基于邻域分类AUC的属性选择方法*
2017-12-13张艳芹窦慧莉
张艳芹,窦慧莉
(1.徐州工程学院 经济学院,江苏 徐州 221008;2.江苏科技大学 计算机科学与工程学院,江苏 镇江 212003)
基于邻域分类AUC的属性选择方法*
张艳芹1,窦慧莉2
(1.徐州工程学院 经济学院,江苏 徐州 221008;2.江苏科技大学 计算机科学与工程学院,江苏 镇江 212003)
为了提升邻域分类器的分类性能,提出了一种利用邻域AUC作为分类性能度量指标的启发式属性选择算法。首先,利用邻域分类器得到邻域AUC,然后在此基础上,借助贪心搜索策略,逐步加入使得邻域AUC尽可能大的属性,当邻域AUC不再增大时,算法终止。7个UCI数据集上的实验结果表明,使用邻域AUC属性选择算法,可以在使用较少属性个数的基础上有效提升邻域分类器的分类性能。
属性选择;启发式算法;邻域分类器;AUC指标
1 背景阐述
不同于经典粗糙集[1]方法,邻域粗糙集[2]借助机器学习中的距离概念,构建样本的邻域,进而达到刻画数据中不确定性的目的。近年来,邻域粗糙集方法因其对数据的适应性强、粒度变化较为灵活等优势受到了众多学者的关注[3-6]。
在邻域粗糙集理论中,除了可以使用邻域粗糙集刻画不确定性以外,借鉴K近邻[7]的思想,Hu等人提出了邻域分类器[8]。与K近邻分类器不同,邻域分类器不再指定待分类样本的邻居个数,而是通过指定半径,自然地得到待分类样本的邻居,即不同的样本可能包含不同个数的邻居,这是邻域分类器与K近邻分类器最重要的差别。除此之外,邻域分类器利用半径这一工具,能够自然地形成一个基于多粒度思想的分类结果,也就是说,随着邻域半径的不同,邻域分类器的分类结果自然也不相同。众所周知,影响分类器分类性能的因素除了分类器自身的分类能力以外,数据中的属性也是一个重要的因素。在现代数据中,往往存在着大量的冗余属性,如何从原始数据中删除影响分类器分类性能的冗余属性,以达到提升分类器性能这一目标已然成为了机器学习中一个重要的研究问题。鉴于此,笔者利用邻域分类器的AUC指标,提出了一种能够提升邻域分类AUC的属性选择算法。该算法与粗糙集理论中的属性约简算法有所不同,因为该算法的目标是提升邻域分类器的分类性能,而非保持粗糙集理论中的不确定性刻画能力不变。
本文的主要内容是:第二节简要介绍邻域粗糙集、邻域分类器和邻域分类AUC;第三节设计了一种能够提升邻域分类AUC的启发式算法,进行属性选择;第四节进行实验分析;第五节总结全文。
2 邻域分类器
对于分类任务来说,一个数据集或者决策系统可以用一个二元组进行描述,记为在S中,U表示论域,是所有样本构成的非空有限集合;AT是所有属性构成的非空有限集合;d是标记属性。
Pawlak粗糙集利用条件属性集合AT上的不可分辨关系生成等价类,对目标概念进行近似逼近。不同于Pawlak的经典粗糙集,邻域粗糙集借助距离的概念,构建样本之间的相似度矩阵,进行分类分析。在S中,对于任意的x,y∈U,表示对象x与y之间的距离。给定邻域半径为σ,不难构建的0-1函数:“△(x,y)=1当且仅当ϑ(x,y)≤σ,否则△(x,y)=0.”
利用0-1函数△(x,y),对于任意的样本x∈U,x的邻域记为表示所有与x之间的距离小于半径σ的样本所构成的集合。
定义1[4]给定,对于任意的X的邻域下近似与上近似分别定义为:
在邻域粗糙集理论中,邻域分类器是一个重要的研究方向。一个邻域分类器的分类过程为:对于待分类样本x,首先记录x的邻域σA(x)中所有样本的标记,其次利用多数决原则,预测对象x的类别,记为Pre(x),即将邻域σA(x)中所有样本的标记出现次数最多的那一标记作为待分类样本x的预测标记。以二分类问题为例,ROC曲线是基于样本的真实类别和预测概率画出的。ROC曲线的纵坐标是真正例率,即TPR=被正确分类的正类样本个数/所有正类样本个数,ROC曲线的横坐标是假正类率,即FPR=被错误分类的负类样本个数/所有负类样本个数。而AUC则是ROC曲线下的面积,常常可以用来评价一个分类器的优劣。
传统的AUC度量是针对二分类问题设计的,对于多类问题来说,文献[9]中给出了一种基于类别概率的AUC计算方式,形如:式(1)中:m为类别的个数;AUCi为第i类样本的AUC值;Pi为第i类样本在数据中出现的比例。
这种计算方式借鉴了一对多的基本思想,即将多类问题转换为多个二类问题。
3 属性选择
属性约简或属性选择是粗糙集理论的核心研究内容。在分类学习任务中,通过属性选择可以有效地删除对于分类任务重要度不高的属性,提升学习器的泛化能力。因此,借助AUC这一度量指标,可以定义以下属性选择。
从定义2中可以看出,邻域分类AUC属性选择实际上是期望找出一个属性子集,它是一个使得邻域分类AUC能够被提升的最小属性子集。下面给出求解这个属性子集的启发式算法。给定定义重要度Sig(a,A)用以表示将属性a加入到条件属性集A中后邻域分类AUC的变化情况:Sig(a,A)=的值越大,表明将属性a加入到属性集合A中后,邻域分类AUC的提升越明显。如果Sig(a,A)为负值,则表示将属性a加入到属性集合A中后,邻域分类AUC反而有所降低。利用属性重要度Sig(a,A)不难设计出下面所示的启发式算法,用以求解定义2所示的属性选择问题。
算法:启发式算法求解邻域分类AUC属性选择。
输入:决策系统S。
输出:一个选择出的属性子集A。
步骤1:在S中计算AUCAT.
步骤3:如果AUCA≥AUCAT,则转步骤4,否则执行以下循环:①对于任意的a∈AT-red,计算属性a的重要度Sig(a,A);②找出属性b,使得b满足Sig(b,red)=max{Sig(a,red):∀a∈AT-red},令 A=A∪{b};③计算AUCA.
步骤4:输出A。
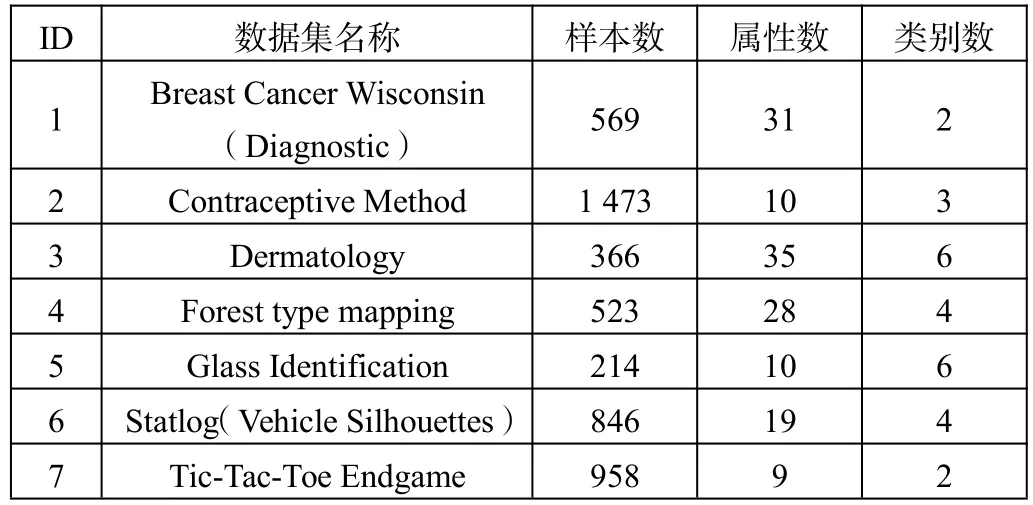
表1 数据集信息
4 实验分析
为了验证第3节所示属性选择算法的有效性,特选取了7组UCI数据集进行实验分析,这些数据信息的基本描述如表1所示。实验环境为PC机,双核2.60 GHz CPU,16 GB内存,Windows10操作系统,MATLAB R2010a实验平台。
在这组实验中,使用了4个不同的邻域半径σ进行属性选择计算,分别为0.1,0.2,0.3和0.4.表2中列出了在这4个不同的半径下,属性选择前后邻域分类AUC的变化情况。
从表2中可以发现,在实验所用的4个半径下,利用笔者提出的属性选择算法,AUC值明显提升。这表明,经过属性选择这一过程,邻域分类器的分类性能有了明显提升。这一实验结果从分类性能的角度验证了属性选择算法的有效性。此外,进一步观察表2所示的均值可以发现,无论是否使用属性选择,随着半径的增大,AUC值都有所降低。这一现象表明,邻域分类器的分类性能随着半径的增大逐渐减弱。表3给出了经过属性选择算法后所得的属性个数。
观察表3不难发现,利用属性选择算法,邻域分类器所使用的属性个数明显减少。这表明,利用笔者提出的属性选择算法,可以有效地删除原始数据中的冗余属性,以达到提升邻域分类器性能的目的。

表2 属性选择前后的AUC值

表3 选择出的属性个数
5 结束语
传统邻域粗糙集理论中的属性约简问题大多是基于不确定性的角度进行分析和研究的。本文为了从AUC的角度提升邻域分类器的分类性能,提出了基于邻域分类AUC提升的属性选择算法。这一算法借助基于贪心搜索策略的启发式过程,能够有效地在删除冗余属性的基础上,提升邻域分类的AUC值。在本文工作的基础上,笔者下一步将就如何提高属性选择算法的效率问题进行深入讨论。
[1]Pawlak Z.Rough Sets-Theoretical Aspects of Reasoning about Data[M].Boston:Kluwer Academic Publishers,1991.
[2]胡清华,于达仁.应用粗糙计算[M].北京:科学出版社,2012.
[3]段洁,胡清华,张灵均,等.基于邻域粗糙集的多标记分类特征选择算法[J].计算机研究与发展,2015,52(1):56-65.
[4]张维,苗夺谦,高灿,等.邻域粗糙协同分类模型[J].计算机研究与发展,2014,51(8):1811-1820.
[5]朱鹏飞,胡清华,于达仁.基于随机化属性选择和邻域覆盖约简的集成学习[J].电子学报,2012,40(2):273-279.
[6]杨习贝,徐苏平,戚湧,等.基于多特征空间的粗糙数据分析方法[J].江苏科技大学学报(自然科学版),2016, 30(4):370-373.
[7]Wu ХD,Kumar V,Quinlan JR,et al.Top 10 algorithms in data mining[J].Knowledge and Information Systems,2008,14(1):1-37.
[8]Hu QH,Yu DR,Хie ZХ.Neighborhood classifiers[J].Expert Systems with Applications,2008,34(2):866-876.
[9]Fawcett T.Using rule sets to maximize ROC performance[C]//IEEE International Conference on Data Mining,2001:131-138.
张艳芹(1979—),女,硕士,讲师,主要研究方向为智能信息处理。窦慧莉(1980—),女,硕士,助理研究员,主要研究方向为粗糙集理论、粒计算、机器学习。
〔编辑:白洁〕
TP18
A
10.15913/j.cnki.kjycx.2017.24.043
2095-6835(2017)24-0043-03
国家自然科学基金(61572242);江苏省高校哲学社会科学基金(2015SJD769)
