基于词向量的微博话题发现方法
2018-01-03李帅彬李亚星冯旭鹏刘利军黄青松
李帅彬 李亚星 冯旭鹏 刘利军 黄青松,2
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500) 2(云南省计算机应用重点实验室 云南 昆明 650500)
基于词向量的微博话题发现方法
李帅彬1李亚星1冯旭鹏1刘利军1黄青松1,2
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(云南省计算机应用重点实验室 云南 昆明 650500)
针对微博的短文本、口语化和大数据等特性,提出基于词向量的微博话题发现方法。爬取实验数据结合中文语料库训练得到词的向量表示,再通过定义的文本词向量模型得到文本的词向量表示,相较于传统的向量空间表示模型,词向量表示模型能够解决微博短文本特征稀疏、高维度问题,同时,能够解决文本语义信息丢失问题;采用改进的Canopy算法对文本进行模糊聚类;对相同Canopy内的数据用K-means算法做精确聚类。实验结果表明,该方法与经典Single-Pass聚类算法相比,话题发现综合指标提高4%,证明了所提方法的有效性和准确性。
话题发现 词向量 短文本 Canopy聚类
0 引 言
2015年中国社交应用用户行为研究报告指出:综合社交媒体中新浪微博的使用率高达43.5%[1]。微博的短文本性、即时性和交互性等优点获得了大批忠实粉丝,但微博提供信息传播途径的同时,也为不良信息、谣言甚至恶意攻击话题提供了传播渠道。因此及时发现微博热点话题并监管,对政府部门舆情引导具有重要意义[2-3],同时,还可以服务于企业战略决策和广告精准营销。但微博短文本、口语化、大数据量等特性给话题发现带来极大的困难。
话题发现研究主要集中于基于文本的聚类算法和基于概率的话题模型。传统聚类算法中文本多采用向量空间模型表示[4]。向量空间模型表示的文本存在稀疏性和高维度缺点,且高维度的向量不利于计算;另一个缺点是忽略词之间的语义关系。例如,文献[5-6]采用向量空间模型结合Single-Pass聚类算法来对短文本进行会话抽取和话题检测。Single-Pass算法思想为按顺序读取数据,每次处理一个数据,根据新数据与已有类的相似度,将该数据判断为已有类或者单独成为新的类,这样可以实现数据的增量聚类,但该算法依赖数据的次序,且用于短文本聚类时特征稀疏。针对特征稀疏性,文献[7]用维基百科来扩充特征,还有的文献用搜索引擎来辅助特征的选择。第一种方法对知识库完备性要求比较高。第二种方法依赖于搜索引擎的结果并且搜索海量的特征需要消耗大量的时间。LDA模型是基于概率的话题模型的代表。文献[8-9]用LDA模型发现话题和追踪话题,朱雪梅等[10]指出LDA可以一定程度解决语义丢失问题。但单斌等[11]LDA话题模型综述中指出LDA模型虽能够自动获取海量文本信息的主题或话题,但大多数基于LDA的话题演化方法都假定话题数目是固定的。陈福等[12]指出新浪微博这样的短文本在线网络,直接用LDA进行语义获取具有一定的局限性,同时指出对微博这样的在线短文本,基于内容的比较和关键词语义识别非常重要。骆卫华等[13]提出了分治多层聚类话题发现算法,基于分治策略解决大规模数据集问题。缺点是采用传统的向量空间模型表示文本,词语语义相似性考虑不足。路荣等[14]通过挖掘短文本的隐主题解决稀疏性问题,然后用一种两层的K均值和层次聚类混合聚类方法解决大规模数据问题,但具体几篇微博能将一个新闻事件完整表示出来有待验证。McCallun A[15]等提出两层聚类方法,解决高维度大数据量问题。但方法中划分Canopy时,每次随机选择一个种子文档,导致两个问题:划分容易先形成规模大的Canopy,影响后面话题精确聚类的效率;初始种子选择不当,导致迭代次数和冗余度增加。陈强等[16]基于Canopy算法基础上提出K-Canopy算法。但其采用传统的信息检索技术将文本转换为一组加权的特征值构成的向量,导致高维度向量,增加空间消耗,不利于计算;划分簇时采用汉明距离比较文本相似度,虽然能够提高效率,但精度难以保证。
Hinton等[17]首先提出词向量的概念,词向量的基本思想是利用词的上下文信息,用固定维数的实数来表示词,通过词间相似性表示词间的语义信息。词向量自提出受到各国学者关注,2003年Bengio提出三层神经网络构建语言模型,根据上下文信息预测下一个词,2013年Mikolov提出并开源了Word2Vec[18]模型。词向量已经用于微博的情感分析[19]、微博采集和个性化推荐[20]。文献[21]中用词向量来对搜索词进行主题分类、聚类来挖掘搜索意图和兴趣。已有文献充分表明词向量能够解决维度灾难和特征稀疏性问题,并且能够结合上下信息,防止语义信息丢失。
综上所述:本文提出一种基于词向量的微博话题发现方法VCK(Vector Canopy&K-means),方法有效解决短文本、口语化等特性造成的维度灾难、特征稀疏和语义鸿沟问题。该方法定义微博的词向量表示模型,然后利用改进的Canopy算法对数据做初始簇聚类,获得聚类中心个数和中心向量。最后利用K-means算法做精确聚类。
1 基于词向量的话题发现方法
本文方法主要工作包括微博文本的词向量表示、Canopy算法初始簇聚类。任务的流程如图1所示。首先模拟登录新浪微博爬取数据,数据除了包括微博内容,还包括发微博的微博账号等级、粉丝数、所发微博的转发数和评论数;然后,对文本做预处理、计算微博的权重和微博的词向量表示;其次,利用改进的Canopy算法对词向量表示的微博文本进行模糊簇聚类;最后,根据Canopy算法得到的簇个数和簇的中心初始化K-means算法的聚类数目和初始中心,进而做精确聚类。

图1 VCK流程图
因为Canopy算法粗聚类之后造成各簇之间有数据重叠,所以利用K-means算法在同一个Canopy簇中再做精确聚类,同时,Canopy算法得到的簇中心和簇数目有效地解决了K-means算法依赖初始中心和聚类数目选择的问题。
1.1 微博的词向量表示
爬取的微博语料内容含有很多无意义词语和符号,为了提高实验的效率和精度需要做一些预处理工作,具体在实验环节介绍。为了方便理解,先给出文中用到的一些定义。
定义1(词的向量表示)W={d1,d2,…,dn}:其中n表示词的向量维度,每个词的维度相同,di表示词对应i维上的值。
定义2(微博的词集合表示)S={w1,w2,…,wm}:其中m表示文本中词的个数,不同文本含有的词的个数不一定相同,wi表示文中第i个词。
Mikolov等[18]在文中指出,词向量的学习不仅仅能够学习到其语法特征,还能够利用向量加减的方式进行语义上面的计算。根据此得出如下定义。
定义3(微博的词向量表示)D={x1,x2,…,xn}:其中n和定义1中词的维度相同,表示文本的词向量的维度,xi表示文本向量第i为上的值。xi由如下公式计算得到:

(1)
式中:m和定义2中文本含有词的个数相同,表示文本中词的数量,Wmi表示文本中第m个词对应的词向量中第i维的值。
定义4(簇Canopy的中心向量)Center={y1,y2,…,yn} 其中n表示中心向量的维度,大小与定义3和定义1中的维度相同,yi表示向量第i维上对应的实数值。yi由如下公式计算得到:

(2)
式中:t表示Canopy算法得到的每个初始簇聚类中文本的数目,Dti表示Canopy中第t个文本的向量中第i维值。
1.2 微博的权重计算
不同的微博对话题的影响力和传播力不同,本文用微博的权重衡量微博的话题影响力。微博D的权重Q计算方法如下:
Q=Weight×(TRi+LRi+CRi)
(3)
式中:Weight是根据微博用户特征定义的权值,微博用户分为加V认证用户和非认证用户。王国华等[22]指出热门微博发布主体中加V用户比例高达72.3%,同时指出加V认证或粉丝数较多的用户在微博的话题传播过程中起到巨大的推动作用。
(4)
其中:P为认证用户取值,Q为非认证用户取值。

(5)

(6)

(7)
其中:NTR、NLR、NCR分别表示每条微博的转发数、点赞数和评论数,Sum(NTR)、Sum(NLR) 、Sum(NCR)分别表示所有微博的转发数之和、点赞数之和和评论数之和。
1.3 基于改进的Canopy算法的粗聚类
1.3.1 Canopy算法简介
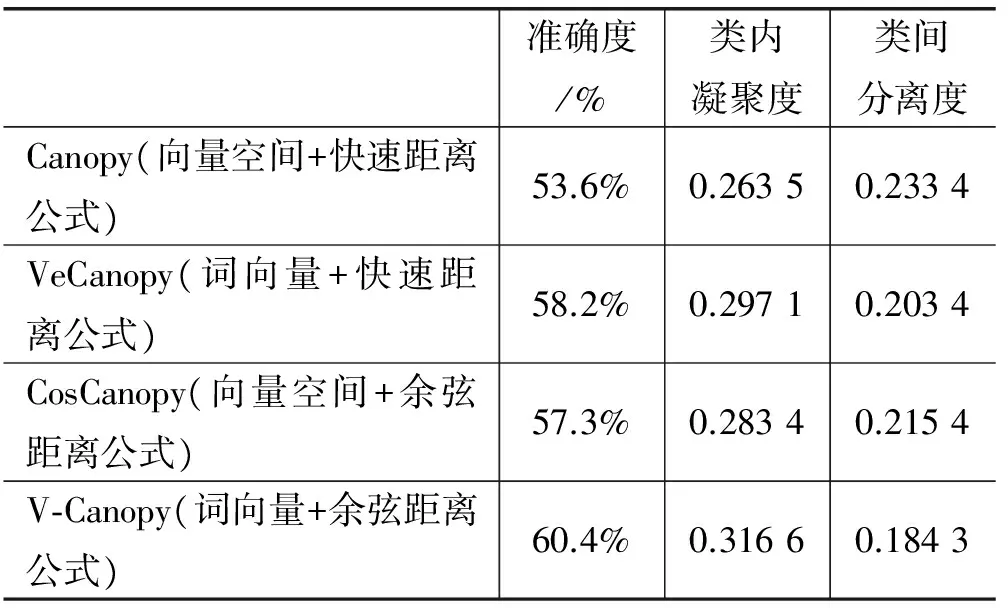
MaCallum A等[15]提出了一种适用高维度和大数据量的聚类算法。算法把数据划分成相互重叠的簇,最后利用传统聚类(Kmean、EM)算法对同一簇的文档做精确聚类。划分簇时定义两个阈值T1和T2(T2 图2 Canopy算法划分结果 1.3.2 改进的Canopy算法 划分簇过程中文本相似度的计算是关键,相似度计算越精确,划分得到的簇越符合实际生活中话题文本的真实聚集情况。计算精度高低同时决定算法的迭代次数。本文试图提高算法的计算精度来提高划分的精度,进而计算出更符合实际情况聚类,有利于提高话题发现的准确率和速度。 本文主要从以下方面来提高计算精度:1) 微博文本向量用定义3表示。文本的词向量表示充分考虑了上下文语义相似性,使文本相似性计算隐射到语义层面,用以解决向量空间模型中特征词孤立和语义鸿沟问题,同时,词向量的低维度特性能够减少计算量,降低空间消耗,提高计算速度等。2) 根据式(3)微博权重Q选取种子文档。高权重的微博文本话题完整,内容真实客观,影响力大,用以解决随机选择种子文档带来的迭代次数和冗余度增加问题。3) 余弦距离公式计算相似度。余弦距离计算两个向量的夹角余弦,倾向于对向量内容的比较,而对绝对的数值不敏感,修正了可能存在的度量标准不统一问题,优于汉明距离公式。本文从上述方面来提高了文本间相似性计算的精确度,使得话题相似文档更容易落入T2子集中,降低了数据冗余度,减少了迭代次数,提高了计算效率和准确率。改进的算法流程如下: 算法1改进的Canopy算法 输入:剩余文档集L,阈值T1、T2。 输出:Canopy簇集合,各Canopy的中心向量。 1.Cluster_Canopy(L ,T2,T1){ 2.SL=Sort(L)//权重排序微博队列L,SL排序后的微博 //文本列表 3.While(SL!=NULL){ //循环直至SL为空 5.Dseed =SL.get();//根据权重获得种子文档 6.Cluster.add(Dseed);//将种子文档作为新的Canopy簇 //中心,Cluster表示聚类簇 7.从剩余文档集队列SL中删除文档Dseed 8.for(C: SL){ 9. dist=cos(Dseed,C); 10. if(dist 11. 文档C加入Dseed所在Canopy的簇中。 12. if(dist 13. 从剩余文档队列SL中删除C文档,C不能作为种子文档,即C不能作为新Canopy簇中心 14.} }}//for end 15.得到簇Cluster加入Canopy簇集合队列CanopyClusters中 16.}//while end 17. for(Cluster : CanopyClusters){ 18. 利用定义4获得Canopy簇的中心向量 19. 将中心向量加入中心向量队列centerClusters中} //for end 20. k=CanopyClusters.size()//获得中心向量的个数} 算法中文本间距离采用余弦距离公式,通过上节文档的词向量表示,得到文本的词向量表示,如文本D1{x1,x2,…,xn},D2{x1,x2,…,xn},则距离计算公式如下: (8) 2.1 实验语料和预处理 微博话题发现没有标准的测试集,本实验采用的语料是从新浪微博2016年7月到2016年8月间采集的热点话题微博,通过人工标注得到10个话题,具体语料如表1所示。 表1 实验数据 预处理包括:去除特殊符号、去除停用词、分词。爬取的微博内容含有很多对内容没有意义的符号和词,如特殊符号#、@、表情符号、链接、“的”、“了”等停用词。分词后少于3个词的文本对话题信息表达不完善,故删除此类文本。最后,获得干净的、具有意义和信息完善的语料。 本文用Word2Vec工具的CBOW模型得到定义1定义的词向量。然后,用定义3得到文本的词向量表示。 2.2 实验评价标准 对于簇聚类的评价标准采用文献[16]中聚类准确度、类内凝聚度、类间分离度来衡量切分准确度和质量,具体定义如下: (9) (10) 式中:CorrectNum表示该Canopy中包含最多文档类别的文档数,TotalDocs表示该Canopy包含的文档数。式(9)表征Canopy的纯度。 (11) (12) 式(11)计算的是类内凝聚度,num是Canopy的数量,size是第i个Canopy所包含的文档数量,center是定义4中Canopy的中心向量,Dist是计算文档Doc和center之间的距离,类内凝聚度越高说明切分质量越好;式(12)计算类间分离度,该值越小,说明切分质量越好。 对于话题发现采用准确率(P)、召回率(R)和F-Measure值作为评价标准。 准确率: (13) 召回率: (14) F-Measure: (15) 式中:A表示已检测到与话题相关的微博数,B表示已检测到与话题不想关的微博数,C表示未检测到与话题相关的微博数。 2.3 实验结果及分析 2.3.1 传统Canopy算法、K-Canopy算法与VectorCanopy算法的对比实验 为了说明VectorCanopy(V-Canopy)算法的有效性,通过比较相同参数条件下算法的各项指标来说明。算法参数中,当T2较大时,Canopy个数比较少;相反T2较小时,Canopy个数较多。当T1较小时,Canopy的大小相对较小;相反T1较大时,Canopy的大小相对较大,数据冗余度较严重。本文更关注数据切分的准确性和切分的质量,但对于数据切分的速度允许一定的损失,因为数据切分的质量决定后期话题发现的准确度和速度,从而影响话题发现相关商业活动的有效性和投资回报率等。如微博广告精准投放对话题的质量要求越高越好。实验采用文献[16]参数指标作为实验中参数的值,即T1=0.05,T2=0.03。实验结果见表2。 表2 Canopy、K-Canopy和V-Canopy算法数据划分实验结果对比 通过对比实验可以发现,在相同的参数的情况下,K-Canopy比传统的Canopy算法的准确度提高了约5%,类内凝聚度提高了约11%,类间分离度减低了约13%。V-Canopy 与K-Canopy相比,精确度提高了约4%,类内凝聚度和类间分离度也较好。但是实验发现,K-Canopy算法的速度优于V-Canopy算法,因为V-Canopy算法采用相似余弦距离公式,精度提高了,但效率降低。 为了说明文本的词向量表示和余弦距离公式的有效性,通过比较V-Canopy算法下分别采用传统向量空间表示文本、传统快速距离公式即词的共现占比和采用词向量空间模型和余弦距离公式的各项指标来说明。实验中的参数同上。实验结果见表3所示。 表3 Canopy、VeCanopy、CosCanopy和V-Canopy算法划分数据实验结果对比 通过对比实验可以发现,VeCanopy算法的精确度、类内凝聚度和类间分离度指标优于传统的向量空间表示文本,因为词向量考虑了上下文语义的相似性,提高了文相似度。CosCanopy算法的精确度、类内凝聚度和类间分离度指标优于Canopy算法,但相对于VeCanopy略显不足,因为向量空间模型的缺点降低了余弦距离公式相似度比较的精度。V-Canopy算法的各项指标都优于单独采用词向量表示或余弦距离公式算法。 2.3.2 话题发现上实验结果对比 为了比较本文话题发现的可行性和优良性,VCK算法得到的结果与K-Canopy&Kmeans算法、Single-Pass算法和LDA算法比较,LDA和single-pass采用传统的向量空间模型和余弦距离,K-Canopy采用传统的向量空间模型,VCK采用词向量模型和余弦距离模型。实验结果见图3。 图3 四种方法的比较 实验结果表明, VCK算法的综合指标比K-Canopy高约3%,比Single-Pass高约4%,比LDA高约2%。充分说明了采用词向量表示模型和余弦距离能够提高话题发现的精度,说明了词向量能够结合语义提高文本间语义相似度,从而提高聚类的准确性。 在以上实验基础上,随机抓取3万条微博做测试,V-Canopy的准确率达到58%,VCK算法准确率达到80%,验证了方法的有效性和合理性。 本文提出了基于词向量的微博话题发现方法,针对微博文本短、特征稀疏、数据量大的特点,用词向量表示文本。与传统方法相比,有效地解决了文本向量高维度、稀疏性问题。同时,词向量模型是通过一个词所在上下文的词来推测这个词向量中的维度值,所以相对于传统方法能够很好地解决语义信息丢失的问题。然后,采用改进的Canopy算法对文本做模糊簇聚类。最后,Canopy的个数作为Kmeans初始中心个数,对相同的Canopy内的数据做精确聚类。实验结果表明,该方法的精确度优于K-Canopy&Kmeans方法。 本文的方法中Canopy簇聚类采用余弦距离,与K-Canopy方法中的汉明距离相比,计算效率降低,后续工作考虑采用Hadoop[23]平台增加计算并发性来提高效率。 [1] 中国互联网信息中心(CNNIC).2015年中国社交应用用户行为研究报告[R].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/sqbg/201604/t20160408_53518/P0201607225514 29454480.pdf. [2] 蒙祖强,黄柏雄.一种新的网络热点话题提取方法[J].小型微型计算机系统,2013,34(4):743-748. [3] 何跃,帅马恋,冯韵.中文微博热点话题挖掘研究[J].统计与信息论坛,2014(6):86-90. [4] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620. [5] 黄九鸣,吴泉源,刘春阳,等.短文本信息流的无监督会话抽取技术[J].软件学报,2012,23(4):735-747. [6] Yang Y,Pierce T,Carbonell J.A study of retrospective and on-line event detection[C]//Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval.ACM,1998:28-36. [7] 叶成绪,杨萍,刘少鹏.基于主题词的微博热点话题发现[J].计算机应用与软件,2016,33(2):46-50. [8] 张晓艳,王挺,梁晓波.LDA模型在话题追踪中的应用[J].计算机科学,2011,38(10A):136-139. [9] 张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802. [10] 朱雪梅.基于Word2Vec主题提取的微博推荐[D].北京理工大学,2014. [11] 单斌,李芳.基于LDA话题演化研究方法综述[J].中文信息学报,2010,24(6):43-49. [12] 陈福,林闯,薛超,等.短句语义向量计算方法[J].通信学报,2016,37(2):11-19. [13] 骆卫华,于满泉,许洪波,等.基于多策略优化的分治多层聚类算法的话题发现研究[J].中文信息学报,2006,20(1):29-36. [14] 路荣,项亮,刘明荣,等.基于隐主题分析和文本聚类的微博客新闻话题发现研究[C]//全国信息检索学术会议,2010. [15] McCallum A,Nigam K,Ungar L H.Efficient clustering of high-dimensional data sets with application to reference matching[C]//Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2000:169-178. [16] 陈强,杜攀,陈海强,等.K-Canopy:一种面向话题发现的快速数据切分算法[J].山东大学学报(理学版),2016,51(9):106-112. [17] Hinton G E.Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society,1986:1-12. [18] Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013. [19] Socher R,Perelygin A,Wu J Y,et al.Recursive deep models for semantic compositionality over a sentiment treebank[C]//Deep Models for Semantic Compositionality Over a Sentiment Treebank.Conference on Empirical Methods in Natural Language Processing (EMNLP 2013),2013. [20] 俞忻峰.新浪微博的数据采集和推荐方案研究[D].南京理工大学,2015. [21] 杨河彬.基于词向量的搜索词分类、聚类研究[D].华东师范大学,2015. [22] 王国华,郑全海,王雅蕾,等.新浪热门微博的特征及用户转发规律研究[J].情报杂志,2014(4):117-121. [23] 赵庆.基于Hadoop平台下的Canopy-Kmeans高效算法[J].电子科技,2014,27(2):29-31. MICROBLOGGINGTOPICDETECTIONBASEDONTHEWORDDISTRIBUTEDREPRESENTATION Li Shuaibin1Li Yaxing1Feng Xupeng1Liu Lijun1Huang Qingsong1,2 1(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)2(YunnanKeyLaboratoryofComputerTechnologyApplications,Kunming650500,Yunnan,China) Aiming at the characteristics of microblogging short text, colloquialization and big data, a new method based on the distributed representation is proposed. We crawled the experimental data combined with the Chinese corpus training to get the vector representation of the word.Then we got the word vector representation of the text by defining the text word vector model.Compared with the traditional vector space representation model,the word vector representation model can solve the sparse and high dimensional problem of microblog short text,and can solve the problem of text semantic information loss.We used the improved Canopy algorithm to fuzzy text clustering,and the data in the same Canopy were clustered by the K-means algorithm. Experiments showed that the comprehensive index of the proposed method’s increased 4% compared with the Single-Pass algorithm. The experimental results proved the validity and accuracy of the proposed method. Topic detection Word distributed representation Short text Canopy cluster 2017-02-01。国家自然科学基金项目(81360230,81560296)。李帅彬,硕士生,主研领域:机器学习,自然语言处理。李亚星,硕士生。冯旭鹏,硕士。刘利军,讲师。黄青松,教授。 TP3 A 10.3969/j.issn.1000-386x.2017.12.009

2 实验及结果分析




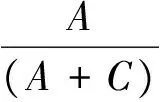



3 结 语
