基于文档相似度的双语文档排序学习∗
2017-11-17黄健
黄 健
(昆明理工大学智能信息处理重点实验室 昆明 650500)
基于文档相似度的双语文档排序学习∗
黄 健
(昆明理工大学智能信息处理重点实验室 昆明 650500)
论文提出了一种双语文档排序学习模型。排序是信息检索系统中重要的一个环节,学者们已经对单语言环境下的文档排序学习问题进行了很多的研究,但是多语言语境下的文档排序问题并没有得到很大的重视。在双语文档集合中,文档是用两种不同语言写成的,所以我们并不能使用已有的单语言排序学习模型直接对双语言文档进行排序。在单语言排序学习模型的基础上,提出了一种基于双语文档相似度的双语文档排序学习方法。为了能够把源语言文档和目标语言文档关联起来,提出了一种基于双语word embedding的双语文档相似度计算方法。通过简单地把源语言查询翻译为目标语言,达到筛选目标语言文档的目的。实验结果表明,该方法在英汉和英越两种语境下都取得了较好的效果。
排序学习;信息检索;文档相似度;查询翻译;双语语境
1 引言
机器学习技术已经在很多信息处理任务中被证明是一种有效的解决方案。如今我们的社会无时无刻不在产生数字媒体,如电子出版物,网页以及软件日志等,快速地定位及提取有用的信息对于信息检索系统是十分重要的。准确地对信息载体进行排序是我们能够高效地取得有用信息的必要条件。研究者们的成果表明,机器学习是解决排序问题的有效途径。排序学习模型使得我们可以不必人工定义排序的规则;我们只需要定义一个合理的排序函数,该函数包含若干影响排序结果的参数,并且在模型训练的过程中对这些参数进行调优即可。这使得我们可以跨过很多对排序影响因素的研究,并且使得对一个排序系统的调优变得更加灵活。
排序学习技术已经被应用在对单语言文档进行排序的问题中,并且得到了很好的效果[1~2]。排序学习任务包括两个环节,模型训练环节以及排序应用环节。模型训练环节被定义为两部分,排序函数和损失函数。排序函数通常包含一定数量的参数,这些参数要在训练过程中进行调节。训练数据中的每一个条目都包含一个文档特征向量以及对应该文档的排序打分。这些特征被从文档的各个方面抽取出来,如文档标题的语义信息,查询中每个词语在训练文档集中的TF-IDF(term frequency-inverse document frequency)值,以及网页文档的page rank值等。排序函数以这些特征向量为输入并输出当前参数值对应的输出。损失函数用来定义当前排序函数的排序结果和训练数据提供的排序结果之间的差值,即排序错误值。通过在训练过程中对排序错误值进行最小值优化来对排序函数中的参数进行调节,最终完成对排序模型的训练调优。对排序函数的排序错误值进行最小值优化的方法通常是基于梯度下降的原理,如SGD(stochastic gradient descent)和动量优化等方法。
研究者们提出了一些单语言语境下对文档进行排序学习的模型,包括基于点,基于对和基于列表的方法[3~5]。不同类型的排序学习模型采用不同的模式来提取训练数据中的排序信息。例如,基于点的排序模型依次从训练数据中取出一条记录来提取排序信息,对排序函数中的参数进行调优;而基于列表的模型每次从训练数据中取出一组记录,从这组记录中得到不同文档排序先后结果的概率分布,以此来对排序函数中的参数进行调优。
目前双语语境下的文档排序学习并没有得到太多的关注。双语文档排序的一个典型应用场景是搜索引擎,比如,我们在搜索引擎中搜索“机器学习”这个短语,我们通常只能得到中文的网页结果,但有时候我们不仅想要得到查询语言的返回结果,又要得到某些外语的查询结果,比如对应于英文“machine learning”的网页文档,现有的单语言排序算法显然不能满足这个需求。因此,我们提出了一种可以对双语文档,或者更普遍的,对多语言文档进行排序的机器学习模型。
为了阐述方便,我们把在搜索时使用的查询语言叫做源语言,把与源语言不同的其它外语叫做目标语言。本文余下部分组织如下:第2部分介绍与排序学习相关的背景知识,在第3部分说明如何计算一个源语言文档和一个目标语言文档之间的相似度,我们在第4部分介绍基于双语word embedding的查询翻译,第5部分给出了我们的模型在英汉和英越两种语境下的实验结果,最后在第6部分对我们的工作进行总结。
2 相关工作
排序学习采用机器学习的方法对对象进行排序。在对文档进行排序学习的情况下,例如对网页以及文本文档等进行排序,机器学习需要的特征来自于文档的内容和结构。目前,基于列表的文档排序模型达到了最高的排序准确率,我们的双语模型中的单语言模型采用基于列表的ListNet模型来分别对源语言文档和目标语言文档进行排序打分。
研究者们在多语言信息检索方面做出了一些基础性的工作。多视角排序学习把文档的不同语言翻译看作是文档不同视角的实体,对每个视角采用排序函数进行排序,最后通过对所有视角的排序函数进行全局一致性规划来对最终的排序模型进行调优[6]。多视角的排序模型需要得到同一文档的不同语言翻译的版本,因此其训练过程中需要的训练语料通常很难获取。我们模型的训练过程不需要多种语言的文档语料,而是在词语级别对不同语言的文档进行相似性计算,因此具有更大的灵活性,并且更加易于实现。
学者们提出了几种单语言及多语言语境下的计算词语相似性的方法。双语word embedding在单语word embedding的基础上,利用机器学习语义对齐的方法把双语的词语映射到一个低维空间[7]。在这个低维空间中,词语之间的距离代表它们之间的相似性,两个词语之间的距离越小,其相似性越强。基于这一词语相似度计算模型的短语翻译实验表明,双语word embedding提供了一种简单有效的计算双语词语相似度的方法,因此也能够为双语文档相似度的计算提供基础模型。
查询翻译已经被证明是一种有效的多语言信息检索方法[8],但是还没有被应用到文档排序学习任务中。我们在词语层级上把源语言查询翻译为目标语言查询,对目标语言文档排序打分进行进一步优化。
3 基于word embedding的文档相似度计算
在双语文档排序学习中,双语文档相似度计算是关联源语言文档和目标语言文档的一种重要的方法。研究者们提出了几种度量跨语言文档相似度的方法,采用了不同的策略和方式来寻找文档之间的关系特征。基于多语言内容维基百科的方法从网页中获取同一文档对象的不同语言版本,以此为根据来得到相关性高的文档集合的特征,从而达到对任意两个不同语言文档进行相似度计算的目的[9]。基于文档表示和度量策略的两阶段模型把不同语言的文档用同一个空间中的向量进行表示,并采取符合文档相似度计算特征的度量方法对空间文档表示进行相似度计算[10~11]。一些研究者们把模糊集应用到了文档相似度计算中,把文档中的所有词语用一个模糊集合进行表示,以此为特征对文档进行相似度计算[12]。这些方法都试图在文档语义的基础上对文档进行相似度度量,而目前的文档语义方面的研究并没有达到很好的效果,不能够很好地支撑文档相似度计算的精度。在排序任务中,文档之间的相似度更注重文档主题的联系性,并不需要对整个文档的语义进行全部表示,由此,基于文档关键词的文档主题可以作为对文档相似度进行计算的度量标准,使得文档相似度模型简单而且有效。
文档由组成它的词语集进行表示,文档中TF-IDF值最大的N个词语可以由下面的公式得到:
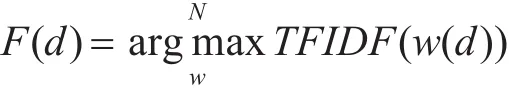
其中d是一个文档,F(d)是包含文档关键词的向量。文档之间的相似度可以计算为
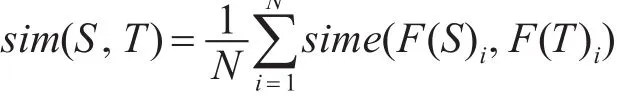
其中S为源语言文档,T为目标语言文档。sime是基于双语word embedding双语词语相似度的文档相似度计算函数,该函数遵守以下规则:如果源语言文档中的一个关键词语在目标语言文档中拥有一个相似的目标语言关键词语,或者说目标语言文档中有一个关键词语与源语言文档中的一个关键词语的直接翻译相似,该函数的结果值相应增加。这是一种简单直观的度量文档相似度的方法,并且我们的实验证明了该方法对于我们的模型的有效性。得到了一个源语言文档和一个目标语言文档的相似度之后,目标语言文档打分的其中一个因素计算为
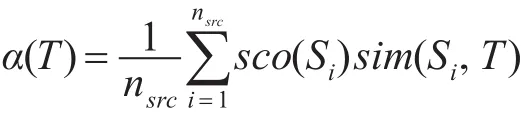
其中nsrc是与查询匹配的源语言文档的数量,sco(Oi)是源语言文档的排序打分,由单语言的ListNet模型得到。在这里我们采用了加权平均的策略来得到基于文档相似度的目标语言文档的排序打分。
4 查询翻译
在文档排序任务中,我们以查询中的词语为基本单位对文档集合进行搜索,查询中词语之间的语义关系很少被考虑在内,因此在我们的模型中,我们在词语级别把源语言查询翻译成目标语言查询。对于一个源语言查询qsrc,其对应的目标语言查询可以由下面规则得到:
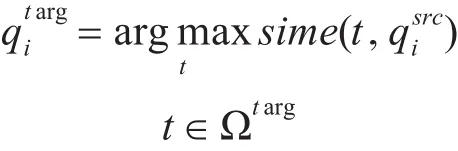
这里Ωtarg是目标语言的词语集合。在得到查询的目标语言翻译后,我们以目标语言查询为输入,用上述的单语言排序模型对目标语言文档进行排序打分,得到打分函数 β(T)。合并基于文档相似度和基于查询翻译的目标语言文档打分,得到目标语言文档的最终排序打分:
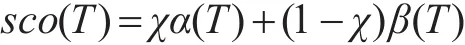
5 实验结果
在我们的实验中,我们首先在OHSUMED训练集上训练出一个单语言排序学习模型,对这个模型进行准确率评估,并把它嵌入到最终的双语模型中。接下来在英汉和英越测试语料集合上对双语模型进行排序准确率评估,最后比较单语模型和双语模型的准确率,验证双语模型的有效性。
5.1 OHSUMED语料集
OHSUMED是一个医药方面的文档和查询集合[13],包含 348566个文档和 106个查询,一共有16140个查询文档对,并且其查询相关度已经被标注出来。查询和文档之间的相关度分为三个等级,包括完全相关,一般相关和完全不相关。文档检索需要的标准特征集合从每个查询文档对中抽取出来,一共有30个特征。
5.2 单语言ListNet模型准确率
我们把OHSUMED数据集分割成五个子集,在此基础上进行五维交叉验证。在每次实验中,我们用三个子集作为训练集合进行训练,一个集合作为验证,一个集合用作准确率测试。我们采用MAP(Mean Average Percision)和 NDCG(Nomalized Discounted Cumulative Gain)两种排序准确率度量标准来评估我们的模型。表1给出了该单语言排序模型的排序准确率,说明了我们构建的单语言排序模型在对单语言文档排序的任务中取得了很好的效果,达到了目前的最高准确率,该单语言排序模型可以胜任支撑双语言模型的任务。
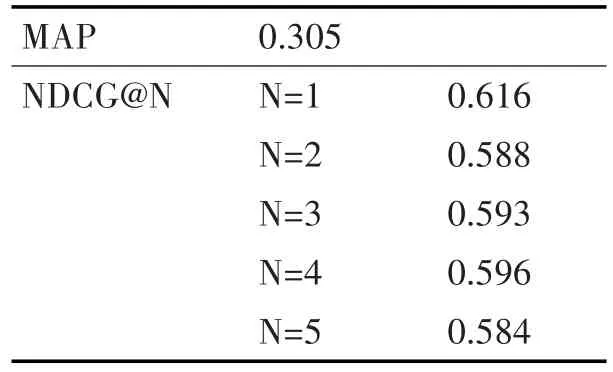
表1 单语言模型准确率
5.3 双语文档集合
我们在英汉和英越语境下分别随机选取了100个查询,共200个查询,并且为每个查询选取10个文档,最终得到2000个文档。我们分别对每个查询文档对进行相关度标注,在此基础上对双语模型进行训练和测试。表2给出了双语模型在英汉语料集合上的排序准确率,表3给出了其在英越语料下的准确率。图1对单语模型和双语模型的准确率进行了比较,比较结果表明最终的双语排序模型几乎达到了单语言排序模型的准确率。
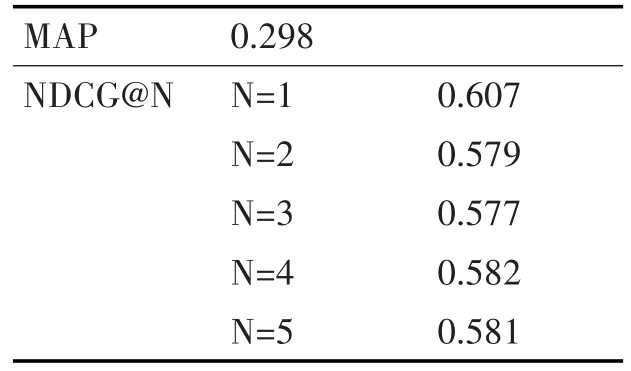
表2 双语言模型在英汉语料集上准确率
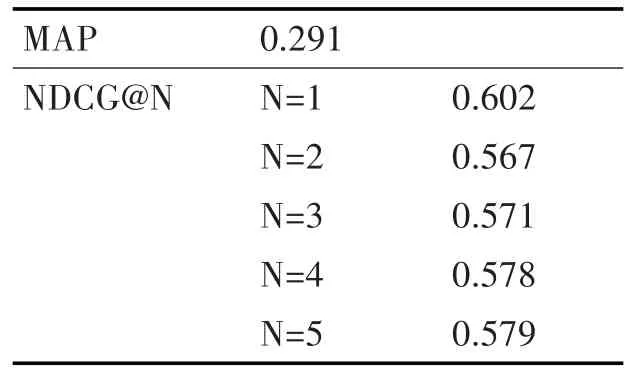
表3 双语言模型在英越语料集上准确率
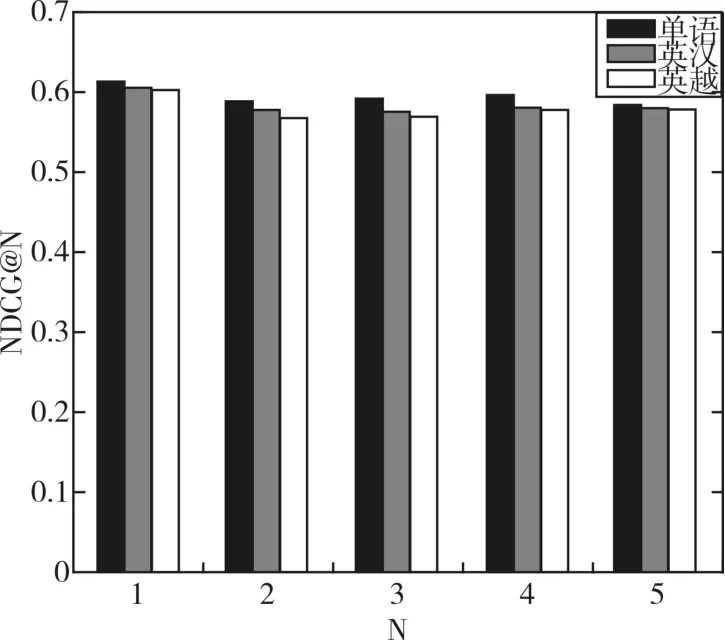
图1 单语言模型与双语言模型准确率比较
6 结语
我们提出了一种基于双语文档相似度和查询翻译的双语文档排序学习模型,并且分别在英汉和英越语境下对其进行训练和验证,达到了与单语言排序模型几乎持平的准确率。这个结果表明双语文档相似度计算是对双语文档进行排序的有效途径。我们的双语文档排序模型的准确率略低于单语言排序模型,其原因是双语文档相似度计算并没有达到理想的准确率,进一步的研究目标是要提高双语文档相似度计算的准确率,可以为文档关键词融入适当的图理论进行模型完善,并且进一步对双语文档排序打分合并模型进行加强。
[1] Burges,C.,Shaked,T.,Renshaw,E.,Lazier,A.,Deeds,M.,Hamilton,N.and Hullender,G.Learning to rank using gradient descent[C]//In Proceedings of the 22nd international conference on Machine learning.ACM,2005:89-96.
[2] Liu,T.Y.,Xu,J.,Qin,T.,Xiong,W.and Li,H.Letor:Benchmark dataset for research on learning to rank for information retrieval[C]//In Proceedings of SIGIR 2007 workshop on learning to rank for information retrieval,2007:3-10.
[3]Crammer,K.and Singer,Y.Pranking with Ranking[J].In Nips,2001(1):641-647.
[4]Cao,Y.,Xu,J.,Liu,T.Y.,Li,H.,Huang,Y.and Hon,H.W.Adapting ranking SVM to document retrieval[C]//In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval.ACM,2006:186-193.
[5]Cao,Z.,Qin,T.,Liu,T.Y.,Tsai,M.F.and Li,H.Learning to rank:from pairwise approach to listwise approach[C]//In Proceedings of the 24th international conference on Machine learning.ACM,2007:129-136.
[6] Usunier,N.,Amini,M.R.and Goutte,C.Multiview semi-supervised learning for ranking multilingual documents.Lecture Notes in Computer Science,2011,6913:443-458.
[7]Zou,W.Y.,Socher,R.,Cer,D.M.and Manning,C.D.Bilingual Word Embeddings for Phrase-Based Machine Translation[C]//In EMNLP,2013:1393-1398.
[8]Ballesteros,L.and Croft,W.B.Phrasal translation and query expansion techniques for cross-language information retrieval[C]//In ACM SIGIR Forum.ACM,1997:84-91.
[9]Rupnik,J.,Muhic,A.,Leban,G.,Skraba,P.,Fortuna, B.and Grobelnik, M.NewsAcrossLanguages-Cross-Lingual Document Similarity and Event Tracking[J].Journal of Artificial Intelligence Research,2016(55):283-316.
[10]Steinberger,R.,Pouliquen,B.and Hagman,J.February.Cross-lingual document similarity calculation using the multilingual thesaurus eurovoc[C]//In International Conference on Intelligent Text Processing and Computational Linguistics.Springer Berlin Heidelberg,2002:415-424.
Learning to Rank Bilingual Document Based on Document Similarity
HUANG Jian
(Kunming University of Science and Technology,Kunming 650500)
The problem of learning to rank bilingual documents is addressed.Ranking is an essential part in information retrieval.Ranking documents in monolingual context using machine learning has been studied a lot,but learning to rank bilingual documents has not been investigated much yet.Bilingual documents are written in different languages,they can't be processed by using existing monolingual methods directly.In this paper a bilingual learning is proposed to rank model which utilizes monolingual model to give ranking score for documents in monolingual context as a base component.A word embedding approach is introduced to measure document similarity in bilingual context,through which a relationship between documents in both languages can be made.We simply translate the query to foreign language at a phrase level to filter foreign language documents.Experiments show that our model is effective in ranking bilingual documents in both English-Chinese context and English-Vietnamese context.
learning to rank,information retrieval,document similarity,query translation,bilingual context
TP391
10.3969/j.issn.1672-9722.2017.10.020
Class Number TP391
2017年4月13日,
2017年5月19日
国家自然科学基金项目(编号:61175068,61472168);云南省关键项目科学基金项目(编号:2013FA130);科技部科学技术创新人才项目(编号:2014HE001)资助。
黄健,男,硕士,研究方向:机器学习和文档排序学习。
[11]Muhiĉ,A.,Rupnik,J.and Škraba,P..Cross-lingual document similarity[C]//In Information Technology Interfaces(ITI),Proceedings of the ITI 2012 34th International Conference on.IEEE,2012:387-392.
[12]Huang,H.H.and Kuo,Y.H.Cross-lingual document representation and semantic similarity measure:A fuzzy set and rough set based approach[J].IEEE Transactions on Fuzzy Systems,2010,18(6):1098-1111.
[13]Hersh,W.,Buckley,C.,Leone,T.J.and Hickam,D.OHSUMED:an interactive retrieval evaluation and new large test collection for research[C]//In SIGIR'94,1994:192-201.
