分布式深度学习研究
2017-10-16辜阳杨大为
辜阳++杨大为

摘 要:传统单机深度学习模型的训练耗时,动辄花费一周甚至数月的时间,让研究者望而却步,因此深度学习并行训练的方法被提出,用来加速深度学习算法的学习过程。文章首先分析了为什么要实现分布式训练,然后分别介绍了基于模型并行和数据并行两种主要的分布式深度学习框架,最后对两种不同的分布式深度学习框架的优缺点进行比较,得出结论。
关键词:深度学习;分布式训练;模型并行;数据并行
中图分类号:TP181 文献标志码:A 文章编号:2095-2945(2017)29-0007-02
1 概述
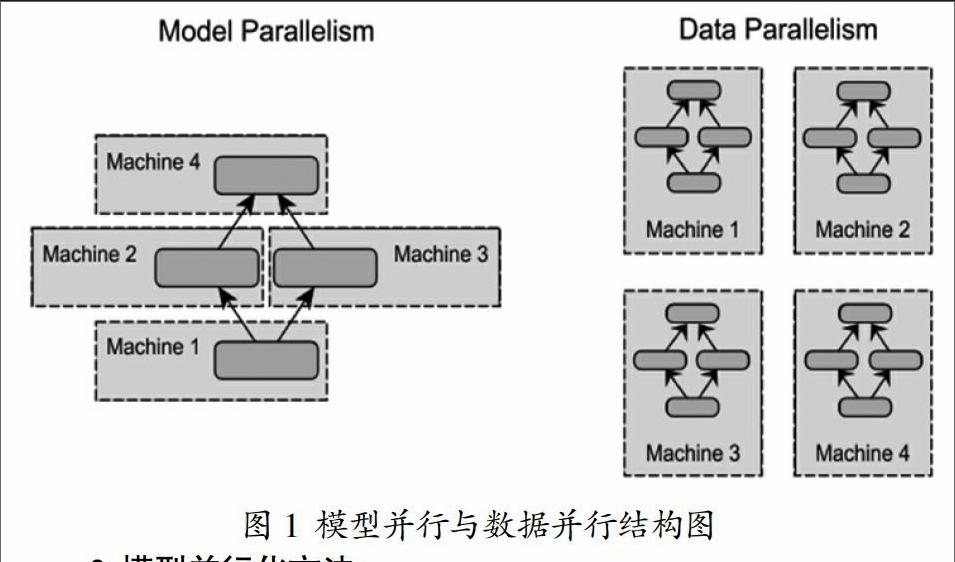
深度学习已经在计算机视觉,文本处理,自然语言识别等领域取得了卓越成就,受到学术界和工业界的广泛关注。随着对深度学习领域研究的深入,有证据表明增大模型参数规模和训练数据集,能有效的提高模型精度。但精度提升同时也带来了巨大的训练时间成本。简单的采用单机加GPU计算的方式,受限于目前GPU的显存限制和单机扩展能力,已经不能满足大型深层网络结构和超TB大小的训练集所要求的计算能力和存储空间。针对上述问题,研究者投入了大量的工作,研究分布式深度学习训练框架,来提升训练效率。当前的分布式深度学习框架主要包含模型并行(model parallelism),数据并行(data parallelism)两种方法,两者的结构如图1所示,左边为模型并行结构,右边为数据并行结构。
2 模型并行化方法
在模型并行化方法里,分布式系统中的不同机器节点负责单个网络模型的不同部分计算。例如,卷积神经网络模型中的不同网络层被分配到不同的机器。每个机器只计算网络结构的一部分,能够起到加速训练的效果。模型并行化适合单机内存容纳不下的超大规模的深度学习模型,其具有良好的扩展能力,尽管在实际应用中的效果还不错,但是在模型能够在单机加载的情况下,数据并行化却是多数分布式深度学习系统的首选,因为数据并行化在实现难度、容错率和集群利用率方面都优于模型并行化,数据并行化方法适用于采用大量训练数据的中小模型,具体介绍见第3小节。
3 数据并行化方法
在数据并行化方法里,分布式框架中的每个节点上都存储一份网络模型的副本,各台机器只处理自己所分配到的一部分训练数据集,然后在各节点之间同步模型参数,模型参数同步算法分为同步式和异步式两种。
3.1 同步式算法
标准的同步式算法,每次迭代都分为三个步骤,首先,从参数服务器(Parameter Server,PS)中把模型参数w拉取(pull)到本地,接着用新的模型参数w计算本地mini-batch的梯度Δw,最后将计算出的梯度Δw推送(push)到PS。PS需要收集所有节点的梯度,再按照公式(1)进行平均处理更新模型参数,其中?琢为学习率。
雅虎开源的基于Spark平台的深度学习包CaffeOnSpark就是采用的同步式算法,同步式算法如图2所示。
这种强同步式算法,会由于系统中各个机器之间的性能差异,导致所有的节点都要等待计算最慢的一个节点执行完,产生木桶效应问题。而且大量的同步操作,造成的通讯时间开销会限制同步式扩展能力,导致性能瓶颈。
3.2 异步式算法
异步随机梯度下降算法(Asynchronous Stochastic Gradient Descent,ASGD)是对同步式算法的改进。参数服务器只要接收到一个节点的梯度值就进行更新,而不是等待所有节点发送完梯度值,再进行平均操作,消除了木桶效应问题,并且利用梯度的延迟更新,如迭代m次再进行同步,减少网络通信量,降低网络通讯造成的时间开销,获得明显加速。文献[1]证明算法是收敛的。
异步式算法比同步式训练加速效果明显,但带来了一个新的问题,即梯度值过时问题。当某个节点算完了梯度值并且将其与参数服务器的全局参数合并时,全局参数可能已经被其他节点更新了多次,而此时传递过来的是一个已经过时的梯度值,会降低算法的收敛速率,达不到异步算法原本应有的加速效果,同时导致模型准确率下降。
异步随机梯度下降方法有多种形式的变种,都采取了各种策略来减弱梯度过时所造成的影响,同时保持分布式深度学习训练的高效率。解决梯度值过时的方法主要包括以下两种:
(1)对每次更新的梯度Δw,引入缩放因子?姿,控制梯度过时对全局的影响。参数的更新形式为:
(2)
(2)采用弱同步(soft synchronization)策略[2],相对于立即更新全局参数向量,参数服务器等待收集n(1≤j≤n)个节点产生的s(1≤s≤m)次更新后,参数随之按照公式(3)进行更新。若s=1,n=1;(3)式即为普通的异步随机梯度下降算法。若s=m;即为异步随机梯度下降法延迟更新。若s=1,n为所有的节点数,(3)式即为同步式算法。
这些改进方法相比简单的异步算法都能有效降低梯度值过时的影响,提升算法的收敛性能。正是由于异步式明显的加速优势,当前热门的分布式深度学习框架,如MXNet、TensorFlow、CNTK等大多采用异步随机梯度下降算法及其变种。
4 结束语
同步式方法就每一轮epoch的准确率,以及全局的准确率来说更胜一筹,然而,额外的同步开销也意味着这个方法的速度更慢。最大问题在于所谓的木桶效应问题:即同步系统需要等待最慢的处理节点结束之后才能进行下一次迭代。结果将会导致随着工作节点的增加,同步系统变得越来越慢,越来越不灵活。
异步式算法是当前加速训练模型的有效方法,在实际使用中也得到广泛应用,只需要控制好梯度值过时的问题。但是带有中心参数服务器的异步式算法仍然可能存在通讯瓶颈,还需要进一步研究解决存在的问题,充分发挥异步式的优势。未來两者的混合模型将是重点研究方向,使得分布式深度学习可以在大模型大训练集上快速训练,得到更加精准的模型。
参考文献:
[1]Zinkevich M,Langford J,Smola A. Slow learners are fast[C]. Advances in Neural Information Processing Systems 22(NIPS 2009),2009:2331-2339.
[2]Wei Zhang,Suyog Gupta,Xiangru Lian,and Ji Liu. Staleness-aware async-sgd for distributed deep learning. IJCAI, 2016.
[3]张行健,贾振堂,李祥.深度学习及其在动作行为识别中的进展[J].科技创新与应用,2016(06):66.endprint
