基于效用函数度量的多维效用关联规则挖掘
2018-01-03王仲君杨文芳
王仲君 杨文芳
(武汉理工大学理学院 湖北 武汉 430700)
基于效用函数度量的多维效用关联规则挖掘
王仲君 杨文芳
(武汉理工大学理学院 湖北 武汉 430700)
传统的多维关联规则挖掘过程通常以规则出现的频率来判定规则的有效性,并以支持度与置信度作为度量标准。这种挖掘方法只考虑规则间的统计相关性,忽略了规则自身的语义重要性,即规则能够为商家带来的期望效益。因此在多维关联规则挖掘过程中,引入效用函数作为统计相关性与语义重要性的综合度量指标。效用函数主要从潜在机会、购买概率、期望效益三个方面来度量规则的有效性,潜在机会与购买概率表示统计相关性,期望效益表示语义重要性。结果表明,以效用函数作为度量挖掘出的规则既符合客观上要求的较高频率,又具有主观上期望的较高效益。
效用函数度量 语义重要性 统计相关性
0 引 言
关联规则作为数据挖掘中最重要的一个分支,最早是由Agrawal在分析市场购物篮数据时提出[1]并用于描述商品间的关联性,现已被应用于网络日志分析、网络安全等多个行业。随着互联网行业的快速发展,海量数据使得挖掘的难度增大。因此,近年来,人们越来越多地关注从多个维度对关联规则进行挖掘,即多维关联规则挖掘。
Kamber等最先提出将数据立方体应用于关联规则挖掘中,他认为数据立方体可以利用数据仓库的结构预先计算聚集值,从而提高挖掘速度[2];Imielinski等提出将联机分析处理技术与关联规则挖掘共同应用于模式识别中[3];Messaoud等提出针对用户需求将度量一般化,不再局限于计数度量[4];Bawane等提出在多维关联规则挖掘中将OLAP技术与Apriori算法相结合[5]。国内相关的研究有胡孔法、陈崚等提出在挖掘过程中数据立方体的存储与物化问题[6];王颖等提出通过减少扫描数据库次数、降低候选项集计算复杂度以及减少预剪枝步骤计算量等途径改进Apriori算法的执行效率[7];李海磊等提出一种数据两方垂直分布条件下,结合数据立方体技术的多维关联规则挖掘算法[8];Lee提出基于效用函数对关联规则进行挖掘[9]。虽然国内外关于多维关联规则挖掘的相关研究较多,但是,这些研究基本都是基于频率来判定规则的有效性,考虑规则在统计学意义上的相关性,而忽略了规则能带来的期望效益。
关联规则挖掘的目的在于将挖掘出来的规则应用于实际的决策之中,因此本文在对多维关联规则挖掘的过程中,综合考虑规则的潜在用户、购买概率、期望效益三个指标,定义效用函数度量作为判定规则有效性的重要指标。效用函数度量是关于支持度置信度的函数,不仅考虑统计相关性因素来判定规则的客观有效性,而且引入语义重要性因素来判定规则的主观适用性,是对传统度量方法的提升与改进,使得挖掘出的规则能够从实际意义上为决策者提供决策依据,这种规则称为效用关联规则。
1 效用函数度量及多维效用关联规则挖掘Apriori算法
本文在对不同客户群体的消费行为进行分析时,首先利用RFM模型对客户价值进行分类,随后通过定义效用函数度量作为判定规则有效性的标准,在此基础上结合Apriori算法对多维数据模型中存在的效用规则进行挖掘。
1.1 RFM模型


表1 RFM模型客户分类标准
可以看出,通过RFM模型对客户分类过后,决策者可以针对不同的客户群体制定不同的营销策略,一方面提高营销策略的成功率,另一方面可以节约成本。因此,本文在对客户价值进行分类之后,对每一类客户的效用规则进行挖掘。在挖掘过程中,通过构建基于潜在客户、购买概率、期望效益三个指标的效用函数度量,以效用函数度量作为规则有效性的判定标准。
1.2 效用规则度量与多维效用关联规则挖掘
在传统的关联规则挖掘过程中,置信度与支持度是判定规则有效性的重要度量标准,支持度的大小可以判定模式是否为频繁模式,再以置信度的大小判定频繁模式是否能生成有效规则。这种挖掘方式依赖于模式出现的次数,充分考虑规则的统计相关性,能挖掘出频繁出现的模式并生成规则。然而,这种方式容易忽略出现频率小但具有高效益的规则。因此,本文引入效用规则的概念,综合考虑规则的统计相关性与语义重要性的效用函数度量作为规则有效性的判定标准,将效用函数度量值大于最小阈值的规则定义为效用规则。
(1) 支持度与置信度度量
在传统关联规则挖掘中,只有支持度与置信度同时大于最小阈值的模式才能作为频繁模式被挖掘。在统计学意义上,支持度与置信度表示的是两种概率,关联规则R:{X,Y⟹Z}的支持度表示的是模式(X,Y,Z)同时出现的概率[11],置信度Conf表示的是(X,Y)的客户群中选择产品Z概率。其计算公式如下:

(1)

(2)
其中:当X、Y两个维度都是关于客户时,|D|表示总的客户数,C(X,Y)表示X、Y代表的群体的总人数,C(X,Y,Z)表示该群体中购买Z产品的人数。
这种度量值的计算方式只考虑到统计意义上的强相关性,忽略了模式的语义相关性,即将生成的规则应用于商业营销之后能够给商家带来的效益值。因此,本文提出效用函数度量的概念,综合考虑规则的统计相关性和语义重要性来判定规则的有效性。效用函数度量是关于传统的支持度和置信度度量的修正函数,在考虑了传统的支持度和置信度度量的基础上,又进一步考虑规则可能会给商家带来的期望效益。
(2) 构建效用函数度量
效用函数大多数时候是用来表示消费者在消费中所获得的效用与所消费的商品组合之间数量关系的函数,以衡量消费者从消费既定的商品组合中所获得满足的程度[12]。本文中,将效用函数表示为商家在销售活动中获得的效用,主要从潜在机会、购买概率、期望效益三个方面来定义,多维关联规则R:{X,Y⟹Z}的效用函数度量U(R)表示为:
U(R)=Opp(R)×Prob(R)×Eff(R)
(3)
其中:潜在机会OPP、购买概率Prob代表统计相关性。潜在机会是指可以应用营销的对象数,即规则对应的潜在客户数量:
Opp(R)=|D|×sup(X,Y)-|D|×sup({X,Y⟹Z})
(4)
购买概率是指当企业向某客户群体推销产品时,该产品会被接受的概率值,可以用现有购物篮数据中的经验概率代替:

(5)
规则产生的期望效益代表语义重要性,期望效益是指规则对效益值的影响,在零售业中可以表示为交易额的增加量,可以定义为:
Eff(R)=AVG(qty(Z,Ti))×price(Z(Ti))=
AVG(qty(Z,Ti))×price(Z)
(6)
最后得到规则的效用函数为:
U(R)= (sup(X,Y)-sup{R})×conf({R})×
|D|×AVG(qty(Z,Ti))×price(Z)=
AVG(qty(Z,Ti))×price(Z)
(7)

效用函数一方面与传统的支持度和置信度度量紧密相关,另一方面又充分考虑了规则可能会给商家带来的期望效益,使得挖掘出的规则不仅能在客观上保证模式的频繁性,同时也能在主观上保证了规则的实用性。因此,这种计算方式比传统方法中只考虑规则出现的次数更加合理。
1.3 多维效用关联规则挖掘
多维效用关联规则挖掘同样以联机分析处理技术OLAP为依托,首先在Java中的开源项目Mondrian中构建多维数据模型,然后利用MDX查询语句计算数据立方体中聚集值C(X,Y,Z)并存储,最后利用OLAP技术对数据立方体中的聚集值进行查找计算[14]。
在用Apriori算法挖掘时,不再用传统的支持度计数进行剪枝,而是对购买概率为0或者1的规则进行剪枝,因为当Prob=0或Prob=1时,规则的效用U(R)=0。由于算法过程中不考虑用计数值C进行剪枝,而是根据人群购买产品的概率,因此,本文忽略频繁一项集的生成过程,直接对以职业或客户价值类别维度与产品维度组合产生的候选2-项集(Vi,Pk)与(Rj,Pk)进行挖掘。
具体步骤为,第一步:生成候选集C2,将各个维度的属性值作为2-候选集的子集;将Prob≠0且Prob≠1的项集放入频繁2-项集F1。第二步:进行循环迭代,根据(k-1)-频繁项集生成k-候选集,再根据k-候选集生成k-频繁项集。第三步:将效用值大于最小效用值阈值的频繁项集生成多维效用关联规则。具体算法如下。
算法名称:多维关联规则挖掘算法
输入: 数据立方体C,V,M,P,min_sup,min_uti
输出:L
1. k=1,L=φ
2. C2={(Vi,Pk),(Rj,Pk)},
3. foreach A∈C2,if prob(A)≠0&prob(A)≠1 then F2=F2∪{A}
4. while F2≠φ
k=k+1
Ck=Fk-1×Fk-1
foreach A∈Ck,
if prob(A)≠0&prob(A)≠1
Fk=Fk∪{A}
foreach B∈Fk,
if uti(B)>min_uti(B)
L=L∪{B/P⟹P}
end
Vi、Rj、Pk分别表示职业、客户价值、产品维度的属性值。其中,在生成Ck的过程中,Fk-1×Fk-1表示将Fk-1中满足一下两个条件的项集联合:① 有k-2个相同项集;② 不相同的两个项集分别属于不同的维度。如:{V5,M12},{M12,P28}可以联合生成{V5,M12,P28},而{V4,M12},{V5,M12}联合生成的{V4,V5,M12}不能作为候选集,因为,V4、V5属于同一个维度。
在效用关联规则挖掘过程中,利用购买概率对效用函数的影响进行剪枝,通过剪枝策略可以有效地减少数据立方体的扫描次数,从而降低算法复杂度。将效用值作为规则的度量标准,可以使挖掘出的规则更加能满足决策者的需求。
2 实证分析
本文的实证部分以购物篮数据为例,对不同客户群体的消费行为模式进行挖掘。对比分析以支持度与置信度为度量的传统方法和以效用函数度量作为标准的改进方法的计算过程以及挖掘结果。
2.1 数据背景
本文以某商场6年来547名忠实用户的购买记录作为数据,共计18万条,该数据是在”数据堂”网站上购买获得。在挖掘之前,首先通过RFM模型对大量的客户进行分群。由于不同职业的人群在购买行为上有较大的差距,并且RFM模型在对客户分类时只考虑客户的消费行为,而忽略了其他信息,所以根据数据特征,增加职业维度,将不同价值的客户群根据职业的不同再进行细分,使得挖掘出的规则更具准确性和针对性。
在购物篮数据挖掘过程中,购买量和销售额始终是人们关注的重要指标,是用来判定规则有效性的主要标准,该数据中各产品总销售额与总销售量占比如表2所示。
表2各产品总销售额与总销售量占比

表2对比显示了数据中28种商品各自的购买量amount和销售额cost分别在总交易数量和总交易额中所占的比例,气泡的大小代表比值的大小。不难发现饮料、零食和副食品这些日常的必需品总交易量占比很大,但总交易额占比很小;相反地,化妆品、珠宝首饰、皮具和手表这类非日常用品虽然总交易量很小,总交易额却比较大。
由于商品在用途上的差异导致了购买量与交易额的量级差异。然而,在用传统挖掘方法对关联规则挖掘的过程中,只是以购买概率作为度量值计算基础,这就导致在挖掘过程中在很大程度上受到交易量的影响,而忽略了交易额这一重要信息与潜在用户数量。因此,在对关联规则进行挖掘过程需要引入效用函数度量,使得挖掘到的规则不仅仅只受销售量这一因素的影响,还能综合考虑多种因素,具有更高的效用性,使得挖掘出的规则同时具有较高统计相关性与语义重要性。
2.2 传统方法与改进方法对比分析
传统方法在对购物篮数据处理的过程中,只考虑模式出现的次数,而忽略了模式本身的效用性,同时也忽略了商品本身存在的量级差。以购物篮数据的特点选取有代表性的部分数据,对传统的多维关联规则挖掘以及效用关联规则挖掘进行对比。为了便于分析,所取的代表性数据只涉及“一般价值客户”这一类客户,其部分购买记录如表3所示。
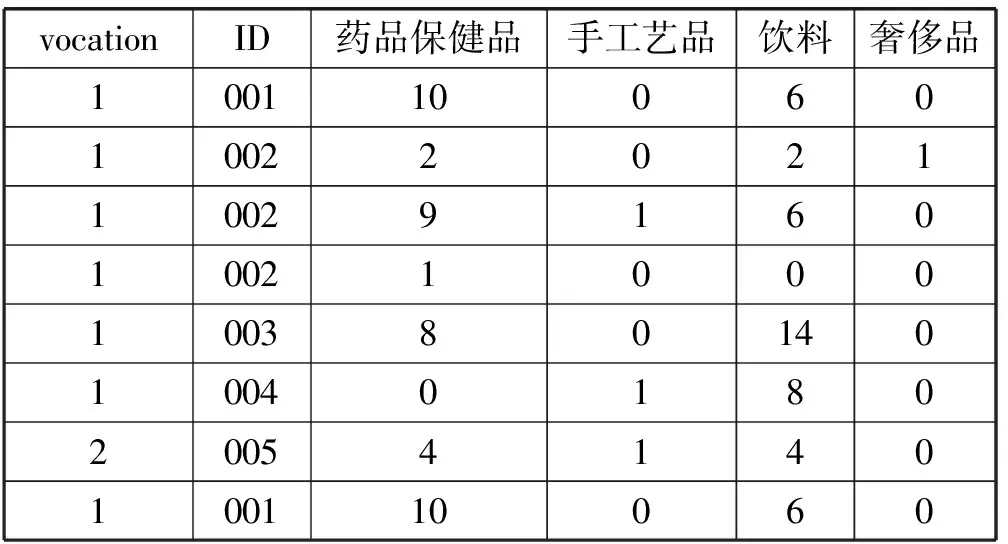
表3 “一般价值客户”部分购买数据
表3共涉及到5名“一般价值客户”。其中,4名属于第一类职业,1名属于第二类职业,表4显示的是涉及到的四类产品的平均价格。

表4 商品价格(元)
分别用传统方法与改进后的方法对规则进行挖掘,两种方法的计算过程如表5所示。

表5 传统方法与改进方法结果对比
表中R1、R2、R3、R4表示如下四种规则:
R1={一般价值客户∧vocation=1}⟹药品保健品;
R2={一般价值客户∧vocation=1}⟹手工艺品;
R3={一般价值客户∧vocation=1}⟹冲调饮品;
R4={一般价值客户∧vocation=1}⟹奢侈品。
表中,方框标出的是大于最小阈值的规则度量值。可以看出,以传统的支持度、置信度作为度量得到R1、R3为有效规则;以效用作为度量则得到R1、R4为有效规则。
对比分析用传统多维关联规则挖掘方法与多维效用关联规则挖掘方法,将两种方法挖掘出的前100条规则相关的产品进行计数,结果如表6-表7所示。

表6 改进方法挖掘结果
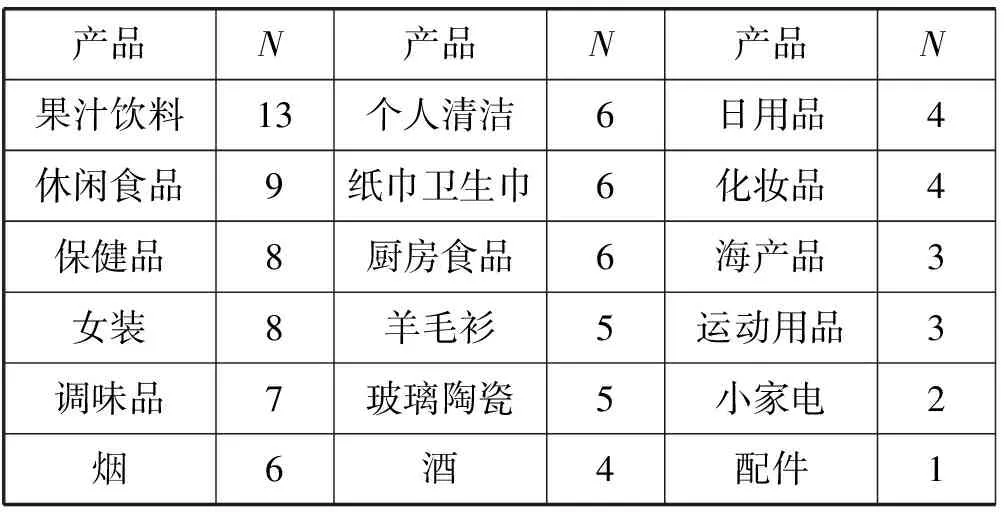
表7 传统方法挖掘结果
表中,N表示与该产品相关的有效规则的数量。结果显示,根据传统的多维关联规则挖掘方法得到的规则,大部分集中于交易量很大的日常生活用品,而根据多维效用关联规则挖掘方法在综合考虑到多方面的因素后,挖掘出的规则主要集中于奢侈品、珠宝、保健品等。其中,奢侈品交易量不高,但价格比较高;珠宝的交易量与价格在所有商品中都是属于中等水平;保健品交易量大,且价格不是很低。而饮料零食这类日用产品虽然交易量高,但是价格太低,并且由于购买概率很大、潜在客户较少,导致相关规则的效用值低于最小阈值。
传统方法在挖掘过程中很大程度上考虑模式出现的频率,这使得挖掘出的模式在客观上具有很强的统计相关性,但是在主观上并非具有很强的实用性。而改进后的方法的优点在于:
(1) 在计算C(R)的过程中(如模式R1),将用户多次购买同一个产品的行为计数为1,保证单个客户的行为不会过度影响客户群的行为模式,同时,在计算效益值Eff(R)时将购买数量求和,保证客户的特殊购买行为不会被忽略。
(2) 同时引进机会、概率两个概念对统计相关性进行度量,统计相关性不会随着购买概率的增大不断增大,因为随着购买概率的增大,潜在机会降低。如模式R3,购买率为1的同时也导致潜在客户为0的情况,说明规则适用性不强。
(3) 引进规则效益度量,使得出现频率很低而效益值很大的模式不会被忽略。如R4,由于商品自身属性不同,奢侈品的购买量很小,但是效益值很大,导致最终计算的效用度量值增大,从而作为效用模式被挖掘出来。
3 结 语
本文在传统多维关联规则挖掘方法的基础上,提出多维效用关联规则挖掘方法。在衡量规则有效性时,该方法不再以项目出现的频率作为单一标准,而是采用同时考虑项目出现频率、用户对规则主观兴趣度的综合标准。多维效用规则挖掘的核心是效用函数,本文在构建效用函数的过程中,以潜在机会、购买概率度量规则的统计相关性,以期望效益度量规则的语义重要性。
实证结果表明,通过定义期望效益对用户的主观兴趣度进行量化,能够使得出现频率不高而效益值很大的规则不被忽略;通过引进机会、概率两个概念对统计相关性进行度量,使得统计相关性不会随着购买概率的增大而不断增大;将效用函数作为规则的度量标准后,挖掘出的规则不再集中于需求量高的日用品,而更偏向于多样性产品。
多维效用关联规则的优点在于结合了商家的需求,在挖掘的过程中增加了主观兴趣因素,使得挖掘的规则不仅仅是客观有效,还能给商家提供更完善的决策依据。这种方法不仅可以应用于购物篮数据分析,还可以应用于文本数据挖掘、电信行业数据挖掘等多个领域。
[1] Agrawal R,Imielinski T,Swami A.Mining Association Rules between Sets of Items in Large Databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data,Washington,D.C.,USA:ACM Press,1993:207-216.
[2] Kamber M,Han J,Chiang J.Metarule-Guided Mining of Multi-Dimensional Association Rules Using Data Cubes[C]//Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining,Newport Beach,CA,USA:The AAAI Press,1997:207-210.
[3] Imielinski T,Khachiyan L,Abdulghani A.Cubegrades:Generalizing Association Rules[J].Data Mining and Knowledge Discovery,2002,6(3):219-258.
[4] Messaoud R B,Rabaséda S L,Boussaid O,et al.Enhanced mining of association rules from data cubes[C]//Proceedings of the 9th ACM international workshop on Data warehousing and OLAP.ACM,2006:11-18.
[5] Bawane G R,Deshkar P.Integration of OLAP and association rule mining[C]//Innovations in Information, Embedded and Communication Systems,2015 International Conference on.IEEE,2015:1-4.
[6] 胡孔法,陈崚,赵茂先,等.DHMC:一种有效的高维Cube并行分布式存储结构[J].计算机研究与发展,2007,44(12):2098-2105.
[7] 王颖.基于数据仓库的联机分析处理探讨[J].教育教学论坛,2014(38):239-240.
[8] 李海磊,王晗,孔令富,等.一种基于数据两方垂直分布的多维关联规则挖掘算法[J].计算机应用与软件,2014,31(1):18-21,80.
[9] Lee D,Park S H,Moon S.Utility-based association rule mining:A marketing solution for cross-selling[J].Expert Systems with applications,2013,40(7):2715-2725.
[10] Hughes A M.Strategic database marketing[M].Chicago:Probus Publishing Company,1994.
[11] Tan Pangning,Steinbach M,Kumar V.数据挖掘导论[M].北京:人民邮电出版社,2006.
[12] 张尧庭,陈慧玉.效用函数及优化[M].科学出版社,2000.
[13] 张磊,夏士雄,周勇,等.基于语义相关性的关联规则挖掘研究[J].东南大学学报(英文版),2008,24(3):358-360.
[14] Rizzi S,Golfarelli M,Graziani S,et al.An OLAM Operator for Multi-Dimensional Shrink[J].International Journal of Data Warehousing and Mining,2015,11(3):68-97.
MININGMULTIDIMENSIONALUTILITYASSOCIATIONRULESBASEDONUTILITYFUNCTIONMEASUREMENT
Wang Zhongjun Yang Wenfang
(CollegeofScience,WuhanUniversityofTechnology,Wuhan430700,Hubei,China)
The traditional multidimensional association rule mining determines the validity of rules by the rule’s frequency. And it takes support and confidence as measurement standards. This mining method only considers the statistical correlation between rules and ignores the semantic importance which is the effectiveness that the rules can bring. In this paper, we introduce the utility function as a comprehensive measure of statistical correlation and semantic significance. The utility function mainly measures the effectiveness of the rule from three aspects: opportunity, probability and effectiveness. Opportunity and probability represents the statistical correlation, effectiveness represents the semantic significance. The results show that the rules mined by the utility function not only meet higher frequency of objective requirements, but also have the subjective expectations of higher effectiveness.
Utility function measurement Semantic significance Statistical correlation
2016-12-31。国家自然科学基金面上项目(71671135)。王仲君,教授,主研领域:复杂系统,数据挖掘。杨文芳,硕士生。
TP3
A
10.3969/j.issn.1000-386x.2017.12.007
