基于编译置换的指令随机化系统设计与实现
2018-01-03何红旗王奕森董卫宇朱怀东
何红旗 王奕森 董卫宇 朱怀东
(信息工程大学数学工程与先进计算国家重点实验室 河南 郑州 450001)
基于编译置换的指令随机化系统设计与实现
何红旗 王奕森 董卫宇 朱怀东
(信息工程大学数学工程与先进计算国家重点实验室 河南 郑州 450001)
指令集随机化技术是一种通过随机变换程序指令编码来抵御代码注入攻击的新型防御技术。现有指令集随机化技术还存在一定缺陷,如性能损耗大、指令数据混杂造成的编码难等。针对这些问题,提出一种基于编译置换的指令随机化技术。该技术在不降低防御效果的同时减少了随机化指令的数量,并在编译过程中实现了关键指令的随机置换,提高了指令随机化的性能和编码精确度。设计并实现了一套基于编译置换的指令随机化原型系统,验证了该技术的有效性。
指令随机化 编译置换 ShellCode DynamoRIO 指令定位
0 引 言
随着信息技术的快速发展,互联网在给人们带来便利的同时也带来了巨大的威胁。各类硬件和软件漏洞层出不穷,黑客为了获得非法利益利用漏洞对目标用户进行网络攻击,获取网络用户隐私信息并出售。因此提升软件的抗攻击性能对提升互联网的安全至关重要。根据OWASP组织在2013年公布的Web十大关键风险[1]显示,注入型攻击排名第一。代码注入型攻击是攻击者通过改变控制流来执行恶意代码从而达到攻击目的,其破坏性很大。目前最常见的代码注入型攻击为缓冲区溢出攻击(如栈溢出攻击和堆溢出攻击等)。
目前已经有很多针对缓冲区溢出攻击行之有效的防御技术。对栈溢出攻击的防御有在关键数据和缓冲区之间加入一个随机的canary字的Stack Guard防御策略及其衍生出的防御策略;构建与普通栈隔绝的全局返回地址堆栈的Stack Shield防御策略;在栈帧中引入随机长度的填充区使攻击者无法准确定位函数返回地址或调用方函数EBP的防御策略。对堆溢出攻击的防御有增加安全cookie;堆块元数据加密;动态改变堆分配算法;函数替换与指针编码等多种方法。
针对当前漏洞攻击防御技术被动、易被绕过的现状,安全人员希望研究出一种主动防御技术,能够对已知和未知漏洞进行全方位防御,随机化防御技术应运而生。随机化技术通过对程序进行部分功能等价替换,模糊程序的控制流信息、地址信息和数据信息等,功能的等价替换可以打破漏洞利用所需要的稳态环境。现有的随机化技术主要有地址空间布局随机化(ASLR)、指令集随机化(ISR)、数据随机化(DR)和操作系统接口随机化(OSIR),部分随机化技术已经在漏洞攻击防御中被广泛使用,如地址空间随机化技术已经在大多数现代操作系统中使用。
本文提出的随机化技术是一种新型指令随机化技术,与现有指令集随机化技术不同,该技术在编译阶段实现了指令的随机改变,可以在低性能损耗下防御代码注入型攻击。该技术解决了以下几个问题:
(1) 对ShellCode执行模式进行分析,选取参与指令随机化的关键指令。
(2) 在指令随机化规则的指导下,编译时对程序中的部分指令进行随机置换。
(3) 实现随机化程序的动态执行。
1 相关研究
在网络攻防中攻击者通常会利用逆向工程对源程序和程序补丁进行比对[2]来发现并利用程序漏洞,进而发动攻击;也可以通过内存泄露信息学习目标系统的防御机制并绕过[3],对目标系统作进一步攻击。1996年出现的代码注入型攻击很快成为了攻击者的最爱。为了防御代码注入型攻击,现代操作系统采用了DEP防护,通过改变内存页属性,使内存页不可同时具有写与执行属性。而随即出现的代码重用攻击[4]即ROP攻击可以成功绕过DEP防护。2010年出现了一种新型代码注入型攻击技术JIT spraying攻击, 2013年Snow等提出的新型ROP攻击技术[5],利用内存泄露信息获得目标程序内的代码布局,搜集代码片段组合成攻击代码对目标系统进行攻击,可以绕过系统的ASLR防护。内存信息泄露会对用户安全造成很大威胁,如2014年爆发的OpenSSL心脏流血漏洞[6],让整个世界的互联网陷入不安全,黑客利用内存泄漏的漏洞从服务器中获取64 KB的数据,里面可能包含用户账号、密码等敏感资源。
面对不断出现的攻击技术,防御技术也在快速发展。1997年Forrest等阐述了多样化技术的整体框架,首次提出数据随机化和代码布局随机化的思想。2000年Cowan等根据随机化所依赖的环境对随机化技术进行了分类:接口随机化技术和系统功能实现随机化技术。1996年Cowan等提出数据布局随机化技术,2002年Chew和Song利用系统调用多样化技术成功防御了缓冲区溢出漏洞攻击。2003年初次出现指令集随机化技术,该技术可以防御大多数代码注入型攻击,但会带来400%的性能损耗,同年,PaX小组提出地址空间布局随机化(ASLR)技术。2010年Georgios等对ELF文件格式的程序实现了基于动态二进制分析平台Pin的指令集随机化。2012年Giuffrida等提出了粒度更细的地址空间随机化技术[7]。ASLR技术可以防御代码注入型、代码重用型攻击,被广泛地应用在现代高级操作系统中,但可以通过内存泄露来绕过[8]。
指令集随机化技术是一种基于加密实现的随机化技术,经过国内外学者不断的研究,目前指令集随机化已经日趋成熟[9]。2003年Kc等提出了一种实现指令集随机化的思路,与RISE相似,都是对二进制机器码进行修改。2004年Boyd和Keromytis实现了SQL语言的随机化,通过利用服务器上的代理应用实现。2012年Hiser等[10]设计了基于加密的代码布局随机化技术,同一年Shioji等[11]设计了基于加密的代码地址随机化技术,可以防御代码注入型攻击和细粒度的代码重用攻击。
数据结构随机化技术也是当前研究的热点,2009年Lin等开始使用编译器对数据结构体变量进行更加细致的随机化处理;2014年南京大学的辛知等[12]展开了自动的结构体随机化工作的研究,将基于编译器的结构体以及数据分布随机化向前推进了一步;2012年Giuffrida等[7]的工作是将数据结构随机化从应用程序扩展到了内核,实现了全空间的数据结构随机化。
随机化防御技术已经得到了很大的发展,在网络安全领域发挥了巨大的作用,但仍然面临防御攻击单一、推广代价大的问题,表1为主流的几种随机化技术性能统计表。现有的指令集随机化技术可以防御大多数代码注入型攻击,但由于缺乏硬件支持,软件实现还不成熟,因此没有得到广泛的推广,但该技术的应用前景很好,具有很大的研究意义。
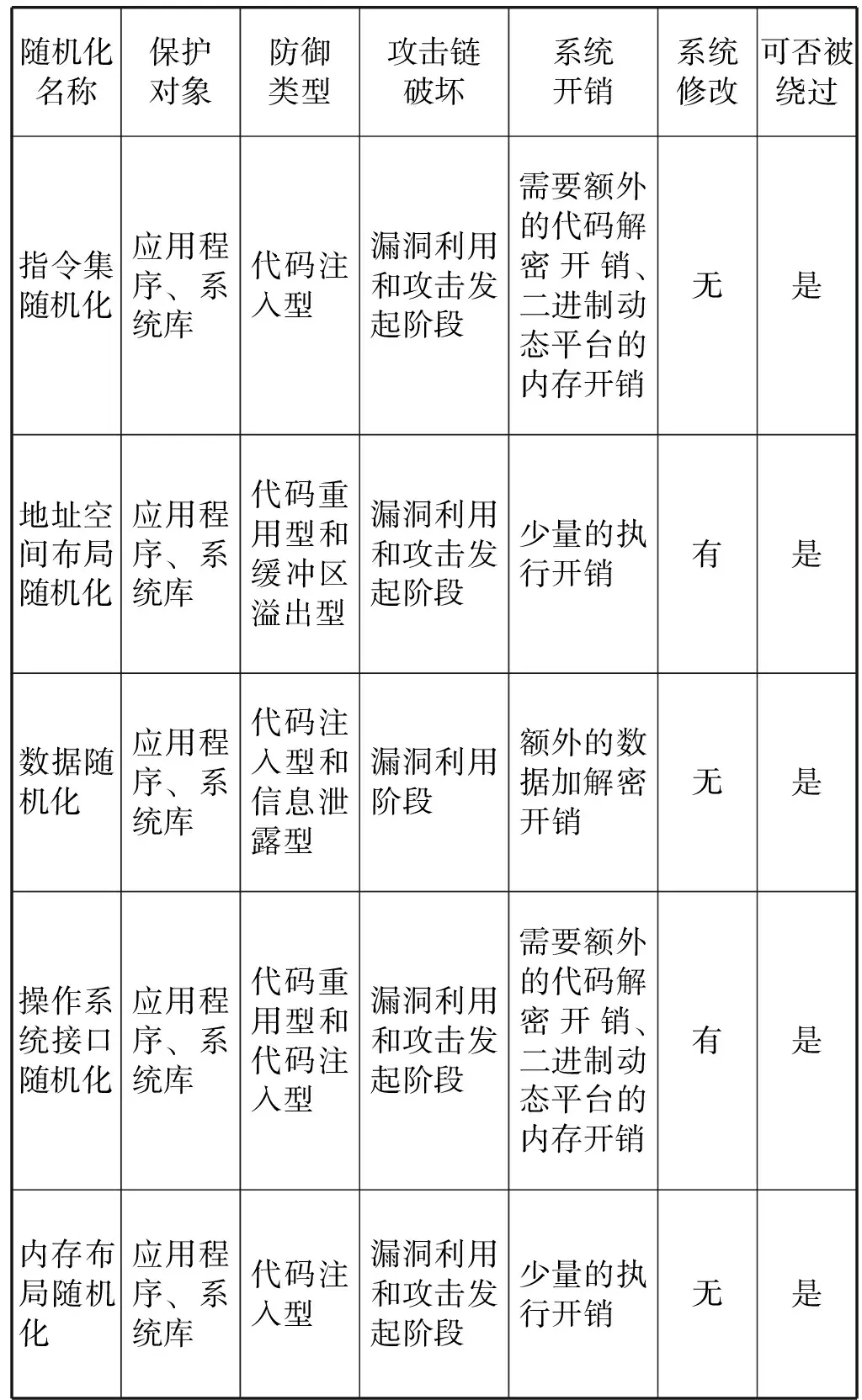
表1 随机化技术性能统计表
2 基于编译的指令置换技术
针对当前指令随机化技术存在的不足,本文提出一种基于编译置换的指令随机化技术。该技术的实现思路为在程序编译阶段根据随机化规则的指导对部分指令随机置换,从而达到指令随机化的目的。
2.1 Phoenix编译器框架
Phoenix是由Microsoft公司提供的一套接口开放、扩展性强的编译器框架,该框架支持多种计算机语言,可以帮助用户开发新的编译器或其他程序分析工具。Phoenix编译器通过对程序源码进行处理,将源码表示成中间表示的形式,即IR (IntermediateRepresentation)的形式,Phoenix编译器和各种基于Phoenix的工具对程序后期的处理工作都是在IR层次上进行的。Phoenix可以帮助用户完成基本块分析、内存跟踪、代码覆盖、实时编译和全系统优化等工作。图1为Phoenix编译器框架图。

图1 Phoenix编译器框架图
从框架图可以看出Phoenix有三种输入方式:CIL(Compiler Intermediate Language)、MSIL(Microsoft Intermediate Language)、PE(Portable Executable),Phoenix将这三种输入文件转换为中间表示(IR,Intermediate Representation)形式。Phoenix对外提供了一些API函数,用户可以利用这些API函数来开发分析工具(Analysis Tools)、插桩工具(Instrumentation Tools)和优化工具(Optimization Tools)。Phoenix编译器的编译阶段对外,开发人员可以在编译的不同阶段(Phases)装入自己的分析工具或编写插入自己的Phase对程序进行分析优化。最后可以根据不同的需要使用COFF Writer模块生成目标对象文件Obj文件,或用连接器Linker生成EXE文件或者DLL文件。
2.2 随机化指令筛选
指令随机化技术是通过在动态执行过程中改变恶意代码内指令的语义,使其无法正常执行,从而达到防御效果。因此,不需要对目标程序全部指令进行随机化处理,只要使恶意代码内关键指令语义发生改变即可阻止其正常执行。本文根据这一思路通过对恶意代码构成规则进行分析,选择出参加随机化的关键指令。随机化指令选择的原则是使恶意代码中指令的随机化率尽可能高,同时用户程序内指令的随机化率尽可能低,使由指令随机化带来的性能损耗保持在一个可控范围内。
通过对ShellCode执行模式进行分析,本文选取了参加指令随机化的指令186条,除了ShellCode中出现的高频关键指令,还掺加了部分程序中低频出现的混淆指令,混淆指令的添加用很低的性能损耗提升了ShellCode的随机化率。在编译阶段对指令随即改变需遵守等长置换的原则,即在指令变换过程中不能改变指令的长度。如果不等长指令置换则会造成指令不完整或覆盖相邻指令,如将 inc eax (0x40) 置换为 call eax (oxFFD0) ,导致部分指令在动态执行时无法被识别而执行失败。即使是操作码等长指令,由于指令类型不同,有些指令有操作数,有些指令无操作数,如果相互置换也会在指令执行过程中出错,如将指令 push eax (0x50)置换为jnc addr (0x73 + addr),虽然操作码指令长度相同,但这两条指令置换后动态执行时会出错。因此本文对筛选出来的关键指令按照操作码长度、是否有操作数进行了分类。表2列出了部分随机化指令信息。
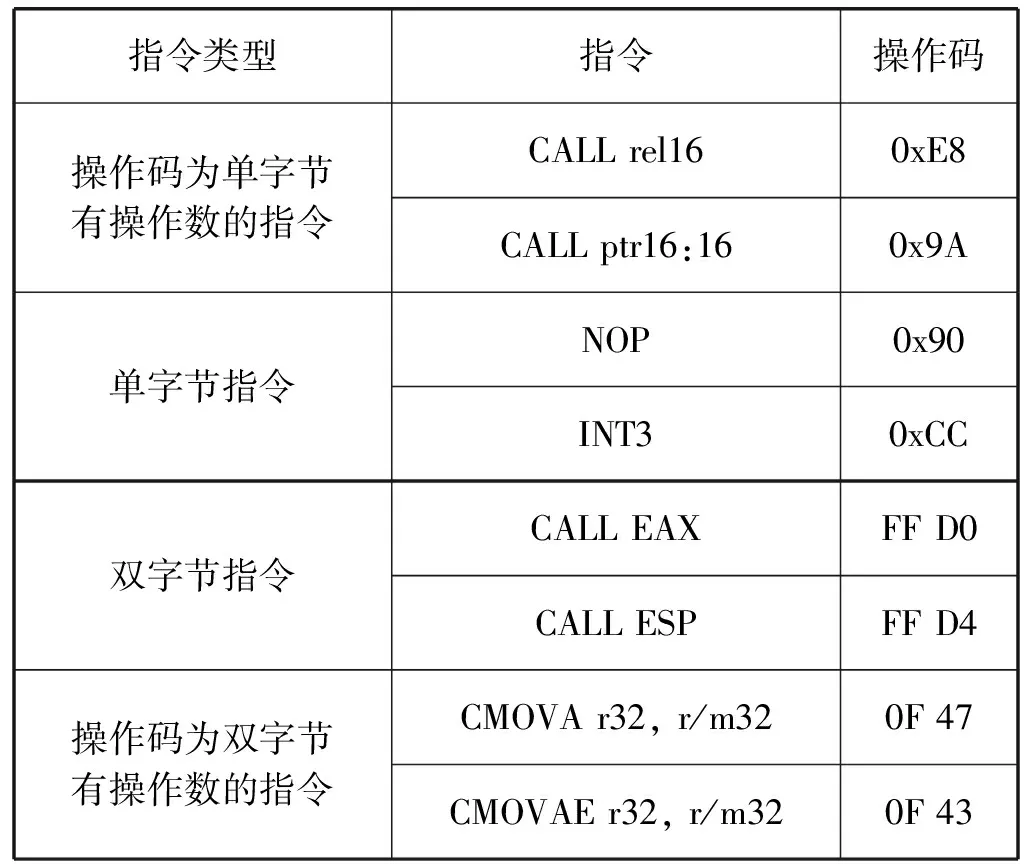
表2 部分随机化指令信息
指令随机化规则在程序编译时指导指令的随机置换,并在随机化程序动态执行时指导随机化指令的还原。规则制定需要满足两方面要求:指令变换后可以在动态执行时还原;指令变换随机。因此制定的指令随机化规则需要在等长置换的原则下对指令在不同集合下进行随机配对,变换时根据配对相互置换。
2.3 前端编译信息获取
编译器对程序编译过程中会分为不同的编译阶段(Phases),每个Phase会执行特定的功能。Phoenix将编译、优化等处理过程分成若干个Phases。Phoenix允许用户制定Phase-List并开发特定功能的Phase,在编译器下次编译程序过程中,Phoenix编译器框架会解析Phase-List并执行其中的Phase。图2为Phoenix中Phase原理图。

图2 Phoenix中Phase原理图
指令随机化规则在程序编译时指导指令的随机置换,并在随机化程序动态执行时指导随机化指令的不同编译阶段完成不同的功能。为了实现随机化分析框架的特定功能,需要在程序编译过程中加入指令分析和处理的相关工作。因此设计编译随机化PhaseList,抽取Phoenix的 C2编译器的前期处理阶段,C2编译器的前期处理阶段主要完成各种检查和编译优化工作。图3为本文构造的指令随机化PhaseList。完成编译前期阶段工作后,按照PhaseList的顺序,开始进入随机化分析阶段。可以通过phase.next与phase.previous查看当前phase的前一个与后一个phase。
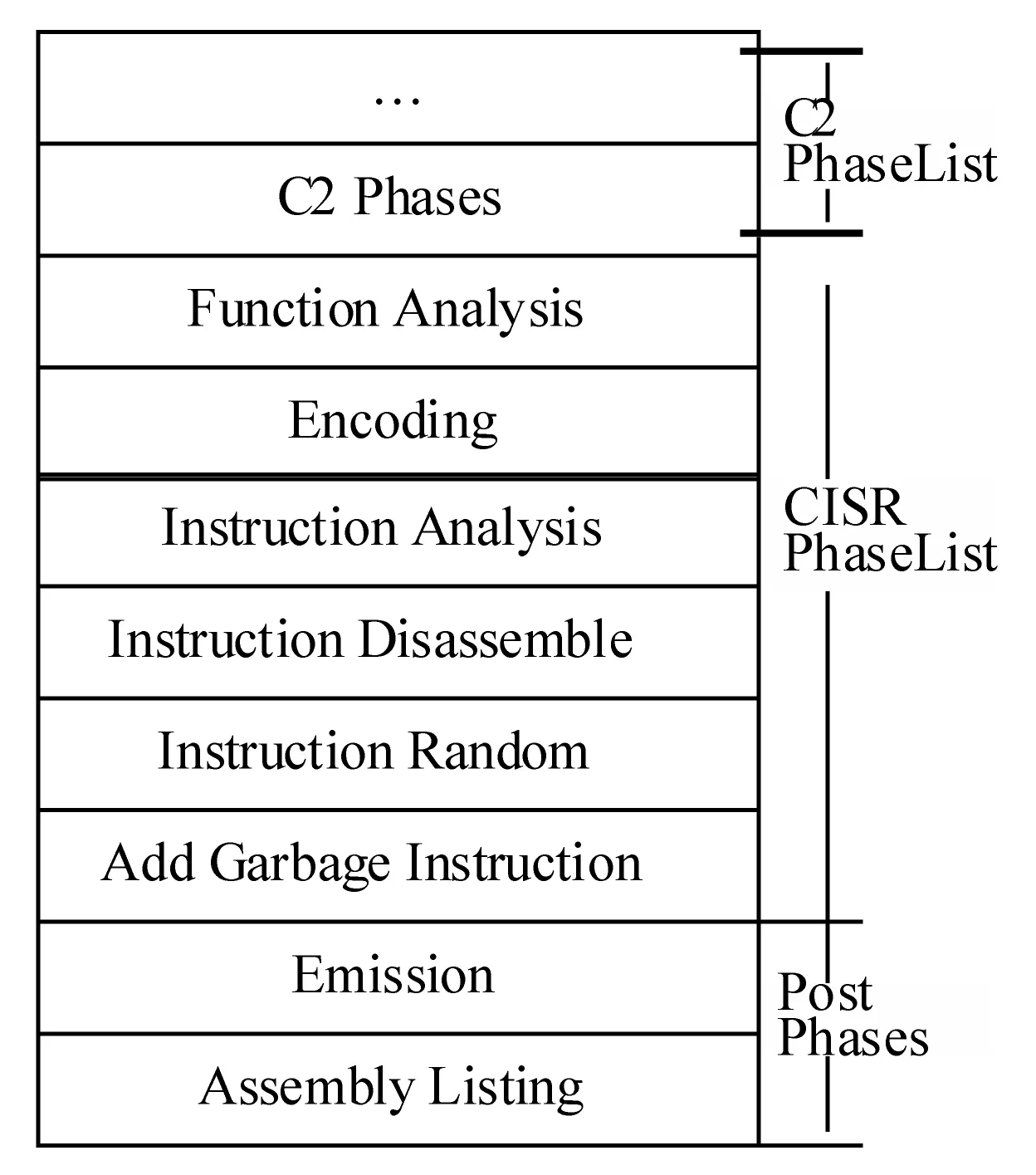
图3 指令随机化PhaseList
在指令随机化PhaseList中包含了函数单元分析、指令流分析、编码、反汇编、指令随机化和垃圾指令注入等阶段。其中函数单元分析和指令流分析是为了从编译的中间表示信息中得到指令随机化所需要的有用信息,编码、反汇编和指令随机化是指令随机化技术需要完成的工作。
2.4 指令随机置换技术
指令置换需要换的主体是指令的操作码,对操作数暂时不作处理。
定位了指令在函数单元内的偏移并得到指令操作码长度后,可以开始对指令进行随机置换。指令随机置换实现的思想是:在编译的优化阶段后,写入目标文件前根据指令在函数单元内的偏移以及指令操作码的长度提取指令的操作码,将操作码与相应的指令随机化规则遍历匹配,如果操作码在规则内则按照规则进行置换,否则读取下一条指令。指令随机化依赖的条件有:
(1) Phase在编译优化阶段后,写入目标文件前。指令的随机化工作会对指令进行改变,如果在优化阶段前进行,则改变的指令很可能被优化掉。如果编译阶段已经将机器码写入目标文件,则无法再进行指令置换。选取在Encoding阶段之后即Post-compilation phases进行,这时IR为EIR形式,即最终写入obj文件中的形式,而且在这个阶段置换指令不会被优化掉。
(2) 规则指导。指令的随机置换需要在一定的规则指导下进行,不能盲目置换,在动态执行阶段需要再次根据规则将指令还原。
(3) 指令数据分开。指令数据混合会导致数据被当做指令,使随机置换错误,只有在编译阶段才能做到指令与数据的严格分离。
(4) 指令在函数单元偏移。指令随机化需要根据指令的偏移来确定指令位置,进而进行指令的随机置换。
满足以上四点要求后,可以开始指令的随机置换。图4为指令置换阶段流程图。指令置换的流程为:首先对EncodedIR内的机器码进行反汇编,得到指令在函数单元内的偏移。根据偏移取出每条指令的操作码并与相应的规则进行匹配,即遍历规则判定操作码是否在其中,若在则进行指令置换,并将置换结果回写入EncodedIR;若不在则该指令不需进行随机化处理,读取下一条指令进行匹配,直到将函数单元内所有指令处理完,继续处理下一个函数单元的指令。

图4 指令置换流程图
2.5 随机化程序执行
经过指令随机化处理的程序在运行时需要进行指令回译,通过指令回译可以达到两方面的目的:一方面使得用户程序内被随机化的指令还原为正常指令;另一方面防止恶意代码的执行,如果攻击者向用户进程内注入恶意代码,由于该恶意代码没有经过编译期间的指令置换,则即使控制流转移到恶意代码,它也不能正常执行。
随机化指令回译需要在动态二进制分析平台上利用指令级插桩来实现,选DynamoRIO作为随机化指令回译的动态二进制平台。因为在编译阶段部分指令的语义发生了改变,只有在指令执行前将其语义还原才可正常执行,通过在指令执行前插入分析代码来判断指令是否被随机化。基于以上思想,随机化指令回译的流程为从基本块内读取一条指令,判断指令的操作码长度,并与随机化指令规则进行匹配,匹配规则分为操作码长度决定,如果遍历规则可以找到该操作码,则根据规则构造指令并置换,如果不匹配则读取下一条指令。如此循环直至基本块内所有指令处理结束读取下一基本块。图5为随机化指令回译流程图。

图5 随机化指令回译流程图
攻击者如果在程序执行期间发起攻击,注入恶意代码并劫持控制流去执行恶意代码,即使如此,攻击者也会攻击失败。因为外部注入的恶意代码没有经过前期的随机化处理,在执行时恶意代码的关键指令会被变换为一个不可预知的指令,导致恶意代码对系统攻击成功的概率降低到一个极小的值。通过对单次随机化程序执行来模拟被破坏的恶意代码的执行环境,并对执行结果做了大量统计,被随机化的指令执行结果可以分为三类:被随机化为非法指令,执行时错误;被随机化为合法指令,向下执行会进入一个死循环,或跳入一段合法代码段;其他类型的错误。图6为单个随机化指令执行时的流向图。
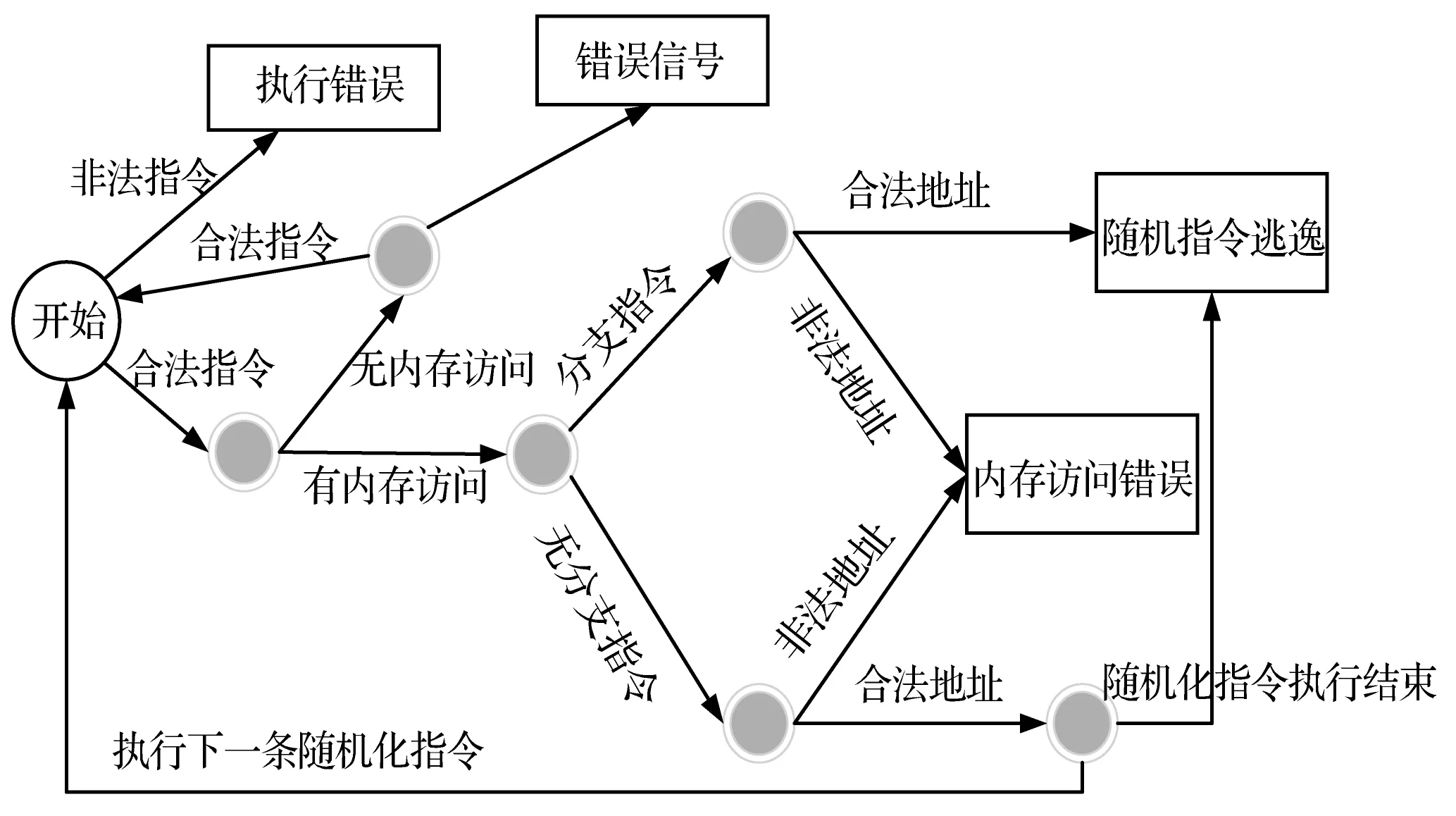
图6 随机化指令执行流向图
如图6所示,其中“随机指令逃逸”状态为分支指令跳转到进程内的可执行内存中。单个随机化指令执行时有三种流向:
1) 经过随机化处理后指令发生改变,执行时产生错误信号。定义系统对这种类型的错误信号处理为直接终止执行。
2) 经过随机化处理后的指令分支跳转,控制流转移到进程的可执行内存中,不产生错误信号。
3) 经过随机化处理后的指令依然是可执行指令,正常执行。
3 实验与分析
为了验证所提技术的有效性,设计并实现了指令随机化原型系统CIRE(Compiled Instruction Randomization Emulation)。该系统在编译阶段实现了指令的随机变换,并在DynamoRIO上执行对随机化程序,该系统可以防御绝大多数的已知和未知代码注入型攻击。为了验证CIRE系统的有效性,从ShellCode指令随机化率和防御攻击效果两个方面测试该系统的实用效果。实验环境及配置如下:
硬件环境:
• 三台PC机:攻击机、防御机和ISR实验用机
• AMD Athlon(tm) 3800+ 2.00 GHz,4.00 GB内存
软件环境:
• 操作系统:WindowsXP 32位、Ubuntu12.04 32位
• 动态二进制分析平台:DynamoRIO,Pin
• 漏洞检测工具:Metasploit 4.13
• 静态二进制分析工具:IDA 6.2
• 编译器:Phoenix、Microsoft Visual Studio 2008
3.1 ShellCode随机化率
为了增大CIRE的防御效果,同时控制由于指令随机化带来的效能损耗,根据ShellCode构造原理筛选出ShellCode常用的关键指令进行随机化,CIRE尽量使ShellCode中指令随机化比率尽量高而用户程序内指令随机化比率尽量低。为了验证该思想的可行性,抽取Metasploit 4.13下470个ShellCode进行测试。分别将470个ShellCode机器码与本文筛选出的随机化指令进行比对,统计出ShellCode内指令的随机化率,并对ShellCode进行调试,跟踪变换后ShellCode的执行,分析随机化后ShellCode的执行流向。表3为部分ShellCode随机化率测试。

表3 部分ShellCode随机化率测试
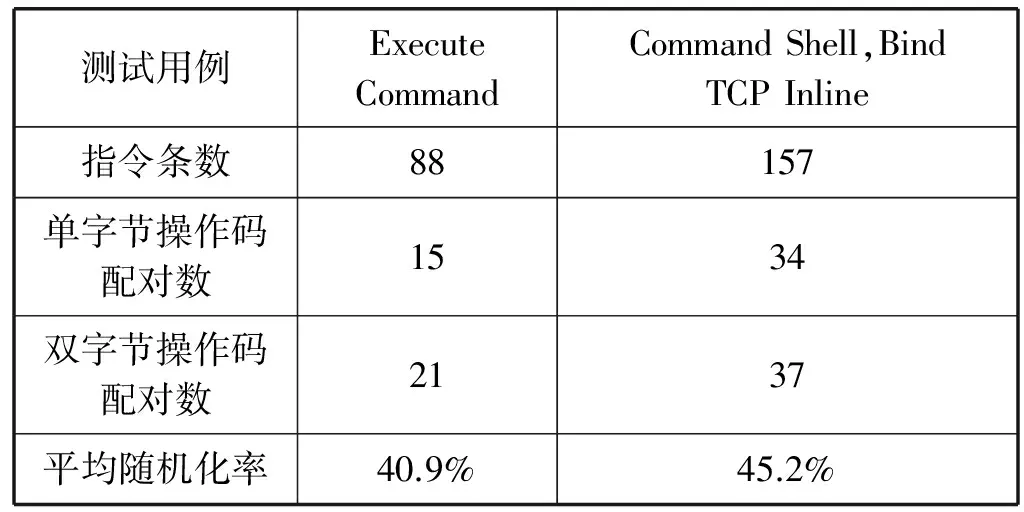
续表3
通过对470个目标ShellCode做统计,筛选出来的随机化指令使得470个ShellCode的指令平均随机化率为39%。
3.2 CIRE防御效果测试
为了验证CIRE系统防御代码注入型攻击的防御效果,选取了100个开源样本软件,并在样本程序中构造了缓冲区溢出漏洞。利用Metasploit对样本程序分别在无CIRE保护和有CIRE保护下进行攻击,每个样本攻击100次,并对结果进行统计,如表4所示。
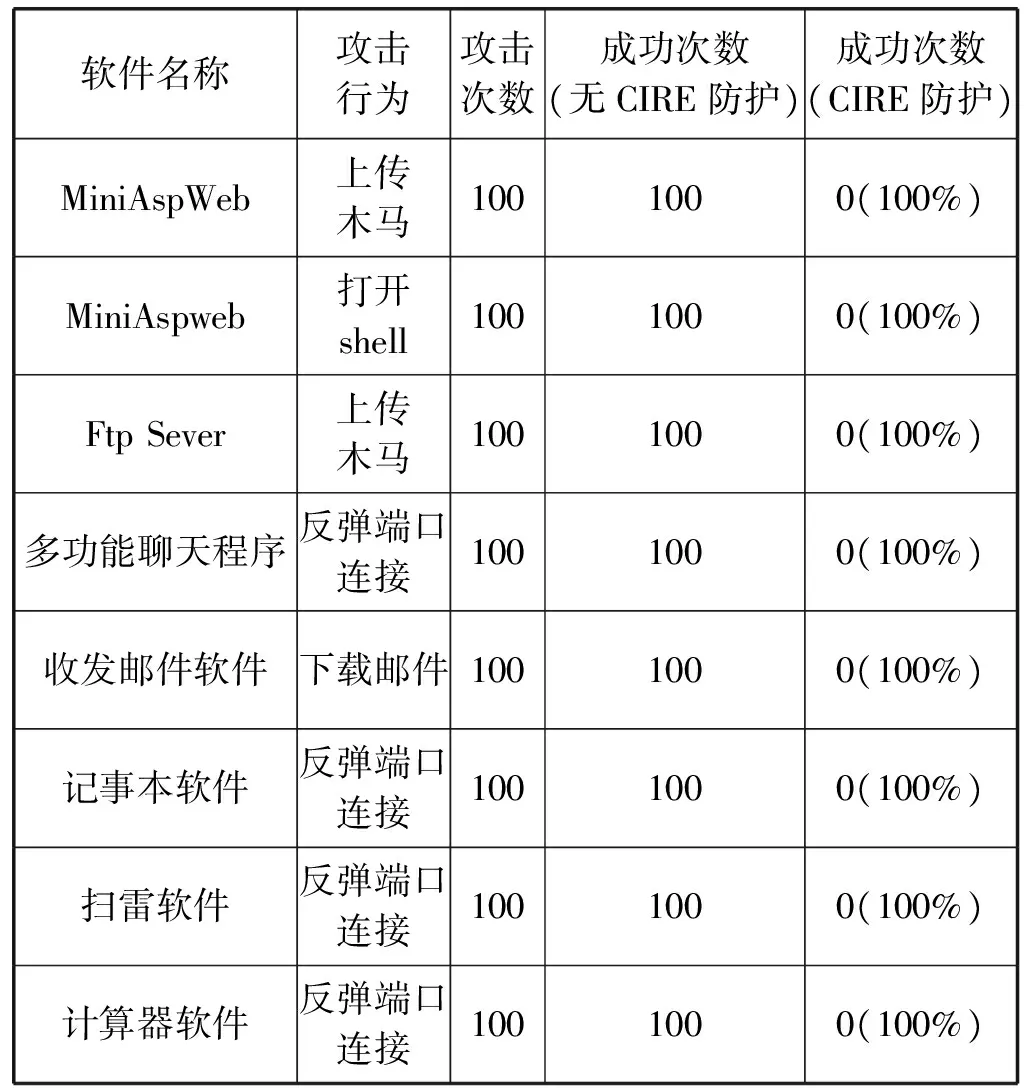
表4 CIRE防御效果部分统计表
理论上,在没有其他安全加固的前提下,对含有缓冲区溢出漏洞的程序进行攻击会100%成功,而通过指令随机化处理后,由于关键指令发生了变化,攻击会100%失败。编写自动化测试脚本,对网上搜集的100个开源Windows软件和1 000个Microsoft Visual Studio编写的程序进行测试。测试结果显示,在没有CIRE保护下,对样本的攻击成功率达到100%,而在CIRE保护下,对样本的攻击成功率为0,证明CIRE可以成功防御代码注入型攻击。
4 结 语
本文通过对传统指令集随机化技术的研究,针对其性能损耗大、安全性低及可扩展性差的缺点,提出一种基于编译置换的新型指令随机化技术。该技术在编译阶段对目标程序的部分指令在指令随机化规则的指导下进行随机置换,攻击者不了解这套指令规则,无法构造与当前指令兼容的攻击代码,该技术可以防御绝大多数的外部代码注入型攻击。并在此基础上,设计并实现了基于编译置换的指令随机化原型系统CIRE,经过大量测试,该系统可以在低开销的情况下防御所有的测试攻击,具有较高的实用性和有效性。
[1] OWASP T. Top 10-2013[EB]. The Ten Most Critical Web Application Security Risks, 2013.
[2] Coppens B, De Sutter B, De Bosschere K. Protecting your software updates[J]. IEEE Security & Privacy, 2013, 11(2): 47-54.
[3] Tang F Y, Feng C, Tang C J. Memory Vulnerability Diagnosis for Binary Program[C]//ITM Web of Conferences. EDP Sciences, 2016, 7: 03004.
[4] Davi L, Sadeghi A R. Background and Evolution of Code-Reuse Attacks[M]//Building Secure Defenses Against Code-Reuse Attacks. Springer International Publishing, 2015: 7-25.
[5] Snow K Z, Monrose F, Davi L, et al. Just-in-time code reuse: On the effectiveness of fine-grained address space layout randomization[C]//Security and Privacy (SP), 2013 IEEE Symposium on. IEEE, 2013: 574-588.
[6] Durumeric Z, Kasten J, Adrian D, et al. The matter of heartbleed[C]//Proceedings of the 2014 Conference on Internet Measurement Conference. ACM, 2014: 475-488.
[7] Giuffrida C, Kuijsten A, Tanenbaum A S. Enhanced Operating System Security Through Efficient and Fine-grained Address Space Randomization[C]// Security’12 Proceedings of the 21st USENIX conference on Security symposium. 2012: 475-490.
[8] Bittau A, Belay A, Mashtizadeh A, et al. Hacking blind[C]//Security and Privacy (SP), 2014 IEEE Symposium on. IEEE, 2014: 227-242.
[9] Sinha K, Kemerlis V, Pappas V, et al. Enhancing Security by Diversifying Instruction Sets[R]. Columbia University Computer Science Technical Reports,2014.
[10] Hiser J, Nguyen-Tuong A, Co M, et al. ILR: Where’d my gadgets go?[C]//Security and Privacy (SP), 2012 IEEE Symposium on. IEEE, 2012: 571-585.
[11] Shioji E, Kawakoya Y, Iwamura M, et al. Code shredding: byte-granular randomization of program layout for detecting code-reuse attacks[C]//Proceedings of the 28th Annual Computer Security Applications Conference. ACM, 2012: 309-318.
[12] 辛知, 陈惠宇, 韩浩, 等. 基于结构体随机化的内核 Rootkit 防御技术[J]. 计算机学报, 2014, 37(5): 1100-1110.
DESIGNANDIMPLEMENTATIONOFINSTRUCTIONRANDOMIZATIONBASEDONCOMPILINGSUBSTITUTION
He Hongqi Wang Yisen Dong Weiyu Zhu Huaidong
(StateKeyLaboratoryofMathematicalEngineeringandAdvancedComputing,PLAInformationEngineeringUniversity,Zhengzhou450001,Henan,China)
Instruction set randomization technology is a new type of defense technology that protects against code injection attacks by random transformation program instruction coding. The existing instruction set randomization technology also has some defects, such as large performance loss, mixed instruction and data can enhance the difficult of encoding. In order to solve these problems, a randomization technique based on compiler permutation was proposed. This technique reduces the number of randomization instructions without reducing the defense effect, and achieves the random replacement of the critical instruction in the compiling process, which improves the performance and coding accuracy of the instruction randomization. This paper designed and implemented compiled instruction randomization emulation based on compiling substitution and verified the effectiveness of the technique.
Instruction randomization Compiling substitution Shellcode DynamoRIO Instruction addressing
2017-02-22。何红旗,副教授,主研领域:信息安全。王奕森,博士生。董卫宇,副教授。朱怀东,硕士生。
TP309.1
A
10.3969/j.issn.1000-386x.2017.12.059
