基于自适应心理声学模型的智能语音识别系统*
2017-11-14熊笑颜黄灿英南昌大学科学技术学院南昌330029
熊笑颜, 陈 栩, 黄灿英, 陈 艳(南昌大学 科学技术学院, 南昌 330029)
基于自适应心理声学模型的智能语音识别系统*
熊笑颜, 陈 栩, 黄灿英, 陈 艳
(南昌大学 科学技术学院, 南昌 330029)
针对包含环境噪声和信道失真等噪声的语音处理问题,提出了一种基于自适应心理声学模型的智能语音识别系统,并建立了听觉模型.该模型将心理声学和耳声发射(OAE)合并到了自动语音识别(ASR)系统中,利用AURORA2数据库分别在清洁训练条件和多训练条件下进行试验.结果表明,所提出的特征提取方法可以显著提高词识别率,优于梅尔频率倒谱系数(MFCC)、前向掩蔽(FM)、侧向抑制(LI)和倒谱平均值及方差归一化(CMVN)算法,能够有效地提高智能语音识别系统的性能.
梅尔频率倒谱系数; 耳声发射; 自适应; 心理声学滤波器; 自动语音识别; AURORA2数据库; 前向掩蔽; 侧向抑制
语音是人类通信中最重要的形式,近年来,自动语音识别(ASR)已受到广泛的关注.经过多年发展,ASR已经能够有效地解码语音,例如,在高于20 dB信噪比(SNR)的情况下,小词汇语境中可以实现超过95%的词精确度,大词汇语境中达到超过90%的词精确度.然而,随着SNR下降(例如至0 dB),识别精度会降低到50%以下,这对于许多典型应用是不可接受的[1].对于人类而言,语音感知是一种感觉和感知过程[2-4],本文专注于该过程的心理声学和耳声发射(OAE)方面研究.心理声学是对人类语言感知的广泛研究,包括声压级和响度、人对不同频率响应以及各种掩蔽效应,在一定程度上,梅尔频率倒谱系数(MFCC)的普及是这一研究领域的成果[5-7];OAE是在耳蜗中产生的声学信号,其广泛用于新生儿听力损失的检测[8-10],但并未真正应用于ASR.
之前在心理声学中的工作已经系统地研究了语音信号如何由人类听觉系统处理并转换成神经尖峰[11],并且已经提出了几种不同的数学模型用于有效实现掩蔽效应,通过并入时间积分对系统进行了改进[12].本文在此基础上对听觉模型进行了改进,将心理声学和耳声发射合并到了自动语音识别系统中,显著提高词识别率.
1 听觉模型
本文研究了听觉神经科学的两个分区,即心理声学和OAE[13].心理声学涵盖诸多不同的主题,包括声音定位和掩蔽效应.掩蔽效应主要是由时间和频率上的神经元信号处理机制引起的[14-15],为了定量测量掩蔽效应,通常需要确定掩蔽阈值.掩蔽阈值是测试声音的声压级,当存在掩蔽物的情况下几乎不可听见,信号可能被前面的声音(前向掩蔽(FM))或后续声音(后向掩蔽)所掩蔽.
OAE是从内耳产生的声信号,其可以使用灵敏的麦克风记录在耳道中,OAE是耳蜗中声音的非线性和主动预处理结果.经过实验已经证明,OAE是通过众多不同的机械原因在内耳产生的[16].
2 算法描述
本文所提出的听觉系统数学模型主要由两部分组成:自适应2D心理声学滤波和OAE滤波.
2.1 自适应2D心理声学滤波
听觉系统对不同频率的响应不同,且掩蔽效应同样依赖于频率,即掩蔽物的频率影响掩蔽的总量.图1给出了前向掩蔽的特性曲线[17],其描述了掩蔽总量Mtotal随时间变化过程,其中,1和4 kHz参数分别用于低频带和高频带时间掩蔽.
掩蔽效应参数随频率改变而变化,理想算法则是对于不同频率应当存在不同的2D心理声学滤波器,但显然在计算中无法实现.在本文的实现方案中,将每个语音样本划分为两个部分,即低频带和高频带,可表示为
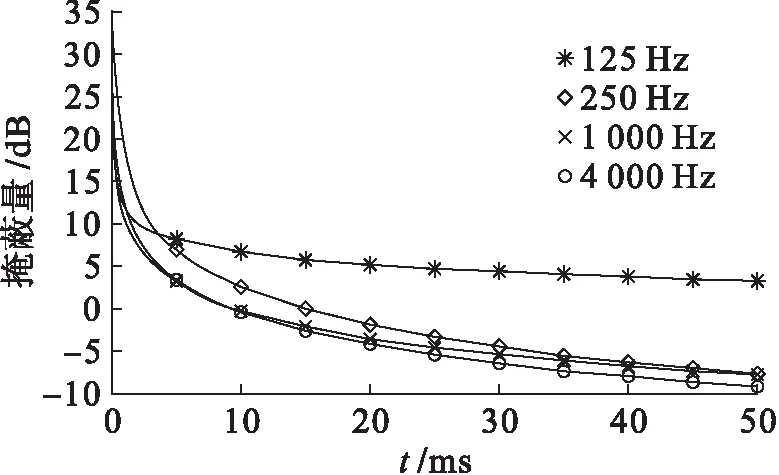
图1 前向掩蔽的特性曲线Fig.1 Characteristic curve for FM
(1)
式中,Ys1和Ys2分别定义为
(2)
(3)
式中,Es和Ts分别为语音信号的频率和时间矩阵.
每个频带由不同的2D心理声学滤波器处理,掩蔽量为时间积分参数与Ys矩阵的乘积,最佳时间积分参数是根据经验获得的.低频带和高频带下语音的时间积分参数分别为4、3;低频带和高频带下非语音的时间积分参数分别为3、2.图2给出了自适应2D心理声学滤波的流程框图.语音在经过离散傅里叶变换(DFT)之后,语音频谱图均等地分成高频带和低频带,语音活动检测器(VAD)用于区分语音/非语音帧.对于每个频带,使用两个不同的时间积分参数,因此,在实现方案中总共有4个不同的2D心理声学滤波器.
2.2 耳声发射滤波
OAE被认为与耳蜗的放大功能相关,且在内耳中产生,OAE与诸多其他心理声学效应(例如掩蔽效应、初步频带等)一同改变语音的频谱,这有助于增强或抑制原始语音的某些区域.
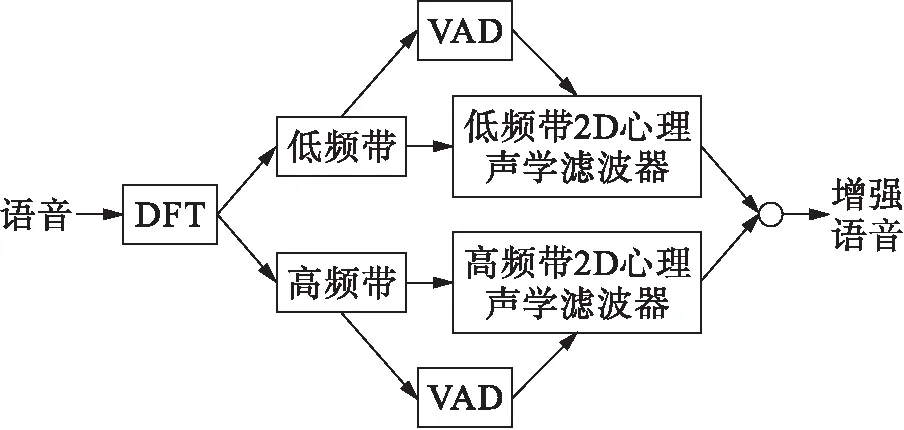
图2 自适应2D心理声学滤波框图Fig.2 Block diagram of adaptive 2Dpsychoacoustic filtering
本文算法主要目的是将语音转换为可由听觉系统神经尖峰来识别的信号,因此,新版本OAE可被建模为
(4)
式中:f和t分别为语音信号的频率和时间;MOAE为OAE的总量,MOAE计算表达式为
MOAE=μMtotal=
(5)
式中:μ为经验系数;-Tbm≤Δt≤Tfm,Tfm和Tbm分别为前向掩蔽和后向掩蔽的有效范围;-F1≤Δf≤F2,F1和F2为同时掩蔽的有效范围;α(Δf,Δt)为时间积分参数.新语音的最终版本可通过心理声学和OAE的联合效应来计算.对于听到的声学信号Y(f,t),其首先通过OAE滤波,滤波后信号为
YOAE(f,t)=Y(f,t)⊗Mask
(6)
式中,Mask表达式为
(7)
之后信号通过掩蔽效应进一步处理可得
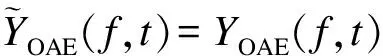
Y(f,t)⊗Mask⊗Mpsy
(8)
式中,Mpsy为心理声学滤波器,其计算参见文献[18].OAE和心理声学滤波器在式(8)中依次实现,这是因为OAE主要由内耳产生,而心理声学(掩蔽)效应主要由紧邻的听觉神经限制产生,即在混合语音通过整个听觉系统之前,首先将OAE添加到原始语音中.
3 实验与分析
分别在AURORA2数据库上进行清洁训练条件和多训练条件的识别实验,实验中将本文所提出的算法与MFCC、前向掩蔽(FM)、侧向抑制(LI)和倒谱平均值(包含TW-2D和TFW-2D)及方差归一化(CMVN)算法进行比较.清洁训练条件集中没有添加噪声,其包括从55个男性和55个女性成年人记录的8 440个语音;在多训练条件集中,记录语音中添加了数据库中包含的4种白噪声.
在SNR等级分别为20、15、10、5、0和-5 dB条件下添加8种类型的噪声(地铁、人群、汽车、展览会、餐厅、街道、飞机场和火车)进行识别率实验.表1、2为本文所提算法对两种不同训练条件语音的识别实验结果;表3、4为不同算法对两种不同训练条件语音在SNR等级为-5 dB及平均值(信噪比为0~20 dB之间取得)条件下的相对提高率对比,相对提高率被定义为
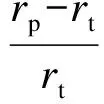
(9)
式中:rp为所提出算法的识别率;rt为比较算法的识别率.
在清洁训练条件下,所提出的算法明显优于其他方法,其对比图如图3a所示.与MFCC、FM、LI和CMVN相比,本文所提算法的平均识别率相对提高了19.62%、10.27%、15.29%和9.64%;在噪声等级为-5 dB时,相对提高率分别为90.03%、16.34%、45.17%和78.27%.TW-2D和TFW-2D心理声学滤波器参见文献[2].与TW-2D和TFW-2D算法相比,本文所提出算法的平均识别率相对提高了6.12%和1.04%;在噪声等级为-5 dB时,相对提高率分别为71.84%和1.68%.
图3b为多训练条件下,所提出算法相对于其他算法的比较结果.与MFCC、FM、LI和CMVN相比,本文所提算法的平均识别率相对提高了5.22%、5.67%、4.73%和0.76%;在噪声等级为-5 dB时,相对提高率分别为71.93%、81.19%、73.49%和8.18%.与TW-2D和TFW-2D算法相比,本文所提算法的平均识别率相对提高了1.08%和0.69%;在噪声等级为-5 dB时,相对提高率分别为19.60%和5.18%.
4 结 论
本文提出了基于MFCC的混合特征提取算法,该种方法设法反映了人类听觉系统的不对称性质.所提出算法的关键特征是结合了自适应方案,其更好地反映掩蔽效应的频率相关属性.语音频谱被分成多个频带,不同的心理声学滤波器被设计成更适合特定频带.此外,所提出的方法无需任何额外的训练过程,使得计算负担较低.由于所提算法的简单性,故其可轻易地与其他算法进行组合.
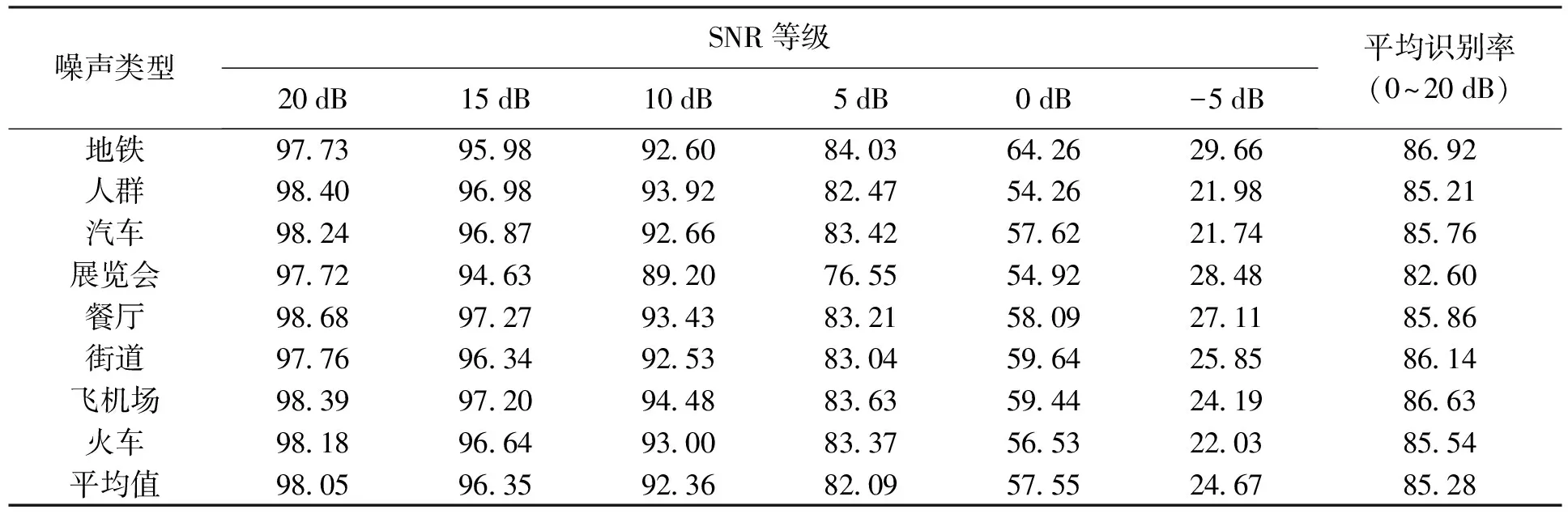
表1 清洁训练条件下所提出算法的识别结果Tab.1 Recognition results of proposed algorithm under clean training condition %
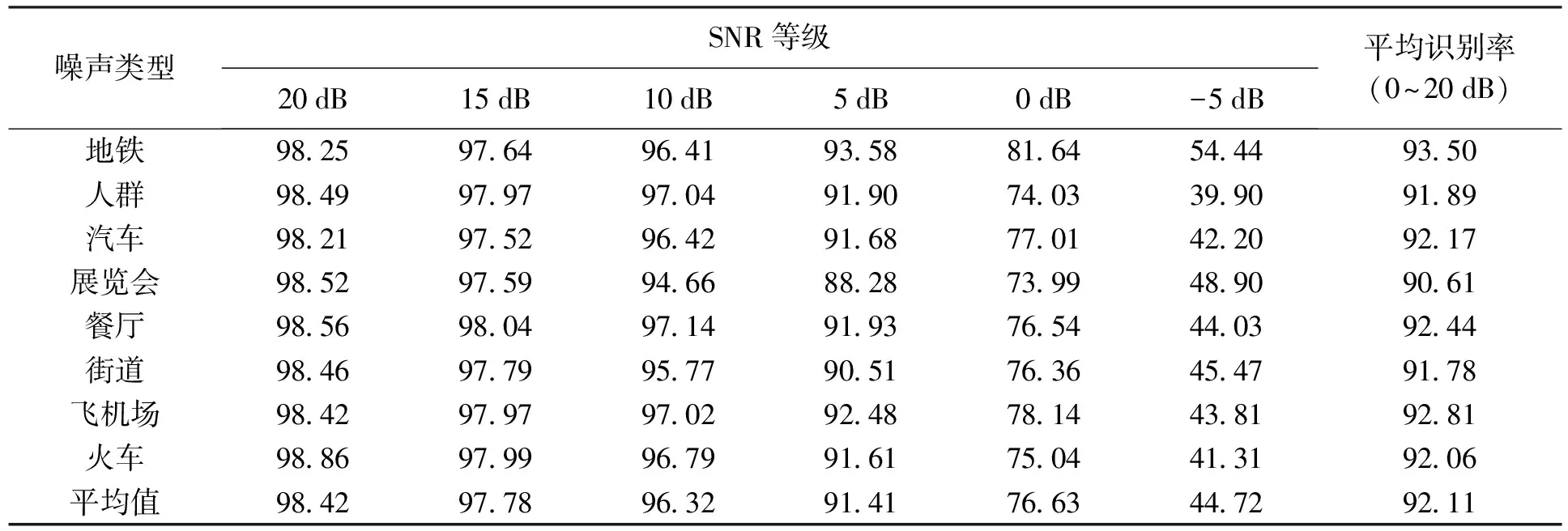
表2 多训练条件下所提出算法的识别结果Tab.2 Recognition results of proposed algorithm under multiple training condition %
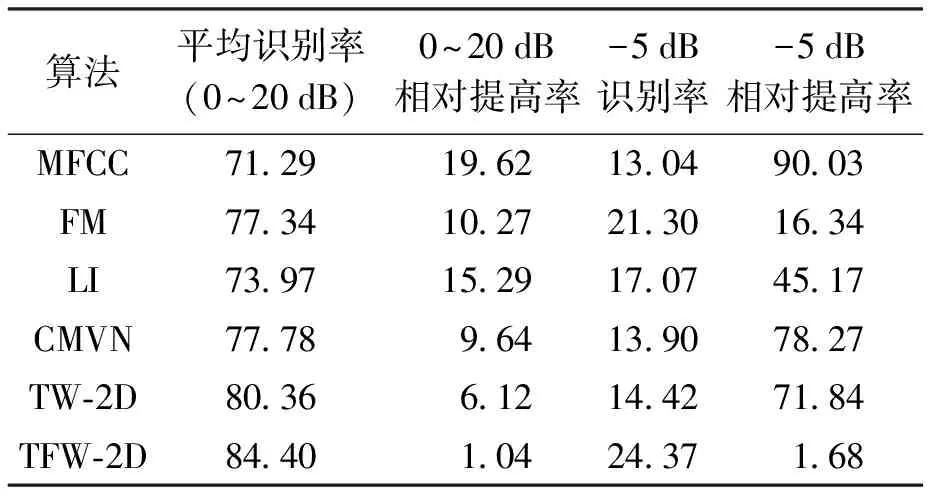
表3 清洁训练条件下的相对提高Tab.3 Relative improvement underclean training condition %
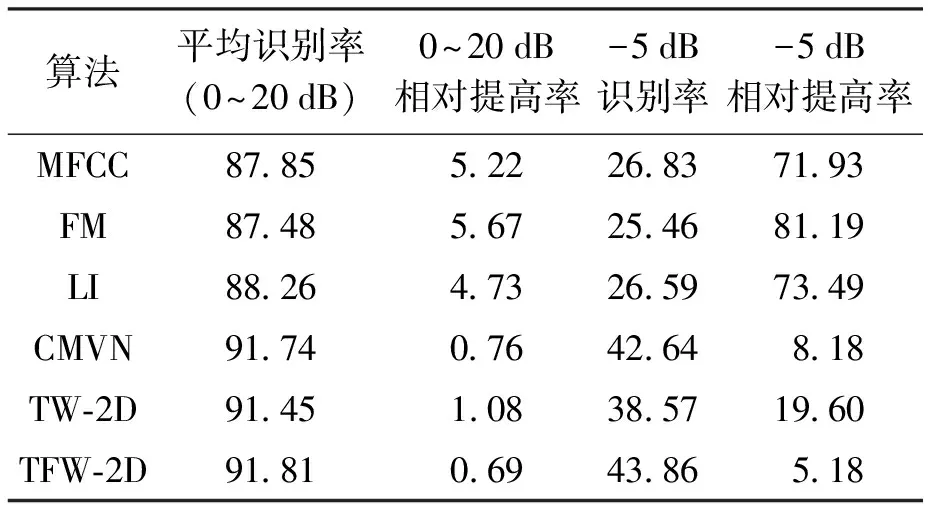
表4 多训练条件下的相对提高Tab.4 Relative improvement undermultiple training condition %
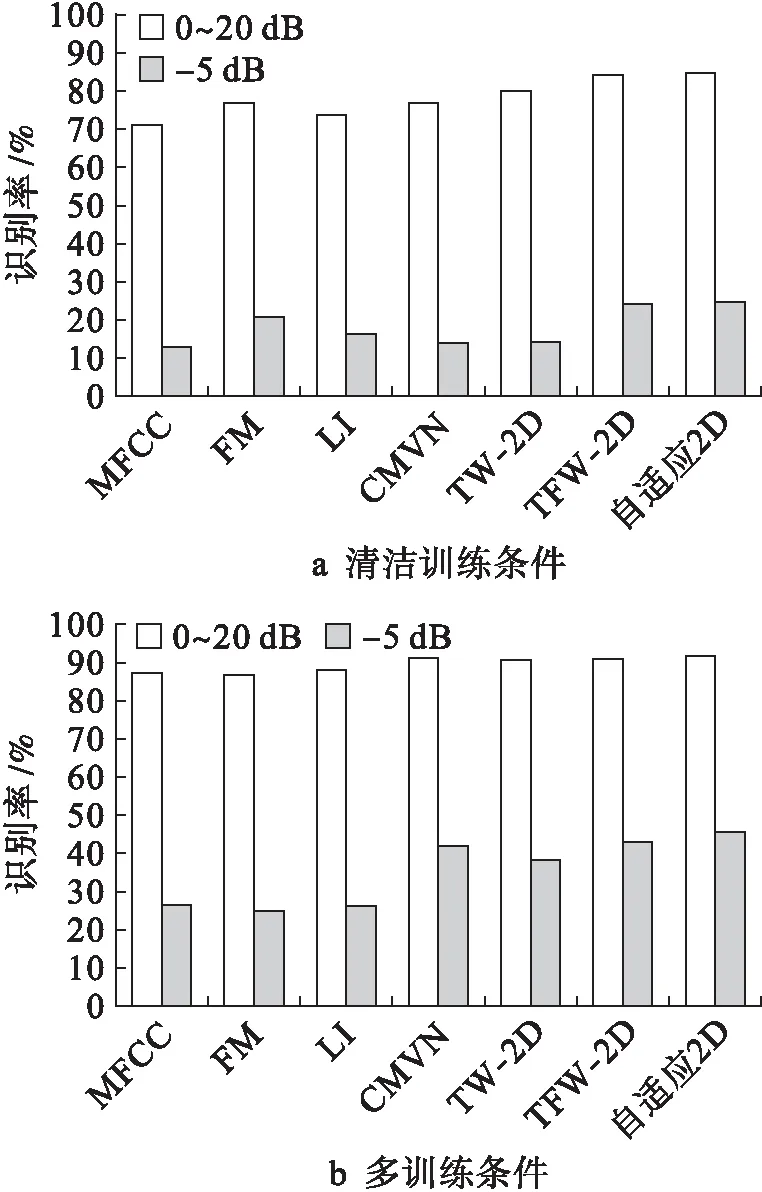
图3 清洁和多训练条件下的对比结果Fig.3 Test results under clean andmultiple training conditions
[1] Heimrath K,Breitling C,Krauel K,et al.Modulation of pre-attentive spectro-temporal feature processing in the human auditory system by HD-tDCS [J].European Journal of Neuroscience,2015,41(12):1580-1586.
[2] Dai P,Soon I Y.A temporal frequency warped (TFW) 2D psychoacoustic filter for robust speech recognition system [J].Speech Communication,2012,54(3):402-413.
[3] Kleinschmidt D F,Jaeger T F.Robust speech perception:recognize the familiar,generalize to the similar,and adapt to the novel [J].Psychological Review,2015,122(2):148-153.
[4] Bidelman G M,Weiss M W,Moreno S,et al.Coordinated plasticity in brainstem and auditory cortex contributes to enhanced categorical speech perception in musicians [J].European Journal of Neuroscience,2014,40(4):2662-2673.
[5] Jeong K H,Lee J W,Park J.Chatter diagnosis using mel-frequency cepstral coefficient of vibrational signal for various operating conditions [J].Journal of the Acoustical Society of America,2016,140:124-131.
[6] Schädler M R,Kollmeier B.Separable spectro-temporal gabor filter bank features:reducing the complexity of robust features for automatic speech recognition [J].Journal of the Acoustical Society of America,2015,137(4):2047-2059.
[7] Govindan S M,Duraisamy P,Yuan X.Adaptive wavelet shrinkage for noise robust speaker recognition [J].Digital Signal Processing,2014,33:180-190.
[8] Sisto R,Moleti A,Shera C A.On the spatial distribution of the reflection sources of different latency components of otoacoustic emissions [J].Journal of the Acoustical Society of America,2015,137(2):768-776.
[9] Christensen A T,Ordoez R,Hammershøi D.Stimulus ratio dependence of low-frequency distortion-product otoacoustic emissions in humans [J].Journal of the Acoustical Society of America,2015,137(2):679-689.
[10]Jedrzejczak W W,Konopka W,Kochanek K,et al.Otoacoustic emissions in newborns evoked by 0.5kHz tone bursts [J].International Journal of Pediatric Otorhinolaryngology,2015,79(9):1522-1526.
[11]Ekanadham C,Tranchina D,Simoncelli E P.A unified framework and method for automatic neural spike identification [J].Journal of Neuroscience Methods,2014,222(1):47-55.
[12]Oxenham A J,Plack C J.Effects of masker frequency and duration in forward masking:further evidence for the influence of peripheral nonlinearity [J].Hearing Research,2000,150:258-266.
[13]Oetjen A,Verhey J L.Spectro-temporal modulation masking patterns reveal frequency selectivity [J].Journal of the Acoustical Society of America,2015,137(2):714-717.
[14]Li N,Osborn M,Wang G,et al.A digital multichannel neural signal processing system using compressed sensing [J].Digital Signal Processing,2016,55(3):64-77.
[15]Azad A K,Wang L,Guo N,et al.Signal processing using artificial neural network for BOTDA sensor system [J].Optics Express,2016,24(6):67-69.
[16]Kujawa S G,Fallon M,Skellett R A,et al.Time-varying alterations in the f2-fl DPOAE response to continuous primary stimulation II.influence of local calcium-dependent mechanisms [J].Hearing Research,1996,97(1/2):153-164.
[17]Jesteadt W,Bacon S P,Lehman J R.Forward masking as a function of frequency,masker level,and signal delay [J].Journal of the Acoustical Society of America,1982,71(2):950-962.
[18]Oxenham A J.Forward masking:adaptation or integration [J].Journal of the Acoustical Society of America,2001,109(2):732-741.
Intelligentspeechrecognitionsystembasedonself-adaptionpsychoacousticmodel
XIONG Xiao-yan, CHEN Xu, HUANG Can-ying, CHEN Yan
(School of Science and Technology, Nanchang University, Nanchang 330029, China)
Aiming at such noise speech processing problems as environmental noise and channel distortion, an intelligent speech recognition system based on adaptive psychoacoustic system was proposed, and an auditory model was established. In the proposed model, the psychoacoustics and otoacoustic emission (OAE) were integrated into an automatic speech recognition (ASR) system. With the AURORA2 database, the experiments were performed under both clean and multiple training conditions, respectively. The results show that the proposed feature extraction method can significantly improve the word recognition rate, is superior to those of Mel-frequency cepstral coefficients (MFCCs), forward masking (FM), lateral inhibition (LI) and cepstral mean & variance normalization (CMVN) algorithms, and can effectively enhance the performance of intelligent speech recognition system.
Mel-frequency cepstral coefficient (MFCC); otoacoustic emission (OAE); self-adaption; psychoacoustic filter; automatic speech recognition(ASR); AURORA2 database; forward masking (FM); lateral inhibition (LI)
2016-12-12.
江西省教育厅科学技术研究项目(GJJ151504,GJJ151505); 江西省教育改革课题资助项目(JXJG-14-28-3,JXJG-14-28-1,JXJG-14-28-6,JXJG-14-28-8).
熊笑颜(1974-),女,湖北房县人,讲师,硕士,主要从事声学数据处理、电子技术及嵌入式系统等方面的研究.
* 本文已于2017-10-25 21∶13在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20171025.2113.066.html
10.7688/j.issn.1000-1646.2017.06.14
TP 511
A
1000-1646(2017)06-0675-05
(责任编辑:景 勇 英文审校:尹淑英)
