基于N-Gram与加权分类器集成的恶意代码检测
2017-11-23,
,
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
基于N-Gram与加权分类器集成的恶意代码检测
王卫红,朱雨辰
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
提出网页恶意脚本代码的监测系统,将恶意脚本用V8引擎编译成机器码,用变长N-Gram模型对其进行数据处理,提取特征形成样本训练集.分别与随机森林、逻辑回归及朴素贝叶斯等分类器组合创建分类模型.研究将多个经过训练集训练的分类模型集成,提出加权分类器集成的方式,每个分类器设定不同权值.通过实验分析,试验多种分类器组合,并通过训练集找出最优权值分配.通过比较单个分类器和其他集成方式,结果证明训练过的加权集成分类器的方式能更准确地检测网页存在恶意行为的代码,有较高的准确率.
恶意代码;N-Gram;机器学习
随着Web应用的发展,计算机和网络的覆盖面越来愈大,网络在人们的生活中也成为越来越重要的一部分.它改善了人们的衣食住行,人们享受着网络带来的便利,也对网络产生越来越多的依赖.截至2016年6月,中国的网民数量已经达到7.10亿,上半年增加了2 132万人,增长率为3.1%.我国网络的普及率达到51.7%,与全球平均相比,高出3.1个百分点,和亚洲平均水平相较,超过8.1个百分点,与2015年底相比提高1.3个百分点[1].人们越来越习惯网上支付,享受着线上支付的便捷.同时,在线教育、在线政务服务以及其他线上的服务越来越多.然而不法分子在网络的飞速发展中看到了可乘之机.许多不法分子利用不法手段破坏网络安全,谋取经济利益,而网站上存在的漏洞成为了他们攻击的目标,网络的飞速发展也为他们提供良好的温床.黑客使用各种类型攻击计算机和通信设施.启动这些攻击的常见方法是通过恶意软件(恶意软件),例如蠕虫、病毒和特洛伊木马,它们在传播时可能对私人用户、商业公司和政府造成严重损害.启动这些攻击的常见方法是通过恶意网站,恶意网站的代码往往包含病毒、蠕虫或者特洛伊木马.反病毒供应商每天都面临大量(数千)可疑文件.这些文件从各种来源收集,包括专用蜜罐,第三方提供程序或者用户提交的报告文件.高效并且有效地检查大量的文件是一个庞大的工程.对于信息安全,越来越多企业和甚至国家开始重视,特别是对恶意代码的检测的研究,已经成为了信息安全研究的重点.
从行为分析的角度来看,现在的检测方式大致分为静态检测和动态检测.再根据分析过程中是否考虑恶意代码的程序语义可以把恶意代码分析方法分成基于代码特征的分析方法、基于代码语义的分析方法、外部观察法和跟踪调试法四种.基于代码特征的分析方法[2]和基于代码语义的分析方法是常用的静态检测方法,而提取网页特征,基于数据挖掘和机器学习的检测技术也是当前研究的热点.对于网页恶意代码的检测可以看成是对网页代码的分类,属于恶意还是非恶意.恶意代码检测就是利用机器学习对代码进行分类.动态检测[3]主要是外部观察法和跟踪调试法.基于蜜罐技术[4]是现在常用的动态检测的方法,蜜罐顾名思义,就像是一个蜂蜜罐子,就像一个陷阱一样引诱黑客来攻击,然后记录下黑客的行为,和对方的重要信息.研究人员通常会故意留下漏洞,但一切情况都处于掌握之中.蜜罐有服务器端蜜罐和客户端蜜罐两种.前者部署在服务器上等待黑客的攻击,并且记录下黑客的信息.后者模仿客户访问网站等客户端行为,主动出击获取恶意行为的信息.动态的检测方法能详细地记录信息,但是检测速度较慢,并且部署麻烦.
1 相关工作
静态分析的检测方法是现在恶意代码检测的热点.付垒朋等针对混淆代码进行处理,先提取脚本的混淆特征,用c4.5决策树分析脚本并且接触混淆[5].徐青等分析大量网页恶意代码,根据url重定向、攻击过程、混淆和基本统计四个方面提取特征,采用多种机器学习的分类方法进行检测[6].李道丰等针对跨站脚本漏洞、ActiveX空间漏洞和WebShellcode方面使用行为语义分析的方式,对恶意代码进行检测[7].Shabtai等提出针对Opcode[8]用N-Gram提取特征,然后用机器学习的分类方法进行检测[9].
在机器学习分类方法上,朴素贝叶斯是当前常见的分类器.随机森林分类器是当前恶意代码检测中较热的算法.贺鸣等分析多种特征选择的方法及ALOFT等改进特征选择,还分析了加权、避免平滑等朴素贝叶斯算法改进[10].卢晓勇等提出对训练集使用采样技术形成多个子训练集,然后训练出多个随机森林分类器进行集成[11].
根据以上研究,提出了使用V8引擎将JavaScript代码编译成机器码,使用混合N-Gram提取特征值,并集成多种机器学习分类器,实现加权集成分类器恶意代码检测[12-15].
2 研究方法
2.1 系统模型
如图1所示,研究分三部分:第一部分恶意代码单个分类模型和集成分类模型的训练,第二部分加权集成分类模型训练,第三部分恶意代码分类测试.
训练集分成两类:第一类,从malware.com上下载的恶意脚本代码,和用爬虫软件从恶意网站获取恶意代码,第二类从github下载正常网页代码,和用爬虫软件从正常安全网站获取正常代码.
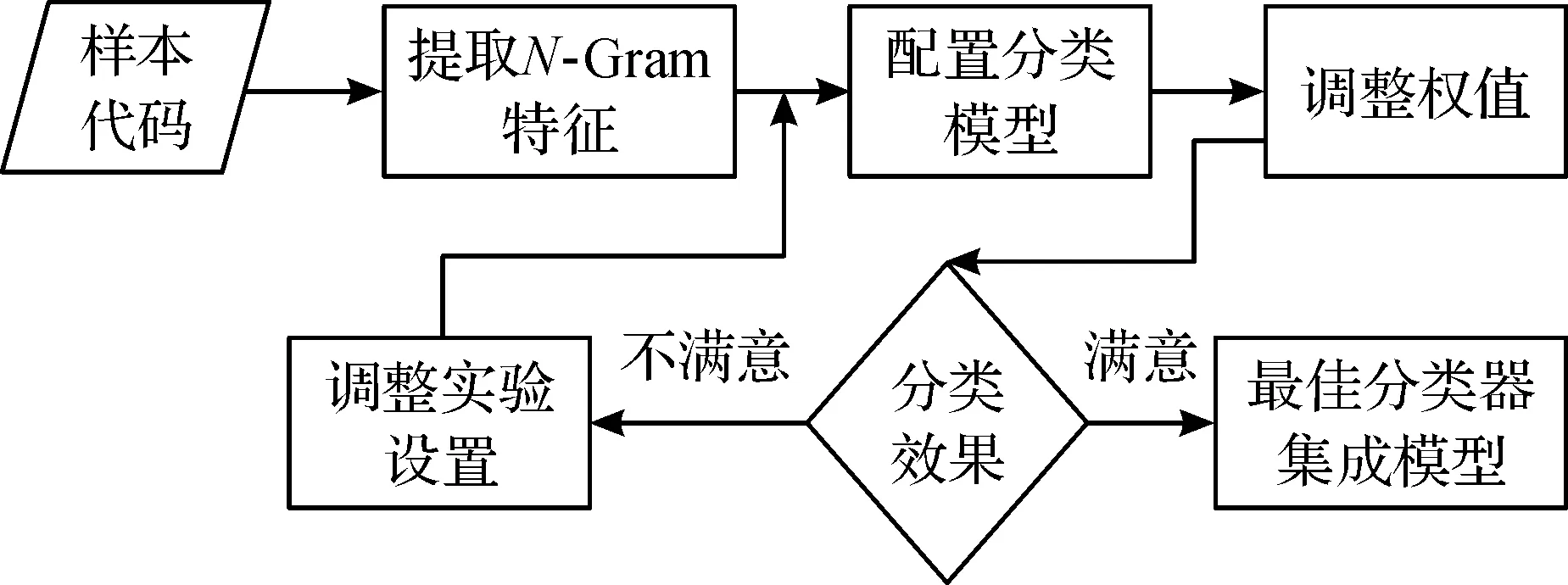
图1 分类器加权集成模型建立流程图Fig.1 Classifier weighted ensemble model flowchart
2.2 变长N-Gram特征提取
N-Gram是大词汇连续语音识别中常用的一种语言模型,该模型认为,第N个词的出现与其他任何词都不相关,只与前面N-1个词有关.这些概率可以通过直接从语料中统计N个词同时出现的次数得到.常用的是二元的Bi-Gram和三元的Tri-Gram.
使用常用的Bi-Gram对恶意代码的样本进行处理,将样本代码处理成一个个连续的单词{word1,word2,word3,word4,word5},经过Bi-Gram处理后,变成特征值{[word1,word2],[word2,word3],[word3,word4],[word4,word5]}.对所有样本处理后,获取所有的特征值,并对每个样本的出现的特征值数量进行统计:
输入:训练集样本代码train_file
测试集样本代码test_file
输出:训练集特征文件trainIns_file
测试集特征文件testIns_file
For each train_file
读取代码所出现的所有单词,并统计相邻的两个出现的个数.
While每个样本
End
混淆是在恶意代码中常出现的技术.被混淆的恶意代码无法简单的使用N-Gram来提取特征.这里使用V8引擎将JavaScript代码编译成本地机器码.V8是Google Chrome浏览器内置的JavaScript脚本引擎.它在设计之初就以高效地执行大型的java script应用程序为目的.V8的性能提升主要来自三个关键部分:快速属性访问、动态机器码生成和高效的垃圾收集.这里利用的就是V8引擎动态机器码的生成.V8引擎通过就是编译的方式将JavaScript代码编译成机器码,不会产生中间码.对编译后的机器码用N-Gram来提取特征可以有效地避免混淆的干扰.
固定长度的N-Gram提取特征,容易将有意义的序列分开.这里利用信息增益来混合Bi-Gram和Tri-Gram的方式提取特征来避免这个问题,其表达式为
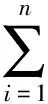
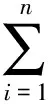

统计训练集出现的所有特征值的频率,各选取TOP500作为特征值.在对每个样本进行特征值统计时,原本一个个连续的单词{word1,word2,word3,word4,word5},经过Bi-Gram处理或者Tri-Gram处理后,变成特征值{[word1,word2],[word2,word3],[word3,word4],[word4,word5]}或者{[word1,word2,word3],[word2,word3,word4],[word3,word4,word5],[word4,word5,word6]}.现在比较[word1,word2]与[word1,word2,word3],当两者都为特征值时,比较两者的信息增益,信息增益较高的特征值加一,另一个特征值不变.同理,比较[word2,word3]和[word2,word3,word4],直到统计完所有样本,如图2所示.
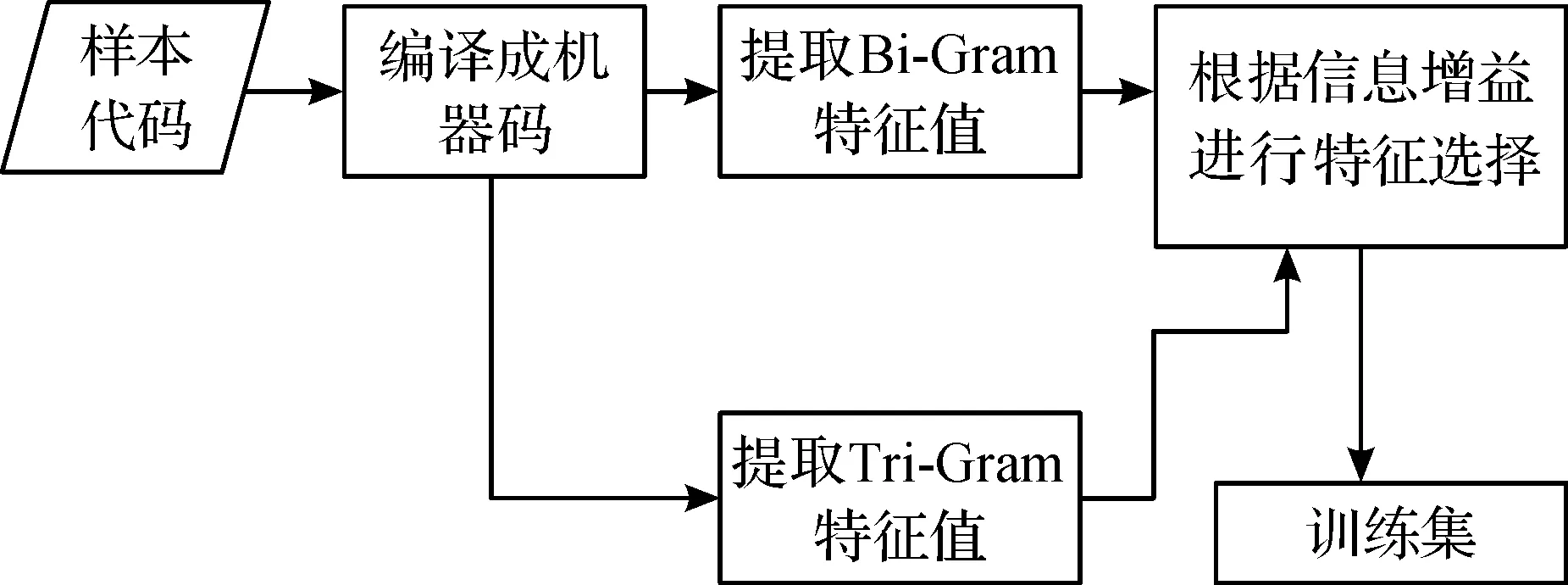
图2 变长N-Gram提取混淆代码特征流程图Fig.1 Variable length N-Gram extract obfuscation code feature flowchart
2.3 分类器
分类简单的理解就是将一个未分类的样本分到几个已知的类别.分类主要分两部分:第一部分,利用已知分类的样本,抽象出它的特征,分析并且建立模型,即用训练集来训练分类器;第二部分,则是用训练好的分类器对未知的样本,根据他们的特质,进行分类.所以分类器是分类中的关键.
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.朴素贝叶斯分类是一种十分简单的分类算法,朴素是指特征条件独立,即为基于贝叶斯定理的特征条件独立的分类算法.贝叶斯定理为

式中:p(y|x)为在x发生的条件下,y发生的概率;p(x|y)为在y发生的条件下,x发生的概率.
证明设a={a1,a2,a3,…,am}为一个待分类项,而每个a为x的一个特征属性.
有类别集合y={y1,y2,y3,…,ym}
计算p(y1|x),p(y2|x),p(y3|x),…,p(yn|x)
如果p(yk|x)=max{p(y1|x),p(y2|x),p(y3|x),…,p(yn|x)}
则x∈yk
对于朴素贝叶斯算法可以理解为对于要分类的样本,求该样本出现的条件下各个类别出现的概率,概率最高的分类就是该样本的分类.
随机森林算法是恶意代码检测中常用的分类算法.随机森林,就是用随机的方式建立一个包含多棵决策树的森林.由训练集集训练随机森林,随机地创建每一颗随机树,每棵树之间没有关联.对于一个待分类的样本,由森林中的每一棵决策树分对其进行分类,根据输出的类别的众数来分类,简单地说,就是哪一类被树最多的选择,这一类就是该样本的分类.
随机森林通过随机有放回的抽取训练集的样本,然后随机选取一定数量的特征,用完全分裂的方式建立出决策树.每棵树的分类能力都不强,但是有很强的多样性.每一个树在窄领域的分类能力都很强,因为每棵树都是由少量特征值训练出来的,然后多棵在不同领域有很强分类能力的树组合起来,对一个样本进行分类,从各自的角度对他进行分类,最后被选择更多的分类,就是该样本的分类.
2.4 集成分类器
单个分类器有各自的优劣,也有不同的分类准确率.集成分类器就是同时使用多个训练好的分类器,结合各自的优点,对测试集进行分类,准确率往往高于使用单个分类器.用专家投票系统对三个分类器进行集成.分别用训练集对三个分类器单独进行训练,然后对测试集进行测试.三个训练好的分类器分别对单个样本进行分类,计算出该样本分类的分布律.每个分类器分别根据分布律投票,投票数最高的分类为该样本的分类:
输入:训练集特征文件trainIns_file
使用的分类器集合Classifier[]
测试集特征文件testIns_file
输出:样本的分类结果
For each Classifier[]
Classifier.Build(trainIns_file)
end
For each testIns_file
For each Classifier[]
Probs[]=Classifier.distrubution(trainIns_file)
End
For each Classifier[]
If Probs[1]>Probs[2]
Vote[1]++
Else
Vote[2]++
投票数最高的为该样本分类
End
基于专家投票的分类器集成是最简单的集成方式,可以将多个分类器集成,结合各自的优点使得分类效果更好.但是专家投票的方式也有一个问题,因为对测试的样本分类时,每个分类器分别对其进行分类,并对分类结果投票,所以每个分类器给出的结果都是1.但实际上,每个分类器在分类时,给出的结果并不是1,因为并不是百分百确定.当某些样本很难分辨时,实际给出的结果可能两者都很接近0.5,所以这样的误差就很大.为了解决这个问题,提出了根据分类的概率来集成分类器.同时,因为每个分类器的分类效果并不同,为了解决每个分类器贡献相同的问题,又引入权值.每个分类器的权值相加为1,通过训练获得最好的权值分配组合,得到最终分类模型,如图3所示.
对单个样本分类的过程很简单.分别用训练集对三个分类器单独进行训练,然后对测试集进行测试.对每个分类器设有不同的权值,三个训练好的分类器分别对单个样本进行分类,计算出该样本分类的分布律.将每个分类器计算出来的分布律乘以各自的权值,获取最终概率,根据最终概率获得分类:
输入:训练集特征文件trainIns_file
使用的分类器集合Classifier[]
测试集特征文件testIns_file
输出:样本的分类结果
For each Classifier[]
Classifier.Build(trainIns_file)
end
For each testIns_file
For each Classifier[]
Probs[]=Classifier.distrubution(trainIns_file)
End
For each Classifier[]
ReProbs[]=ReProbs[]+Probs[]*Weight
End
For each ReProbs[]
ReProbs[i]=max(ReProbs[])
i为分类结果

图3 加权分类器集成训练过程Fig.3 Weighted classifier ensemble training process
2.5 机器学习的评估标准
在机器学习中如果分类只要有两类,那么:True positives(TP)为本身是正例并且也被分类器划分成正;False positives(FP)为本身是负例但是被分类器划分成正;False negatives(FN)为本身是正例但是被分类器划分成负;True negatives(TN)为本身是负例并且也被分类器划分成负.
精确率是机器学习重要评估标准.精确率是指被分为正的样本里本身的确为正的概率,即
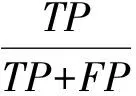
准确率(Accuracy)为
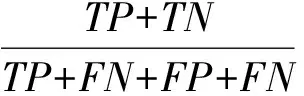
精确率(Precision)和准确率(Accuracy)是不一样的.而召回率也是重要的评估标准,它表示的是本身为正例的样本有多少被正确分类了,即

3 实验与分析
实验数据分两部分:恶意脚本代码从Walmare等网站下载样本,爬虫软件从恶意网站获取;正常脚本代码从GitHub下载,爬虫软件从安全网站获取.
使用的机器学习工具为Weka.Weka的全名是怀卡托智能分析环境(Waikato environment for knowledge analysis).Weka是一个可视化的机器学习工具,能更加便捷明了地对数据进行处理、分类和聚类等,并且也集合了大量的机器学习算法.
将所有样本用V8引擎编译成机器码,机器码包含变量名,存储地址等无意义的干扰项,排除这些干扰,仅对机器码的操作指令使用Bi-Gram和Tri-Gram统计训练集出现的所有特征值的频率,各选取TOP500作为特征值.根据信息增益对每个样本进行混合N-Gram统计,获得训练集.
使用常用的分类器单独对样本进行机器学习,采取的是10fold训练,即将样本分成十份,九份用于训练,剩下一份用于测试.实验结果表明:单个分类器中随机森林的精确率最高,效果最好,逻辑回归的效果最差,如表1所示.

表1 单个分类器分类准确率Table 1 Classification accuracy of single classifier %
如表2所示,选择随机森林、随机树和朴素贝叶斯等与随机森林、随机树以及逻辑回归为组合进行专家投票集成.实验发现集成分类器的准确率,召回率都低于随机森林.随机森林分类器因为两个随机性的引入,使得随机森林不容易陷入过拟合,具有很好的抗噪声能力,多棵树的专家决策使其分类作用远远强于其他分类器,而一人一票的专家投票使得所有分类器贡献相同,分类效果反而变差,所以引入权重来提高集成效果.

表2 不同分类器专家投票集成Table 2 Classifier expert voting integration %
所以引入权值,对分类效果最好的三个分类器随机森林、随机树和朴素贝叶斯进行加权集成.使用测试集将最小单位设为0.01进行试验,实验结果表明在以最小单位为0.01的权值组合中,0.08,0.9,0.02的组合的分类准确率最高,即随机森林的权值为0.8,随机树的权值为0.03,朴素贝叶斯的权值为0.17,准确率也达到了0.957,如表3所示.由表3可以看出:权值的引入,避免了所有分类器贡献相同的弊端,使随机森林分类器在分类过程中占主要作用,同时发挥了集成分类器使分类器功能互补的作用,提高了分类效果.

表3 随机森林、随机树和朴素贝叶斯加权集成Table 3 Random forest, random tree, naive Bayesian weighted ensemble %
虽然引入权值来集成分类器效果上有所提升,但可以看到在这三个分类器组合中,随机树的权值分配非常的低,在分类过程中的贡献非常的小.Weka工具中的随机树分类器和决策树类似,但和决策树相比,随机树并不选取所有属性,会随机选择若干属性构建树.在weka的实现中,随机树分类器,设置要选取的属性数量k,对属性无放回的抽样,再根据信息增益选择分裂节点,构建树.这个方式和随机森林中的单棵树的构建方式非常类似.所以在集成的时候,随机树的作用被随机森林覆盖,并不能更好的提升集成分类的效果.
所以将随机树的分类器替换成逻辑回归分类器重新进行实验.也先将最小单位设置为0.01.逻辑回归的权值为0.12,随机森林的为0.78,随机树的权值为0.1时,精确率最高,达到0.96,如表4所示.

表4 随机森林、朴素贝叶斯和逻辑回归加权集成Table 4 Random forest, naive Bayes, logistics weighted ensemble %
如图4所示,实验发现:朴素贝叶斯、随机森林和逻辑回归这三个模型的加权组合精确率.逻辑回归可用于概率预测,也可用于分类,经常被用于根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大,并且逻辑回归不像朴素贝叶斯一样需要满足条件独立假设.但每个特征的贡献是独立计算的,即逻辑回归是不会自动帮你联合不同的特征产生新特征的.同时因为引入权重,合理的分配了三个算法的贡献,使得分类效果提高.
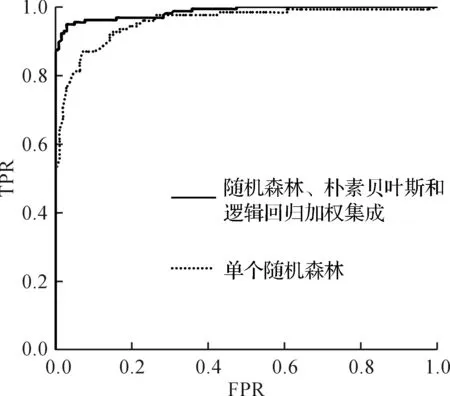
图4 加权集成和随机森林ROC曲线对比图Fig.4 Weighted ensemble and random forest ROC curve comparison chart
将这个训练好的模型用于实际检测.火眼和VirusTotal是常用的在线检测的网站.用户提交待检测文件或者网址,火眼是通过动态检测,VirusTotal主要是通过静态检测.分别从两个网站下载150个样本,并且自己用爬虫软件从网上随机获取300份样本代码.将这200份样本分别通过加权分类器集成模型、火眼和Payload security检测.可以发现:通过集成加权模型检测检测率高于Payload security的静态检测,接近于火眼的动态检测,如表5所示.
表5分类器加权集成、火眼和Payloadsecurity对比结果
Table5Classifierweightedensemble,fireeye,payloadsecuritycomparisonresults个

4 结 论
提出了一种对网页恶意脚本代码的静态监测系统,并将恶意脚本用V8编译成机器码.用变长N-Gram模型进行数据处理,提取特征形成样本训练集.使用训练集对随机森林、逻辑回归、朴素贝叶斯和随机树分类器进行训练创建分类模型,并将其集成.实验比较了单个分类器、多个分类器普通集成和多个分类器加权集成,发现加权集成的方式能有效地提高分类准确率.同时通过实验,找到了最佳的分类器组合和最佳的权值组合.
[1] 中国互联网信息中心.CNNIC发布第38次《中国互联网络发展状况统计报告》[J].信息网络安全,2016(8):89.
[2] 黄建军,梁彬.基于植入特征的网页恶意代码检测[J].清华大学学报(自然科学版),2009(S2):2208-2214.
[3] ALAM S, HORSPOOL R N, TRAORE I, et al. A framework for metamorphic malware analysis and real-time detection[J]. Computers & security,2015,48:212-233.
[4] 诸葛建伟,唐勇,韩心慧,等.蜜罐技术研究与应用进展[J].软件学报,2013(4):825-842.
[5] 付垒朋,张瀚,霍路阳.基于多类特征的JavaScript恶意脚本检测算法[J].模式识别与人工智能,2015(12):1110-1118.
[6] 徐青,朱焱,唐寿洪.分析多类特征和欺诈技术检测JavaScript恶意代码[J].计算机应用与软件,2015(7):293-296.
[7] 李道丰,黄凡玲,刘水祥,等.基于行为语义分析的Web恶意代码检测机制研究[J].计算机科学,2016(8):110-113.
[8] SANTOS I, BREZO F, BRINGAS PG, et al. Opcode sequences as representation of executables for data-mining-based unknown malware detection[J]. Information sciences,2013,231(9):64-82.
[9] SHABTAI A, MOSKOVITCH R, FEHER C, et al. Detecting unknown malicious code by applying classification techniques on OpCode patterns[J]. Security informatics december,2012(1):1-22.
[10] ALAM S, SOGUKPINAR I, TRAORE I, et al. Sliding window and control flow weight for metamorphic malware detection[J].
Journal of computer virology and hacking techniques,2015,11(2):75-88.
[11] 贺鸣,孙建军,成颖.基于朴素贝叶斯的文本分类研究综述[J].情报科学,2016(7):147-154.
[12] 卢晓勇,陈木生.基于随机森林和欠采样集成的垃圾网页检测[J].计算机应用,2016(3):731-734.
[13] 林冬茂.基于“写”操作的Web安全防护系统的研究[J].浙江工业大学学报,2012,40(2):201-204.
[14] 严萍,史旦旦,钱能.计算机信息安全交换系统的设计[J].浙江工业大学学报,2004,32(4):23-27.
[15] 周梦麟,张森.一种基于自然语言理解的Web挖掘模型[J].浙江工业大学学报,2004,32(1):97-100.
ThemaliciousscriptcodedetectionbasedonN-Gramandweightedclassifierintegration
WANG Weihong, ZHU Yuchen
(College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China)
This paper proposes a static monitoring system for detecting malicious script code. In this system, malicious script code is compiled into machine code with V8 engines and theN-Gram model is used to process the machine code and the features are extracted to form the sample training set. The classification model is created by combining with random forest, logistic regression, Naive Bayes classifier respectively. In this paper, classification models which are trained in multiple training sets are integrated and a way of weighted classifier integration is proposed. Each classifier is set a different weights. Through experimental analysis, a variety of classifiers are combined and tested, and the optimal weight is found through the training set. assignment. By comparing the individual classifier and other integrated approach, the results show that the trained weighted classifiers can be more accurate to detect malicious codeand have higher accuracy.
malicious script;N-Gram; machine learning
2017-02-20
王卫红(1969—),男,浙江临海人,教授,研究方向为空间信息服务和网络信息安全,E-mail: wwh@zjut.edu.cn.
TP301
A
1006-4303(2017)06-0604-06
(责任编辑:陈石平)
