基于Hadoop的GNSS网基线向量的分布式处理
2017-11-10杨国庆岳东杰陈浩尹斌权
杨国庆,岳东杰,陈浩,尹斌权
(河海大学 地球科学与工程学院,江苏 南京 211100)
基于Hadoop的GNSS网基线向量的分布式处理
杨国庆,岳东杰,陈浩,尹斌权
(河海大学 地球科学与工程学院,江苏 南京 211100)
对于海量的GNSS观测数据,常规的集中式数据处理方法面临着计算效率低的问题,利用Hadoop平台技术分布式解算基线的方法可以有效地解决这一问题。通过划分子网,调用GAMIT软件并行解算基线,63个IGS站计算结果表明,3个计算节点的加速比达到了6.67,平差得到的坐标点精度在毫米量级。
Hadoop;分布式计算;基线解算;全球卫星导航系统
0 引 言
随着越来越多的连续运行基准站(CORS)的建立,全球卫星导航系统GNSS(Global Navigation Satellite System)观测的数据量越来越大,这对数据的存储以及计算带来了很大的挑战。近年来,网络技术也在不断的发展进步,网格计算、云计算等分布式计算在海量数据的存储、检索以及计算中得到了广泛的应用[1]。如今Hadoop被一些大型互联网公司应用,比如Google、雅虎等,这些企业利用Hadoop开发了开源的大数据管理系统,展现了Hadoop在处理大数据时的巨大潜力,很多企业决定引入Hadoop解决面临的大数据难题[2]。本文将Hadoop平台技术引入到GNSS网的基线解算当中,对预处理后的观测文件进行分布式存储与计算,通过算例验证了利用子网划分策略和Hadoop技术分布式解算GNSS网基线向量的效率。
1 Hadoop平台技术
Hadoop作为一个大数据的分布式处理平台,其特点是非结构化数据的存储、聚集、提取和过滤[3]。Hadoop平台提供了一组稳定可靠的接口以及数据服务,实现了MapReduce算法,能够把文本分成许多个可以重复执行的小单元。Hadoop平台可以利用分布式处理系统进行数据的存储,并且可以保持对数据拥有很高的吞吐率,同时该平台还可以自动地处理失败节点[4]。
Hadoop最核心的模块为用来存储节点文件的分布式文件系统HDFS(Hadoop Distributed File System)和用来计算大规模数据集群的MapReduce。HDFS能够以较高的传输率对大量的数据进行访问,并且能够以流的方式对文本数据进行访问;MapReduce可以分解数据,在数据存储节点上对大量数据进行分析处理。
本文利用HDFS技术对预处理后GNSS观测数据进行分布式存储和传输。HDFS集群包含了一个Namenode和多个Datanode[5]。NameNode负责管理整个文件系统的元数据,维护文件系统的目录树,包括每个测站的名称,对应的观测文件的存储位置。DataNode 负责管理观测文件数据块,一个观测文件会按照固定的大小(Blocksize一般为128 M)切成若干块后分布式存储在若干台Datanode上,每一个文件块可以有多个副本(默认为3个),并存放在不同的Datanode上。通过自己开发的客户端向HDFS中写入或者读取观测数据文件。Datanode会定期向Namenode汇报自身所保存的文件Block信息,而Namenode则会负责保持文件的副本数量。HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向Namenode申请来进行。图1是基于HDFS的观测数据分布式文件系统体系结构图。

图1 基于HDFS的观测数据分布式文件系统结构
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。一个完整的MapReduce程序在分布式运行时有三类实例进程:MRAppMaster负责整个程序的过程调度及状态协调;MapTask负责map阶段的整个数据处理流程;ReduceTask负责reduce阶段的整个数据处理流程。本文在map函数中通过调用GAMIT软件的批处理命令对基线进行解算。
2 基于Hadoop平台的基线解算过程
在进行Hadoop集群使用的时候,必须在独立节点以及数据“可分”的情况下才能够利用其进行
数据的处理[6]。针对GNSS大网,可以使用划分子网再综合处理的方法,能够提高计算效率,其处理时间优于整体解算,并且解算精度也与直接整体解算在一个量级上,可以满足大规模GNSS基准站网数据处理的要求[7]。本文在使用2个和3个计算节点的时候采取了划分子网的策略,各个子网间有4个重复的站点,以便后续对平差后的坐标结果进行检验。
根据划分的子网建立多个索引文件,文件名为子网编号,文件内容为测站点名,各个点名空格隔开,方便map函数对文件内容进行操作;利用自己编写的客户端代码上传预处理后的观测文件、精密星历文件、广播星历文件和索引文件至HDFS集群。在map函数中,通过本地文件系统的应用程序编程接口(API),在本地建立GAMIT软件运行需要的工程文件目录;map函数经解析索引文件得到该子网的所有测站名,利用HDFS的API从分布式文件系统中拷贝相应的观测文件、星历文件至本地建立的相应的工程文件夹中;map函数通过执行相应的Linux命令进入到工程文件中,调用sh-setup脚本链接外部tables表文件,调用sh-gamit批处理命令进行基线解算。处理过程中,一个索引文件对应一个子网,Hadoop对每一个索引文件操作时都会分配一个Maptask,一个子网正好匹配了一个Maptask对其进行处理。以上过程如图2所示。

图2 基于Hadoop平台技术的基线解算流程
3 计算实例及分析
采用亚洲以及周边地区63个IGS连续运行跟踪站2013年第133天的30 s采样间隔的预处理后的观测资料,O文件的数据量约为252 Mb,站点分布如图3所示。

图3 实验相关IGS站点分布图
在VMware Workstation Pro上搭建多台虚拟机建立实验环境,虚拟机内存1 Gb,物理核1核,操作系统为CentOS6.7,各节点计算环境基于Hadoop2.6.1,相关的基线解算采用GAMIT10.6版本。采用Master-Slave集成模式进行架构,如图4所示。

图4 基于Hadoop的分布式计算架构
采用划分子网的分布式计算策略,单节点对整网进行基线解算,2个节点划分为2个子网,3个节点则划分为3个子网,各个子网间有4个重合站点,基线解算时间取3次结果的平均值。不同数量子网个数和计算节点数下的解算时间如表1所示。

表1 不同节点数和子网个数解算时间对比
从表1可以看出,随着子网个数和计算节点数的增加,解算速度显著加快,3个节点处理3个子网比单机集中处理整网的加速比提高了6.67倍。
Hadoop能够把相当一部分大型计算任务拆成若干小任务在很多并行的服务器上运算,但是并没有完全解决计算瓶颈的问题。一般想象中,增加10倍的处理器并行运算,就可以同样成倍地节省时间,但是在工程上这是做不到的。利用Hadoop对各个子网进行基线解算的过程中,最终的计算速度取决于最后解算完成的子任务。因此,并行计算的时间是远远做不到和服务器数量成反比。事实上,使用的处理器越多,并行计算的效率越低[8]。所以在实际的工程当中,合理地分配计算资源才能使效率最大化。
解算完成后,从生成的sh_gamit_133.summary文件中查看标准化均方根残差(NRMS)以及解算总结,一般说来,NRMS值越小,基线估算精度越高;反之精度越低[9]。NRMS是衡量基线解算质量的最重要指标,一般为0.25左右,原则上应小于0.3[10]。本实验得到的NRMS都小于0.2,因此解算结果满足精度要求。
最后再对结果进行GLOBK平差,在globk_comb.org文件中查看平差结果,各个子网间重复基准站的坐标差如图5所示。
从图中可以看出,子网间重复站点坐标较差都在1 cm以内,解算结果相差较小,精度符合要求。
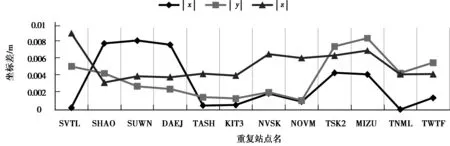
图5 各个子网重复站点坐标较差统计图
4 结束语
随着CORS站的不断建成,其连续观测产生的数据量越来越大,这对海量观测数据的存储和快速计算带来了挑战。本文利用了Hadoop平台技术和子网划分策略对GNSS基线向量网进行分布式解算,大大提高了计算的效率,主要结果如下:
1) 利用Hadoop平台技术的MapReduce算法,一个计算节点可以分配多个MapTask并行处理多个子网的观测数据,有效地分配了计算资源,实现了GNSS基线向量网的分布式解算。
2) 采用划分子网的策略,在实际工作中效率得到了提高,处理时间相对缩减,其解算精度也在毫米量级。子网划分策略同时也满足了Hadoop技术数据“可分性”的需求,让Hadoop技术更好地运用在GNSS网的基线解算当中。
3) 利用已有的软件进行数据处理,一方面减少了软件开发的成本,另一方面还能够保证计算结果的质量要求。
[1] 李志才,张鹏,孙占义,等. 大规模GNSS基准站网快速同步处理方法研究[J]. 测绘通报,2017(2):65-69.
[2] 乐天. Hadoop:打开大数据之门的金钥匙[N]. 计算机世界,2012-02-27(030).
[3] 王凯,曹建成,王乃生,等. Hadoop支持下的地理信息大数据处理技术初探[J]. 测绘通报,2015(10):114-117.
[4] 戴中华,盛鸿彬,王丽莉. 基于Hadoop平台的大数据分析与处理[J]. 通讯世界,2015(6):59-60.
[5] 吕志平,陈正生,崔阳,等. 大型CORS网基线向量的分布式处理[J]. 测绘科学技术学报,2013(4):433-438.
[6] 任仁. Hadoop在大数据处理中的应用优势分析[J]. 电子技术与软件工程,2014(15):194.
[7] 姜卫平,赵倩,刘鸿飞,等. 子网划分在大规模GNSS基准站网数据处理中的应用[J]. 武汉大学学报(信息科学版),2011(4):389-391,505.
[8] 吴军. 智能时代:大数据与智能革命重新定义未来[M]. 北京:中信出版社,2016.
[9] 陈正生,吕志平,崔阳,等. 大规模GNSS数据的分布式处理与实现[J]. 武汉大学学报(信息科学版),2015(3):384-389.
[10] 赵建三,杨创,闻德保. 利用GAMIT进行高精度GPS基线解算的方法及精度分析[J]. 测绘通报,2011(8):5-8,35.
DistributedProcessingofGNSSNetwork’sBaselineVectorsBasedonHadoop
YANGGuoqing,YUEDongjie,CHENHao,YINBinquan
(CollegeofEarthScienceandEngineering,HohaiUniversity,Nanjing211100,China)
For the massive data of GNSS observation, the method of conventional centralized data processing is facing the problem of low computational efficiency, distributed to process the baseline by using the technology of Hadoop platform, which can solve this problem effectively. By dividing the subnet, calling the GAMIT software to process the baseline in parallel, the result of 63 IGS stations shows that the acceleration ratio of the three compute nodes is 6.67, and the accuracy of the coordinate points is in the order of millimeters.
Hadoop; distributed computing; baseline solution; GNSS
10.13442/j.gnss.1008-9268.2017.04.012
P228.4
A
1008-9268(2017)04-0066-04
2017-05-27
联系人: 杨国庆E-mail: gqyang@hhu.edu.cn
杨国庆(1994-),男,江西赣州人,硕士研究生,研究方向为测量数据处理理论与方法。
岳东杰(1966-),女,山东梁山人,教授,主要研究方向为近代测量数据处理。
陈浩(1993-),男,江苏盐城人,硕士研究生,研究方向为测量数据处理理论与方法。
尹斌权(1994-),男,江苏徐州人,硕士研究生,研究方向为测量数据处理理论与方法。
