一种基于RLDA主题模型的特征提取方法∗
2017-11-17冯新淇任奕豪
冯新淇 张 琨 任奕豪 谢 彬 赵 静
(南京理工大学计算机科学与工程学院 南京 210094)
一种基于RLDA主题模型的特征提取方法∗
冯新淇 张 琨 任奕豪 谢 彬 赵 静
(南京理工大学计算机科学与工程学院 南京 210094)
为了准确挖掘微博用户的兴趣,论文获取并分析用户原创、转发和点赞过的微博内容以及微博热度的排行等数据,准确地得到描述微博用户兴趣的信息,然后基于LDA模型,提出了一种新的主题特征提取模型——RLDA模型。该模型在原有的LDA模型中加入了微博背景中特有的微博热度排行这一信息,从而改进LDA模型的来提高模型挖掘微博用户兴趣的准确率。在RLDA主题模型建模的过程中,引入“超超参数”的概念,通过Dirichlet分布对超参数取值进行采样。实验表明,与LDA模型相比,RLDA模型在微博用户兴趣挖掘的准确度上有了很大的提升。
兴趣挖掘;微博热度排行;RLDA模型;特征提取;超超参数
1 引言
随着微博的日趋流行,如何寻找一种有效的模型方法来挖掘出微博等社会化媒体上用户的兴趣和需求成为了当前研究的一个热点。通过对微博数据进行挖掘和分析,可以发现用户的兴趣。针对每个用户的具体兴趣,可以为用户推荐相应的信息、产品、广告等,也可以为用户推荐其可能感兴趣的用户,从而达到个性化的推荐效果[1]。
在数据挖掘领域,尽管传统文本的主题挖掘已经得到了广泛的研究,但对于微博这种特殊的文本,因其本身带有一些结构化的社会网络方面的信息,传统的文本挖掘算法不能很好地对它进行建模。提出了一个基于潜在狄利克雷分布(Latent Dirichlet Analysis,LDA)的微博生成模型 RLDA(Ranking LDA)。模型中综合考虑了用户原创、转发和点赞过的所有微博文本,并定义了微博热度排行这一概念来辅助进行微博的主题挖掘。使用Collapsed Gibbs采样方法对模型进行推导,能够在一定程度上提高微博用户兴趣挖掘的准确度。本文实验表明,RLDA模型能有效地对微博进行主题挖掘。
下面是本文的整体框架结构图:
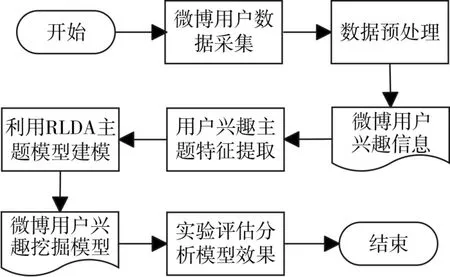
图1 论文整体框架图
主题模型一般指的是两种分布:第一种就是主题-词语的分布,就是P(w |z)。第二种是是文档-主题分布,即P(z |d)。有了这两种分布后,这个文档集合的表示就有了一种立体化的感觉[2],如图2所示,LDA主题模型具有清晰的层次结构,从上到下分别为文档层、隐藏的主题层和词语层。
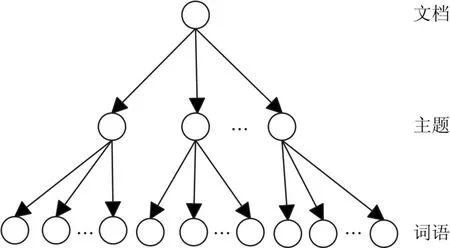
图2 LDA模型拓扑结构示意图
2 相关工作
1990年,芝加哥大学的Bell等专家[3]提出了潜在语义分析(Latent Semantic Analysis,LSA)模型。LSA主要是利用矩阵奇异值分解(Singular Value Decomposition,SVD)的方法,使得向量空间的高维表示变成潜在语义空间的低维表示,从而实现降低维度和识别主题的目的。1999年,Hofmann等[4]在LSA的基础上通过引入最大似然估计法和产生式模型的概念,提出了概率潜在语义分析模型(Probabilistic Latent Semantic Analysis,PLSA),但是在PLSA模型的计算复杂度仍然很高。Blei.David M.等[5]于2003年在LSA和PLSA的基础上进行了扩展,从而提出了LDA主题模型的概念。LDA模型可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布,然后就可以根据主题分布进行主题聚类或文本分类[6]。王志宏等[7]对传统的TF-IDF算法进行了改进和拓展,提出了融合基本IDF词典和联合兴趣度的动态IDF词典的用户个性化IDF词典,并基于改进的算法应用模型抽取微博用户兴趣的关键词。李文波等[8]提出了一种附加类别标签的LDA模型,通过在传统LDA模型中融入文本类别信息,提高了该模型的分类能力,可以计算出隐含主题在各类别上的分配量,从而克服传统LDA模型分类时强制分配主题的缺陷,有效的改进了文本分类的性能。石晶等[9]利用LDA模型为语料库和文本进行建模,采取背景词聚类及主题词联想的方式将主题词扩充到待分析文本处,挖掘词语表面中隐含的主题,提高了文本分析的效果。Xing等[10]将LDA模型和语言模型相结合,并使用聚类方法提高了检索的召回率。张晨逸等[11]针对微博这种本身就带有一些结构化的社会网络方面信息的特殊性的文本,提出了一个基于LDA的微博生成模型MB_LDA,综合考虑了微博的联系人关联关系和文本关联关系来辅助进行微博的主题挖掘。
本文也是基于LDA文本主题模型进行研究的,通过引入微博热度评价(Ranking)这一定义建立RLDA模型,从而提取文本的主题分布信息,采用Streaming Gibbs采样方法进行参数估计,然后选定Precision、Recall、F值等实验评定指标对实验结果进行分析,证明了RLDA模型比一般的LDA模型能够更准确的挖掘出用户的兴趣。
3 改进的LDA主题模型
3.1 LDA模型
LDA模型是对文本中隐含主题的一种建模方法,模型的训练过程可以用马尔科夫链-蒙特卡洛(Markov Chain-Monte Carlo,MCMC)的简化方法直接生成,并且在生成学习模型时的参数空间规模是固定的,与文本及自身规模无关[12]。其基本思想是可以随机的生成一篇有N个词语组成的文档,其中每一个词语都是根据一定的概率选择一个主题,并从这个主题中以一定概率选择出来的[12]。在LDA模型中,定义语料库中任意一篇文档的生成过程[13]如下:
1)从Dirichlet分布α中取样生成文档m的主题分布θm;
2)从主题的多项式分布θm中取样生成第m个文档的第n个词语的主题tm,n;
3)从Dirichlet分布 β 中取样生成主题tm,n对应的词语分布向量 Φtm,n;
4)从词语的多项式分布 Φtm,n中采样,最终生成词语 wm,n。
LDA主题模型的Bayesian网络图如图3所示。
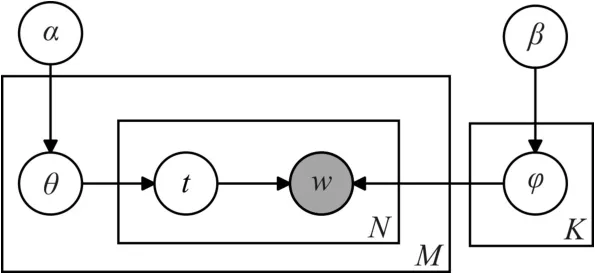
图3 LDA模型的贝叶斯网络图
图中,灰色圆圈则代表可以直接观察到的变量,透明的圆圈代表隐含的变量,这些变量在算法中都是需要推理的,箭头代表变量之间的依赖关系。M代表文档集,N代表一篇文档的长度,K代表主题的数目,θm指第m个文档的主题多项式分布,φk指第k个主题的词语多项式分布。
从上图3可以看出,LDA模型中有两组先验,文档-主题分布的先验和主题-词语分布的先验,两组分布分别来自于超参数α和β的Dirichlet分布。Θ是所有文档的主题分布向量,Φ是所有主题的词语分布向量,根据Collapsed Gibbs采样算法可以估计后验分布,得到如下公式:

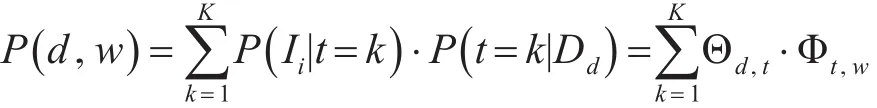
以上是LDA模型生成一篇文档的过程。
3.2 RLDA模型
本章节中详细介绍了RLDA模型。
本文是基于微博用户兴趣挖掘的背景,通过LDA主题模型进行微博主题特征的提取,从而更准确地挖掘出用户感兴趣的主题。本文是基于语义进行分析,因此本文研究的对象全部是短文本微博[14]。
假设用户兴趣的挖掘不仅与其原创、转发和点赞过的微博内容有关,而且还会在一定程度上受到一些热门微博内容的影响。本文基于这一假设对LDA模型进行了改进,在模型中引入并定义了一个新的变量——微博热度排行(Ranking),简称为R,从而构建了一个改进的RLDA模型,提高了用户兴趣挖掘的准确度。R是根据语料库中微博被转发(Repost)、评论(Comment)和点赞(Like)的统计次数计算而来,是评价用户微博热度的一个指标,R值越大代表该微博越受欢迎,而这类热门微博比较容易成为用户感兴趣的内容。设任意一篇微博的转发、评论和点赞数分别为xi,yi和zi,首先对其进行统一的归一化处理,公式如下:

上述处理后可得,微博转发、评论和点赞数的归一化数值分别为,和。R值定义如下:

经过上述计算可得到RLDA模型中所需的变量r。归一化的处理方式减小了转发、评论和点赞数量的差异,以及其取值区间的不同造成的权重失衡问题,将所有数据统一到区间(0,1)内进行比较叠加,更能体现出各个因素对最后R取值的影响。
在RLDA的文档-主题-词语的三层模型中,将一个用户发表、评论和点赞过的全部微博文本内容看作一篇文档d,同类或者相似的微博内容会有共同的主题t,而文档本身则是由很多单词w组成。同时,RLDA模型在基于LDA模型的基础上,引入微博热度排行r这样一个变量,辅助挖掘微博用户的兴趣。

图4 RLDA模型的贝叶斯网络图
如图4则是RLDA模型的贝叶斯网络图,与图3相比,图4中RLDA模型的贝叶斯网络图进行了改进,其中R表示语料库中所有微博的热度排行的集合,Ω表示特定主题下热度排行的多项式分布,这一分布的先验来自于另一个超参数λ的Dirichlet分布,其余符号的意义参照图3。
RLDA模型的主要思想就是在主题相同或相似的情况下,一篇微博的热度排行越高越容易受到用户的欢迎。算法1中定义了RLDA模型的生成过程:
1)根据Dirichlet的超参数对主题分布、主题-热度排行分布和文档-主题分布进行抽样;
2)对于每一条经过用户转发、评论及点赞过的微博,都有一个对应的热度排行r,从文档中找出一个与之对应的主题t;
3)基于主题t,对应的词语w和热度排行r会
相互独立的产生。
算法1 RLDA模型生成过程
输入:D,W ,K,R
步骤:
1 for主题 t∈T do
2 新建一个主题-词语的分布:
3 Φt~Dir(β)
4 新建一个主题-热度排行的分布:
5 Ωt~Dir(λ)
6 for文档 d∈Ddo
7 for词语 w∈Wdo
8 给文档d分配一个主题t:
9 t~Mul(d)
10 根据已选主题得出对应词语:
11 wd,t|t~Mul(Φt)
12 根据已选主题得出对应热度排行:
13 rd,t|t~Mul(Ωt)
对于获取准确的参数而言,文档-主题分布Θ,主题-单词分布Φ和主题-微博热度评价分布Ω这三个参数是隐含变量。因此,本文采用Collapsed Gibbs采样方法来估计这些先验分布,Gibbs采样方法是一种评估LDA模型简单有效的方法,是MCMC算法的一种特殊形式[15]。
基于RLDA模型独立的假设,主题、词语和微博热度排行的联合分布定义如下:

在 RLDA 模型中,α,β,γ是 Dirichlet先验,Θ,Φ,Ω表示利用Dirichlet分布采样的多项式分布,因此需要估计模型的三个隐含变量,并得出他们在当前状态 j下的条件概率:


确定模型参数之后,可以推导出P(w ,r|d ),然后根据P(w ,r|d)对给定文档的进行的主题进行排序,得到文档-主题向量分布。
4 实验论证及结果分析
4.1 数据准备
本文使用的是新浪微博的数据集来挖掘微博用户的兴趣。原始数据集中随机收集17423名用户2016年3月至9月原创、转发及点赞过的43128343条微博。本文截取其中6000名用户的1000000条微博作为实验数据。平均而言,每个微博用户每天大概会原创、转发或者点赞一条微博。微博数据采集需要抓取微博的内容信息、评论信息及用户信息。本实验的数据采集主要有基于爬虫和API接口两种方式,少量的数据是通过在微博中人工搜索的方式获取的[16]。最后,将数据集随机分成两部分,70%作为训练数据和30%作为测试数据。本文用RLDA模型对这100万条微博进行分析从而挖掘用户兴趣。原始的微博数据集在使用RLDA模型分析之前,首先要进行数据预处理,文本的预处理过程主要包括分词处理和去除停用词。
4.2 参数设置
RLDA模型是一个基于贝叶斯统计的模型。在贝叶斯统计当中,先验分布的参数我们称之为超参数。RLDA模型中有三个超参数α,β和λ。在LDA模型的学习过程中,α,β一般会通过经验来确定。若 k为模型的主题数目,则 α=50/k,β=0.01,(λ是本文模型中引入的超参数,不具有一般性)。当超参数的取值对主题模型的分析影响较大时,这种方法可能会降低实验结果的精确度。因此本文引入“超超参数(hyper-hyperparameters)”这一概念[17]。即超参数α,β和λ的先验分布是未知的,每次进行Gibbs采样的迭代之前,在Dirichlet分布上采样出3个具体的数值对模型中的超参数进行赋值。实验证明,“超超参数”的取值方式相比超参数固定取值的方式对模型的结果影响更小,降低了因为超参数取值不当对模型分析结果的影响。
4.3 实验评定指标
为了验证本研究提出的微博用户兴趣模型构建方法是否具有更好地准确性,需要对本文构建的用户兴趣模型进行实验评估。本文采用直接的方式对模型进行评估,用准确率(Precision)、召回率(Recall)以及协调均值F(F-measure)作为RLDA模型的评估指标。
其中准确率和召回率的定义如下[18]:
其中,tp是模型中被准确分类成正类的数量,即hit;fp是模型中被错误分类成正类的数量,即falsealarm;tn是模型中被准确分类成的负类的数量,即correct rejection;fn是模型中被错误分类成的负的数量,即miss。tp+tn是分类正确的总数,fp+fn是分类错误的总数。在本文的RLDA模型中,hit表示模型中分析出的正确兴趣的数量,K表示模型中全部的兴趣数量, ||Testd则表示用户全部的兴趣数量。
对于RLDA模型来说,Precision和Recall的值越大,模型的分类效果越好,但是同一模型中Precision和Recall的结果一般是负相关的,通常一个升高会造成另一个减小,因此本文还引入了Precision和Recall的协调均值F这样一个综合的评价指标,一般来说,F值越高实验效果越好。其定义如下[18]:

4.4 实验结果及分析
本文实验采用SVM作为分类器,并辅助使用开源的工具LibSVM,首先训练数据集中70%的训练样本,然后利用剩余的30%的数据进行测试,根据RLDA用户兴趣挖掘模型进行分类与评估。为了验证RLDA模型能够在LDA模型的基础上提高用户兴趣挖掘的准确度,将测试数据分别应用LDA模型和RLDA模型进行实验。
图5是文档的主题数取值在区间[10,200]内时,分别用LDA模型和RLDA模型进行微博文本的主题特征提取并建模进行分析评估,然后得到的实验数据。图 5(a)(b)(c)分别是两个模型在 Precision、Recall和F值三个评价指标上对比实验的效果图。
从图中可以看出,采用RLDA主题特征模型和使用LDA模型相比,Precision、Recall和F值均有明显提升。可以得出,微博热度排行较高的微博,微博用户对其感兴趣的概率越大,即微博热度一定程度上影响了微博用户的兴趣。因此,将微博热度排行这一指标的加入到LDA模型中进行改进,得出的RLDA模型能够更准确地挖掘出用户的兴趣,从而提高了兴趣挖掘的精度。
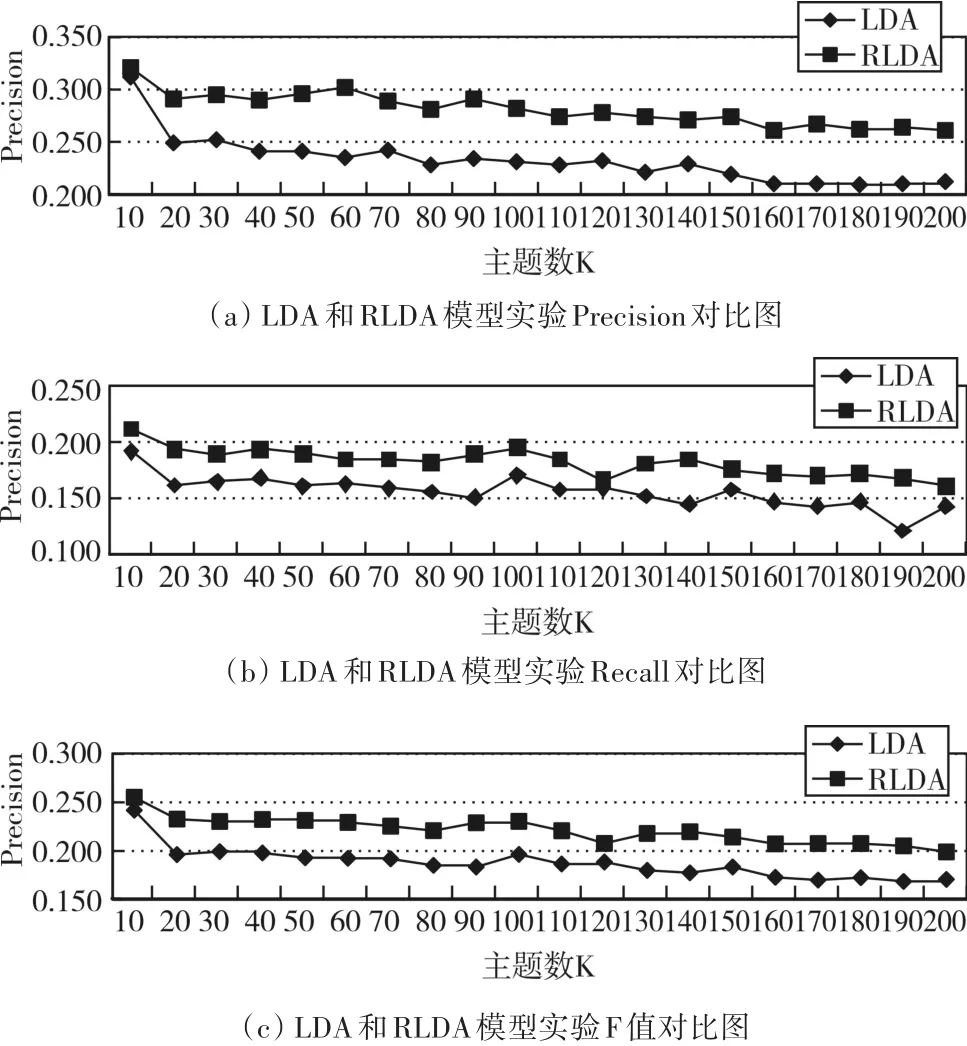
图5 主题数K从10到200时Precision、Recall和F值的变化图
此外,图中还显示当文档中的主题数K=100时,RLDA模型的评估指标F值接近最大,即此时的实验效果接近最佳挖掘用户的兴趣信息最为准确。
5 结语
LDA模型常用于本文分类和特征提取,实验证明该模型该许多应用中都取得了很好的效果。本文基于LDA模型的基础上,提出了一种新的主题特征提取模型——RLDA模型,它在原有的LDA模型中加入了微博背景中特有的微博热度排行这一信息,从而对模型的进行了改进,提高模型挖掘微博用户兴趣的准确率。同时,本文在建模过程的参数设置中还引入了“超超参数”这一概念,本文不采用原始的固定取值方式,而是通过Dirichlet分布对其取值进行采样,极大地减小了由于超参数取值不当对实现效果产生的影响。
实验表明,与LDA模型相比,本文中提出的RLDA模型在微博用户兴趣挖掘的准确度上有了很大的提升。
[1]袁博阳.基于微博内容和用户关注的微博用户兴趣模型构建[D].广州:华南理工大学,2015:12-14.YUAN Boyang.Based on the content and users concerns of microblog user interest model building[D].Guangzhou:South China University of Technology,2015:12-14.
[2]王振振,何明,杜永萍.基于LDA主题模型的文本相似度计算[C]//全国智能信息处理学术会议,2013:229-232.WANG Zhenzhen,HE Ming,DU Yongping.Text Similarity Computing Based on the Topic Model LDA[C]//National Conference on intelligent information processing,2013:229-232.
[3]Cha M S,Kim S Y,Ha J H,et al.Topic Model based Approach for Improved Indexing in Content based Document Retrieval[J].2016,4(1).
[4]Naphade M R,Huang T S.A probabilistic framework for semantic indexing and retrieval in video[C]//Multimedia and Expo,2000.ICME 2000.2000 IEEE International Conference on.IEEE,2010:475-478 vol.1.
[5]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[6]Filippova K.Multi-sentence compression:finding shortest paths in word graphs[C]//COLING 2010,International Conference on Computational Linguistics,Proceedings of the Conference,23-27 August 2010,Beijing,China.2010:322-330.
[7]王志宏.微博用户兴趣挖掘技术研究[D].广州:华东理工大学,2015:49-52.WANG Zhihong.Research of Text Mining Technologies for Interests of Micro-Blog Users[D].Guangzhou:East China University of Technology,2015:49-52.
[8]Zhou X,Wu S.Rating LDA model for collaborative filtering[J].Knowledge-Based Systems,2016,110:135-143.
[9]Meo P D,Messina F,Rosaci D,et al.Recommending Users in Social Networks by Integrating Local and Global Reputation[M].Internet and Distributed Computing Systems.Springer International Publishing,2014:437-446.
[10]Ramage D,Dumais S T,Liebling D J.Characterizing Microblogs with Topic Models[C]//International Conference on Weblogs and Social Media,Icwsm 2010,Washington,Dc,Usa,May.2010:130-137.
[11]张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.ZHANG Chenyi,SUN Jianling,DING Yiqun.Topic mining for microblog based on MB-LDA model[J].Research and Development of Computer,2011,48(10):1795-1802.
[12]Naveed N,Gottron T,Kunegis J,et al.Bad News Travel Fast:A Content-based Analysis of Interestingness on Twitter[J].uni,2011:1-7.
[13]Meo P D,Messina F,Rosaci D,et al.Recommending Users in Social Networks by Integrating Local and Global Reputation[M].Internet and Distributed Computing Systems.Springer International Publishing,2014:437-446.
[14]Deerwester S.Indexing by latent semantic analysis[J].Journal of the Association for Information Science and Technology,1990,41(6):391-407.
[15]Kail G,Tourneret J Y,Hlawatsch F,et al.Blind Deconvolution of Sparse Pulse Sequences Under a Minimum Distance Constraint:A Partially Collapsed Gibbs Sampler Method[J].IEEE Transactions on Signal Processing,2012,60(6):2727-2743.
[16]刘淇.基于用户兴趣建模的推荐方法及应用研究[D].合肥:中国科学技术大学,2013:66-72.Liu Qi.A Study of Designing and Applying Recommenders Based on User Interests Modeling[D].Hefei:University of Science and Technology of China,2013:66-72.
[17]Blei D M,Griffiths T L,Jordan M I.The nested Chinese restaurant process and Bayesian nonparametric inference of topic hierarchies[J].Journal of the Acm,2010,57(2):87-103.
[18]https://en.wikipedia.org/wiki/Precision_and_recall#Precision
Feature Extraction Method Based on RLDA Topic Model
FENG XinqiZHANG KunREN YihaoXIE Bin ZHAO Jing
(School of Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094)
In this paper,to accurately mining micro-blog user interest,the data concerning original,reposted and liked micro-blog content as well as the ranking of all these micro-blogs are collected and analyzed.So the accurate description information of micro-blog users'interests is obtained.Then based on the LDA model,we proposed a modified topic feature extraction model named as Ranking LDA is proposed.In comparison to LDA model,RLDA model includs a new concept-Micro-blog popularity ranking to improve the mining accuracy of the micro-blog users'interests.In the process of modeling the RLDA topic model,the concepts of hyper-hyper parameters is introduced.Hyper parameters are sampled from dirichlet distribution.Experiments suggest that,compared with the LDA model,RLDA model achieves quite a great promotion on the accuracy of interest mining for micro-blog users.
interests mining,Micro-blog popularity ranking,Ranking Latent Dirichlet Allocation model,feature extraction,hyper-hyper parameters
TP391.1
10.3969/j.issn.1672-9722.2017.10.019
Class Number TP391.1
2017年4月12日,
2017年5月19日
冯新淇,女,硕士研究生,研究方向:数据挖掘与语义分析。张琨,女,博士研究生,教授,研究方向:信息安全与复杂网络。任奕豪,男,硕士研究生,研究方向:数据挖掘,自然语言处理。谢彬,男,博士研究生,高级工程师,研究方向:基础软件、大数据与网络科学。赵静,女,博士研究生,研究方向:信息安全、复杂网络理论与应用。
