in 1983, Ph. D., professor. His research interests include object tracking, level set based image segmentation.
SONGHuihui, born in 1986, Ph. D., professor. Her research interests include remote sensing image processing.
Unsupervisedvideosegmentationbyfusingmultiplespatio-temporalfeaturerepresentations
LI Xuejun, ZHANG Kaihua*, SONG Huihui
(JiangsuKeyLaboratoryofBigDataAnalysisTechnology(NanjingUniversityofInformationScienceandTechnology),NanjingJiangsu210044,China)
Due to random movement of the segmented target, rapid change of background, arbitrary variation and shape deformation of object appearance, in this paper, a new unsupervised video segmentation algorithm based on multiple spatial-temporal feature representations was presented. By combination of salient features and other features obtained from pixels and superpixels, a coarse-to-fine-grained robust feature representation was designed to represent each frame in a video sequence. Firstly, a set of superpixels was generated to represent foreground and background in order to improve computational efficiency and get segmentation results by graph-cut algorithm. Then, the optical flow method was used to propagate information between adjacent frames, and the appearance of each superpixel was updated by its non-local sptatial-temporal features generated by nearest neighbor searching method with efficient K-Dimensional tree (K-D tree) algorithm, so as to improve robustness of segmentation. After that, for segmentation results generated in superpixel-level, a new Gaussian mixture model based on pixels was constructed to achieve pixel-level refinement. Finally, the significant feature of image was introduced, as well as segmentation results generated by graph-cut and Gaussian mixture model, to obtain more accurate segmentation results by voting scheme. The experimental results show that the proposed algorithm is a robust and effective segmentation algorithm, which is superior to most unsupervised video segmentation algorithms and some semi-supervised video segmentation algorithms.
superpixel segmentation; K-Dimensional tree (K-D tree); Gaussian Mixture Model (GMM); graph-cut algorithm; optical flow method
2017- 05- 16;
2017- 05- 31。
国家自然科学基金资助项目(61402233, 41501377);江苏省自然科学基金资助项目(BK20151529,BK20150906)。
李雪君(1993—),女,江苏南京人,硕士研究生,主要研究方向:视频分割; 张开华(1983—),男,山东日照人,教授,博士,CCF会员,主要研究方向:目标跟踪、水平集图像分割; 宋慧慧(1986—),女,山东聊城人,教授,博士,主要研究方向:遥感影像处理。
1001- 9081(2017)11- 3134- 05
10.11772/j.issn.1001- 9081.2017.11.3134
(*通信作者电子邮箱zhkhua@gmail.com)
TP312
A
