大规模社交网络中高效的关键用户选取方法
2018-01-08郑永广尹子都张学杰
郑永广,岳 昆,尹子都,张学杰
(云南大学 信息学院,昆明 650500)
大规模社交网络中高效的关键用户选取方法
郑永广,岳 昆*,尹子都,张学杰
(云南大学 信息学院,昆明 650500)
针对大规模社交网络及其用户发布消息的历史数据,如何快速有效地选取具有较强信息传播能力的关键用户,提出了一种关键用户选取方法。首先,利用社交网络的结构信息,构建以用户为节点的有向图,利用用户发布消息的历史数据,基于Spark计算框架,定量计算由用户活跃度、转发交互度和信息量占比刻画的权重,从而构建社交网络的有向带权图模型; 然后,借鉴PageRank算法,建立用户信息传播能力的度量机制,给出基于Spark的大规模社交网络中用户信息传播能力的计算方法; 进而,给出基于Spark的d-距选取算法,通过多次迭代,使得所选取的不同关键用户的信息传播范围尽量少地重叠。建立在新浪微博数据上的实验结果表明,所提方法具有高效性、可行性和可扩展性,对于控制不良突发信息传播、社交网络舆情监控具有一定的支撑作用。
大规模社交网络;信息传播能力;关键用户;PageRank;Spark
0 引言
随着在线社交网络的迅速发展及移动智能终端的迅速普及,社交网络中信息的传播对于国家和社会的影响日益深入,既给信息的传递和社交活动带来了便利,也可能构成影响社会稳定的隐患[1],例如,在2011年爆发的“埃及革命”中,不法分子利用Twitter和Facebook等社交网络使得骚乱极度放大[2]。以国内新浪微博社交网络为例,目前的注册用户已超过5亿,每天有超过1亿条微博内容产生[3],对于如此大规模社交网络中的信息传播,如何快速、及时地发现当前社会热点事件或不良社会思潮,具有重要意义[4]。
由于在线社交网络是典型的小世界网络,具有较短的平均路径长度和较高的聚类系数[5],社交网络的小世界现象和级联式传播方式具有很强的放大作用[6],因此某种信息在社交网络上的某个节点或多个节点传播,极有可能引起很大的社会影响。识别网络中最有影响的传播者、选取具有较强信息传播能力的关键用户,对于确保信息有效传播[7]、信息传播控制和舆情监控具有重要意义[8]。针对大规模社交网络,信息传播数量大,关键用户的选取也具有相当的挑战。
对此,本文综合考虑以用户作为节点的大规模社交网络的有向图结构信息,以及用户发布消息的历史数据,重点考虑影响用户信息传播能力的因素,研究用于快速有效地选取大规模社交网络中关键用户的方法,为突发信息传播控制和社交网络舆情监控等问题提供支撑技术。
近年来,研究人员针对社交网络中关键节点发现问题,从不同的角度提出了不同的方法。早期的社交网络关键节点计算,以Kempe等[9]提出的贪心算法为代表,由于算法时间复杂度较高,随后出现了各种改进的贪心算法和启发式算法,如CELF(Cost-Effective Lazy Forward selection)[10]和DegreeDiscount[11]算法,这些算法面对大规模社交网络时效率仍然较低,并且这些算法主要考虑社交网络结构,而用户信息传播能力的定量度量机制,仍有待进一步研究。
从社交网络用户影响力度量的角度,研究人员提出了意见领袖发现或识别方法。例如: 文献[12]从热门消息传播趋势预测的角度,提出基于消息传播的微博意见领袖影响力建模与测量分析方法;文献[13]基于微博文本数据分析,从结构、行为和情感三个维度度量用户影响力,从而识别意见领袖。针对大规模社交网络的意见领袖影响力建模技术,仍有待进一步研究;同时,针对社交网络中突发事件和不良突发信息检测等问题,发现具有较强信息传播能力的关键用户,与意见领袖识别具有同样重要的意义。
从社交网络中用户关系建模角度,文献[14]以贝叶斯网作为社交网络中用户之间依赖关系表示和推演的知识模型,利用模型的结构特征和贝叶斯网的概率推理机制,提出了用于关键用户发现的MapReduce算法,但仅考虑了网络结构信息。文献[15]考虑用户交互影响及其动态衰减,提出基于霍克斯过程的社交网络中用户关系强度模型及预测方法,但对于支持社交网络中突发事件检测的用户信息传播能力度量,还需进一步研究,并且针对大规模社交网络的建模和度量方法的效率仍需进一步提升。
因此,为了在大规模社交网络中快速有效地选取关键用户,本文的研究面临以下三方面的挑战和问题:1)大规模社交网络的高效计算;2)用户信息传播能力的有效度量;3)关键用户的有效选取。
Spark是一个面向分布式海量数据分析、基于内存的迭代计算通用框架[16],其GraphX工具可以高效地执行大规模图的操作算法[17],因此,针对问题1),本文使用Spark作为数据处理框架,设计基于Spark的大规模社交网络计算与处理算法。
PageRank[18]算法的核心思想是,每个节点的PageRank值,简称PR值,取决于所有指向它的节点的PR值,且平均分配给它所指向的节点。然而,在社交网络中,用户(即节点)的信息未必总是平均地传播到它所指向的用户,用户之间相互关系的强度(例如不同用户之间消息转发频度),即节点之间边上的权重,对信息传播也具有重要的影响。因此,针对问题2),首先基于用户发布消息的历史数据构建带权的社交网络模型,然后借鉴PageRank算法并对其进行扩展,从而有效地度量用户节点的信息传播能力。
针对问题3),为了使选取的用户可以有效地用于检测社交网络中的突发信息或舆情监控,本文提出了d-距选取算法,其核心思想是通过多次迭代使得所选取用户之间的最短路径长度大于参数d,使得所选取的关键用户的信息传播范围尽量少地重叠。
总的来说,本文的主要工作概括如下:
1)利用社交网络的结构信息,构建以用户为节点的有向图,利用用户发布消息的历史数据,基于Spark定量计算由用户活跃度、转发交互度和信息量占比刻画的权重,从而构建社交网络的有向带权图模型。
2)基于大规模的有向带权社交网络模型,通过用户粉丝节点对其信息传播能力贡献值的累加来衡量用户的信息传播能力,借鉴并扩展PageRank算法,给出基于Spark的节点信息传播能力的度量方法。
3)针对突发信息检测和舆情监控等应用中选取关键用户的高效性和有效性需求,给出基于Spark的d-距选取算法,通过多次迭代,快速选取关键用户,且不同关键用户的信息传播范围尽量少地重叠。
4)建立在新浪微博数据集和Spark分布式集群上的实验,测试了本文方法的高效性、可行性和可扩展性。
1 社交网络模型构建
不失一般性,本文用带权有向图G=(V,E)作为社交网络模型[19],其中,V为节点集(|V|=n),节点表示社交网络中的用户;E为有向边的集合,边表示用户之间的关注关系,从vi到vj的有向边上的权重wij表示vi对vj信息传播能力的贡献(1≤i,j≤n,i≠j)。一个包含3个用户的社交网络如图1所示。

图1 带有边上权重的社交网络模型Fig. 1 Social network model with weights on edges
用户发布消息的历史数据中,一条记录的基本信息包含用户、内容、时间及来源,可表示为Item=(vi,c,t,f)。其中:vi表示用户,c表示消息内容,t表示消息发布时间;f用以标识消息的来源,若f=0表示该消息为用户原创,否则表示转自其他用户。基于图1中的社交网络,用户历史消息数据片段如表1所示。

表1 用户历史消息数据片段Tab. 1 Fragments of user historical messages
G中有向边上的权重定量地刻画了存在直接关注关系的用户之间的信息传播关系,是定量度量用户信息传播能力的基础,对此,本文选择与信息扩散和用户相互影响的主要因素作为用户之间权重的度量指标,即用户活跃度、转发交互度、以及信息量占比。进而,可利用用户的历史消息定量地计算上述3个指标的值,从而得到G中边上的权重。
1.1 度量指标定义
1.1.1 用户活跃度
用户活跃度记为a(vi),通过用户在一段时间内所发布信息量d(vi)和转发率r(vi)两个方面来衡量,反映用户对信息传播的活跃情况,如式(1):

(1)
其中:nrp(vi)与np(vi)分别表示用户在这段时间内所转发的信息量、发布的信息量,通过用户历史消息数据统计计算得到;p为时间段长度。
1.1.2 转发交互度
转发交互度记为eij,由用户vi转发vj消息的概率pij和vj对vi的重要程度zij决定,体现用户对于信息转发的交互在其关注节点上的差异,如式(2):

(2)
其中,nrp(vi→vj)表示节点vi转发vj的信息量,通过用户历史消息数据统计计算得到。
1.1.3 信息量占比
若社交网络中节点vi的某段时间所发信息量为np(vi)、其关注为节点vj,则vj发布的信息量在vi所关注节点发布信息总量的占比为hij,如式(3):
(3)
其中fri(vi)表示节点vi所关注节点的集合。
1.2 权重计算
前述3个指标中,用户活跃是信息传播的诱因,信息量占比反映的是用户之间的影响程度,在用户活跃与用户之间有影响的情况下,进而通过转发交互才能向其他用户贡献自己的信息传播能力,因此本文将这3个指标的值相乘来度量节点之间信息传播能力的贡献,即社交网络中边上的权重,vi到vj的有向边上的权重wij由式(4)计算:
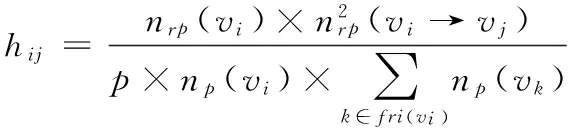
(4)

例1 为了确定图1中社交网络各有向边上的权重,首先对形如表1中的数据片段进行统计计算,得到如表2所示的统计信息,其中,“v2:2”表示来自节点v2的转发量,式(4)中参数p的值为1,则可得到w12、w13、w21和w23的值分别为0.67、0.17、0.67和0.17。

表2 节点统计信息Tab. 2 Statistics of nodes
注:—表示该节点没有对其他节点的信息进行转发。
2 基于信息传播能力的关键用户选取
2.1 节点信息传播能力计算
节点信息传播能力,以定量的方式反映了社交网络模型中某一节点对信息传播的作用,其值为其所有粉丝节点对其信息传播能力贡献值的累加。在此,本文借鉴PageRank算法[18],采用NodeCapacity算法计算节点的信息传播能力,简记为NC,其核心思想是:在社交网络模型中,每个节点的NC值为其所有粉丝节点对其贡献值的累加,每个节点的NC值以边上权重的形式贡献给它关注的节点,如式(5)所示:
(5)
其中:nci表示节点vi的信息传播能力;foll(vi)表示关注节点vi的节点集;wji表示节点vj对vi信息传播能力的贡献权重;q为阻尼系数,q∈(0, 1)。
针对大规模的带权社交网络,本文首先使用Spark中用于图操作的aggregateMessage方法,将各节点其粉丝节点的NC值以边上的权重汇聚并作为其NC值,然后基于图操作joinVertices方法将汇聚后的值更新为相应节点的NC值,依此进行多次迭代操作,上述思想由算法1给出。
算法1 NodeCapacity。
输入G为带权社交网络图,N为给定的迭代次数阈值。
输出NG为带有节点NC值的社交网络图。
1)
varg←G
2)
variteration← 0
3)
varpG: Graph[Double, Double] ← null
/*用于释放缓存的图RDD*/
4)
WHILEiteration 5) g.cache() /*缓存图RDD*/ 6) varupdates←g.aggregateMessage[Double](ctx=> ctx.sendToDst(ctx.srcAttr *ctx.attr), _ + _, TripletFields.Src) /*汇聚其粉丝节点的贡献值*/ 7) pG←g 8) g← g.joinVertices(updates) { (id,oldAr,msgSum) => (1.0-q) +q*msgSum} /*更新图节点中的NC值*/ 9) pG.unpersist(false) /*释放图RDD*/ 10) iteration←iteration+1 11) END WHILE 12) NG←g 算法1的执行代价主要取决于步骤6)和8)中的图操作,其执行代价取决于社交网络中节点及其粉丝节点数,时间复杂度为O(mn),因此,算法1的时间复杂度为O(lmn),其中,l为算法迭代次数,m为每个节点的平均粉丝节点数,n为社交网络中所包含的节点数。此外,算法1的收敛性与PageRank算法相同,二者的主要区别仅在于节点对于其关注节点的贡献的分配方式,PageRank算法根据节点的出链数进行平均分配,而算法1按照边上的权重进行分配。 例2 针对图1中的社交网络,假设节点v1、v2和v3的当前NC值分别为nc1、nc2和nc3,算法1的一次迭代操作为:首先由步骤6)得到各节点的汇聚值upNci,若upNc1为nc2*w21、upNc2为nc1*w12、upNc3为nc1*w13+nc2*w23,则由步骤8),用节点的汇聚值更新相应节点的NC值,得到新的NC值,节点v1的NC值为(1.0-q)+q*upNc1。 对于社交网络G=(V,E),本文希望从V中选取关键节点集S,S⊂V,|S|=k,使得S中的节点在G中具有尽量大的信息传播范围,即能够尽量多地影响到其他节点。首先,关键节点应该具有较大的信息传播能力,即具有较大的NC值;其次,不同关键节点的信息传播范围应该尽量少地重叠。若给定节点的信息传播范围阈值d,则节点vi的信息传播范围可用从vi出发经过长度不超过d的路径可到达的节点集来描述。 因此,为了高效地选取关键节点,在选取G中的k个关键节点时,每次选取当前具有最大NC值的节点,然后将该节点及与其之间路径长度不大于d的节点进行标记,不作为待选取的关键节点,从而使得选取的节点之间的路径长度都大于d,经过k次迭代,可高效地选取k个关键节点(即关键用户)。根据社交网络的小世界特性,将d的取值范围设为1~6。 针对大规模社交网络,本文基于Spark实现上述关键用户选取的思想,称为d-距选取算法。首先,向图的reduce操作传入一个比较函数,进而选取出当前具有最大NC值的节点、并将其作为关键节点;然后,将与所选取节点之间路径长度不大于d的所有节点的NC值都置为0;接着,使用图的subgraph操作去除NC值为0的节点,以生成一个新的子图,如此进行多次迭代操作。上述思想见算法2。 算法2d-距选取。 输入G为带有NC值的图G=(V,E)(由算法1得到),k为关键节点个数,d为路径长度。 输出S为关键节点集合。 1) varg←G 2) varS← new ListBuffer[(Long, Double)] /*保存关键节点*/ 3) varpG: Graph[Double, Double] ← null /*用于释放缓存的图RDD*/ 4) def max(a,b) /*定义一个比较函数*/ 5) FORi← 0 TOkDO /*选取k个关键节点*/ 6) vart←g.vertices.reduce((a,b) =>max(a,b)) /*选取具有最大NC值的节点*/ 7) S←S∪{t} /*将选取的节点t添加到S中*/ 8) pG←g 9) FORj← 1 TOdDO 10) g← 将与节点t的最短路径长度小于等于j的所有节点的NC值置为0 11) END FOR 12) g←g.subgraph(vpred=(id,attr)=>attr> 0.0) /*从g中去除NC值为0的节点*/ 13) pG.unpersist(false) 14) END FOR 15) RETURNS /*返回关键节点集*/ 算法2的执行代价主要取决于步骤5)~14)中图操作执行时节点、关注节点及其粉丝节点的数量,步骤6)中图操作的时间复杂度为O(n),步骤9)~11)的时间复杂度为O(dmn),步骤12中图操作的时间复杂度为O(mn),因此,算法2的时间复杂度为O(kdmn)。其中,k为选取的关键节点个数,d为路径长度,m为平均每个节点的粉丝节点数,n为社交网络模型中包含的节点数。 例3 针对图1中的社交网络,若节点v2的NC值为当前最大值,若阈值d为1,算法2执行时的一次循环操作为:首先,由步骤6)选取节点v2,由步骤7)将v2加入到关键节点集S中,然后由步骤8)~11)将节点v2、v1和v3的NC值设为0,由步骤12)去除这些NC值为0的节点,从而以生成一个新的子图,以进行下一次迭代操作。 为了测试本文算法的有效性,在Spark集群环境下实现了本文方法,采用新浪微博数据集进行性能测试。首先从数据堂(http://www.datatang.com/detail/6)下载微博用户关系数据集,从中提取出度数大于10的节点,形成一个社交网络,然后使用网络爬虫技术抓取用户发布的消息数据。数据集包含4 269 813个用户节点,共有69 060 604条反映用户之间关系的边,包括67 432 812条2016年5月的用户消息历史数据集,大小为10.75 GB;集群环境由1个Master节点和10个Worker节点组成,其中Master节点CPU为4核、2.2 GHz主频、32 GB内存,Worker节点CPU为2核、2.2 GHz主频、16 GB 内存。我们首先测试了关键用户选取结果的有效性,然后测试了算法1和算法2的执行时间、加速比和并行效率。 为了测试利用本文方法所选取关键用户的有效性,根据新浪微博舆情系统2016年6月热点舆情报告(http://blog.sina.com.cn/s/blog_ec0961940102wn59.html)中的TOP-10社会热点事件,对所选取关键用户的有效性进行评测,测试指标包括捕捉率(Catch Ratio, CR)和捕捉收益(Catch Profit, CP),其中CR为通过选取的关键用户检测到的突发信息与网络中实际存在的突发信息的比值,CP为通过选取的关键用户对突发信息的检测而可遏制信息量所占比例。这两个评价指标的值越大,说明选取的关键用户的有效性越大。 首先测试关键用户数量k和路径长度阈值d对CR的影响,如图2所示。可以看出,k与d对CR的影响较大;当d为2时,随着关键用户数量k的增加,CR值稳定增大,基于本文的方法选取关键用户的有效性更加显著。 图2 不同路径长度阈值下的CR指标Fig. 2 CR under various route length thresholds 然后将本文中关键用户选取结果与基于PageRank[18]和DegreeDiscount[11]进行关键用户选取的结果进行比较,测试了不同方法的CR和CP,其中将本文方法中路径长度阈值d设置为2。图3给出了关键用户数量为10、20、30、40和50的情况下,本文方法、PageRank及DegreeDiscount算法对CR的影响。可以看出,随着关键用户数量的增加,本文方法的CR明显优于PageRank及DegreeDiscount算法。 图3 不同算法下CR指标比较Fig. 3 CR comparison of various algorithms 进一步测试本文提出的关键用户选取方法对新浪微博社交网络中的真实突发事件检测的CP,如图4所示。事件1~事件6分别为“小学生当街闹分手”“8名江西高中老师为学生出征壮行”“六一妈妈偷鸡腿给生病女儿”“网现史上最强的考研指导”“西安南郊变电站闪爆”及“上海浦东机场T2航站楼发生爆炸”。由图4可以看出,基于本文方法、PageRank及DegreeDiscount算法选取的关键用户检测到的评测事件有所差异,在捕捉到的情况下,各方法的捕捉收益CP基本都在0.75以上,不少情形达到了0.9以上,表明这三种方法选取的关键用户可以较早地检测到评测事件的传播,进而可以对事件的扩散有很好的控制。这说明本文提出的关键用户选取方法,对于用来检测社交网络中的突发事件是有效的。 图4 不同算法下CP指标比较Fig. 4 CP comparison of various algorithms 为了测试算法1和算法2的执行效率,本文将数据集划分为规模为2.2 GB、4.4 GB、6.6 GB、8.8 GB和11 GB的5个数据块,基于这5个数据块构建相应的边数逐渐增加的有向带权社交网络模型,ID分别为1、2、3、4和5,节点数和边数如表3所示。 表3 社交网络模型的节点和边数Tab. 3 Number of nodes and edges in social network models 在Worker数(计算节点)为1、2、4和8的情况下,本文分别在这5个社交网络模型之上,对算法1和算法2的执行时间、加速比和并行效率进行了测试。通过反复测试,将迭代次数阈值设为10,此时节点信息传播能力的计算收敛;将d和k分别设置为2和50。 算法1和算法2基于不同规模的社交网络模型在不同Worker数下的执行时间如图5所示。 图5 算法的执行时间Fig. 5 Execution time of algorithm 可以看出,算法1和算法2的执行时间在同一Worker数量下随着社交网络规模的增大而呈线性增长;社交网络规模一定时,执行时间随着Worker数量的增多而明显减少,说明算法1和算法2在数据规模增大时,可以通过增加Worker数来大幅降低其执行时间,即能有效地处理大规模社交网络。 加速比是算法在1个Worker节点与多个Worker节点情形下执行时间的比值。在不同规模的社交网络上、不同Worker数情形下,算法1和算法2的加速比如图6所示。可以看出,社交网络规模一定时,加速比随着Worker数量的增多而明显增大。当Worker数为2时,加速比均接近1.5;当Worker数为8时,加速比随着社交网络规模的增大而明显增加,说明算法1和算法2具有较好的并行性和可扩展性。 图6 算法的加速比Fig. 6 Speedup of algorithm 并行效率是算法加速比与Worker数的比值。在不同规模的社交网络上、不同Worker数情形下,算法1和算法2的并行效率如图7所示。可以看出,算法1和算法2的并行效率在同一Worker数量下,随着社交网络规模的增大而缓慢增大,在Worker为2时,并行效率增大不明显,主要是因为已达到一个比较大的值,由于社交网络规模划分不均匀而造成并行效率和加速比的抖动,说明算法1和算法2具有较好的并行性,且较适合处理大规模社交网络。 图7 算法的并行效率Fig. 7 Parallel efficiency of algorithm 利用社交网络的结构信息和用户发布消息的历史数据,本文给出了社交网络中用户信息传播能力的定量度量机制,提出了一种高效的大规模社交网络中关键用户的选取方法,并给出了基于Spark的算法实现。在新浪微博社交网络真实数据集上,测试了本文所提出方法的可行性、高效性和可扩展性。本文提出的关键用户选取方法,可作为支撑技术用于解决大规模社交网络中突发信息检测和舆情监控等问题。 然而,本文提出的用户信息传播能力度量和关键用户选取方法,仅考虑用户传播消息的行为而未考虑传播信息的内容,因此可能产生消息主题漂移而选出“伪关键用户”。为了使得选取的关键用户更加准确有效,基于社交网络结构信息,将用户传播消息的行为与用户之间转发交互的内容结合起来,可进一步完善关键用户的性质和选取方法。将社交网络的影响最大化及种子节点选择的已有方法用于本文中关键用户的选取,对目前的方法进行改进,是将要开展的工作。 References) [1] ZHAO Z, RESNICK P, MEI Q Z. Enquiring minds: early detection of rumors in social media from enquiry posts[C]// Proceedings of the 24th International Conference on World Wide Web. New York: ACM, 2015:1395-1405. [2] 周东浩,韩文报.DiffRank:一种新型社会网络信息传播检测算法[J]. 计算机学报,2014, 37(4):884-893. (ZHOU D H, HAN W B. DiffRank: a novel algorithm for information diffusion detection in social networks[J]. Chinese Journal of Computers, 2014, 37(4):884-893.) [3] 曹玖新,吴江林,石伟,等.新浪微博网信息传播分析与预测[J]. 计算机学报,2014,37(4):779-790. (CAO J X, WU J L, SHI W, et al. Sina microblog information diffusion analysis and prediction[J]. Chinese Journal of Computers, 2014, 37(4):779-790.) [4] BIAN J W, YANG Y, CHUA T S. Predicting trending messages and diffusion participants in microblogging network[C]// Proceedings of the 37th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2014:537-546. [5] 徐恪,张赛,陈昊,等.在线社会网络的测量与分析[J]. 计算机学报,2014,37(1):165-188. (XU K, ZHANG S, CHEN H, et al. Measurement and analysis of online social networks[J]. Chinese Journal of Computers, 2014,37(1):165-188.) [6] 韩毅,许进,方滨兴,等.社交网络的结构支撑理论[J]. 计算机学报,2014,37(4):905-914. (HAN Y, XU J, FANG B X, et al. Structural supportiveness theory on social networks[J]. Chinese Journal of Computers, 2014,37(4):905-914.) [7] GUILLE A, HACID H, FAVRE C, et al. Information diffusion in online social networks: a survey[J]. ACM SIGMOD Record, 2013,42(2):17-28. [8] MAHMOODY A, RIONDATO M, UPFAL E. Wiggins: detecting valuable information in dynamic networks using limited resources [C]// Proceedings of the 9th ACM International Conference on Web Search and Data Mining. New York: ACM, 2016: 677-686. [9] KEMPE D, KLEINBERG J, TARDOS E. Maximizing the spread of influence through a social network [C]// Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2003:137-146. [10] LESKOVEC J, KRAUSE A, GUESTRIN C, et al. Cost-effective outbreak detection in networks[C]// Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2007: 420-429. [11] CHEN W, WANG Y J, YANG S Y. Efficient influence maximization in social networks[C]// Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 199-208. [12] 王晨旭,管晓宏,秦涛,等.微博消息传播中意见领袖影响力建模与应用研究[J]. 软件学报,2015,26(6):1473-1485.(WANG C X, GUAN X H, QIN T, et al. Modeling on opinion leader’s influence in microblog message propagation and its application[J]. Journal of Software, 2015, 26(6):1473-1485.) [13] 曹玖新,陈高君,吴江林,等.基于多维特征分析的社交网络意见领袖挖掘[J]. 电子学报,2016,44(4):898-905. (CAO J X, CHEN G J, WU J L, et al. Multi-feature based opinion leader mining in social networks[J]. Acta Electronica Sinica, 2016, 44(4):898-905.) [14] YUE K, WU H, FU X D, et al. A data-intensive approach for discovering user similarities in social behavioral interactions based on the Bayesian network[J]. Neurocomputing, 2017,219:364-375. [15] 于岩,陈鸿昶,于洪涛.基于霍克斯过程的社交网络用户关系强度模型[J]. 电子学报,2016,44(6):1362-1368.(YU Y, CHEN H C, YU H T. A social networks user relationship strength model based on Hawkes process[J]. Acta Electronica Sinica, 2016, 44(6):1362-1368.) [16] ZAHARIA M. An architecture for fast and general data processing on large clusters[EB/OL].[2016- 11- 20]. http://digitalassets.lib.berkeley.edu/etd/ucb/text/Zaharia_berkeley_0028E_14121.pdf. [17] XIN R S, GONZALEZ J E, FRANKLIN M J, et al. GraphX: a resilient distributed graph system on Spark[C]// Proceedings of the 1st International Workshop on Graph Data Management Experience and Systems. New York: ACM, 2013: Article No. 2. [18] XIE W L, BINDEL D, DEMERS A, et al. Edge-weighted personalized PageRank: breaking a decade-old performance barrier[C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 1325-1334. [19] 吴信东,李毅,李磊.在线社交网络影响力分析[J].计算机学报, 2014,37(4):735-752. (WU X D, LI Y, LI L. Influence analysis of online social networks[J]. Chinese Journal of Computers, 2014,37(4):735-752.) This work is partially supported by the National Natural Science Foundation of China (61472345, 61562090), the Key Program of Natural Science Foundation of Yunnan Province (2014FA023), the Program for the Second Batch of Yunling Scholars of Yunnan Province (C6153001), the Program for Excellent Young Talents of Yunnan University (WX173602), the Research Foundation of Educational Department of Yunnan Province (2016ZZX006, 2016YJS005). ZHENGYongguang, born in 1988, M. S. candidate. His research interests include massive data analysis and services. YUEKun, born in 1979, Ph. D., professor. His research interests include massive data analysis and services. YINZidu, born in 1990, Ph. D. candidate. His research interests include massive data analysis and services. ZHANGXuejie, born in 1965, Ph. D., professor. His research interests include distributed computing. Efficientapproachforselectingkeyusersinlarge-scalesocialnetworks ZHENG Yongguang, YUE Kun*, YIN Zidu, ZHANG Xuejie (SchoolofInformationScienceandEngineering,YunnanUniversity,KunmingYunnan650500,China) To select key users with great information dissemination capability efficiently and effectively from large-scale social networks and corresponding historical user massages, an approach for selecting key users was proposed. Firstly, the structure information of the social network was used to construct the directed graph with the user as the node. Based on the Spark calculation framework, the weights of user activity, transmission interaction and information quantity were quantitatively calculated by the historical data of the message, so as to construct a dynamic weighted graph model of social networks. Then, the measurement for user’s information dissemination capacity was established based on PageRank and the Spark-based algorithm was given correspondingly for large-scale social networks. Further more, the algorithm ford-distance selection of key users was given to make the overlap of information dissemination ranges of different key users be as less as possible by multiple iterations. The experimental results based on Sina Weibo datasets show that the proposed approach is efficient, feasible and scalable, and can provide underlying techniques to control the spread of bad news and monitor public opinions to a certain extent. large-scale social network; information dissemination capacity; key user; PageRank; Spark 2017- 05- 16; 2017- 06- 05。 国家自然科学基金资助项目(61472345, 61562090); 云南省应用基础研究计划重点项目(2014FA023); 第二批“云岭学者”培养项目(C6153001); 云南大学青年英才培养计划项目(WX173602); 云南省教育厅科研基金资助项目(2016ZZX006, 2016YJS005)。 郑永广(1988—),男,河北邢台人,硕士研究生,主要研究方向:海量数据分析与服务; 岳昆(1979—),男,云南曲靖人,教授,博士生导师,博士,CCF高级会员,主要研究方向:海量数据分析与服务; 尹子都(1990—),男,甘肃兰州人,博士研究生,主要研究方向:海量数据分析与服务; 张学杰(1965—),男,云南昆明人,教授,博士生导师,博士,主要研究方向:分布式计算。 1001- 9081(2017)11- 3101- 06 10.11772/j.issn.1001- 9081.2017.11.3101 (*通信作者电子邮箱kyue@ynu.edu.cn) TP391.41 A2.2 关键用户选取
3 实验结果
3.1 有效性测试

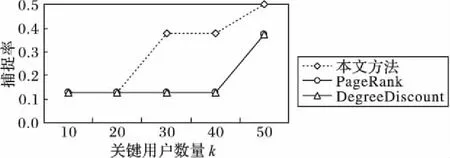
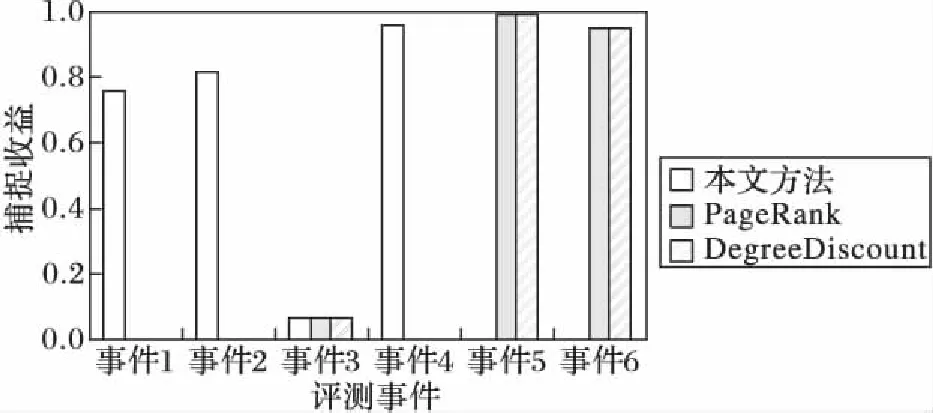
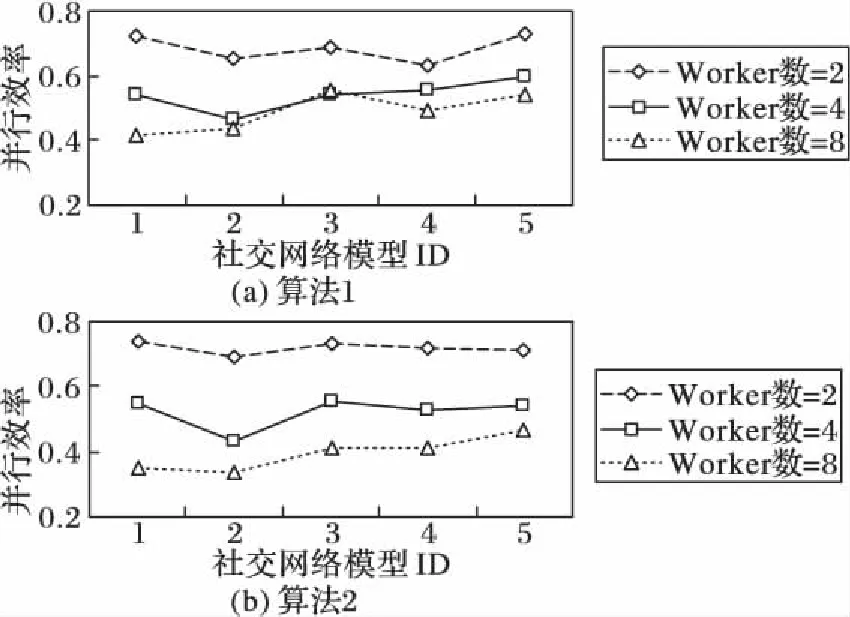
3.2 效率测试



4 结语
