语音情感识别算法中新型参数研究*
2017-11-03章勤杰
余 华,章勤杰,赵 力
(1.江苏开放大学,南京 210065;2.东南大学信息科学与工程学院,南京 210096)
语音情感识别算法中新型参数研究*
余 华1*,章勤杰2,赵 力2
(1.江苏开放大学,南京 210065;2.东南大学信息科学与工程学院,南京 210096)
语音情感识别是实现智能人机交互的关键技术之一。然而,用于语音情感识别的语音情感特征十分有限。为此,提出一种新型的语谱图显著性特征来改善语音情感识别效果。识别算法利用选择性注意模型获取语音信号语谱图像的显著图,并从中提取显著性特征,结合语音信号传统的时频特征构成语音情感识别特征向量。最后,利用KNN分类方法进行语音情感识别。实验结果表明,加入显著性特征后识别率有明显提升。
语音情感识别;显著性特征;KNN分类
当今世界科技水平高速发展,人们也对计算机提出了更多要求。在智能人机交互系统构建中,语音情感识别已成为关键技术之一。对语音信号的情感分析,使得人机交互更加流畅[1-2]。智能人机交互系统通过对操作者的情感进行分析,可以更主动、更准确的去完成操作者的指示,并实时调整对话的方式,使交流变得更加友好、和谐和智能[3]。此外对单调的、高强度的任务中,执行人员的某些负面情绪监测具有使用价值。因此,对语音信号情感识别的研究仍具有重要意义。
本文针对语音情感识别中特征参数的构造问题,提出基于语音信号语谱图的新型特征参数提取方法,并用于构建语音情感识别算法。算法利用语谱图像的显著性特征提取用于情感识别的特征参数,构建情感识别特征参数向量,最后利用KNN分类算法建立语音情感识别算法。
1 语音情感识别方法
语音信号是一种典型的非平稳信号。但是,由于语音的形成过程是与发音器官的运动密切相关的,这种物理运动比起声音振动速度来要缓慢的多,因此语音信号常常可假定为短时平稳的,即在10 ms~30 ms这样的时间段内,其频谱特性和某些物理特征参量可近似地看作是不变的。这样就可以采用平稳过程的分析处理方法来对其进行处理。语音信号的特征计算都是以帧为单位进行的。一般来说,语音中的情感特征往往通过语音韵律的变化表现出来。例如,当一个人发怒的时候,讲话的速率会变快,音量会变大,音调会变高等,这些都是人们直接可以感觉到的。因此在语音情感识别中,韵律特征起着非常重要的作用,而韵律特征往往用语音的时域特征表示。进行语音情感识别时,首先要对输入的语音数据进行预处理,然后计算特征参数,再利用特定的模式匹配算法把这些特征参数与语音信息库中的标准情感语句的参数相匹配,最后得到语音的情感类型。语音情感识别的整体流程如图1所示。
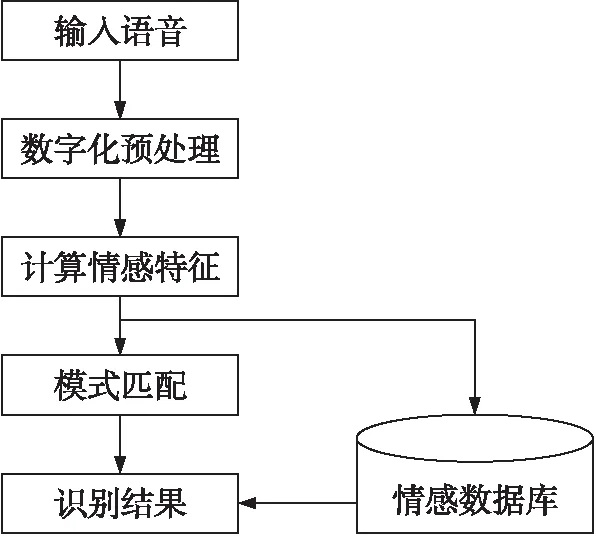
图1 语音情感识别流程图
2 传统情感语音信号的时域特征
语音信号具有短时平稳性。语音信号经过与处理之后,进行加窗分帧处理,能够有效利用语音信号的短时平稳性进行特征提取和分析。把原始的语音信号与特定的窗函数w(n)相乘得到加窗语音信号xw(n)=x(n)w(n)。
用En表示第n帧语音信号xn(m)的短时能量,定义:
(1)
从En的表达是可以看出,当语音信号中存在一个较高的采样值时,这个异值会使得短时能量很高,造成一定的误导。为了消除这中噪声敏感的特性,我们用短时平均幅度函数An来刻画信号幅值的变化,其计算公式如下:
(2)
从短时能量和短时平均幅度两者的计算公式可以看出,前者对于信号的最值反应很敏感,单个的采样结果对最终的短时能量的影响突出;而后者这种敏感性较低。
定义语音信号xn(m)的短时过零率Zn为:

(3)
式中:sgn[ ]是符号函数。
相关分析经常会在信号的时域分析中用到,有自相关和互相关的分别。我们主要讨论自相关函数。定义第n帧语音信号xn(m)的短时自相关函数为:
(4)
Rn(k)不为零的范围为k=(-N+1)~(N-1),为偶函数。
3 情感语音信号语谱图的显著性特征提取
本文将普遍存在于人类感知领域中的听觉和视觉选择性注意机制引入到情感语音的特征提取当中。利用选择性注意模型[4,7]对语音信号的语谱图像进行显著性分析。模型首先将图像进行分解,提取视觉特征(颜色、强度和方向),并进行中心周围差和归一化运算得到各特征图;将个尺度的特征度跨尺度融合得到各通道的关注图;最后将个关注图跨通道合并得到显著图。分析情感语音语谱图像的显著图,提取特征参数用于情感识别。
3.1 显著图计算
首先对图像进行分解,得到不同尺度的图像,这过程称为对尺度滤波。通过将图像与线性分解高斯核(6×6的高斯核[1,5,10,10,5,1]/32)进行卷积运算来完成分解,这也被形象的称为高斯金字塔分解。各层高斯金字塔分解图像之间的关系可用如式(5)表示:
I(σ+1)=I(σ)/2
(5)
式中:σ为层数、I(σ)代表第σ层卷积分解图像。根据卷积结果算出各层上的分解图像。之后,在不同尺度的的图像上提取图像的颜色、亮度和方向特征,分别形成颜色、亮度和方向金字塔序列图像。
3.1.1 颜色特征高斯金字塔分解图
r、g、b分别表示一幅彩色图像中红、绿、蓝分量值,根据德国生理学家赫林提出的拮抗色学说,用R-G和B-Y的拮抗作用来模表示颜色信息对最终显著图的贡献,这两对颜色对相应的高斯金字塔分解图像由如下公式算得:
PR-G(σ)=(r-g)/max(r,g,b)
(6)
PB-Y(σ)=(b-min(r,g))/max(r,g,b)
(7)
式中:PR-G(σ)和PB-Y(σ)分别表示R-G和B-Y颜色对在对应尺度σ图像上的高斯金字塔分解图。
3.1.2 亮度特征高斯金字塔分解图
模型中的亮度特征通道的高斯金字塔分解图像可以简单地由图像的r、g、b分量的平均值来表示:
PI(σ)=(r+g+b)/3
(8)
式中:PI(σ)表示在相应尺度σ上的高斯金字塔分解图像。
3.1.3 方向特征高斯金字塔分解图
图像的方向特征可以通过二维Gabor方向滤波器来提取。Gabor滤波器与人类视觉系统中简单细胞的视觉刺激响应非常相似,可以很好的模拟视网膜感受野方向选择的机制。将滤波器与相应尺度的图像进行卷积得到方向通道的高斯金字塔分解图。
Pθ(σ)=|PI(σ)*G0(θ)|+|PI(σ)*Gπ/2(θ)|
(9)
不同尺度上,不同方向角度的方向特征高斯金字塔分解图即可由上式计算出来。
得到各特征通道的子关注图像之后,经过一定的合并策略将这些子关注图合并成3个通道对应的关注图:颜色关注图、亮度关注图与方向关注图,将这3幅关注图求和平均后即得到最终的显著图像。
3.2 显著图分析
根据上述的显著图计算方法,我们对不同情感语音信号语谱图对应的显著图进行分析。
分析结果如表1。

表1 各情感类型显著图灰度级分布比例
从表1可以看出,3种情感语音信号显著图的0~150灰度级所占比例均在90%以上,说明各情感显著图的灰度大部分都集中在0~150这个范围内。为了体现各情感语音信号显著图间的差异,我们选取0~100灰度范围所占比例作为衡量灰度级分布的参数用于情感识别。

图2 显著图中Sv(a)和Sh(b)对应的图像
显著图中较为明亮的部分对应于语谱图中有效谱线对应的部分,能量越高的部分对应于显著图中越明亮的部分。基于这样的一个事实我们对显著图进行一些处理,划分出两类面积:一类是语谱图中有效谱线对应的面积,我们用Sv表示;一类是语谱图在显著图中比较突出的部分对应的面积,我们用Sh表示。显著图中Sv和Sh对应关系如图2所示。
将Sh和Sv的比值Ss作为显著图第2参数,并将其用于后续的情感识别算法中。
4 实验结果分析
本文的情感识别算法采用语音信号传统时域特征和语谱图显著性特征相结合的方法构建特征参数向量。所采用的特征参数向量包括:语谱图显著图灰度分布参数、显著图面积比参数、能量、幅度、过零率和基音频率这6种参数作为识别模型的特征参数向量进行识别。
实验中我们使用到的情感语音信号四名录制者(男女各两名),语音内容为20句不同的话语,每位录制者分别对这20句话用不同的情感表达,采用专业的录音工具录制而得。每种情感含有80个样本语音,每个语音样本的采样率为11 025 Hz,以16 bit、“.wav”的格式保存于PC机中。从录制完的语音情感库中每种情感选取120个样本作为训练样本集,也即标本库。选取剩余120句作为测试样本集,也即待测库。
识别测试中我们使用KNN分类算法进行识别[8]。并对仅使用四维时域特征(基频、能量、幅度和过零率)和使用六维特征(加入两个显著图参数:显著图分布参数和显著图面积比)两种情况下的识别率进行对比。
4.1 四维特征识别率和六维特征识别结果对比
在不使用显著性参数的情况下,构建四维特征参数向量进行情感识别。各情感及不同分类算法的识别结果如表2所示。在特征参数向量中加入显著图参数,构建六维特征参数向量进行情感识别。各情感及不同分类算法的识别结果如表3所示。
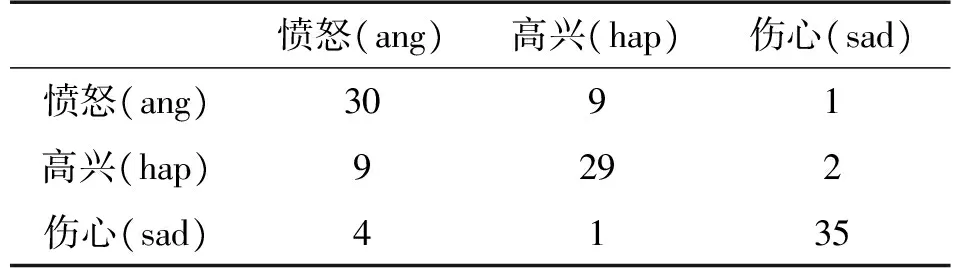
表1 四维特征识别结果
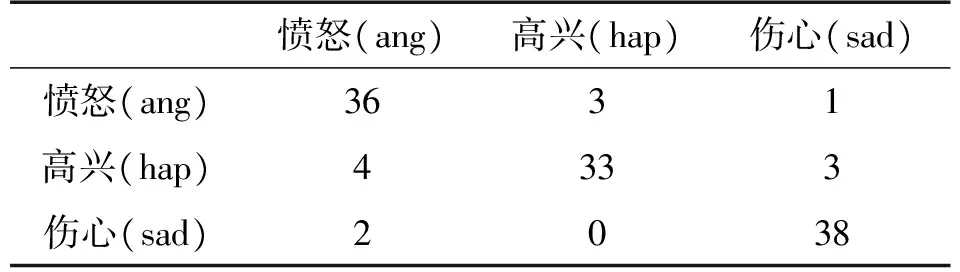
表2 六维特征识别结果
4.2 实验结果分析
从以上四维和六维特征的识别结果可以看出:加入显著图特征参数之后,算法的情感识别率均有所提升,各情感的识别率均在80%左右,愤怒(ang)和伤心(sad)情感的识别率接近于90%,在四维特征识别率中表现不佳的高兴(hap)情感识别率在加入显著图特征参数后识别率提升至80%以上。这表明引入显著图特征参数后算法的识别率有了一定的改善。
5 结论
本文主要对情感识别算法中新型特征参数的构造进行分析研究,提出两种显著性特征参数用于情感识别。基于传统特征参数识别算法的识别率基本保持在70%~80%之间;在特征参数向量中加入提出的两种显著性参数后识别效率基本在80%~90%范围内。由此可见,基于显著性参数的识别模型具有较好的识别性能,相比于利用传统特征参数进行识别的模型来说有进10%的提升,具有较高的研究价值。
[1] Song K T,Han M J,Wang S C. Speech Signal-Based Emotion Recognition and Its Application to Entertainment Robots[J]. Journal of the Chinese Institute of Engineers,2014,37(1):14-25.
[2] Attabi Y,Dumouchel P. Anchor Models for Emotion Recognition from Speech[J]. Ieee Transactions on Affective Computing,2013,4(3):280-290.
[3] Ramakrishnan S,El Emary I M M. Speech Emotion Recognition Approaches in Human Computer Interaction[J]. Telecommunication Systems,2013,52(3):1467-1478.
[4] Planet S,Iriondo I. Children's Emotion Recognition from Spontaneous Speech Using a Reduced Set of Acoustic and Linguistic Features[J]. Cognitive Computation,2013,5(4):526-532.
[5] Schröder M. Speech Emotion Recognition Using Hidden Markov Models[J]. 2016.
[6] Jin Q,Li C,Chen S,et al. Speech Emotion Recognition with Acoustic and Lexical Features[J]. 2015:4749-4753.
[7] Ferreira C B R,Soares F,Martins W S. Parallel CUDA Based Implementation of Gaussian Pyramid Image Reduction[C]//XII Workshop de Visão Computacional. 2016.
[8] Liu Q,Liu C. A Novel Locally Linear KNN Model for Visual Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE,2015:1329-1337.
PracticalSpeechEmotionRecognitonAlgorithmResearch*
YUHua1*,ZHANGQinjie2,ZHAOLi2
(1.Jiangsu Open University,Nanjing 210065,China;2.School of Information Engineering,Southeast University,Nanjing 210096,China)
Speech Emotion recognition is one of the key technologies of intelligent human-computer interaction. However,the speech emotion feature for speech emotion recognition is very limited. Therefore,a new spectrogram of significant features is proposed to improve speech emotion recognition effect. Using selective attention model to obtain significant speech signal spectral image of the language,and extract significant features,recognition algorithm combined with the frequency characteristics of the speech signal constitutes the traditional speech emotion recognition feature vectors. Finally,we use KNN classification method for speech emotion recognition. Experimental results show that adding significant feature recognition rate has improved significantly.
speech emotion recognition;significant features;KNN classification method
10.3969/j.issn.1005-9490.2017.05.035
项目来源:国家自然科学基金项目(61673108)
2017-05-08修改日期2017-06-22
TN912;TP317.5
A
1005-9490(2017)05-1234-04

余华(1963-),女,江苏开放大学教授,研究方向为情感信息处理、电子与通信。
