基于支持向量机和稀疏表示的文本分类研究∗
2018-01-04刘国锋
刘国锋 吴 陈
(江苏科技大学计算机科学与工程学院 镇江 212003)
基于支持向量机和稀疏表示的文本分类研究∗
刘国锋 吴 陈
(江苏科技大学计算机科学与工程学院 镇江 212003)
文本分类对于各个领域挖掘文本信息非常重要,论文在基于频率核函数的文本分类基础上,充分比较各种分类器的优缺点,提出一种利用稀疏表示分类器(SRC)和支持向量机(SVM)的组合方法进行文本分类,以提高文本分类的性能。最后通过实验表明,使用二者结合的方法效果明显好了很多。
稀疏表示;SVM;频率核函数;文本分类
1 引言
互联网的迅速发展,大量的数字媒体的信息传播产生大量数据,这些数据包括大量许多有价值的信息,怎样去挖掘数据中有价值的信息。文本分类就是挖掘信息的很重要的解决方法。文本分类就是将一个文本文档通过各种方法判定文档的属性类型和文档主题。传统的贝叶斯分类[1],决策树[2],k近邻方法[3]等;这些算法的缺点是不能对大量文本进行分类。为了解决这个问题,研究者们又相继提出了许多特征选择文本方法。在本文中,对几种的分类进行了探讨,提出了一种稀疏表示分类器(SRC)的文本分类方法。目前利用稀疏表示进行文本分类的研究很少。
支持向量机(SVM)[4]是目前流行的文本分类方法,支持向量机传统的方法是利用线性核函数或高斯核函数进行分类。然而在本文中,将支持向量机运用直方图交叉核、卡方分布和Hellinger核函数[5]在文本分类中。最后充分利用各种分类器的优点,本文提出一种新的方法将分类器进行相结合,然后进行分类。
2 稀疏表示分类
2.1 稀疏表示
假设向量X∈Rd字典D={u1,u2,…,uNt}T∈Rd×Nt,
那么X的稀疏表示就是将X表示为u的线性组合X= β1u1,β2u2,…,βNtuNt,这 里 β={β1,β2,…,uβNt}T是和基向量有关的系数向量,稀疏表示时,要确保β只能有很小一部分能为0,稀疏表示通过β和X可以转化为
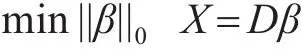
这里||β||0是 X的稀疏度,β为非零系数的个数。我们想使得 X尽可能稀疏,就要使得||β||0最小。最近有研究表明,上述问题最小可以有
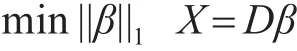
2.2 稀疏表示进行分类
在进行分类时,文本分类的训练集作为基向量D ,则有字典矩阵 D=[D1,D2,…,DM]T,M 为种类数量,在这里,DM=[Xm1,Xm2,…,XmN]T,n=1,2,…,m;有M类训练样本。对于样本是否属于M类可以求m类训练样本是否可以线性组合,即系数β和训练样本M的相关系数不为0,其他系数均为 0;系数向量 β ,表示为 β ={0,…,0βm1,βm2,…,βmn,0,…0}T理想情况下,一个测试集的最优 β应该使得训练集和测试集相同时相关的系数不为零并且为稀疏的。
用稀疏表示方法来进行文本分类的主要问题是要具有超完备字典D,特征词向量的维数大小取决于词汇量的大小。通常情况下,词汇量远大于训练集数目,这不满足超完备字典D的必要条件,为了解决这个问题,有人提出减少词汇的方法[6],在本文中采用对词汇的特征向量进行主成分提取的方法,用主成分分析的方法确保了主成分训练的数量要少于训练总数量,本文给出下面三种分类规则
1)理论上,在完备词典D下,所有非零项β都使得测试集和训练集是相同类别。这样,一个测试集就分配具有最大值训练样本的类标签。
2)实际上,对应于其他类的测试样本,也可以是非零的。基于这一点,我们计算了所有的所有类别的稀疏度,并选择最大的稀疏度的类作为类标签的测试样本。让δM(β)作为m类值为 β的一个向量,然后给定的类标签的一个测试样本的赋值:
Label=max(||δm(β)||2);m=1,2,…,M
3)最小残差:X作为测试样本,Dβ指出了X的范围。X和它的重构时候出现残余误差。既然属于其他类的 β也可以是非零,||X-Dδm(β)||2给出了M类残余误差,最小残差作为测试样本的类标签:
Label=min(||X-Dδm(β)||2);m=1,2,…,M
3 基于频率核函数的SVM分类
3.1 直方图交叉核
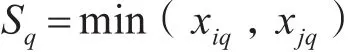
则通过HIK计算全部匹配总数为
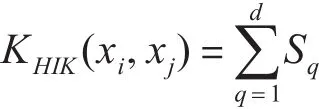
3.2 卡方核函数
卡方统计方法和HIK方法[7]计算相似,第q个bin中的匹配数如下公式计算:
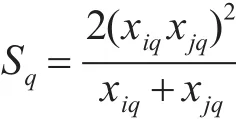
卡方计算总数为
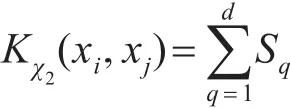
3.3 Hellinger核函数
Hellinger核函数[8]也和HIK方法计算相似,第q个bin中的匹配数如下公式计算:

计算匹配总数为
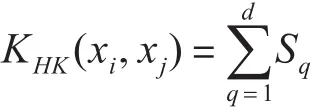
4 分类器组合
由于采用SRC分类会把一些文本文档错误分类,而用SVM分类时却是正确的,一些文本SVM会分错误而SRC会分类正确,为了解决这个问题,本文利用基于投票表决的方法去进行分类器的组合。m表示类别数和k表示对应的分类器。每一个分类器 λk,K=1,2,…,K ;都会为测试样本提供一个投票数 vk,vk∈{1,2,3,…,M},那么测试样本类别可表示为
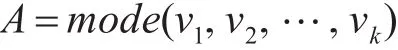
出现次数最多即A最大,那么测试样本就是这一类别,这样做有时会失败,这需要分类器之间有某种约定,可能在一次投票中,两个分类器投票时对同一测试样本投的不是同一类。
对于测试样本来讲,类标签是后验概率决定的。对于每一个测试样本,分类器都计算一个后验概率。测试文档的类别就是所有分类器中最大后验概率的类别。
5 文本分类实验仿真
在本文中采用实验仿真来进行文本分类。本文运用20 Newsgroup新闻语料库来进行分类实验。本语料库由18774个文件,分为20类不同的新闻组,其中的60%(11269个)的文件用于训练模型,剩余的40%的文件被用于测试。这里采用词频作为主要特征,我们从所有的训练中得到53975个单词作为词汇,在文档中计算每个词汇发生的频率,每一个文档都被表示为一个53975维的词频向量。
首先,利用稀疏表示的分类器(SRC)[9]进行分类,对于用的语料库 Nt=11269小于文档D的53975,不满足SRC必要条件,所以用上面提出的主成分分析进行分析[10]。采用主成法分析D值从1000到11000并且每增加1000的SRC性能分析。对于不同词汇数量的SRC分类精度如图1,图1还比较了SRC与支持向量机的高斯方法性能比较。由图1可见,当d=6000是分类性能最佳。还可以看到,使用第二种SRC的分类规则要优于第一和第三种的分类规则。SRC使用第二种规则的分类精度可达78.78%。还可以看出使用SRC文本分类比基于高斯方法的SVM分类器性能好。
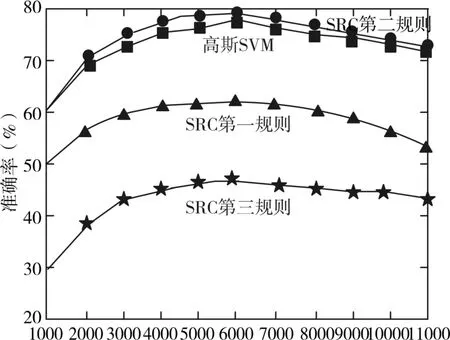
图1 对SRC和SVM性能分析
对基于频率核函数的支持向量机方法进行研究,对每一个文档词频向量表示维度都是53975。运用svmtorch工具建立分类器[11]。基于频率核函数有:直方图交叉核,卡方分布,Hellinger核函数,表1对它们的分类效果进行比较,同时也比较了基于SVM和SRC的高斯核的分类效果。可以看出,SVM用Hellinger核函数时的分类略优于使用直方图交叉核和卡方核函数,SVM基于频率核函数要略优于基于高斯核分类。这说明基于频率核函数的SVM分类器效果更好。
由于不同种类分类器对文档产生不一样的分类结果。而且不同规则制定和SVM运用不同核函数时,结果也不一样。本文提出将分类器进行结合,可以适当解决不同分类造成的差异而且适用于各个训练集。k是分类器的数量取决于文本数量多少。如果K个分类器对样本都分配同样的标签,那么该文本就属于这一类别。

表1 分类效果比较
表2给出了在SRC和SVM结合后的分类效果。给出了三种结合方法的分类:第一,SRC和三种不同分类规则结合,第二,基于高斯核函数,直方图交叉核,卡方核函数,还有Hellinger核函数的SVM结合,第三,将三种结合后SRC和四种结合后的SVM相结合。可以看出,当SRC的三种不同规则相结合时,分类正确率提高了约5%。,当用四种SVM函数结合时有正确率提高了大约7%,当结合所有的SRC和SVM时,分类正确率提高了约8%。

表2 SRC和SVM结合后的分类效果
6 结语
本文从比较了SVM和SRC的分类器性能,可以看出使用组合分类器性能对于文本分类效果有了很大的提升。但是本文中对于组合分类器的适用的范围有所限制,提高分类器的普适性也是以后文本分类进一步的研究方向。
[1]Andrew McCallum,Kamal Nigam.A comparison of event⁃models for naive Bayes text classification[J].in Proceed⁃ings of AAAI-98 workshop on learning for text categoriza⁃tion,1998,752:41-48.
[2]尚朝轩,王品,韩壮志,等.基于类决策树分类的特征层融合识别算法[J].控制与决策,2016(6):1009-1014.SHANG Zhaoxuan,WANG Pin,HAN Zhuangzhi,et al.Features of decision tree classification fusion recognition algorithm based on[J].Control and Decision,2016(6):1009-1014.
[3]郝秀兰,陶晓鹏,徐和祥,等.KNN文本分类器类偏斜问题的一种处理对策[J].计算机研究与发展,2009(1):52-61.HAO Xiulan,TAO Xiaopeng,XU Hexiang,et al.A kind of countermeasure of KNN text classifier class skew problem[J].Journal of Computer research and development,2009(1):52-61.
[4]Thorsten Joachims.Text categorization with support vector machines:Learning with many relevant features[C]//in Proceedings of the 10th European Conference on Machine Learning(ECML'98).ACM,1998:137-148.
[5]黄宏图,毕笃彦,高山,等.基于局部敏感核稀疏表示的视频跟踪[J].电子与信息学报,2016(4):993-999.HUNG Hongtu,BI Duyan,GAO Shan,et al.Video track⁃ing based on local sensitive kernel sparse representation[J].Journal of Electronics and Information Technology,2016(4):993-999.
[6]Tara N Sainath,Sameer Maskey,Dimitri Kanevsky,Bhu⁃vana Ramabhadran,David Nahamoo,and Julia Hirsch⁃berg.Sparse representationsfor text categorization.[J].in Proceedings of INTERSPEECH,2010,10:2266-2269.
[7]Jan C.van Gemert,Cor J.Veenman,Arnold W.M.Smeul⁃ders,and JanMark Geusebroek.Visual word ambiguity[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(17):1271-1283.
[8]Ken Chatf i eld,Victor S Lempitsky,Andrea Vedaldi,and Andrew Zisserman.The devil is in the details:an evalua⁃tion of recent feature encoding methods[C]//in Proceed⁃ings of the 22nd British Machine Vision Conference(BM⁃VC 2011),Kingston,UK,September 2011:76.1-76.12.
[9]陈才扣,喻以明,史俊.一种快速的基于稀疏表示分类器[J].南京大学学报(自然科学版),2012(1):70-76.CHEN Caikou,YU Yiming,SHI Jun.a fast sparse repre⁃sentation classifier based on[J].Journal of Nanjing Uni⁃versity(Natural Science Edition),2012(1):70-76.
[10]范雪莉,冯海泓,原猛.基于互信息的主成分分析特征选择算法[J].控制与决策,2013(6):915-919.FAN Xue li,FENG Haihong,YUAN Meng.Principal component analysis based on mutual information feature selection algorithm[J].Control and Decision,2013(6):915-919.
[11]R.Collobert and S.Bengio.SVMTorch:Support vector machines for large-scale regression problems[J].Jour⁃nal of Machine Learning Research,2001:143-160.
Text Classification Using Combined Sparse Representation Classifiers and Support Vector Machines
LIU GuofengWU Chen
(School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang 212003)
Text classification is very important for various fields of management of a large number of text content,based on text classification based on the frequency of kernel function,the advantages and disadvantages of all kinds of classifiers are com⁃pared,this paper proposes a sparse classifier(SRC)and support vector machine(SVM)combination method to improve the perfor⁃mance of text classification.Sparse representation classifier the field dictionary is constructed by means of the vector representation of the document.SVM text classifier linear kernel function and Gauss kernel function are used for the vector representation of the document.
sparse representation,SVM,frequency-based kernels,text classification
Class Number TP391
TP391
10.3969/j.issn.1672-9722.2017.12.032
2017年6月6日,
2017年7月27日
刘国锋,男,硕士研究生,研究方向:信息处理理论与技术应用。
