基于SVR预测的可逆数据库水印技术
2018-01-03龙晓泉
龙 晓 泉
(中移互联网有限公司 广东 广州 510640)
基于SVR预测的可逆数据库水印技术
龙 晓 泉
(中移互联网有限公司 广东 广州 510640)
频繁模式树(FP-tree)的关联规则是利用数据挖掘算法来确定受保护的属性和其他数据库之间存在的关系,支持向量回归方法(SVR)用来预测每个受保护的属性值。提出通过嵌入原始数据库的重要特征来检测数据库是否被篡改过的实现方法。通过对比差值扩展(DE)的原始值和预测值之间的差异,数据库管理员可以在受保护的数据库中嵌入数字水印,如果受保护的数据库是扭曲的,在SVR功能下仍然是可以预测保护值的。FP-tree挖掘方法用于降低SVR的训练时间,如果该数据库已被篡改,我们可以从受保护的数据库中提取水印,来验证并定位篡改元组,恢复原来的属性值,如果该数据库没有遭到攻击,我们也可以利用水印保护数据库。因此,提出的数据库的电子水印方式可以有效地验证数据库的完整性和保护数据库的安全性。
数据库水印 差值扩展 支持向量回归 FP-tree挖掘
0 引 言
在现实生活中,个人和组织都喜欢将一些数字信息存储在数据库中,便于管理。由于这些信息包含与重要决策相关的数据,因此保护数据库免受篡改是一个重要的问题[1]。近年来,研究人员已经开发了数据库水印技术,把数字水印嵌入数据库中,使得数据库中的保护列将允许检测是否被篡改。
在数据库中嵌入数字水印,应确保和保护通过使用水印技术存储在数据库中的所有列的决策数据的正确性和一致性。然而,如果数字水印嵌入在列中,并且列中的值需要修改,那么数字决策数据可能会失真,这将导致出现不正确的决策数据[2]。
在数据库中,存储的数字决策数据不允许失真,并且决策数据库中的数据不能随意修改。虽然目前的嵌入式水印技术可以验证列的正确性,但是不能恢复原始的数字数据[3]。因此,本文针对SVR技术,将数字水印嵌入在数字决策数据库中,验证是否可以恢复原来的数字数据。
有些人通过使用独特的特征来表示关系数据,给数字水印带来新的挑战。通过提取嵌入的数字水印来检测数据库是否被篡改[4-5]。嵌入的水印可以用于任何关系数据库。然而,如果发生篡改攻击,向数据库插入新属性,那么提取的水印可能不正确。
还有些人提出了一种通过在数据库中建立附加信息的索引表来嵌入水印的数据库水印技术[6-7]。通过改变索引表中的序列而不改变数据表中内容的值来嵌入水印。因此,在数据库中的内容不会受影响,并且在嵌入水印之后无需修改。然而,由于索引值是在数据库内容上的附加信息,如果索引值被删除或重新建立,水印有可能是错误的或可能会完全消失[8]。
为了解决上述问题,本文所提出的方法是,通过使用FP-tree的数据挖掘来保护数字决策数据库中的重要列,从而过滤掉受保护列和其他列之间的关系。在许多用于数据挖掘技术的方法中,FP-tree的数据挖掘在实际运行中已经显示出高水平的效率。因此,FP-tree技术已成为最常见的数据挖掘方法。FP-tree的数据挖掘技术主要统计数据库中列的出现次数[9]。列出现的次数越多,说明越重要。我们需要做的就是选定重要的列,建立一个树形结构以防止多次扫描、节省时间[10]。
接着,在SVR中,通过FP-tree的数据挖掘中所选择列的值来计算保护列的预测值。通过预测值和原始保护列之间的差异,以及回归差值扩展(RDE),将水印嵌入保护列中。该方法的优点在于区分有数字水印的数字数据库和原始数据库之间的微小差异[11]。因此,该方法可确定决策数据库中的值是否已被恶意篡改,并确定已被篡改的列。相反,如果嵌入有水印的数字决策数据库没有被篡改,则列中的值可以恢复为具有RDE的原始值。这种方法具有非常好的检出率。
1 解决方案
在该方案中,通过使用FP-tree的数据挖掘改进了数据库表中重要特征。然后,将挖掘结果中受保护字段的相关重要特征进一步由SVR来预测保护。因此,可以计算每条记录中保护字段的预测值和原始值之间的差。另一方面,DE是一种可逆的隐藏方案。提出了基于DE可逆水印的基本方法来选择嵌入目标值。通过这个目标值和最低有效位(LSB)的替换方式,将结果更新到表中。所提出的技术方案如图1所示。
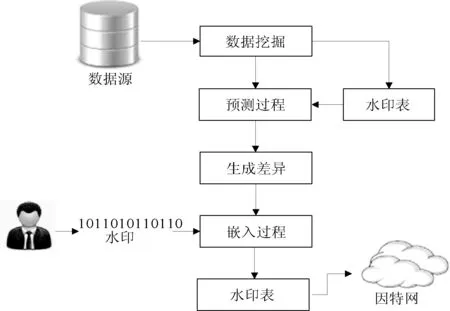
图1 SVR培训和嵌入程序图
1.1 FP-tree 特征挖掘
在开始阶段,原始数据库O的重要特征是选择使用FP-tree的数据挖掘技术。FP-tree结构可以找出受保护属性的关联特征。首先,计算特征的数量。其次,为频繁属性创建树形结构。
步骤1计算每个属性值的频率。
步骤2为数据库O构建FP-tree。
表1是在超市中交易表的例子;编号列表示不同购买者;购买项目代表交易数据;频繁项使用统计后的支持度阈值方法进行过滤。假设最小支持度阈值为3。支持度模式为a,其中a表示一组项目,是包含在事务数据库中的事务数目。

表1 事务表的例子
例如,集合收集频繁项如下:
<(a:3),(b:3),(c:4),(d:1),(e:1),)(f:4),(g:1),(h:1),(i:1),(j:1),(k:1),(l:2),(m:3),(n:1),(o:2),(p:3),(s:1)>,在该集合中,c表示特征,数字4表示支持度。此购买项目的订单很重要,因为树的每个路径都将遵循此顺序。频繁项会通过最小支持度阈值过滤。
首先,会对事务数据库进行扫描导出一个频繁项的列表。其次,会对一个空的树创建根值。在编号1中插入这些频繁项目集合<(f:1),(c:1),(a:1),(m:1),(p:1)>得到如图2(a)所示的树。在编号2中插入这些频繁项目集合<(f:1),(c:1),(a:1),(b:1),(m:1)>得到如图2(b)所示的树。由于在路径(f,c,a,m,p)中存在频繁项目(f,c,a),所以频繁项目列表中的每个节点的数目就增加1,新创建的(b:1)节点就作为(a:2)的子节点链接。
在编号5中插入这些频繁项目集合<(f:1),(c:1),(a:1),(m:1),(p:1)>得到如图2(c)所示的树,并构造最终的FP-tree。
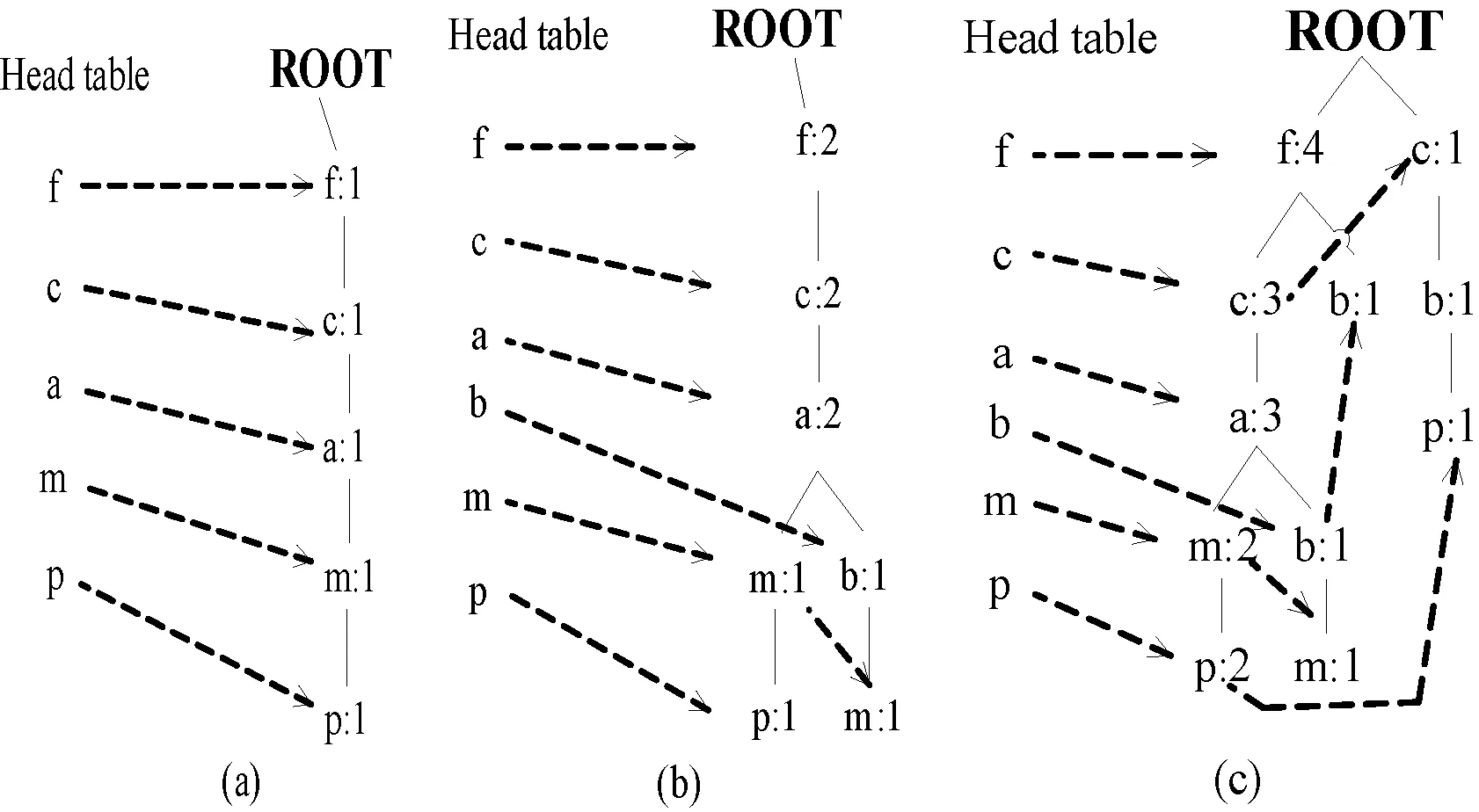
图2 集合收集频繁项目顺序图
1.2 SVR训练算法
在上述理论基础上,FP-tree中的属性存储在表X中。接下来,表X中的重要特征被选择用于训练过程。使用SVR可以涉及训练样本,并从SVR获得训练函数f(Y)。
输入:数据库O和表X与属性A1,A2,…,Ag;
输出:训练后的SVR函数f(Y)。
步骤1使用表X中的属性来预测数据库O中的受保护属性。训练数据集T可以表示为:T={sj|sj={A1,j,A2,j,…,Ag,j},j=1, 2,…,n}。其中:sj被定义为数据库O中的第j个选择的训练元组。
步骤2通过使用训练元组T来训练SVR模型以获得SVR函数f(Y)。
1.3 数据库水印的嵌入
在这个阶段,对于数据库O中的受保护目标属性U,提出在水印嵌入过程使用数据库O和SVR预测函数f(Y)中的目标属性U使用差值扩展(DE)来嵌入水印。水印W可以被分成1-LSB位,2-LSB位或3-LSB位,用于嵌入到修改后的U中。
输入:数据库O,经过训练的SVR函数f(Y)和水印W;
输出:嵌入到数据库O′。
第一步将目标值Ui与训练的SVR函数值f(yi)进行比较。如果Ui小于f(yi),则定义di=f(yi)-Ui,并且转到第二步;否则定义di=Ui-f(yi)并转到第三步。实验数据假定Ui为16,f(yi)为7,则di为9。
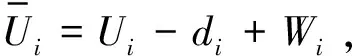
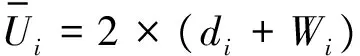
第四步重复第一步至第三步,直到所有的水印信息都嵌入到数据库O中,并获得水印数据库O′。
1.4 数据库水印的提取
在我们提出的方案中,为了验证数据库的内容,通过数据挖掘可以发现重要的特征,并且使用SVR来预测f(Y)。我们使用DE的概念从受保护的目标值中提取嵌入的水印。并获得水印和目标值。如果水印已经被破坏,则该数据库被篡改。否则,数据库将显示原始值。数据库水印提取的过程如图3所示。
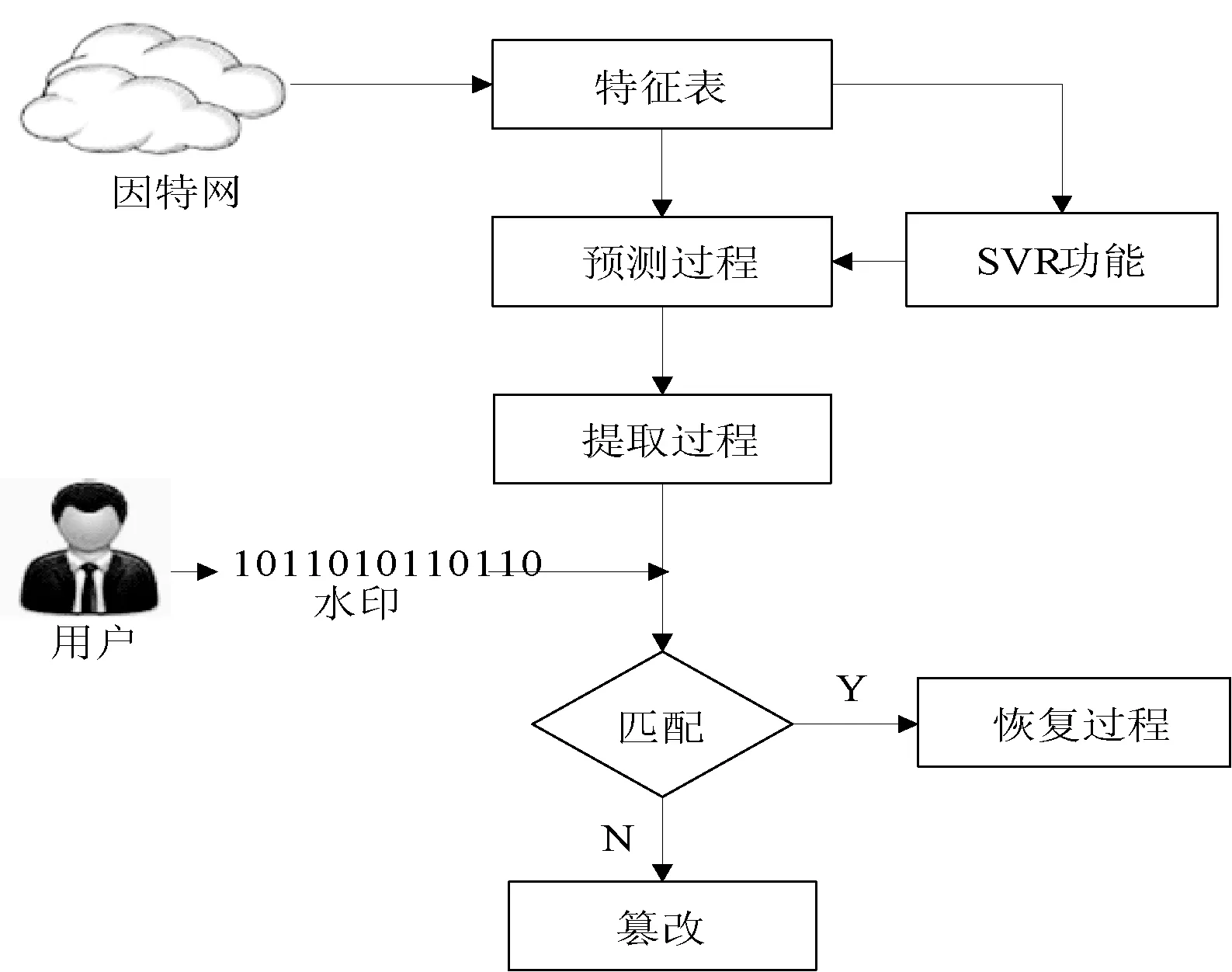
图3 检测与恢复过程图
输出:怀疑的水印W′。
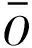
第二步训练SVR模型通过训练元组集T′获得SVR函数f(Y)。
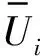

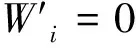
第七步将提取的水印和原始水印进行比较,以确定数据库是否被篡改。
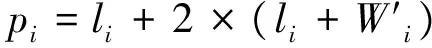
2 实验结果与分析
在实验结果中,两个不同的数据库虹膜(Iris)和鲍鱼(Abalone),被用作测试数据库。其中第二个鲍鱼是使用FP-tree数据挖掘进行测试。使用FP-tree数据挖掘方法可以极大提升检出率。
采用的SVR工具是LIBSVM。虹膜数据库有150个元组和5个属性。训练参数包括可平衡参数C(C=3)和最小拟合误差ε(ε=0.1);训练元组的数目为150。这些属性包括:萼片长度、萼片宽度、花瓣长度、花瓣宽度和类别。实验结果如表2所示。

表2 改装“Iris数据库”的实验结果
鲍鱼数据库的元组数为4 096,有8个属性。属性包括:性别、长度、直径、高度、整体重量,、脱壳重量、脏器重量和壳重。平衡参数C(C=3)和最小拟合误差ε(ε=0.1),训练元组数为1 000。实验结果如表3所示。
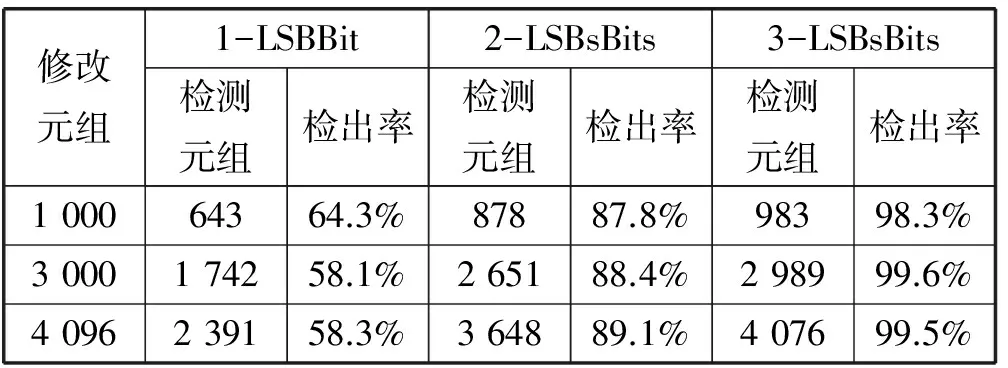
表3 改装“Abalone数据库”的实验结果
由表2、表3的结果得出,在Abalone数据库的中,嵌入1-LBS的水印平均检测率为58.5%;嵌入2-LBS的水印接近88%;嵌入3-LBS的水印接近98.8%。与Iris数据库相比,它在元组复杂度提高26倍的情况下,依然大大提升了检出率(参见图4)。

图4 实验结果对比(以2-LSBsBits为例)
为了对比使用FP-tree前后对数据库防篡改的实际效果,作者对虹膜和鲍鱼两个数据库O1和O2分别实施了两组对照实验。我们关注三个指标的对比分析:
检测率 = 成功检出的篡改数量/总篡改数量
误报率 = 误报为异常的数量/总事件数
漏检率 = 漏报未检出的篡改数量/总事件数
我们人为制造对目标数据库的篡改,对两个数据库进行了多组实验测试,选取两组典型测试数据,第一组数据为使用了FP-tree算法训练,第二组数据未使用FP-tree算法训练,两组的操作总数均为100次,实验结果如表4、表5所示。

表4 虹膜数据库O2的实验结果

表5 鲍鱼数据库O2的实验结果
在实验结果中,两个不同的数据库两组对照实验数据对比非常明显,在虹膜数据库中,应用了FP-tree算法的检测率提升12.25%,误报率降低2%,漏检率降低8%。在另一组鲍鱼数据库的实验结果中,应用了FP-tree算法训练的实验结果较比未应用FP-tree算法的实验数据检测率提升22.12%,误报率降低1%,漏检率降低7%。
这意味着几乎所有被篡改的数据都可以被成功检测和定位。实验结果表明,上述提出的方法确实可以保持数据库内容的完整性。值得注意的是,通过前面的数据挖掘,我们可以减少SVR在后续步骤中的训练时间。假设数据维度是相当高的,我们要找出重要的特征。可以先在数据没有被篡改的情况下,建议通过程序来恢复原始值。在恢复过程中,可以通过预测值和li来获得原始的目标属性。总的来说,恢复数据库的内容是这个新方法中最重要的特征。它可以有效地降低管理成本。
3 结 语
在本文中,我们提出了一种基于SVR预测的可逆水印算法,该算法使用FP-free的数据挖掘方法,用来验证数据库的内容。首先,使用FP-free关联规则挖掘重要特征,关联规则将会选择最相关的一个数据。此数据的特征将被用于SVR的预测,这种方法的主要目的是为了防止在SVR预测期间维度很高时,训练时间会变得太长。因此,通过关联规则的挖掘,该方法可以大大减少因SVR训练造成的时间浪费。在计算SVR预测与原始值之间差异时,我们可以使用DE方法作为嵌入数字水印的基本概念。如果数据库受到攻击并被恶意篡改,则SVR预测值可能会产生差异;我们可以用这种方法提取水印,然后计算和定位被攻击的记录。在不被攻击的情况下,可以通过提取水印来恢复原始数据库。
[1] 王奎,孙天凯,丁宾.脆弱水印技术在关系数据库保护中的应用研究[J].福建电脑,2012,28(11):16-17.
[2] 周飞,赵怀勋.基于混沌的DCT域关系数据库水印算法[J].计算机应用研究,2012,29(2):786-788.
[3] 高领云.关系数据库脆弱性数字水印技术的研究[D].湖南:湖南大学,2013.
[4] 刘芳,汪玉凯.一种基于差值直方图平移的多层可逆水印算法[J].计算机应用与软件,2014,31(1):303-307.
[5] 刘瑞.可逆水印技术及其在加密域的研究算法[D].北京:北京交通大学,2015.
[6] 陈进东,潘丰.基于在线支持向量回归的非线性模型预测控制方法[J].控制与决策,2014(3):460-464.
[7] Clarke S M,Griebsch J H,Simpson T W.Analysis of Support Vector Regression for Approximation of Complex Engineering Analyses[C]//ASME 2003 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference.American Society of Mechanical Engineers,2005:1077-1087.
[8] Choi W Y,Choi D H,Cha K J.Robust estimation of support vector regression via residual bootstrap adoption[J].Journal of Mechanical Science & Technology,2015,29(1):279-289.
[9] 李少华,吕志旺,车德勇,等.基于有序FP-tree的最大频繁项集挖掘算法[J].东北师大学报(自然科学),2016,48(2):65-69.
[10] 吴倩.基于压缩FP-tree的频繁项集快速挖掘算法研究[D].上海:华东理工大学,2015.
[11] 付冬梅,王志强.基于FP—tree和约束概念格的关联规则挖掘算法及应用研究[J].计算机应用研究,2014,31(4):1013-1015.
REVERSIBLEDATABASEWATERMARKINGTECHNOLOGYBASEDONSVRPREDICTION
Long Xiaoquan
(ChinaMobileInternetCompanyLimited,Guangzhou510640,Guangdong,China)
The association rule of FP-tree (frequent pattern tree) uses data mining algorithm to determine the relationship between protected property and other databases. SVR (Support vector regression) method is used to predict each protected attribute value. We propose a method to detect whether the database has been tampered with by embedding the important feature of the original database. By comparing the difference between original and predicted values of the DE (difference expansion), the database administrator can embed digital watermark in a protected database. If the protected database is distorted, it is still possible to predict the protection value under the SVR function. In this paper, FP-tree mining method is used to reduce the training time of SVR. If the database has been tampered with, we can extract the watermark from the protected database to verify and locate the tampered tuples and restore the original attribute value. If the database is not under attack, we can also use the protection of database watermarking. Therefore, the database can effectively verify the integrity of the database and protect the security of the database.
Database watermarking Difference expansion Support vector regression FP-tree mining
2016-11-05。龙晓泉,硕士,主研领域:数据库技术。
TP3
A
10.3969/j.issn.1000-386x.2017.12.012
