基于机会式网络编码改进的加权广播重传方法
2017-11-23,
,
(浙江工业大学 信息工程学院,浙江 杭州 310023)
基于机会式网络编码改进的加权广播重传方法
孟利民,单剑辉
(浙江工业大学 信息工程学院,浙江 杭州 310023)
针对在无线广播网络链路状态不同和丢包率较高的情况下,WONCR(Weighted opportunistic network coding retransmission)等重传方法存在计算复杂度高的问题,提出了一种经过改进的基于机会网络编码的加权广播重传方法.该方法先根据接收端的反馈信息构建加权数据包状态矩阵,然后根据状态矩阵创建丢包的Hash表,最后通过Hash邻域最大值搜索和接收端缓存优化快速选择满足一定编码条件的丢包组合通过异或生成编码包进行重传,从而在保持较高重传性能的同时,有效降低了重传方法的时间复杂度和接收端所需的缓存容量.仿真结果表明相比已有算法有较低的时间复杂度,能有效地减少计算开销和接收端的缓存压力,大大提高实用性.
无线广播网络;机会式网络编码;重传;优化方案
网络编码(Network coding,NC)概念于2000年首次提出[1],中转节点通过对多条有关链路的数据流进行编码形成一个单独的编码数据流,接收节点可利用数据流之间的相关性来解码.与传统节点对数据包仅进行“存储转发”的方式不同,它可以提升网络的传输性能,使网络多播信息流达到最大流最小割定理(Max-flow min cut theorem)所述的理论值上界.无线网络随着它的普及得到了业内越来越多的关注,近些年以来有许多基于无线网络的研究出现[2-4].其中,无线网络具有有线网络所不具备的天然的广播特性,也正是由于该特性为网络编码理论的应用提供了比较有利的条件,因此国内外有越来越多的研究者开始将无线网络和网络编码两者结合起来进行研究并得到了许多研究结果.而在这些研究结果当中,机会式网络编码(Opportunistic network coding,ONC)方案[5]由于只需要进行异或操作就可以完成编解码,具有复杂度低、高效率的特点,逐渐成为了主流,取得了许多研究成果[6-8].文献[9]提出了将ONC与自动重传请求(Automatic repeat request,ARQ)相结合的重传策略.文献[10]提出了一种基于网络编码的广播重传(Network coding wireless broadcasting retransmission,NCWBR)方法,该方法相比于传统的ARQ能相对减少所需的平均传输次数并提高传输性能,但其存在着重传编码包无法每次都被所有接收节点解码和丢失成块数据包时传输性能恶化的问题.针对NCWBR的不可解码问题,文献[11]提出了一种改进的重传策略(Improved network-coding-based broadcasting retransmission,INCBR),但该方法虽解决了不可解的问题,却并未对丢失数据包的选择进行优化.文献[12]从多发送端多接收端的角度出发,提出了一种应用于多发-多收网络的重传方案(Network coding wireless retransmission mechanism,NCWRM),在该算法中每个节点既可以是发送者也可以是接收者,因此该方案的情况更一般化,但该方案的缺陷是会使中心度较高的节点能耗较大.文献[13]从改善选包策略的角度提出(Hash lookup assisted retransmission,HLAR),该方法利用散列组合进行选包,能更快地寻找到合适的丢失分组进行编码并降低平均传输次数,但其将编码包的重传过程理想化了,未考虑重传编码包在重传过程中出现的再丢失问题.文献[14]在HLAR的基础上提出了一种改进的基于机会网络编码的重传(Improved opportunistic network coding retransmission,IONCR)方法,其在保持较低算法复杂度的情况下挖掘了丢失数据包更多的编码机会,提高了丢失包的编码率,但该方案需要接收节点缓存额外的重传编码包,对接收节点的存储资源不够友好,无法适用于一些设备存储资源比较有限的场景.不同于文献[10-14],苟亮等[15]从每个节点接收链路数据丢失率不同的角度出发,提出了一种基于机会网络编码的加权广播重传算法(Weighted opportunistic network coding retransmission,WONCR),该方法对减少重传次数的问题进行了转化,将其变为基于加权的接收节点的最大增益问题,即让每次重传都能使尽可能多的接收节点受益,但该方案的加权数据包调度算法采用逐行逐列寻找,其时间复杂度较高,而且也未对接收端的缓存容量进行优化,因此在现实场景当中应用有较大限制.
为了更好的在各节点接收链路分组丢失率不同的情况下保持较高重传方法性能,降低其数据包调度算法的时间复杂度,并且保证在每次重传收益最大的情况下使接收端平均所需缓存容量最小,在WONCR等方法的基础上,提出了一种基于机会网络编码改进的加权广播重传(Improved-WONCR,IWONCR)方法.其基本思想是在WONCR的基础上采用Hash邻域最大值搜索和接收端缓存容量优化来快速选择丢失数据包组合进行编码重传从而降低加权数据包调度算法的复杂度和优化接收端平均所需缓存容量.
1 系统模型及基本原理
该系统模型包含一个发送数据的源节点S和N个接收数据的接收节点R={R1,R2,…,RN},假设源节点广播M个原始数据包P={P1,P2,…,PM}给N个接收节点.整个数据广播过程分为两个阶段:原始数据发送阶段和丢包重传阶段.
在第一阶段,也就是原始数据发送阶段,源节点先将M个原始数据包进行广播,所有接收节点对每个数据包的状态通过ACK/NCK反馈给源节点S.这里假设接收节点Ri可以在源节点S广播数据包之后,通过接收信号的信噪比来得到链路的信道状态,而且状态信息反馈不会发生丢失.另外,假设每个接受节点和源节点之间的信道是相互独立的,而且各链路丢包率在发送一个数据包的时隙内不会发生改变.
在第二阶段,也就是丢包重传阶段,源节点根据接收节点反馈的丢包信息,通过某种调度算法来选择不同接收节点的丢包进行异或编码,然后将编码包再次发送出去.接收节点收到重传的编码包之后,通过异或运算从该编码包和已接收的数据包中恢复出所需的丢失数据包信息.然后不断重复此过程,直到接收节点都收到了所有数据包.这里假设接收节点系统只有在底层缓存的数据包可用的情况下才会将数据包从底层缓存中移至应用层中,即当第k个数据包到达时,只有当数据包Pi(i∈{1,2,…,k-1})都正确接收到且不会再用于重传包解码的情况下,Pk才会被系统从底层缓存中移至应用层当中,如果前面存在丢包,则这个包也只能暂时保存在底层缓存当中.
假设被选择的丢失数据包为X1,X2,…,Xt,其中Xi(1≤i≤t)长度为l,y表示一个编码组合,分别用二进制序列表示为[xi1,…,xij,…,xil]和[y1,…,yj,…,yl],从而采用ONC生成的广播重传分组序列的某一数据包可以描述为
(1)
式中αi为数据包Xi编码与否的控制因子.当αi=0时,数据包Xi不参与编码,否则,Xi获得参与编码的机会.
由于单个重传编码包中包含一个或多个原始丢失数据包,多个接收节点可以从该重传数据包中通过异或解码恢复得到各自的丢失数据包.因此可以得出:基于ONC的广播重传方法相对于传统的ARQ方法能有效减少重传次数.在每条链路损耗都不同的情况下,寻找丢失数据包组合的算法以及编
解码策略的设计是基于ONC的加权广播重传的关键所在,尽可能在每次重传过程中都能使更多接收节点受益的情况下来降低算法时间复杂度,而且又能使重传次数减到最少.
IWONCR是基于WONCR的广播重传,其核心思想是在保持每次重传都能让最多的接收节点受益以及尽可能减少平均重传次数的情况下,进一步降低算法的时间复杂度,并减少接收端的缓存压力.
2 算法描述
WPDM是指在原始数据传输之后,源节点通过ACK/NCK的方式收集各接收节点反馈的数据包状态信息和链路状态信息所形成的列表[15].该列表是一个N×M的矩阵,行系数和列系数分别代表各个接收节点和数据包,数据包元素在矩阵中用wi,j(0≤wi,j≤1;i=1,2,…,N;j=1,2,…,M)来进行表示.假设wi,j=1-pi>0,则代表接收节点Ri没有成功接收到数据包Pj,且接收节点Ri和源节点S之间的通信链路成功传输概率为1-pi,其中pi为接收节点Ri和源节点S之间通信链路的丢包率;如果wi,j=0,则说明Ri已经成功接收到数据包Pj.表1给出了一个3个接收节点和10个原始数据包的WPDM示例.

表1 加权数据包分布矩阵(WPDM)Table 1 The weighted packet distribution matrix
图1给出了IWONCR重传方法的实现流程,一共分为6个步骤,具体步骤描述如下:
步骤1在初始阶段,源节点将原始数据包广播发送给所有接收节点.
步骤2在初始传输阶段或某次重传结束之后,通过ACK/NCK更新接收状态表,根据WPDM矩阵是否为全“0”矩阵来判断是否所有数据分组都被节点正确接收,如果是,则表示所有数据分组都被各接收节点正确接收,不需要再进行重传,直接进入步骤6;否则进入步骤3继续执行.
步骤3根据WPDM计算所有丢失数据包的Hash值,并生成丢失数据包的Hash列表(Hash table).然后利用Hash值通过Hash邻域最大值搜索来快速寻找合适的第i次重传的丢失数据包组合.判断第i次的Hash最大值的数据包组合是否唯一,若是,则转到步骤5继续执行;如果不是,则进入步骤4进行接收端缓存容量优化环节.
步骤4使用接收端缓存容量优化选择合适的编码包,即在多个Hash最大值相同的组合当中根据原始包的先后顺序选出总顺序和最小的数据包分组,进入步骤5.
步骤5根据所选的数据包组合进行异或编码,然后广播给所有接收端,接收端对其进行解码.然后继续重复步骤2.
步骤6当所有接收端都接收到所需的数据包,源节点如果接下去还需要发送更多信息,则系统重新从步骤1开始新一轮的传输流程,否则整个传输流程结束.

图1 IWONCR方法流程Fig.1 IWONCR algorithm flow
2.1 根据WPDM生成丢失分组的Hash表
WPDM里的第i列表示数据分组Pj(1≤i≤M)在N个节点接收丢失分组的情况.为了在搜索阶段能够快速通过邻域来搜索,需要保证当接收节点在丢失数据包Pj的情况不一样时其对应Hash值大小也不一样,否则其对应的Hash值大小相同,IWONCR采用Hash函数h计算每一个丢失数据包的Hash值,h表示为

(2)
由式(2)算出每个丢失包的Hash值之后,按Hash值从大到小的顺序创建丢失分组的Hash表,为方便后续操作,这里将Hash值作为列的索引下标.表2给出了表1所示WPDM的Hash表,其中Nhi代表索引下标为i的Hash值的丢失分组数量.
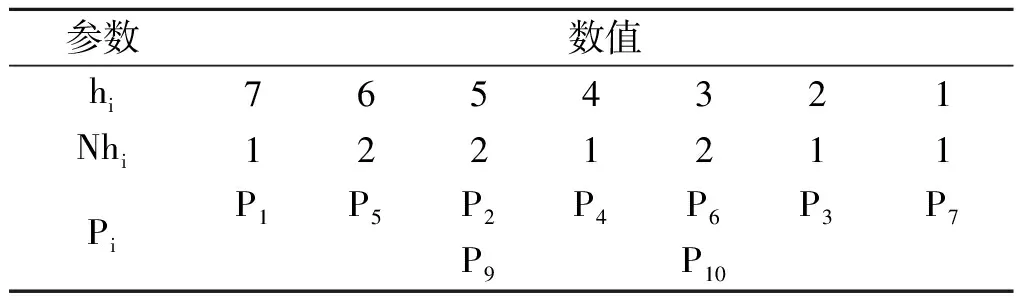
表2 丢失数据包的Hash表Table 2 The Hash Table of missing packet
2.2Hash邻域最大值搜索
根据丢失分组的Hash表,IWONCR在邻域范围通过最大值搜索符合条件的丢失数据包组合,如果组合唯一则进行编码重传,否则需要进行接收端缓存容量优化选择来选出进行重传的编码包组合.当所有的丢失数据包都被搜索完成之后,此步骤完成.邻域搜索相对于一般的逐行逐列的扫描判断,极大地缩小了搜索的范围,大大降低了搜索过程所需的时间,提高了搜索效率.同时,IWONCR优先重传能让更多节点恢复其丢失数据包的编码组合,也就是让每次的重传收益最大化.
根据文献[12],当数据分组为P1,P2,…,Pn(n∈{1,2,…,M}),对应的Hash值分别为h1,h2,…,hn,当满足
Fi(h1,h2,…,hn)≤1i=1,2,…,N
(3)
由P1,P2,…,Pn编码组合而成的数据分组对所有接收节点可解,其中Fi表示全部hj(1≤j≤n)用二进制表示下其第i比特之和.特别的,当满足
Fi(h1,h2,…,hn)=1i=1,2,…,N
(4)
P1,P2,…,Pn满足异或编码组合的全局最大值条件,也可称之为满秩条件,即每个接收节点都可以从单个重传编码包中恢复出各自所需的丢失数据包,达到重传收益的最大值.
集合U表示Hash值h1,h2,…,hn(n∈{1,2,…,M})的邻域,U表示为
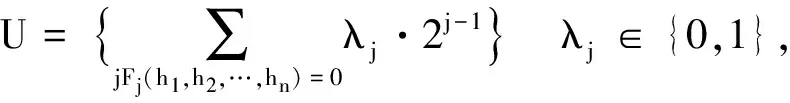
(5)
2.3 接收端缓存容量优化
IWONCR根据数据包的影响范围来确定数据包的重要性.IWONCR认为,在传输中,如果某个数据包被越少的接收端成功接收到,则该数据包在重传阶段所带来的重传影响也就越大,因此在重传过程中也应该最优先发送.而当在Hash邻域最大值搜索阶段出现多个数据包或数据包组合具有相同重传影响时,考虑到一般接收节点系统底层缓存容量的局限性,为了减少对接收节点的系统底层缓存压力,使重传数据包能尽早从底层缓存转移到应用层当中,应该让发包顺序靠前的数据包优先得到编码重传的机会,以此来对接收端系统缓存容量进行优化,减轻接收端系统缓存的压力.
每一次搜索中,在丢失包的Hash表中IWONCR优先寻找满足式(4)Hash值或Hash值组合(所有接收端都可从编码中收益),当找不到满秩条件的Hash组合时再寻找满足式(3)条件下的最大值组合,使重传收益最大化.当出现多个Hash值或Hash值组合最大值相同的数据包或数据包组合时,就根据接收端缓存容量优化的原则选择数据包索引之和更小的.由于在邻域范围中搜索Hash值,可以大幅度排除不符合条件的丢失数据包,缩小数据包搜索的范围,从而提高了数据包组合的搜索效率.在选择了一组Hash值之后,将对应的数据包进行编码组合成重传编码包.以表2所示的Hash表为例,P8为所有接收端都成功接收的数据包,因此无需重传.IWONCR首先选最大的Hash值7,对应的数据包P1直接符合满秩条件,因此进行单独传输.接着,搜索找到P5和P7,P2和P3,P4和P6三个组合包也符合满秩条件,因为最大值不唯一,因此进行接收端缓存优化处理,因此重传的顺序是P2和P3,P4和P6,P5和P7.最后将剩余不满足满秩条件的丢失包按照满足式(3)条件下的Hash值或Hash值组合从大到小进行编码重传,也就是单独重传P9和P10.
3 性能分析
3.1 重传性能
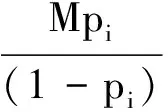
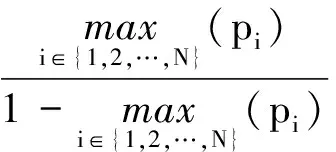
(6)
3.2 算法复杂度
本小节还是假设丢失包的个数为M个,为作比较,将传统的存储转发方法加入讨论,记为SF,由于其每次都直接对丢失包进行单独重传,单独重传一个编码包的复杂度为O(1),因此其时间复杂度为M·O(1)=O(M)级别.WONCR调度算法将在重传阶段寻找所有的M2个包的组合,因此该算法的时间复杂度为O(M2)级别.IWONCR调度算法的过程:1) 计算一个数据包Hash值的复杂度O(1),因此构建Hash表的时间复杂度为M·O(1)=O(M);2) 在Hash表当中根据不同的Hash值来搜索一个数据包的时间复杂度为常数级别O(1),因此从M个数据包中搜索选取所有丢失数据包的组合的时间复杂度为O(M).由此可以得出:IWONCR算法总的时间复杂度为O(M)+O(M)=O(M)级别,具体如表3所示.

表3 3种调度方案的时间复杂度Table 3 Time complexity of three scheduling schemes
3.3 接收端平均所需缓存容量
假设系统能实时地将底层缓存当中正确接收的满足转移要求的数据包移到应用层中,而且只考虑单一源节点发送数据的情况.在原始数据包传输阶段传输了M个数据包之后,各接收端分别有Mpi个数据包未成功接收到.当所有的丢包都连续出现在数据包序列的最后部分时达到理想情况下的最小所需缓存容量为Mpmax,同样假设每一次重传都能使每个接收端都能恢复出一个丢失数据包,因此可得理想情况下最小的接收端平均所需缓存容量(Average required cache size,ARCS)为
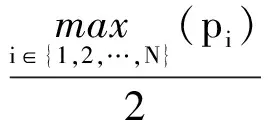
(7)
4 仿真结果
为了验证笔者提出的IWONCR方案的有效性,本节对SF,WONCR,IWONCR 3个方案的平均重传次数和时间复杂度进行了仿真实验.假设通信链路的平均丢包率为μ,各接收节点与源节点与之间的链路丢包率均匀分布在[μ-0.1,μ+0.1]范围内.经过500次的仿真,得出了3种方案的平均重传次数和计算开销,并对它们进行了比较.
4.1 平均重传次数
当接收节点个数N=5,链路平均丢包率μ=0.3时,图2(a)给出了各方案的平均重传次数随数据包数量变化的关系.WONCR,IWONCR两个方案的平均重传次数都要远小于传统的SF方案;随着数据包数量的增加,SF,WONCR,IWONCR 3个方案的平均重传次数都大致呈线性的增加,而且WONCR,IWONCR的增长幅度要明显小于SF方案,这是因为随着数据包的增加丢失数据包满足式(4)的编码组合也开始变多;WONCR,IWONCR方案的平均重传次数都比较接近于理论上的最少重传次数.当数据包数量M=100,接收节点个数N=5时,图2(b)给出了各方案的平均重传次数随丢包率变化的关系.这里可以看出:3个方案的平均重传次数都随着丢包率的增加而快速增加;WONCR,IWONCR方案的性能要好于SF方案,更接近于理论上的最小重传次数,但随着平均丢包率的增加,WONCR,IWONCR的曲线都逐渐向SF靠拢,这是因为当链路的平均丢包率μ接近1时,也就是当信道完全不可用的时候,不管SF,WONCR还是IWONCR的平均重传次数都趋向无穷大.
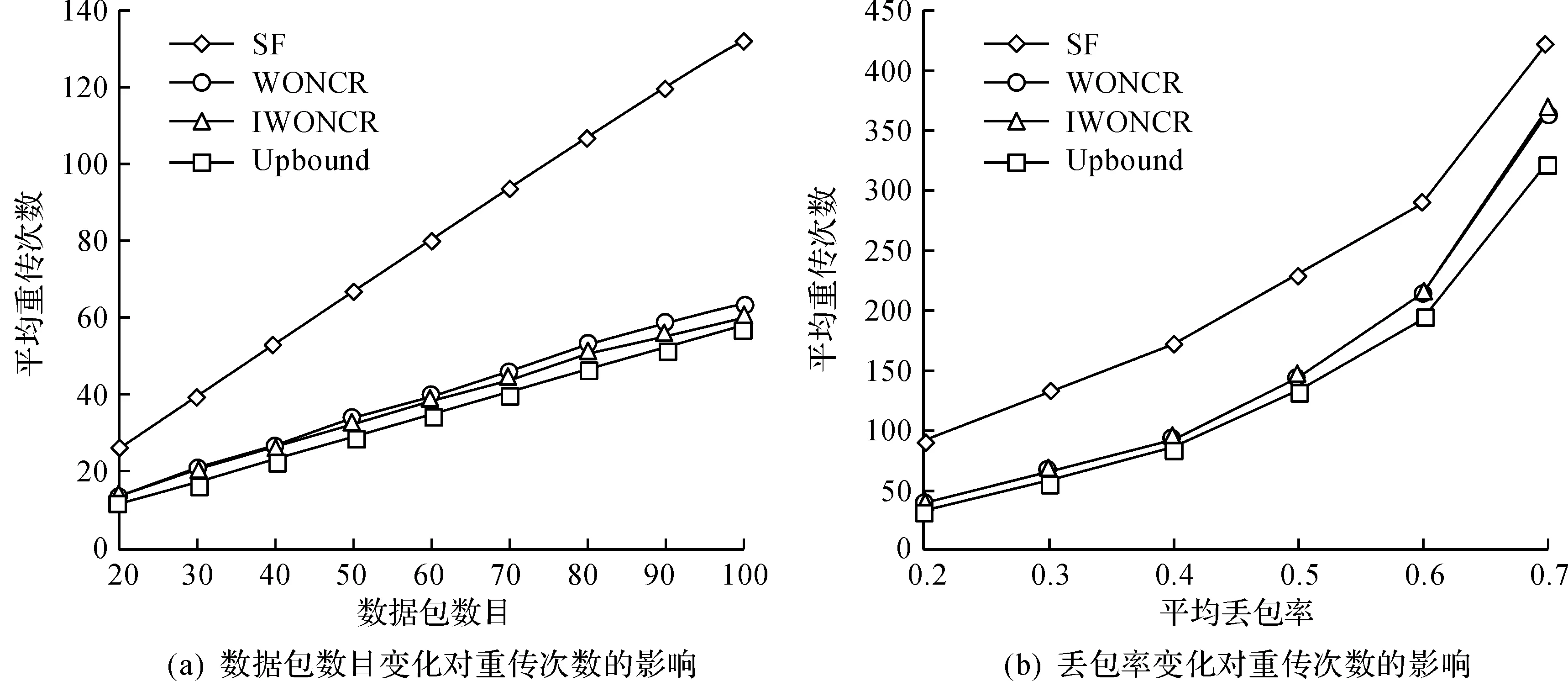
图2 各情况下的重传次数比较Fig.2 The number of retransmissions in each case
4.2 计算开销
本节对SF,WONCR,IWONCR 3种方案的运算时间进行了仿真验证,使用的仿真计算机的CPU为Intel(R) Core(TM)i3 M380 2.53 GHz,内存为6 GB,仿真实验软件为Matlab R2012a.
图3(a)给出了当接收节点个数N=5,链路平均丢包率μ=0.3时,3种方案的运算时间随数据包数目变化的比较曲线.由于SF方案不需要编码包的选取,直接重传的时间消耗非常小,导致该方案在数据包数量变化和丢包率变化下的影响可忽略不计,因此在这里我们主要比较WONCR,IWONCR这2种方案.从图3(a)里可以看出:2种方案的运算时间均随着数据包数目及丢包率的增大而增大.但WONCR方案的运算时间增长速度随数据包的增加变得越来越快,基本与数据包的增加呈平方关系,而IWONCR方案的运算时间要远远低于WONCR方案,且大致与数据包数目呈线性关系,这也与第3节当中对时间复杂度的理论分析相吻合.图3(b)给出了当数据包数量M=100,接收节点个数N=5时,3种方案的运算时间随平均丢包率变化的比较曲线.从图3(b)可以看出:在丢包率变大的情况下,IWONCR,WONCR的运算时间都随之增长,但是IWONCR方案的运算时间和增长幅度都要比WONCR方案小的多.
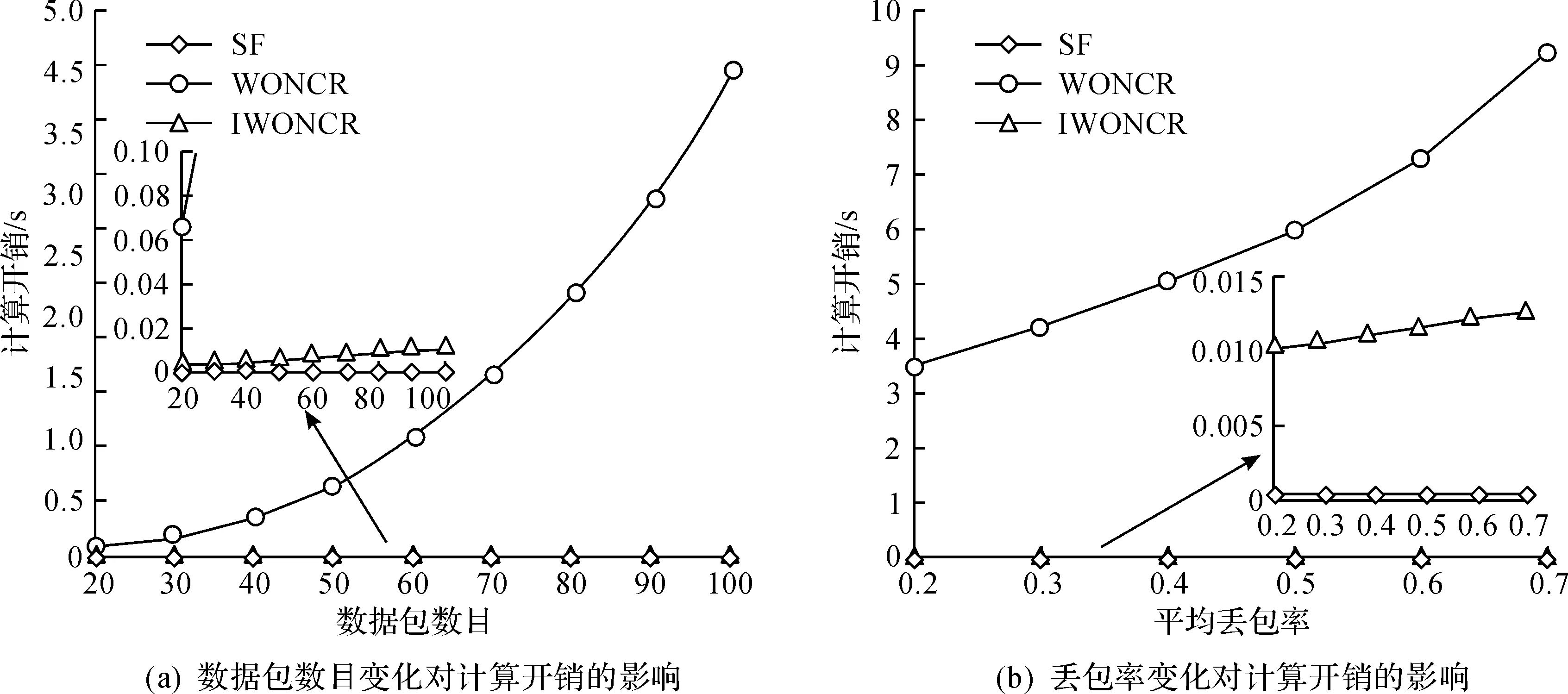
图3 各情况下的计算开销比较Fig.3 The computational cost in each case
4.3 接收端平均所需缓存容量
图4(a)给出了当接收节点个数N=5,链路平均丢包率μ=0.3时,3种方案的接收端平均所需缓存容量随数据包数目变化的比较关系.由于SF采用丢一个重传一个的策略,因此该方案不受数据包数量和平均丢包率变化的影响始终为1个数据包的缓存容量.从图4(a)可以看出:WONCR,IWONCR方案的平均所需缓存容量都随着数据包数目的增加而增加,但由于IWONCR在选包过程中针对缓存容量进行了优化,因此平均所需容量要比WONCR小.图4(b)给出了当数据包数量M=100,接收节点个数N=5时,3种方案随着平均丢包率变化的比较关系.可以看出:WONCR,IWONCR都随着平均丢包率的增大而增大;在所有情况下,IWONCR都比WONCR的接收端平均所需缓存容量要小.

图4 各情况下的平均所需缓存容量比较Fig.4 The average cache capacity in each case
由以上仿真可以看出:WONCR方案的传输效率相较于传统SF方案要高许多,但计算复杂度较高,且在选包策略上并未针对接收端缓存容量进行优化,因此在一些计算资源和系统底层缓存资源受限制的系统上实用性不强;经过改进的IWONCR方案在传输效率上与WONCR方案基本保持一致,但其计算开销和接收端平均所需缓存容量都要低于WONCR方案,因此具有更高的使用价值.
5 结 论
该方案在WONCR方案的基础上通过使用WPDM矩阵,利用Hash表和接收端缓存容量优化进行重传编码包的调度,以此提高计算效率和减轻对接收端的底层缓存压力.通过理论分析和仿真表明:改进之后的方案可以在保证与WONCR方案相同传输效率的同时降低计算时间复杂度和减少接收端平均所需缓存容量,减小接收节点的处理负荷和缓存压力,使在各链路丢包率不同的情况下基于机会式网络编码的无线广播重传算法性能得到了比较大的提升,使其能够应用到一些接收节点性能和资源受限的场景当中,譬如,卫星广播网、无线传感器网络等系统,具有较高的应用价值.
[1] AHLSWEDE R, CAI N, LI S Y R, et al. Network information flow[J]. IEEE transactions on information theory,2000,46(4):1204-1216.
[2] 龙胜春,龙军.一种应用于无线传感器网络的数据压缩方法[J].浙江工业大学学报,2014,42(2):210-213.
[3] 周晓,朱仁烽,赵锋,等.基于人工蜂群算法的无线传感器网络路由协议[J].浙江工业大学学报,2014,42(5):577-580.
[4] 彭宏,荆晶.无线自组织量子通信网络的Grover路由算法研究[J].浙江工业大学学报,2014,42(6):612-615.
[5] KATTI S, RAHUL H, HU W, et al. XORs in the air: practical wireless network coding[C]//ACM SIGCOMM Computer Communication Review. Pisa: ACM,2006:243-254.
[6] WANG Y, ZHANG Q. An approach on wireless broadcasting retransmission using network coding[C]//Wireless Communications, Networking and Mobile Computing (WiCOM), 2012 8th International Conference on Wireless Commucation. Shanghai: IEEE,2012:1-4.
[7] GONG D, YANG Y, LI H. An efficient cooperative retransmission MAC protocol for IEEE 802.11 n Wireless LANs[C]//2013 IEEE 10th International Conference on Mobile Ad-Hoc and Sensor Systems. Beijing: IEEE,2013:191-199.
[8] GO K C, CHA J R, OH S K, et al. End-to-end performance analysis based on cross-layer retransmission scheme in wireless communication system[C]//The International Conference on Information Networking 2013 (ICOIN). Bangkok: IEEE,2013:141-144.
[9] NGUYEN D, TRAN T, NGUYEN T, et al. Wireless broadcast using network coding[J]. IEEE transactions on vehicular technology,2009,58(2):914-925.
[10] 肖潇,王伟平,杨路明,等.基于网络编码的无线网络广播重传方法[J].通信学报,2009(9):69-75.
[11] 孙伟,张更新,边东明,等.卫星通信中基于网络编码改进的广播重传策略[J].宇航学报,2013,34(2):231-236.
[12] 刘期烈,吴阳阳,曹傧.无线网络中基于网络编码的重传机制[J].计算机应用,2014,34(2):309-312.
[13] 卢冀,肖嵩,吴成柯.一种基于机会式网络编码的高效广播重
传方法[J].电子与信息学报,2011,33(4):858-863.
[14] 邵鹏飞,赵燕伟,吴耀辉,等.多播网络中基于机会网络编码改进的重传方法[J].电信科学,2015,31(4):99-106.
[15] 苟亮,张更新,孙伟,等.无线网络中基于机会网络编码的加权广播重传[J].电子与信息学报,2014,36(3):749-753.
[16] SOROUR S, VALAEE S. Adaptive network coded retransmission scheme for wireless multicast[C]//2009 IEEE International Symposium on Information Theory. Seoul: IEEE,2009:2577-2581.
Animprovedweightedbroadcastingretransmissionmethodbasedonopportunisticnetworkcodinginwirelessnetworks
MENG Limin, SHAN Jianhui
(College of Information Engineering, Zhejiang University of Technology, Hangzhou 310023, China)
The weighted opportunistic network coding retransmission (WONCR) has high computational complexity in the case of different link state and high packet loss rate of wireless broadcast networks. To solve this problem, this paper proposes an improved weighted broadcast retransmission scheme based on opportunistic network coding. The scheme first constructs a weighted packet status matrix based on the feedback information of the receivers, and then creates a lost Hash table according to the matrix. Finally, according to the Hash table, the Hash neighborhood maximum search and the receiver cache optimization are used to quickly select ta packet loss combination that satisfies certain coding conditions. Then an encoding packet generated by XOR is retransmitted. It can reduce the time complexity of the retransmission scheme and the cache capacity of the receiver while maintaining high retransmission performance. The simulation results show that this method has lower time complexity compared to the existing algorithms, and can effectively reduce the computational overhead and the cache pressure of the receiver, greatly improve the usability.
wireless broadcasting network; opportunistic network coding; retransmission; optimal scheme
2016-12-23
国家自然科学基金资助项目(61372087);浙江省科技厅公益社发项目(2016C33166)
孟利民(1963—),女,浙江金华人,教授,研究方向为无线通信与网络多媒体数字通信,E-mail:mlm@zjut.edu.cn.
TP393
A
1006-4303(2017)06-0621-07
(责任编辑:陈石平)
