基于序列标注算法比较的医学文献风险事件抽取研究
2018-01-03邱武松
喻 鑫 张 矩 邱武松 王 飞
1(中国科学院大学 北京 100000) 2(中国科学院重庆绿色智能技术研究院 重庆 400714) 3(第三军医大学西南医院 重庆 400038)
基于序列标注算法比较的医学文献风险事件抽取研究
喻 鑫1,2张 矩1,2邱武松2王 飞3
1(中国科学院大学 北京 100000)2(中国科学院重庆绿色智能技术研究院 重庆 400714)3(第三军医大学西南医院 重庆 400038)
医学文献快速增长,如何从医学文献文本大数据中挖掘出有价值的知识是一种巨大挑战。聚焦医学文献中定量风险语句的风险事件抽取,构建智能临床决策支持系统医学风险知识库。运用序列标注算法中重要的隐马尔可夫模型、最大熵马尔可夫模型和条件随机场三种模型分别对医学文献非结构化全文文本中风险事件信息进行抽取,并对算法进行比较。从三个模型平均F1测度值来看,条件随机场效果最好,其次为最大熵马尔可夫模型,然后是隐马尔可夫模型,但是每个模型都有自己对某些风险事件抽取的准确率或者召回率的优势。
医学文献 风险事件 隐马尔可夫模型 最大熵马尔可夫模型 条件随机场
0 引 言
随着生物技术的发展,生物医学文献呈现出爆炸式增长的趋势,美国国家医学图书馆的PubMed医学文献检索系统中收录的文章每年都有较大幅度增长,本文实验中所使用的医学文献就来自于PubMed检索系统。
在医疗领域,运用信息抽取的算法对医学文本进行处理是目前重要而且热门的研究方向,它是构建临床决策支持系统[1]的基础。信息抽取可以自动帮助人们从日益增长的海量信息中快速找到自己真正需要的信息,并用结构化的格式进行表示[2-4]。其中,文本信息抽取是从自然语言文本中自动抽取信息的技术。美国高级研究计划署(DARPA)所资助的信息理解会议MUC(Message Understanding Conference)促进了文本信息抽取的发展。
本文对医学风险信息的抽取对临床医学操作评判有着重要的预警和决策分析作用,对已发生的医学事故有着重要的评估作用。医学中风险分析研究一直都受到大家的关注。风险是引起不幸和损失的可能性,在流行病学、临床医学和日常生活具有重要地位,医学风险信息有助于疾病的认识、预防和治疗[5]。一个重要的应用就是在医学领域决策支持中引入风险分析[6]。
目前对医学文本风险信息的抽取集中在对病历文本知识的抽取[7]中,通过对病历中治疗指标的抽取和分析,获取其中的风险信息。然而,对医学文献文本进行风险信息抽取的研究却较少。一方面,医学文献中风险的表现形式各有不同[8],另一方面,阅读医学文献需要花费较长时间。但是,如果医生遇到已有知识和已有病例无法解决的问题,这时候从医学文献中获取知识极其关键,本文就是解决从医学文献中快速获取风险知识的问题。由于医学文献文本属于非结构化文本,信息噪声太大,对它的处理难度较大,所以对医学文献处理大部分都集中在对医学文献中摘要的处理,摘要是全文的浓缩,文本量小,处理起来要简单一点。Deleris等从医学文献的摘要中对风险信息进行抽取[9]。Jochim等所使用的风险信息语料库就是从PubMed中200篇乳腺癌文献摘要中得到的[10]。但文献摘要会大面积舍掉正文信息,产生信息损失,存在着缺陷,所以本文尝试对文献全文进行处理。Jochim等对条件事件和结果事件进行了定义,并运用条件随机场的方法识别风险条件事件和风险结果事件[10]。
本文从医学文献中提取风险信息知识不同于目前研究较多的医学命名实体以及实体之间关系的提取。医学实体之间关系的抽取是一个文本中两个或者更多特定医学实体之间关系的识别[11-12],是医学本体研究的重要基础,其中比较重要的是确定医学命名实体类别(如诊断、症状和治疗等)和实体之间关系类别(如上下位、同义词等关系,当然也包括治疗、预防等关系)。
1 风险事件抽取
1.1 医学风险事件语料库
医学文献中的风险语句一般指的是已发表出来的医学文献文本中包含有对疾病的产生、发展、症状呈现、诊断治疗、监测随访等有影响因素的语句,因素可能是单一的,也可能是混合的,当然因素也可以包括其他疾病。风险语句分为定性风险语句和定量风险语句,定性风险语句是用叙述的形式来进行说明,例如,“The highest risk is seen in women with lobular carcinoma in situ (LCIS), but this is very rare.”。而定量风险语句是指带有数值说明的风险语句,其中分为普通数字(不算百分数)和百分数两种,举个带有普通数字(不算百分数)的风险语句的例子,“More common is atypical hyperplasia (AH), which carries a 4-5-fold risk of breast cancer as compared to general population.”,再举个带有百分数的风险语句的例子,“Tamoxifen has been shown to be particularly effective in preventing subsequent breast cancer in women with AH, with a more than 70% reduction in the P1 trial and a 60% reduction in IBIS-I.”。本文中所说到的风险语句指的是带有百分数的强风险定量信息语句。
风险语句中的风险事件指的是风险语句中关于其百分数描述的相关事件,本文重点关注针对百分数的影响说明元素、被影响说明元素、提示说明元素、来源说明元素、风险程度说明元素,如表1所示。影响说明元素,是指风险语句中产生影响的元素;被影响说明元素,是指风险语句中受到影响的元素;提示说明元素最能表明这是风险语句的标志,如存活率、复发率、死亡率等;来源说明元素指的是风险语句信息数据来自哪里,大多数情况下,数据来自作者的实验结果,但是也有可能来自临床指南,或综述报告等;风险程度说明元素指的是风险数据的修饰术语,如大约、精确、可能等。举个例子,“Tamoxifen has been shown to be particularly effective in preventing subsequent breast cancer in women with AH, with a more than 70% reduction in the P1 trial and a 60% reduction in IBIS-I.”,对于百分数70%,影响说明元素为T(t)amoxifen,被影响说明元素为breast cancer in women with AH (atypical hyperplasia),提示说明元素为reduction,来源说明元素是P1 trial,风险程度说明元素为more than;对于百分数60%,影响说明元素为T(t)amoxifen,被影响说明元素为breast cancer in women with AH (atypical hyperplasia),提示说明元素为reduction,来源说明元素是IBIS-I,无风险程度说明元素。

表1 风险事件类别
1.2 隐马尔可夫模型
隐马尔可夫模型HMM(Hidden Markov Model)[13]与马尔可夫模型不同,隐马尔可夫模型中包含一个隐藏状态序列和一个观察状态序列。对隐马尔可夫模型而言,模型中状态之间的转换是隐藏的,观察状态的随机过程是状态之间转换的随机函数[14]。
其中对隐马尔可夫模型作如下假设:下一个隐藏状态只与前一个隐藏状态有关,观察状态的概率只与当前隐藏状态有关。符合这种假设的隐马尔可夫模型也就是我们常说的一阶隐马尔可夫模型。
从隐马尔可夫模型的介绍中就可以看出来,一个HMM=(N,M,A,B,π) 过程由五部分组成:
(1) 隐藏状态的数目N;
(2) 观察状态的数目M;
(3) 隐藏状态之间转换的概率矩阵A={aij};
(4) 从隐藏状态到观察状态的概率矩阵B={bj(k)};
(5) 初始状态概率矩阵π={πi}。
给定一个观察状态序列O={o1,o2,…,oT}和模型M=(A,B,π)找出最优的隐藏状态序列S={s1,s2,…,sT},任务是要求解:
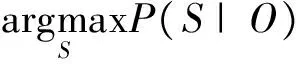
(1)
对于解码问题,常用解法是采用维特比(Viterbi)算法,维特比算法是运用动态规划的方法求解最优隐藏状态序列[14]。
(1) 初始化计算:
β1(i)=πibi(o1)
(2)
φ1(i)=0
(3)
(2) 中间动态规划计算:
(4)
(5)
(3) 结束计算:
(6)
(7)
(4) 路径回溯:
(8)
对于隐马尔可夫模型中参数学习问题,本文中由于语料库有限,先通过似然估计的方法确定参数,再通过Baum-Welch算法实现参数收敛。
1.3 最大熵马尔可夫模型
最大熵马尔可夫模型MEMM(Maximum Entropy Markov Model)[15-16]是在隐马尔可夫模型基础上增加了最大熵模型特点。由于隐马可夫模型采用生成式联合概率模型解决条件概率问题时不能用多特征进行刻画,最大熵马尔可夫模型运用最大熵的办法弥补这个缺点[14]。
隐马尔可夫模型中当前时刻观察输出取决于当前隐藏状态,最大熵马尔可夫模型中当前时刻观察输出除了取决于当前隐藏状态,也可能取决于前一时刻的隐藏状态。
假设观察状态序列为O={o1,o2,…,oT},隐藏状态序列为S={s1,s2,…,sT},解码问题需要求解:
(9)
(10)
前一时刻状态取值st-1用s′表示,当前观察序列值ot用o表示,运用最大熵原理:
P(s|s′,o)=Ps′(s|o)
(11)
(12)
式中:λa是需要学习的参数,Z(o,s′)是归一化因子,使得∑sP(s|o)=1 ,而fa(o,s)是特征函数。特征函数fa(o,s)包含两个参数,一个当前观察值,一个可能的隐藏状态值,特征函数通过a=
fa(ot,st)=f
(13)
(14)
MEMM中对隐藏标注序列的求解,也是用到Viterbi算法,不过需要在隐马尔可夫模型所使用的Viterbi算法基础上进行改进[16],改进后的算法如下:
(1) 初始化计算:
β1(i)=πipi(s|o1)
(15)
φ1(i)=0
(16)
(2) 中间动态规划计算:
(17)
(18)
(3) 结束计算:
(19)
(20)
(4) 路径回溯:
(21)
最大熵隐马尔可夫模型的参数训练采用的是GIS算法。
1.4 条件随机场
条件随机场CRF(Conditional Random Field)[17-18]是一种由John Lafferty等于2001年提出的概率化无向图,对于输出标识序列Y和观察序列X,条件随机场通过定义条件概率P(Y|X),而不是联合概率P(X,Y)描述模型。以观察序列X为条件,每一个随机变量满足马尔可夫特性[14]。
同样,假设观察状态序列为O={o1,o2,…,oT},隐藏状态序列为S={s1,s2,…,sT},则P(S|O)正比于:

(22)
式中:pj(si-1,si,O,i)表示观察序列O的隐藏序列在i-1到i之间的转移概率函数,qk(si,O,i)表示已知观察序列o在i时的状态标记概率函数。
根据最大熵模型的方法,两个特征函数可以通过二值特征表示,特征函数统一表示为:
(23)
那么条件随机场的条件概率分布可以表示为:
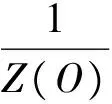
(24)
分母为归一化因子,表示为:
(25)
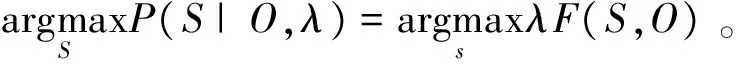
条件随机场中对于隐藏标注序列的求解同理于MEMM中改进的Viterbi算法,而参数估计使用的是L-BFGS算法,算法通过对训练集进行迭代来求解。
1.5 特征选择
把SNOMED CT(Systematized Nomenclature of Medicine Clinical Terms)中的医学临床术语集和风险事件语料库中的术语集组成医学术语词典,通过借鉴中文分词的最大正向匹配算法把风险语句中的有关关键词抽取出来,可以极大过滤掉无用信息,接着就可以通过序列标注算法对抽取出来的医学术语进行标注。
对于隐马尔可夫模型,需要在已知观察序列和训练语料库下,先通过参数学习,接着通过Viterbi算法求解得到最合适的隐藏状态标注序列。
对于最大熵马尔可夫模型和条件随机场,需要解决三个基本问题:特征选取、参数训练以及实验解码。两种算法采用条件概率模型和改进后的Viterbi算法来进行求解隐藏标注序列。对于其中的最大熵过程,需要选择合适的特征。特征选取决定着特征函数,会直接影响到序列标注实验效果。如果特征集选择过大,可能会出现过拟合现象;特征集过小,可能会降低实验准确率。特征选择需要考虑到上下文统计信息的重要性,上下文指的是当前词在术语抽取集中的前面若干词和后面若干词组成的窗口。窗口太小,就不能获得更多有用信息,然而窗口太大,就会占用更多资源,效率反而会有所下降。词性是信息提取中极其重要有效的特征,特征选择中一般需要同时考虑到词性,如风险程度事件更加集中于形容词(组)、副词(组)等。本文中词性采用的是宾州树库词性标注类型,其中对词组和单独词表示方式不同,通过词性就可以看出来这个词是一个单独词(一个单词)还是一个词组(两个单词及以上),如“cancer”的词性为NN,而“breast cancer”词性为NP。特征模板除了词和词性两种以外,还对当前词进行了一些其他判断,包括当前词是不是本组中第一个词,当前词是不是数字开头,以及当前词中是否有连词。实验中选择的特征模板如表2所示。

表2 特征模板
2 实验与分析
2.1 实验准备
从美国国家医学图书馆PubMed检索系统中获得医学文献文本,转换为统一文本格式,构建医学文献文本语料集。从医学文献文本中得到强风险定量信息语句,进而构建风险事件语料库。实验选取风险事件语料库中的3/4(3 140)事件作为训练语料,剩下的1/4(1 049)事件作为测试语料,用隐马尔可夫模型、最大熵马尔可夫模型和条件随机场分别对训练语料进行学习,然后分别对测试语料进行测试。本文选用常用的准确率、召回率和F1测度值进行结果测试,通过实验得到每个模型每种事件抽取的准确率、召回率和F1测度值,以及每个模型所有事件抽取的F1平均测度值:

(26)

(27)

(28)
(29)
2.2 实验结果
隐马尔可夫模型、最大熵马尔可夫模型和条件随机场抽取风险事件的结果分别为表3、表4和表5,隐马尔可夫模型、最大熵马尔可夫模型和条件随机场模型事件抽取的平均F1测度值的结果为表6。
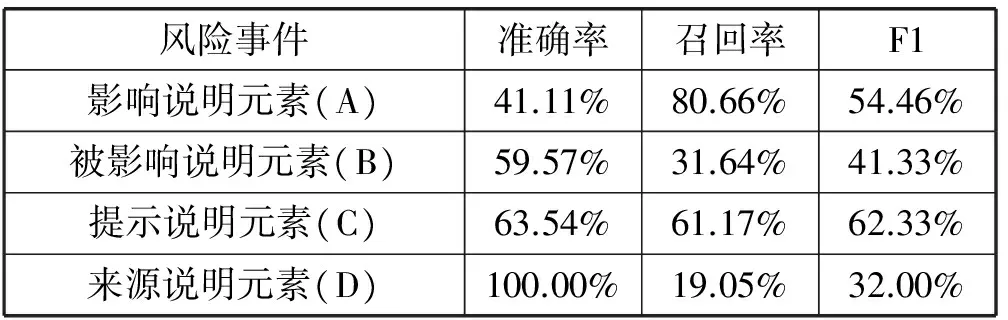
表4 最大熵马尔可夫模型(MEMM)风险事件提取结果

续表4
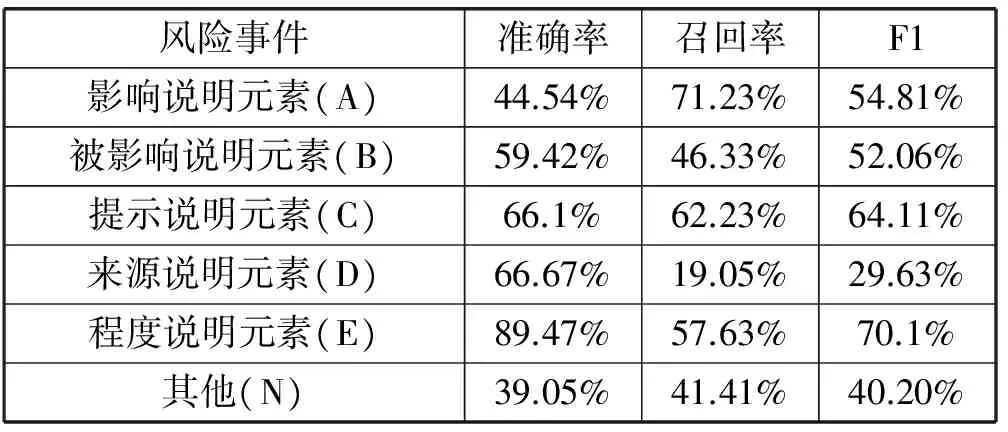
表5 条件随机场(CRF)风险事件提取结果

表6 序列标注算法风险事件抽取平均F1测度值比较
2.3 实验分析
对比隐马尔可夫模型、最大熵马尔可夫模型和条件随机场提取效果,进行分析比较。
从三个模型平均F1测度值来看,条件随机场效果最好,其次为最大熵马尔可夫模型,然后是隐马尔可夫模型,但是每个模型都有自己对某些事件抽取的准确率或者召回率的优势。对于影响说明元素,条件随机场的准确率要高,最大熵马尔可夫模型召回率要高;对于被影响说明元素,最大熵马尔可夫模型的准确率最高,条件随机场的召回率最高;对于提示说明元素,条件随机场的准确率和召回率都是最高的;对于来源说明元素,最大熵马尔可夫模型准确率最高,隐马尔可夫模型的召回率最高;对于程度说明元素,条件随机场的准确率和召回率都是最高的;对于其他我们不需要的情况,最大熵马尔可夫模型的准确率要高,隐马尔可夫模型的召回率要高。从三个模型的各个元素F1值来看,三个模型的提示说明元素和程度说明元素效果都还可以,而来源说明元素普遍效果较差。从事件的重要程度来看,最为重要的当然是影响事件元素和被影响事件元素,三个模型中条件随机场对这两种事件的抽取F1值都超过了50%,而且都高于其他两种模型。
从准确率来看,准确率高的一般变化形式较少,例如,提示说明元素一般集中在risk、rate、survival等,这些词出现在句子中大部分时候就是提示说明元素,属于其他类别事件的情况较少。程度说明元素集中在形容词和副词,如around、high、about等,而且这些词出现大部分就是程度说明元素,属于其他类别情况较少。最大熵马尔可夫模型的来源说明元素准确率极高,来源说明元素一般集中在带有report、review和guideline等词中,而且与上下文关系较为密切。从召回率来看,从三个模型所有事件召回率来看,未有高于85%的,召回率不是太高,说明三个模型在大部分事件提取中,还有很多相应事件没有找出来,查全不够,测试语料中的相应事件的未登录词的识别差、召回率低。隐马尔可夫模型是基于独立假设的,如果以隐马尔可夫模型为基准,可以看出,允许用特征来刻画观察序列有助于信息的抽取。
从医学文献文本中抽取风险事件,面临的最大问题可能就是实验文本为非结构化医学文献全文文本,自然语言处理起来噪声太大,无关信息太多,作者句子中用词风格各有不同,与临床标准术语集之间也有着很大的鸿沟,为医学文献文本信息抽取增加了很大难度。当然本实验中抽取的事件类别较多,也无形中增添了更多难度。另一个比较大的问题是语料库太小,未登录词处理量大,严重影响实验结果。
从结果来看,有些难点问题需要特别说明一下:
1) 并列式,以and或者or联合起来的事件。
2) 指代式,如果句子中表示事件的词是指代词(如it等)的话,这可能就需要通过前面句子才能理解指代词到底指代的是什么。
3) 拼接式,如果句子中表示事件的词表示不够完整,需要当前句子中的其他词,或者前面句子中的词拼接到一起才是完整的事件表示词。
后面要继续努力的方向还很多,如风险语句边界确定问题、风险事件边界确定问题、无关信息词的去除问题和医学领域本体构建问题等。
3 结 语
本文运用序列标注算法对医学文献文本中风险信息进行了提取,构建了风险事件语料库,比较了序列标注算法中隐马尔可夫模型、最大熵马尔可夫模型和条件随机场三种模型的抽取效果,从每个模型的平均F1测度值来看,条件随机场效果最好,其次是最大熵马尔可夫模型,然后是隐马尔可夫模型。当然本研究还有很大的完善空间,如语料库还是太小;对非结构化文献全文而言,信息抽取处理起来难度还是很大;还未结合规则化处理事件类别等。
[1] 陈黎明,卞丽芳,冯志仙.基于护理电子病历的临床决策支持系统的设计与应用[J].中华护理杂志,2014,49(9):1075-1079.
[2] 李保利,陈玉忠,俞士汶.信息抽取研究综述[J].计算机工程与应用,2003,39(10):1-5.
[3] 孙师尧,妙全兴.基于改进SVM和HMM的文本信息抽取算法[J].计算机应用与软件,2015,32(11):281-284.
[4] 张国庆.基于生物医学文献的知识发现方法研究[D].华中科技大学,2006.
[5] Edwards A,Prior L,Butler C,et al.Communication about risk-Dilemmas for general practitioners[J].British Journal of General Practice,1997,47(424 ):739-742.
[6] Deleris L A,Deparis S,Sacaleanu B,et al.Risk Information Extraction and Aggregation[M]//Algorithmic Decision Theory.Springer Berlin Heidelberg,2013:154-166.
[7] 李莹.文本病历信息抽取方法研究[D].浙江大学,2009.
[8] Crowson C S,Therneau T M,Matteson E L,et al.Primer:demystifying risk-understanding and communicating medical risks[J].Nature Clinical Practice Rheumatology,2007,3(3):181-187.
[9] Deleris L A,Sacaleanu B,Tounsi L.Extracting risk modeling information from medical articles[J].Studies in Health Technology & Informatics,2013,192(192):1158.
[10] Jochim C,Sacaleanu B,Deleris L A.Risk event and probability extraction for modeling medical risks[C].2014 AAAI Fall Symposium Series on Natural Language Access to Big Data.2014:26-33.
[11] 夏涵.基于本体的医学命名实体识别技术研究[D].上海交通大学,2012.
[12] Ben A A,Zweigenbaum P.Automatic extraction of semantic relations between medical entities:a rule based approach[J].Journal of Biomedical Semantics,2011,2(S5):S4.
[13] 于江德,肖新峰,樊孝忠.基于隐马尔可夫模型的中文文本事件信息抽取[J].微电子学与计算机,2007,24(10):92-94.
[14] 宗成庆.统计自然语言处理[M].清华大学出版社,2008.
[15] Rabiner L R,Juang B H.An introduction to hidden Markov models[J].IEEE ASSP Magazine,1986,3(1):4-16.
[16] 林亚平,刘云中,周顺先,等.基于最大熵的隐马尔可夫模型文本信息抽取[J].电子学报,2005,33(2):236-240.
[17] 王胜,朱明.基于最大熵马尔可夫模型的地址信息抽取[J].计算机工程与应用,2005,41(21):192-194.
[18] 张金龙,王石,钱存发.基于CRF和规则的中文医疗机构名称识别[J].计算机应用与软件,2014,31(3):159-162,198.
[19] 范岩.基于条件随机场模型的中医文献知识发现方法研究[D].北京交通大学,2009.
RESEARCHONMEDICALDOCUMENTRISKEVENTEXTRACTIONBASEDONCOMPARISONOFSEQUENCEMARKINGALGORITHMS
Yu Xin1,2Zhang Ju1,2Qiu Wusong2Wang Fei3
1(UniversityofChineseAcademyofSciences,Beijing100000,China)2(ChongqingInstituteofGreenandIntelligentTechnology,ChineseAcademyofSciences,Chongqing400714,China)3(SouthwestHospital,theThirdMilitaryMedicalUniversity,Chongqing400038,China)
With the rapid growth of medical literature, it is a huge challenge to extract valuable knowledge from big data in medical literature text. This paper focused on the event extraction of quantitative risk statements in medical literature, and constructed the knowledge base of intelligent clinical decision support system. Firstly, the risk events corresponding to the quantitative risk information were extracted from the medical literature, and then the risk events were processed. The hidden Markov model, the maximum entropy Markov model and the conditional random field model were used to extract the information of the risk events in medical literature unstructured full text, and the algorithms were compared. From the average F1 of three models, conditional random field was the best, followed by maximum entropy Markov model, and then the hidden Markov model, but each model had its own advantage of certain event extraction accuracy or recall.
Medical literature Risk event Hidden Markov model Maximum entropy Markov model Conditional random field
2017-02-14。重庆市社会民生科技创新专项项目(cstc2015shmszx120025)。喻鑫,硕士生,主研领域:机器学习,自然语言处理。张矩,研究员。邱武松,助理研究员。王飞,工程师。
TP391
A
10.3969/j.issn.1000-386x.2017.12.011
