一种基于图的数据流关联规则挖掘算法
2018-01-05汪峰坤张婷婷
汪峰坤,张婷婷
计算机及其应用
一种基于图的数据流关联规则挖掘算法
汪峰坤,张婷婷
针对经典的数据流挖掘算法Lossy Counting算法空间性能较差,并且在搜索指定长度的频繁项所用时间较长等缺点.提出了基于改进的有向图结构的数据流挖掘算法.改进的算法可在图中双向查询和增加频繁项,并且结构中包含了频繁项的长度,在进行指定长度频繁项查询时,无需遍历整个数据结构.实验表明,改进算法比Lossy Counting算法执行效率有所提高.
数据流挖掘;关联规则;频繁项集
数据流上的关联规则挖掘是数据挖掘重要的研究方向[1].随着网络应用,特别是物联网应用的快速发展,针对数据流的处理越来越多[2].如各种传感器监测信号分析、网络中连接地址分析、股市实时分析等领域.数据流是指具有无穷、实时、不确定、连续、随时间变化等特点的数据序列.数据流无法全部保存在主存中,数据流挖掘算法必须满足对数据只扫描一次,处理速度要足够快.
Manku和Motwani于2002年提出了“有损计数算法”[3],近似挖掘数据流中的数据频繁项.算法使用了两个参数:支持度阈值s和允许错误范围ε.将数据流中数据分成“桶”,每“桶”共条记录,当“桶”满时进行挖掘.当满一个“窗口”(多个“桶”)时进行剪枝,挖掘的中间结果以Trie树形式保存在内容中.该算法的优点是计数比较准确,任意元素统计个数最大误差不超过εN(其中N是数据流的长度).缺点是算法空间性能不是很好,数据存储结构不太紧凑.Li等提出了基于前缀树的数据结构“频繁项集的项后缀森林(Item-suffix Frequent Itemset forest)”和基于此数据结构的算法:DSM-FI[4].Item-suffix forest由三个部分组成:OFI-List、FI-List和 SFI-Tree.优点的是插入数据时较快.缺点是增加删除结点要在多个数据结构中进行.Chang和Lee提出了旧数据作用随时间衰减的数据流挖掘算法[5].该算法优点是通过定义衰减因子d,当新数据到来时,对已有数据个数按衰减因子减少,体现了新到数据的重要性.缺点是衰减因子大小不好定义.
数据流关联规则挖掘算法主要由两部分组成:数据频繁集的生成和数据频繁项的查询.对于数据频繁集的生成,一般是在主存中生成数据流的频繁集的数据摘要.因为算法要针对连续到达、数据量巨大的有序序列进行挖掘,所以数据频繁集生成算法要足够快,即数据频繁集生成算法的时间复杂度要低.频繁项实时查询操作过程中,用户往往对指定频繁项长度范围的频繁项感兴趣.例如:在某次查询中,用户可能想查看长度大于4的频繁项.在常见的数据流挖掘算法中,如果查看指定长度的频繁项,需要遍历所有频繁项,然后根据长度进行筛选显示.
针对上述应用场景,本文提出了基于图结构的数据存储结构BNG(双向结点图)和基于BNG的数据流挖掘算法DSM_BNG.当向BNG数据结构中插入频繁项时,算法可以从头结点和尾结点同时进行查询与增加.并且BNG中包含了频繁项的长度,在进行指定长度频繁项查询时,无需遍历整个数据结构.通过仿真实验,验证了本文算法的有效性.
1 数据流关联规则的基本概念和理论
设DS={I1,I2,...,In,...}表示一个数据长度可以是无限的数据流,其中Ii表示在数据流中的第i条事务(或数据).事务I={x1,x2,...,xk},xi为事务中一项,如果事务I中项的个数为k,则称此事务的长度为k,也记作:k=||I.所有长度为k的事务组成的集合称为事务的k项集(k-itemset).为了表示的方便,我们设每条事务都包含一个唯一标识tid,即I=(tid,x1,x2,...,xk).
定义1 对事务I={x1,x2,...,xk}中的项按某种规则排序(一般比较ASCII码值)后得到的新事务I'={x1',x2',...,xk'},称为有序的事务I.在本文中不区分I和I',认为它们是等价的.本文中提到的事务,默认是指排序的事务.
定义2 在算法处理过程中,将数据流中按时间读取的固定事务个数的数据序列称为窗口,记作:W,其中在窗口中所包含的事务个数称为窗口大小,记作:| |W.
定义3 给定支持度阈值s(0<s<1),如果事务Ik在数据流中出现的次数大于等于sN(N为当前已接收的数据流长度),则称事务Ik为真实频繁的,记作:FI(Ik).
定义4 给定允许错误范围ε(0<ε<1),如果事务Ik在数据流中出现的次数小于εN(N为当前已接收的数据流长度),则称事务Ik为不频繁的.
定义5 如果事务Ik在数据流中出现的次数大于等于(s-ε)N(N为当前已接收的数据流长度),则称事务Ik为计算频繁的.
定义6 如果事务I={x1,x2,...,xk},则其尾插结点集合为I'={{x1,x2,...,xk},{x2,...,xk},...{xk-1xk}},显然,对于长度为k为事务,则其尾结点集合中共有k-1条事务.
由于数据流的无穷性,所以在有限的存储空间和运算时间的挖掘过程中,我们不能以枚举的方式生成某条事务的所有子集,所以在算法中我们用某事务尾插结点集合代替事务的子集进行计数统计.同理,算法求出的频繁项集是有误差的,很难保证能挖掘出所有的真实频繁项集.通常情况下,针对数据流的挖掘,求出的是计算频繁项集.在本文中,认为计算频繁项集和真实频繁项集是一样的,简称频繁项集,记作:FI(Ik).
2 改进算法
2.1 算法的基本数据结构
算法的数据结构称为双向结点图(BNG),它的组成部分如下:
(1)头结点哈希表(HeadHashTable).头结点列表中保存事务的第一项相关信息的哈希表.
列表中每一项由5个属性组成:(item,freq,wId,level,nextLinks).其中item指事务中某项内容.freq指item项出现的次数.wId指item项最早加入的窗口编号.level指以item项为第一项的频繁事务项的最大层次(即最大长度).nextLinks:指向下一元素的指针集合.
(2)尾结点哈希表(TailHashTable).尾结点列表中保存事务的最后一项相关信息的哈希表.
列表中每一项由5个属性组成:(item,freq,wId,level,prewlLinks).其中item指事务中某项内容.freq指item项出现的次数.wId指item项最早加入的窗口编号.level指以item项为最后项的频繁事务项的最大层次(即最大长度).prewLinks:指向上一元素的指针集合.
(3)频繁候选项集图结构(FICG).FICG是在内存中存储频繁候选项集的数据结构,每个频繁候选项的首项和尾项链接到头尾结点哈希表.
FICG中每个结点由4个部分组成:(item,freq,wId,prewLink,nextLinks).其中,item指事务中某项内容.freq指item项出现的次数.wId指item项最早加入的窗口编号.prewLink:指向上一元素的指针.nextLinks:指向下一元素的指针集合.
2.2 算法流程
类似于算法Lossy Counting算法,本算法中生成内存摘要树也分成三个部分:Buffer、CreateG和SetGen.另外本算法中包括针对实时搜索频繁项的部分FISearch算法.
Buffer部分是从数据流中读取多条事务到内存中,然后对每条事项按项进行排序,当读取的事务长度等于窗口大小| |W时,按顺序生成窗口编号,转到CreateG部分进行处理.
CreateG部分针对Buffer部分传递过来的事务进行处理,在内存中生成数据流的数据摘要结构:双向结点图.CreateG部分的算法如下.
①遍历Buffer中每一条事务,并求出每一条事务的尾插结点集合.
②遍历尾插结点集合中的所有事务.
③根据事务的第一项在HeadHashTable查找是否存在相应项的头结点,如果存在,更新头结点中最大频繁候选项长度level,且转步骤⑤.否则建立该项的头结点,然后转步骤⑤.
④根据事务的最后一项在TailHashTable查找是否存在相应项的尾结点,如果存在,则转步骤⑤.否则建立该项的尾结点,然后转步骤⑤.
⑤根据HeadHashTable头结点指针集nextLinks查找FICG与事务中下一项相同的结点,同时从TailHashTable尾结点指针集prewLinks查找FICG与事务中上一项相同的结点.如果头查找和尾查找到同一结点,则说明此频繁候选项已经存在,更新查询路径上的结点的freq数值,转到步骤②.如果未查找到同一结点,转到步骤⑥.
⑥将未找到的事务项生成FICG结点,其中freq=1,wId为当前窗口编号.将生成的结点按顺序连接到FICG中.当在FICG中一条事务路径生成结束时,更新头尾结点哈希表中相应头结点freq为freq+1.转到步骤②.
⑦算法结束.
SetGen部分用于内存中候选频繁项集摘要结构的剪枝,删除FICG中结点的条件是:该结点满足:freq<εN,其中N表示当前已读取的数据流长度.SetGen部分的算法如下.
①遍历HeadHashTable中每个头结点.
②如果头结点满足freq<εN,则表示以此头结点开始的候选频繁项集都是非频繁项.删除头结点和头结点下的所有后续结点,转到步骤①.否则转到步骤③.
③按广度优先方式遍历头结点后的所有结点,如果被访问的结点满足freq<εN,则删除该结点和该结点下的所有后继结点.
④算法结束.
FISearch算法可根据用户输入的最短频繁项长度(MinItemLength),快速在候选频繁项集中搜索满足条件的频繁项.在本算法中不输出长度为1的频繁项,即MinItemLength≥2.
FISearch部分的算法如下.
①遍历HeadHashTable中每个头结点.
②如果头结点的level属性小于MinItemLength则说明此头结点下的所有频繁候选项不满足最短频繁项长度的要求,转到步骤①.否则转到步骤③.
③按深度优先方式遍历头结点后的所有后继结点,如果被访问的结点满足freq>(s-ε)N,则被访问结点是频繁项,直到访问到尾结点.如果深度优先遍历的频繁项长度大于或等于MinItemLength,则输出.
本算法相对于经典的数据流挖掘算法,如:DSM-FI、Lossy Counting等,主要是针对内存中存储的数据流摘要信息所使用的数据结构进行了改进.通过使用支持头尾结点双向搜索并且保存有频繁项最大层次数属性的图结构,可以提高数据流摘要信息的增加删除操作的性能,同时,也提高了指定最短频繁项长度的频繁项集的搜索操作性能.
3 DSM_BNG算法实验与分析
3.1 算法流程实验
设读取某数据流时,当前窗口Wj共有6个事务,N=6,Wj={I1,I2,I3,I4,I5,I6},各事务内容为 :I1={a,c,d,f},I2={a,b,e},I3={d,f},I4={c,e,d,f},I5={a,c,d,e,f},I6={c,e,f}.假设错误范围ε=0.2,支持度阈值s=0.5,则剪枝条件是结点频繁数小于等于εN≈2,频繁项条件是频繁数大于等于sN=3.算法流程如下.
(1)生成数据流内容摘要HeadHashTable、TailHashTable和FICG.
处理第一条事务:I1={a,c,d,f}.排序后生成尾插结点集合:I1'={{a,c,d,f},{c,d,f},{d,f}}.对于I1'中的第一条事务{a,c,d,f},到HeadHashTable中判断首结点a是否存在,不存在生成首结点a.首结点a有(item,freq,wId,level,nextLinks)5个属性,对应的值为:(a,1,j,4,null).然后判断直接后继结点c是否存在,生成结点c,相应的属性有(c,1,j,*a,null).处理到最后一项时,判断尾结点f是否存在,不存在生成首结点f.当I1'处理完成时,生成的数据流内容摘要如图1所示.

图1 处理第一条事务后的内存摘要数据结构
处理完窗口Wj的6个事务后,生成的数据流内容摘要如图2所示.

图2 窗口Wj中数据处理完成时的内存摘要数据结构
(2)对数据流内容摘要进行剪枝操作.
当处理完成窗口中数据后,将执行剪枝操作,通过剪枝去除频繁项小于或等于εN≈2的结点,减少内存开销.
例如:对于头结点b,其频繁个数为1小于εN,删除头结点b和它的所有后继结点.对于头结点a的直接后继结点b的频繁个数为1小于εN,删除头结点a中以b为直接后继结点的所有结点.剪枝后内存摘要数据结构如图3所示.
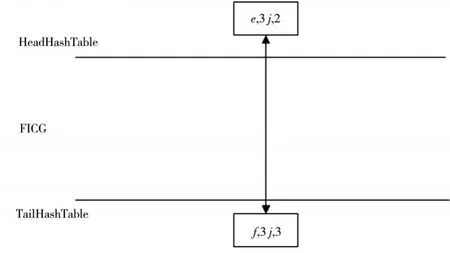
图3 剪枝完成时的内存摘要数据结构
显然,当前满足频繁数大于等于sN=3的频繁项集为:{e,f}.
3.2 算法性能比较
针对多维多值数据频繁模式生成为例,比较了经典的Lossy Counting算法和本文提出的DSM_BNG算法.

图4 不同数据量上算法运行时间
图4比较的是不同数据量时数据流关联规则挖掘的算法效率.测试数据由IBM数据生成器生成.算法参数为:最小支持度1%,错误率为0.1%,数据窗口W为100,数据维数为9,数据量1万条升到10万条.
由图4中可见,在数据量较大时,DSM_BNG算法比Lossy Counting算法性能更好.
4 结束语
本文根据数据流关联规则挖掘特点,提出了基于有向图数据存储结构的数据流挖掘算法DSM_BNG.通过仿真,本算法性能相对于经典的Lossy Counting算法有了一定的提升.
A Graph Based on Algorithm for Mining Association Rules in Data Streams
WANG Feng-kun,ZHANG Ting-ting
(Anhui Technical College Of Mechanical and Electrical Engineering,Wuhu,Anhui 241000,China)
In view of the classic data stream mining algorithm Counting Lossy algorithm has a poor performance in space,and in the search for the specified length of the frequent items with a long time and other shortcomings.A data stream mining algorithm based on the improved directed graph is proposed.The improved algorithm can be bidirectional query and add frequent items in the graph,and the structure contains the length of the frequent items,which is not required to traverse the entire data structure when the frequent item of the specified length is carried out.The experiments show that the improved algorithm is more efficient than the Counting Lossy algorithm.
data stream mining;association rules;frequent itemsets
TP301.6
A
1008-7974(2018)01-0065-05
10.13877/j.cnki.cn22-1284.2018.02.017
2017-02-23
2016年安徽省高校省级自然科学研究重点项目(KJ2016A136);2017年安徽省高校省级自然科学研究重点项目(KJ2017A759);安徽省质量工程项目(2014mooc093).
汪峰坤,安徽霍邱人,安徽机电职业技术学院讲师;张婷婷,女,安徽芜湖人,安徽机电职业技术学院讲师(安徽 芜湖241000).
[1]Agrawal R,Srikant R.Fast algorithms for mining association rules[C]//Bocca JB,Jarke M,Zaniolo C,eds.Proc.of the 20thInt’l Conf.on Very Large Data Bases.Santiago:Morgan Kaufmann Publisher,1994:487-499.
[2]Estan C,Verghese G.New directions in traffic measurement and accounting:Focusing on the elephants,ignoring the mice[J].ACM Trans,on Computer Systems,2003,21(3):270-313.
[3]G.S.Manku and R.Motwani.Approximate Frequency Counts OverData Streams[C].In Proc.Of VLDB,2002.
[4]H.Li,S.Leeand M.Shan.An EfficientAlgorithm for Mining Itemsets over the Entire History of Data Streams[C]//In Proc.Of First International Workshop on Knowledge Discovery In Data Streams,2004.
[5]J.H.Chang and W.S.Lee.Finding RecentFrequent Itemsets Adaptively over Online Data Streams[C].In Proc.of KDD,2003.
王前)
