一种基于分类器的社交网络去匿名方法
2017-12-09胡光武张平安马江涛
胡光武,张平安,马江涛
(1.深圳信息职业技术学院计算机学院,广东 深圳 518172;2.解放军信息工程大学数学工程与先进计算国家重点实验室,河南 郑州 450001;3.郑州轻工业学院计算机与通信工程学院,河南 郑州 450002)
一种基于分类器的社交网络去匿名方法
胡光武1,张平安1,马江涛2,3
(1.深圳信息职业技术学院计算机学院,广东 深圳 518172;2.解放军信息工程大学数学工程与先进计算国家重点实验室,河南 郑州 450001;3.郑州轻工业学院计算机与通信工程学院,河南 郑州 450002)
为保护社交网络用户隐私,验证社交网络提供商对社交数据进行匿名保护的有效性,本文提出了一种基于随机森林分类器的社交网络去匿名方案。首先,方法将社交网络的去匿名问题转化为辅助网络与匿名网络之间的节点匹配问题,然后把网络结构的特征(如节点度中心性、中介中心性、亲近中心性、特征向量中心性)作为节点特征向量训练分类器。最后,根据训练后分类器的判定结果,方法实现两个网络节点间的匹配,完成了去匿名测试过程。利用真实的学术社交网络数据进行了方案评估,结果表明本文提出的方法优于已有方案,在0.5%假阳性率的情况下仍能实现81%的社交网络节点去匿名化效果。
社交网络;去匿名;节点匹配;社交网络结构
引言
社交网络(Social Network,SN),如新浪微博、人人、Facebook等每天产生了用户大量的真实数据,包括用户简介、好友关系以及日常生活细节等。因此社交网络数据常被第三方获取,用于精准营销、学术研究以及公开竞赛[1-3]等活动。用户真实数据被利用的现象频发,引发了公众对社交网络提供商泄露用户隐私的担忧。尽管社交网络提供商向第三方发布社交数据时,通常会简单地消除用户ID等信息,然而这些操作对于保护用户的隐私还远远不够[4]。因此,社交网络提供商发布社交网络数据之前的隐私保护方法,引起了研究人员和社交网络供应商的极大关注[5]。他们提出了多种隐私攻击和去匿名方法以验证工匿名化工作对用户隐私保护效果,如基于k-anonymity[6]、以及基于图映射的去匿名技术等。然而,已有工作至少存在三方面的不足:第一,有些方法只关注某一类社交网络的去匿名工作,因此设计的模型不具有通用性,也无法适用于其它类型的社交网络;其次,还有工作[7-8]对于攻击者的先验知识要求较高,如假定攻击者事先掌握社交网络节点度、社交网络的拓扑结构图等关键信息,致使整体方案实用性较差;最后,还有一些方案对用户特征建模不完善,致使模型无法自动抽取用户节点特征完成自动化去匿名化工作。
为了弥补以上方案的不足,本文提出了一种基于随机森林分类器的自动化社交网络去匿名化方案。方案的目标是:构建自动化去匿名模型,并利用该模型评估基于结构匿名方法的有效性,从而给设计隐私保护技术(比如匿名化)的社交网络提供商提供测试结果,从而降低社交网络用户隐私泄露风险。
为了实现以上目标,本文方案首先把社交网络的去匿名问题转化为两个网络间(匿名社交网络和辅助社交网络)的节点匹配问题,并利用已知社交网络结构的特征(如节点度中心性、中介中心性、亲近中心性、特征向量中心性)作为节点特征向量训练分类器。之后,使用训练后的分类器对匿名社交网络(简称“匿名网络”)和辅助社交网络(简称“辅助网络”)的候选节点对进行匹配,判定两者是否属于同一节点,从而实现社交网络节点去匿名化过程。
本文的主要贡献在于:(1)提出了基于随林森林分类器自动化的社交网络去匿名方法;(2)利用社交网络节点的特征(度中心性、介数中心性、亲近中心性、以及特征向量中心性)建立了社交网络去匿名评估模型;(3)在真实的学术社交网络数据集上验证了方法的有效性,并证明优于现有方案。
1 问题描述
如前所述,我们利用了辅助社交网络数据去匿名化匿名社交网络数据。匿名网络数据是指社交网络提供商使用匿名手段对其社交数据进行隐私保护后发布给第三方的数据,而辅助网络数据是含有部分真实信息的社交网络数据。辅助网络数据可以是匿名网络数据发布前的快照,也可以是根据先验知识构造的网络(如对社交网络爬取、数据挖掘、信息集成得到的数据等)。去匿名是指通过辅助网络数据找出匿名网络数据中匿名数据的原始信息。
若将匿名网络或辅助网络视为含有若干节点(用户)的有向图:G=(V,L),其中集合V表示图节点集合,L表示节点之间连接边的集合(用户之间的好友/粉丝关系),那么我们去匿名的目标转化为:找出匿名图Gs和辅助图Gt中节点的映射关系σ:Gs→Gt。对于节点p∈Vs,q∈Vt,如果p,q匹配,则σ(p,q)= 1,否则σ(p,q) =0。我们的目标是最大程度地找出两个网络中匹配节点p和q的集合。
2 网络结构特征参数描述
考虑到网络结构是社交网络的重要特征,我们的思路是:首先,分别从匿名网络和辅助网络中找出其网络节点的特征,包括节点度、聚类系数、特征向量的中心性等,并将这些特征组合为节点的特征向量,然后将匿名网络和辅助网络节点间的匹配问题视为二分类问题,最后采用随机森林分类器根据节点的特征向量进行评估分类,判定两个节点是否属于同一节点。涉及的主要网络参数描述如下:
(1)度中心性
度中心性(节点的边连接数量)刻画了节点的直接影响力。它认为一个节点的度越大,则能直接影响的邻居就越多,影响力也就越大,重要性也就越高。但值得注意的是,不同规模的网络中即使有相同度值的节点影响力却不尽相同,为了进行归一比较,我们将节点vi的度中心性定义为:

(2)中介中心性
中介中心性表示两个节点的最短路径经过桥(中间节点)节点的次数。该值表明桥节点的中介中心性,具体可通过此节点的最短路径个数除以所有的最短路径个数表示。在无向图中,对于v∈V,它的中介中心性定义为:

其中x,y∈V,N为规模很大的连通分支中节点的数量,分母中σxy(G)=|P(x,y)|表示G中x与y之间的所有的最短路径数量。分子中σxy(v)=|{p(x,y)∈P(x,y)|,表示x与y之间的所有的最短路径中经过节点v的数量。
(3)接近中心性
度中心性只考虑了和它相连的边的数量,故它仅能表示节点的局部性质。为了充分刻画一个节点对其拓扑的重要性,需要从全局角度考虑度量节点中心性的方法。接近中心性,也称之为亲近中心性,度量了一个节点与其它节点的接近程度,即网络中节点的数量(减一)除以节点v到所有节点的最短路径之和。在定义中,N是节点的数量,距离是节点到另一节点所经过的边数。对于v∈Va,它的接近中心性cv定义为:

其中,|p(v,u)|表示节点v到节点u的最短路径数量。(3)式表明,一个节点到其它节点的最短路径边数越少,则此节点的接近中心性越大.
(4) 特征向量中心性
节点的度指标把周围相邻节点视为同等重要,而实际上节点之间是不平等的。因此,必须考虑邻居节点对该节点重要性的影响,某节点的邻居很重要,那么该节点重要性也应该很高。特征向量中心性认为一个节点的重要性不仅取决于其邻居节点的数量,还取决于每个邻居节点的重要性。特征向量中心性是网络邻接矩阵对应最大特征值的特征向量,记Xi为节点vi的重要性度量值,则有:

其中,λ为一个0到1之间的常数。矩阵X=[x1,x2,x3,…,xn]T,经过多次迭代后达到稳态:x=λ-1Ax,x是矩阵A的特征值λ所对应的特征向量。式(4)表达了一个节点的影响力值是它的邻居的影响力值之和。特征向量指标是从网络中节点的影响力角度考虑将单个节点的影响力视为其它邻居节点权值的线性组合,从而得到一个线性方程组。该方程组的最大特征值所对应的特征向量就是各个节点的重要性。特征向量中心性把那些与特定节点相联结的其它节点的中心性也考虑进来,从而度量一个节点的中心性。在此情况下,节点既可以通过连接重要的节点,也可以大量连接一般节点,以提升自身的重要性。
3 基于分类器的社交网络去匿名化方法
随机森林是机器学习中很重要的分类器之一,其原理是用随机的方式建立一个森林,森林里包含有若干决策树,并且每一棵决策树之间没有关联。在建立森林之后,当有新的输入样本进入时,森林中的每一棵决策树分别进行判断,看该样本被哪一类树选择最多,从而预测该样本的类别属性。本文中,我们使用随机森林分类把匿名网络节点和辅助网络节点根据度中心性、中介中心性、接近中心性以及特征向量中心性特征进行分类,如果两个网络中某一对节点被分为一类,则它们就是相同的用户节点,此时可用非匿名节点替代匿名账号节点,从而实现节点信息去匿名的目的。相反,如果一对节点不被分为一类,则它们不是匹配的账号节点。每个叶子节点对应的决策树预测结果的平均值,产生一个决策森林的平均预测结果,其定义为:

其中,p(c|v)是度中心性、中介中心性、接近中心性、特征向量中心性的经验概率,v代表这四种特征,T是决策树的数量,pt(c|v)可根据这些特征得出单个树的预测结果。公式5表示随机森林分类器首先根据每类特征对一对节点进行分类,然后汇总分类结果,并根据多个预测树的结果以及随机森林投票机制得出最终结果。
具体流程上,方法首先初始化辅助网络中节点的特征向量,然后初始化匿名网络中节点的特征向量,接着计算两个节点特征向量的余弦相似度。如果相似度值小于阈值,则这两个节点进入随机森林分类器的左子树,否则进入右子树。对进入右子树的节点对,我们可视为匹配的节点(账户)对,就可用已知的辅助网络账号信息替换匿名网络中的账号信息,从而实现去匿名目标,具体流程如图1所示。

图1 社交网络去匿名方法流程图Fig.1 The flow chart of de-anonymizing method for social networks
4 性能评估
4.1 实验数据集
为了评估本文方法的先进性,我们使用了两类真实的社交数据进行了测试。
微软学术数据集[9]:该数据集是从微软学术图(MAG)的真实数据。本文抽取了MAG上2000-2016数据挖掘(DM)、社交网络分析(SNA)领域会议以及期刊论文中的两种作者合作关系网络,一个为偶数年的数据匿名图(ODM),另一个为奇数年的数据辅助图(EDM),均包含了文章的标题信息、引用关系、作者及其单位的信息。
ArnetMiner[10]数据集:ArnetMiner是一个提供专家搜索和挖掘服务的学术社区,包含了1,053,188个用户和3,916,907个论文合作关系。
4.2 测试方法
为了便于对比,我们与如下几种主流的社交网络去匿名方法进行了比较。
DDM[11]:Fabiana等人提出的基于度驱动的图匹配去匿名方法,主要利用社交网络节点的度分布特征识别度值较大的节点实现去匿名化效果。
ADA[12]:Ji等人设计的一个综合考虑辅助网络局部和全局拓扑特征的去匿名方法,并使用上一轮去匿名的结果作为种子不断迭代,实现去匿名未知的节点信息。
Seed-and-Grow[13]:Peng等人提出的一个基于图结构特征的种子节点增长识别方法。该方法首先识别出一个种子节点的子图(由用户事先植入到网络中),然后根据用户的社交关系扩展该种子的子图,并不断扩大该图并识别未知节点。
4.3 评估结果
首先我们使用MAG数据集的辅助图识别匿名图,实现识别出匿名网络中作者的信息。图2给出了4种算法在MAG数据上的受试者工作特征曲线(ROC曲线),从中我们可以清晰地看出:对比DDM、ADA、Seed-and-Grow方案,本文方法在整个过程中效果最好,在0.7%的假阳率情况下,算法实现了去匿名84%的节点,而其他三种方案分别为68%、57%、52%。即使对于很小的假阳率(0.005或0.5%),本文方法仍然可以去匿名81%的节点,而当假阳率高于0.25时,可以实现去匿名99%以上的节点。
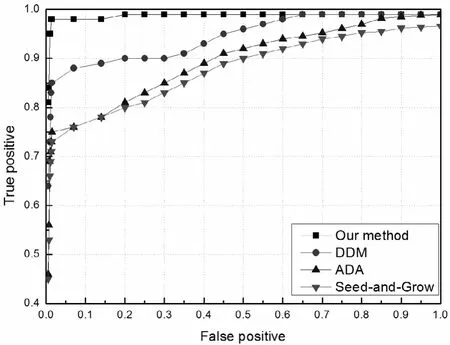
图2 不同去匿名方法在微软学术图(MAG)数据集上的ROC曲线比较Fig.2 The ROC comparison with four different de-anonymization methods in MAG dataset
此外,我们还对Aminer数据集的辅助图和匿名图上进行了去匿名实验。图3给出了4种算法的ROC曲线。在0.7%的假阳性情况下,本文算法实现了去匿名85%的节点,DDM、ADA、Seed-and-Grow方法的结果分别为68%、63%、56%。对于很小的假阳率(0.005或0.5%),本文方法仍可以实现去匿名82%的节点,当假阳率高于20%(0.2)时,方案可以实现去匿名99%的节点。
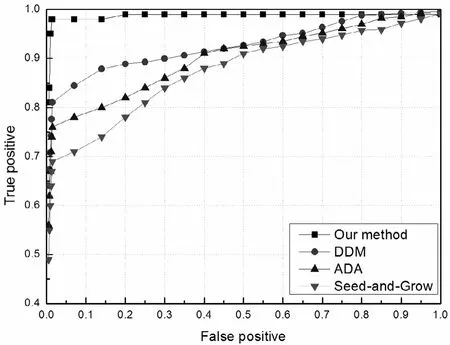
图3 不同去匿名方法在Aminer数据集上的ROC曲线比较Fig.3 The ROC comparison with four different de-anonymization methods in Aminer dataset
5 结束语
针对社交网络的去匿名问题,本文提出将社交网络的去匿名问题转化为机器学习中的分类问题,并利用图的结构特征,如度中心性、接近中心性、介数中心性、特征向量中心性等特征,作为参数训练随机森林分类器,实现了社交网络去匿名化过程。方案无需种子数量及先验知识作为前提,通过在两种不同的真实数据集上进行测试,结果表明本文方案优于现有几种方案,至少实现了去匿名81%网络节点的效果。但同时我们也看到,社交网络账号的用户图像、在线活跃度等信息也是社交用户的重要特征。下一步,我们将尝试将这些特征融入方案,以进一步提高社交网络节点去匿名化比率。
[1]S.Motahari,T.Jung,H.Zang and et.al.P redicting the influencers on wireless subscriber churn [C]//.IEEE Wireless Communications and Networking Conference,2014: 3402-3407.
[2]C.Shah,R.Capra,and P.Hansen.Collaborative Information Seeking [J].Computer,2014,47(3): 22-25.
[3]Z.Xu,J.Ra manathan,and R.Ra mnath.Identifying knowledge brokers and their role in enterprise research through social media [J].Computer,2014,47(3): 26-31.
[4]T.Jung,X.-Y.Li,and M.Wan.Collusion-tolerable privacypreserving sum and product calculation without secure channel [J].IEEE Trans.Dependable Secur.Computer,2015,12(1): 45-57.
[5]T.Jung,X.Y.L i,Z.Wan and et.al.Control Cloud Data Access Privilege and Anonymity With F ully Anonymous Attribute-Based Encryption [J].IEEE Trans.Inf.Forensics Secur.,2015,10(1): 190-199.
[6]K.Liu and E.Terzi.Towards Identity Anonymization on Graphs [C]//.ACM SIGMOD International Conference on Management of Data 2008: 93-106.
[7]R.T.Z.Zabi elski Michałand Kasprzyk and K.Szkó łka.Methods of P rofile Cloning Detection in Online Social Networks [C]//.MATEC Web of Conferences,2016: 4013.
[8]Y.Zhang,J.Tang,Z.Yang and et.al.COSNET: Connecting Heterogeneous Social N etworks with L ocal and G lobal Consistency [C]//.ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2015:1485-1494.
[9]A.Sinha,Z.Shen,Y.Song and et.al.An overview of Microsoft academic service (mas) and applications [C]//.The 24th international conference on World Wide Web,2015:243-246.
[10]J.Tang.AMiner: Toward Understanding Big Scholar Data[C]//.The 9th ACM International Conference on Web Search and Data Mining,2016:467.
[11]C.Fabiana,M.Garetto and E.Leonardi.De-anonymizing scale-free social networks by percolation graph m atching[C]//.IEEE INFOCOM,2015:1571-1579.
[12]S.Ji,W.Li,M.Srivatsa and et.al.Structure Based Data De-Anonymization of Social Networks and Mobility Traces[C]//.The 17th International Conference,ISC 2014: 12-14.
[13]W.Peng,F.Li,X.Z ou and et.al.A T wo-Stage Deanonymization Attack against Anonymized Social Networks [J].IEEE Trans.Computer,2014,63(2): 290-303.
【责任编辑:杨立衡】
Classifier-based De-anonymization Method for Social Networks
HU Guangwu1,ZHANG Pingan1,MA Jiangtao2,3
(1.School of Computer science,Shenzhen Institute of Information Technology,Shenzhen 518172,China 2.State Key Laboratory of Mathematical Engineering and Advanced Computing,PLA Information Engineering University,Zhengzhou 450001,China 3.School of Computer and Communication Engineering,Zhengzhou University of Light Industry,Zhengzhou 450002,China)
In order to protect social network users’ privacy and test the vulnerability of the anonymization methods that provided by s ocial networks’ provider,in this paper,we propos e a random forest classifier-based automatic de-anonymize method for social networks.First,we convert the de-anonymization problem among social networks into two nodes mapping problem between two graphs.Then,we utilize social network structure features,such as node’s degree,betweenness centrality,closeness centrality,eigenvector centrality,to train binary classifier.Then,we predict whether two nodes belong to the same kind of nodes through classifier.Therefore,we can map the node automatically through trained binary clas sifier to perform de-anonymization process.Finally,the experiments that conducted on real academic social networks’ datasets demonstrate that the effective of our proposed method,which outperformances existing methods and it can de-anonymize 81% of network nodes in the worst scenario of 0.5% false positive ratio.
social network; de-anonymization; node matching; social network structure
TP311.13
A
1672-6332(2017)03-0006-06
2017-9-30
广东省自然基金资助项目(2015A030310492);深圳市基础研究项目(JCYJ20160301152145171);河南省科技厅科技攻关项目(162102410076,162102310578);河南省高等学校重点科研项目(16A520062,17A520064)
胡光武(1980-),男(汉),湖南桃源人,讲师,博士,主要研究方向:下一代互联网及其体系结构。E-mail: hugw@sziit.edu.cn
