深度学习的汽车驾驶员安全带检测
2017-10-11杨凯杰章东平
杨凯杰,章东平 ,杨 力
(中国计量大学 信息工程学院,浙江 杭州 310018)
深度学习的汽车驾驶员安全带检测
杨凯杰,章东平 ,杨 力
(中国计量大学 信息工程学院,浙江 杭州 310018)
自智能交通系统出现以来,汽车驾乘员的安全带检测一直是备受关注的研究课题.依据城市道路的交通卡口监控数据,研究一种基于深度学习的汽车驾乘人员安全带检测算法,能够准确识别驾驶员是否佩戴安全带.通过对卡口图片进行人工标定,并运用深度学习方法训练两个检测器和一个分类器,最终实现安全带的快速定位和分类.本文提出的方法在城市道路卡口采集的图像上检测效果较好.
安全带检测;目标检测;深度学习;图像分类;智能交通
Abstract: With the development of intelligent traffic systems(ITS), the detection of drivers’ safety belts attracted a lot of attention. In this paper, we studied a safety belt detection algorithm based on deep learning, which could help accurately identify whether or not the driver wore the safety belt. The method could locate and classify the safetey belt by using deep learning to train the two detectors and a classifier. The method has a better detection effect on traffic monitoring images collected in urban roads.
Keywords: safety belt detection; object detection; deep learning; image classification; ITS
近年来随着国内汽车的不断增加,事故的案发量也与日俱增.当两车相撞时,驾驶员不系安全带的死亡率为75%,而系安全带的生还率为95%,因此安全带检测逐渐成为智能交通中热门的研究方向.
目前已有的安全带检测方法可分为两类:一是以Guo等人为代表提出的基于图像处理的传统方法[1],该方法包括驾驶区域定位模块和安全带检测模块,首先将一张图像进行预处理,即光纤补偿和图像去噪.然后将边缘检测和霍夫直线变化相结合,通过检测车窗边缘以进一步缩小安全带检测区域,再通过车辆、车窗和驾驶员的位置关系,以及检测安全带的两条长直线边缘,最终实现对安全带的检测.但是该方法受车身颜色、光照条件和拍摄角度的影响较大,缺乏鲁棒性,而且对图像的质量要求较高,因此较难推广.二是以Chen等人为代表提出的基于Adaboost的安全带检测系统[2],该方法通过Haar特征提取和模型训练,先后对车窗部件、驾驶员部件和安全带部件训练不同的弱分类器,定位各部件的候选区域,然后用加权级联的方法把所有的弱分类器变成一个强分类器,最后经过高斯混合模型的后处理得到安全带的精确检测结果.虽然该方法与传统方法相比,检测精度和鲁棒性有了一定提升,但是其检测精度还达不到可推广应用的地步,对图像质量的要求仍较高,安全带检测的误报也较多.
为了提高安全带检测的精度,提高系统的鲁棒性并减少误报,本文提出了一种基于深度学习的汽车驾驶员安全带检测方法.如图1所示,将高清卡口图片输入早已训练好的深度学习模型,包括两个检测器D1、D2和一个分类器C1,即可实现对安全带的定位和判断.具体分为以下三个步骤:
1) 将高清卡口图片输入第一个检测器D1,检测器D1用于检测图像中的汽车目标,并定位汽车的挡风玻璃区域;
2) 在此基础上用检测器D2检测挡风玻璃的主驾驶区域,进一步缩小安全带检测范围,同时过滤掉不符合条件的挡风玻璃区域图片;
3) 将主驾驶区域图片送入二元分类器C1判断是否系安全带,得到精确度较高的检测结果,完成对卡口图片的检测.

图1 基于深度学习的安全带检测框架图Figure 1 The framework of safety belt detection based on deep learning
1 卷积神经网络
近几年来,深度学习由于其强大的自主学习能力和较高的预测精度,逐步成为目标检测方法中的新宠儿.深度学习隶属于机器学习范畴,通过模仿人类脑神经的运作模式,实现对数据的自动学习和分析,常用于文本处理、声音检测和图像识别[3].深度学习的特点是结构复杂,多层网络可充分提取样本特征,并在不断的训练中调整各层的模型参数,以实现最优的预测效果.深度学习分为监督和无监督两种学习模式,无监督学习输入没有经过标注的样本,最终得到数据的本质特征,常用的有深度置信网络(DBNs);监督学习从已经标注好的样本中去学习,用于映射出新的实例,比如卷积神经网络(CNNs).
卷积神经网络是一种独特的神经网络,常应用于机器学习的图像处理方面.卷积神经网络的概念是由Hubel、Wiesel提出的[4],和传统的神经网络相比,它的复杂性较低,但识别效率却大大提高了.卷积神经网络主要用于目标分类领域,一个最基本的卷积神经网络,通常包含卷积层、下采样层和全连接层.
1.1 卷积层
卷积层主要用于提取图片的特征,也被称作为“特征提取层”.在一副图像中相邻像素之间的信息关联性很强,但会随着像素之间距离的增加而逐渐减弱.在卷积神经网络中,卷积层的神经元具有“局部感知”的特性,每一个神经元只提取局部特征,并在网络的最后几层整合成全局特征.如图2(a)所示,神经元Y1到YN中,每一个神经元都对输入层进行全连接,其参数总共为M×N个.而图2(b)中,隐层中每个神经元利用局部感知的特性,只对输入层的3个神经元进行卷积,从输入层到隐层的参数总共为3×N个,从隐层到输出层的参数为N个.因此采用局部连接替代普通神经网络中全连接的方法,可大大减少参数的个数,加快特征提取的速度和网络训练的效率.

图2 全连接和局部连接结构图Figure 2 Structure diagram of full connection and local connection
1.2 下采样层
下采样层也被称作池化层,按照采样方式可分为均值下采样和最大值下采样.下采样主要用于简化模型的复杂度,其过程如图3所示.

图3 下采样层原理图Figure 3 Schematic diagram of down-sampling layer
假设输入层大小为4×4,卷积核大小为2×2,滑动步长为2,则卷积核分别与输入层的4个2×2区域分别卷积,最终得到2×2的输出层.从4×4的输入层到2×2的输出层,可以看到通过下采样操作,能够大大减少模型的参数.下采样的计算如下:
Y00=X00W00+X01W01+X10W10+X11W11
Y01=X02W00+X03W01+X12W10+X13W11
Y10=X20W00+X21W01+X30W10+X31W11
Y11=X22W00+X23W01+X32W10+X33W11
W00+W01+W10+W11=1.
(1)
1)若为均值下采样,则2×2的卷积核中W00=W01=W10=W11=0.25,因此输出层的值即为输入层对应区域的均值,即把输入图像作模糊处理,并把长和宽各减少一半.
2)若为最大值下采样,则卷积核的四个值除了一个是1,其他都是0,最终筛选出区域中的最大值作为输出层的结果.此时输入层、卷积核、输出层三者的关系相当Y=max{X1,X2,X3,X4}.最大值下采样只保留输入图像的强特征,并把长和宽各减少一半.
1.3 全连接层
全连接层实质上也是一种特殊的卷积.当前面连接的是卷积层时,全连接层会变成全局卷积;而当前面跟的是全连接层时,则变成1×1的卷积.全连接层主要用于多目标分类,常见的有Softmax分类器.卷积层、池化层和激活函数层是把人眼可见的图像特征转换成抽象的高维特征,而全连接层负责把这些高维特征映射回低维空间,即分类标签.以图2(a)为例,全连接的表达式如式子(2)所示:

(2)
2 基于双网络的安全带检测
2.1 Faster RCNN检测网络
本文采用的是基于Faster RCNN卷积神经网络的目标检测方法,相比于普通的卷积神经网络,层次结构更深,预测准确性更高.具体网络结构如图4所示.

图4 Faster RCNN网络模型Figure 4 Network model of Faster RCNN
Faster RCNN卷积神经网络主要由两部分组成,分别为区域提议网络(RPN)和Fast RCNN网络[5].输入一张原图,通过5个卷积层的提取特征和2个下采样层的特征降维,再分别经过两个网络处理后,最终得到较为准确的检测目标.由于单一卷积层只获取到局部特征,因此网络使用5个卷积层来提取特征,保证特征的全局性.

若按照以往的方法,根据上路300个ROI区域的坐标在原图上截取对应位置得到300张子图,再把这些子图通过五个卷积层提取特征和两个下采样层降维,最终得到300个子特征图.该方法虽然操作简单,但重复300次特征提取会花费大量的时间,从而降低了目标检测的效率.本文将区域坐标与特征图结合起来,并把RPN网络和卷积层5的输出结果共同作为Fast RCNN网络的输入.通过RPN网络输出的300个ROI区域的坐标,在卷积层5输出的特征图上对应抠出300张子特征图,由于总体上只卷积了一次,相比于通过300张子图卷积得到子特征图的方式,本文方法的检测速度提升较大.
经过ROI下采样层的降维,所有子特征图被统一成固定大小,在全连接层中进行特征映射处理后,同样送入到Softmax层和边框回归层.Softmax层的优化目标是分类,对300个ROI逐个进行处理,判断每个ROI属于目标的概率;边框回归层的优化目标是对区域坐标进行修正,即输出每一类的边界回归偏差,使之更靠近真实目标所在的位置.最后输出得分最高的ROI区域,即为系安全带的主驾驶区域.
2.2 AlexNet
分类网络在得到主驾驶区域的图像后,需要一个二元分类器对图像进行分类,判断驾驶员是否系安全带.目前常用的分类器是支持向量机(SVM),SVM是一个有监督的学习模型,常用于模式识别、分类、以及回归分析[7].但是当样本数量变大、特征变多时,SVM参数的计算和存储将耗费大量的机器内存和运算时间,并且分类的精确度也不高.由于深度学习在图片分类等复杂问题上更具优势,因此本文采用AlexNet深度卷积网络结合Softmax的方法训练二分类器,实现对安全带的判定[8].AlexNet是深度学习在图像分类应用中典型的网络模型,其网络结构如图5所示.
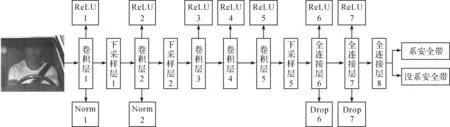
图5 AlexNet深度学习分类模型Figure 5 AlexNet classification model besed on deep learning
AlexNet深度卷积网络的主干由输入层、卷积层、下采样层、全连接层和Softmax层组成.整体思路是输入一张驾驶区域图片,经过5个卷积层充分学习图片的局部特征,并辅以3个下采样层进行特征降维.然后经过三个全连接层学习图像的全局特征,其中最后一个全连接层的输出即为融合了标签的Softmax层.Softmax支持多目标的分类,但本文中的Softmax层只设置了两个节点,其输出分别代表原图属于“系安全带”和“没系安全带”的概率,最后把概率较大的节点标签作为分类结果.
卷积层还同时连接ReLU层和Norm层.ReLU用于函数的激活,其表达式如公式(4)所示.传统的机器学习中一般采用Simoid和tanh函数来作为激活函数,但是这两个函数在梯度下降的过程中迭代次数较多,特别是在复杂的神经网络中,Simoid和tanh激活函数效率太低,导致运行速度变慢.因此本文采用 ReLU 函数,可大大缩短学习周期并提高效率.Norm层的作用为“临近抑制”,即实现局部区域的归一化,从而有助于模型的泛化.
ReLU(x)=max(x,0).
(4)
本文在全连接层中添加Drop层,它会在训练时随机关闭一半隐层神经元的输出,防止所有特征选择器共同作用,切断神经元之间的依赖性,终而避免一直放大或者缩小某些特征[9].图6是Drop的示意图,其中所有的神经元有50%的可能性被关闭,因此N个节点的神经网络可以看作是2N个模型的集合.Drop可减少神经元之间的互适应性,即使样本数据较少时也能有效防止过拟合.
3 实验结果与分析
3.1 挡风玻璃和主驾驶区域检测
本文训练Faster RCNN卷积神经网络模型所用图片均来自于卡口相机的拍摄,随机选取10 000张高清图像用于实验.首先通过人工对图像中的挡风玻璃区域进行标注,标注后实际可用图片为8 560张.然后将标注好的数据随机分成4∶1,分别用于模型训练的训练集和测试集,因此训练集和测试集分别有6 848张和1 712张,输入Faster RCNN网络后训练得到检测器D1.
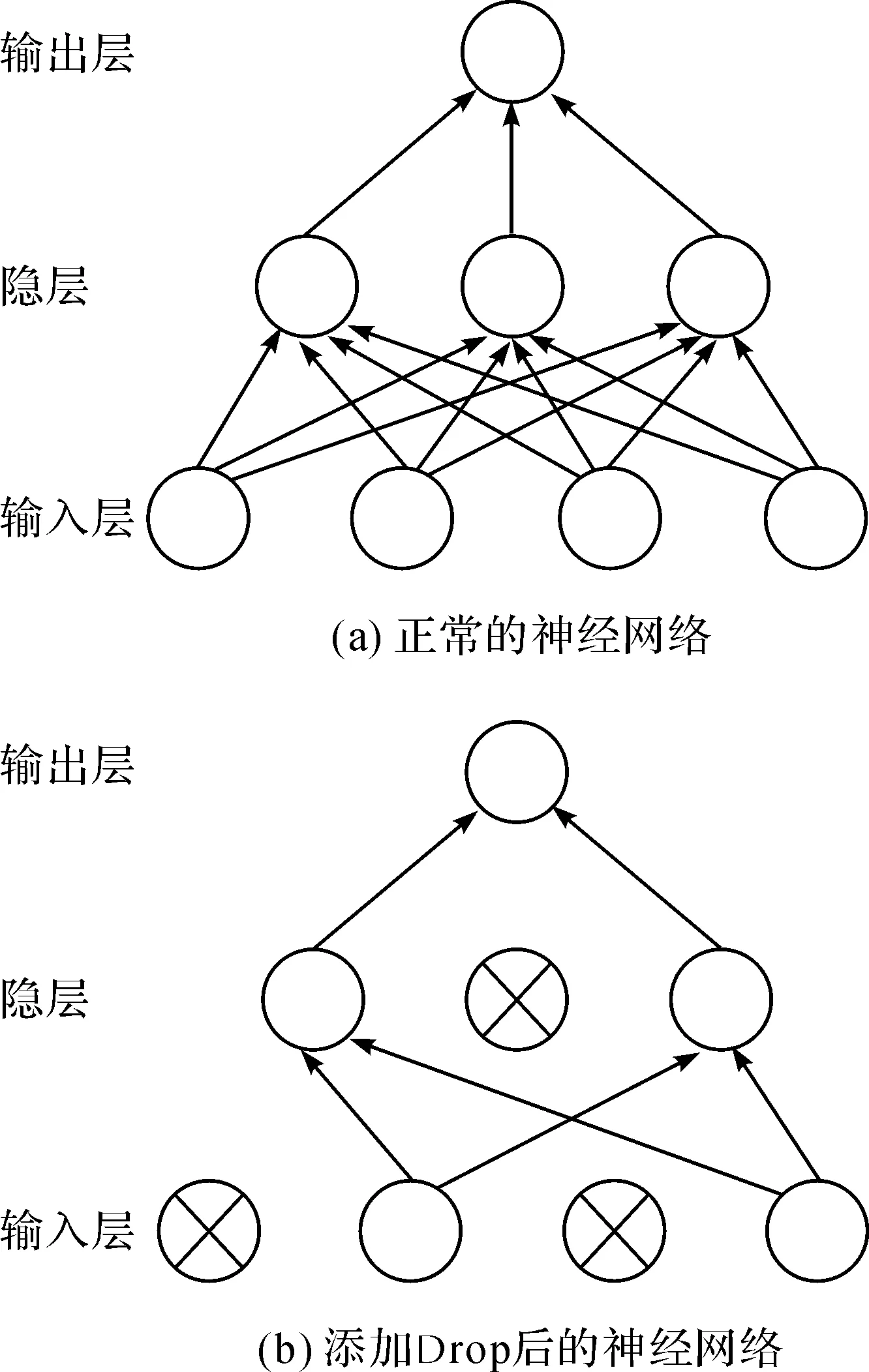
图6 效果比对图Figure 6 Comparison diagram of different effects
为了更好地验证模型效果,模型的测试图片由同一路段不同卡口的相机拍摄所得,并从中随机挑选出1000张作为检测数据集.同时本文使用检出率(DR)、虚警率(FAR)和漏检率(MAR)作为目标检测的评价指标[10].三个指标的计算方式如公式(5)所示,其中Ns表示待检测图片的总数,Nd表示正确检测到挡风玻璃的图片张数,Nf表示非挡风玻璃区域被识别成挡风玻璃区域的图片张数,Nm表示没有检测出挡风玻璃区域的图片张数.


(5)
检测器D1的实验结果:检出率为92.1%,虚警率为5.8%,漏检率为2.1%.挡风玻璃区域的检测示例如图7.

图7 挡风玻璃检测示例Figure 7 Detection example of windshield
检测主驾驶区域的Faster RCNN模型的训练过程也大致相同.首先把所有原图输入D1检测器处理后得到挡风玻璃区域图片,再对图片中的主驾驶区域进行手动标注,得到标注好的图片共7 875张.然后随机分成4∶1,作为第二个Faster RCNN模型的训练集和测试集,最终训练得到检测器D2.
接着从不同卡口相机拍摄的图像中随机抽取1000张用作检测数据集,检测器D2的实验结果:检出率为93.7%,虚警率为4.5%,漏检率为1.8%.主驾驶区域的检测示例如图8所示.
3.2 驾驶员安全带检测
首先往检测器D1和检测器D2输入大量的卡口图片,筛选出明显系安全带或未系安全带的驾驶区域图片各8 000张.为了提高分类器的准确性,对这16 000张图片进行预处理.将所有驾驶区域图片统一成256×256的大小,然后根据每张图像的亮度均值和灰度变化率调整亮度和锐度.最终随机挑选出系安全带和未系安全带的训练集各6 500张和测试集各1 500张,并输入AlexNet网络训练得到二元分类器C1.再用同样的方法随机挑选出与训练数据集不重复的图片各1 000张,作为模型的检测数据集.分类器的安全带检测示例如图9所示.

图8 主驾驶区域检测示例Figure 8 Detection example of left driving area

图9 安全带检测示例Figure 9 Detection example of safety belt
为了进一步比较检测效果,本文用Guo的传统图像处理方法和Chen的Adaboost方法分别做了安全带检测.传统图像处理在对图像进行预处理后,运用Canny边缘检测以实现对挡风玻璃的定位,然后用hough变换检测边缘中的直线,最后根据安全带的角度和距离等特性识别出安全带.而Adaboost通过对输入的数据不断迭代,将产生的效果较差的弱分类器不断级联,最终形成一个效果好的强分类器,并且具有很好的自适应性.三种方法采用同一数据集作为输入,同样使用检出率、虚警率和漏检率作为安全带检测的评价指标,对比实验结果如表1.

表1 三种方法检测实验结果对比
3.3 结果分析
从表1的结果可以看出,传统图像处理的检测效果最差.由于传统图像处理方法极易受光线条件、司机衣服颜色和车身颜色的影响,对于摄像机拍摄的角度也有较高的要求.而且大货车和小汽车的安全带位置区别很大,容易造成安全带区域的锁定错误.种种因素导致传统图像处理方法的鲁棒性差,单个场景下的最优参数并不适用于其他场景,结果表明传统方法的检出率只有82.53%,虚警率和漏检率也相对较高,分别为11.65%和5.82%.
通过比较可以发现,基于机器学习的Adaboost方法,对安全带的检测效果比传统图像处理要好得多,其检出率为90.28%.Adaboost采用弱分类器加权叠加成强分类器的方法,对于背景颜色和光照的鲁棒性较强,并能有效定位车窗区域.但对于安全带这种小范围区域的效果提升并不明显,当安全带区域较模糊时会被判定为“未系安全带”.因此该方法的虚警率较高有7.13%,漏检率为2.59%.
本文方法利用深度网络充分挖掘并学习汽车、挡风玻璃和主驾驶区域之间的特征关联,快速定位安全带区域.两个检测模型的级联可有效降低虚警率,即第一个检测模型的误检区域可在第二个检测模型中被过滤掉,实验证明虚警率仅为5.52%.而对主驾驶区域图片进行亮度和锐度的调整,可减少偏暗和模糊图片对检测的影响.最后级联一个基于深度学习的二分类模型,实现对安全带的准确分类.本文方法的检出率最高达到92.66%,漏检率最低为1.82%.
4 结 语
本文提出一种基于深度学习的汽车驾乘人员安全带检测方法,采用深度学习的多层次网络训练和模型级联的方式,在对安全带快速定位的同时,保证输出区域最优.并且结合二分类器的后处理以提高安全带区域分类的正确性和系统的鲁棒性,这在一定程度上降低了虚警率和漏检率.相比于传统图像处理方法和Adaboost方法,本文方案的检测效果更好.但是有几处不足:系统仍然不能实现对卡口图像的实时检测;只能对主驾驶座进行安全带的检测;车辆的误检较高,特别是车内无人时依旧在检测.因此,后期的目标主要有:继续优化模型结构,在保证正确率的前提下减少检测时间;增加副驾驶区域的训练样本,支持同时对主、副驾驶座上的人员进行安全带的检测;增加一个人脸识别模块,在保证座位上有人的前提下再检测安全带.
[1] GUO H, LIN H, ZHANG S, et al. Image-based seat belt detection[C]//IEEEInternationalConferenceonVehicularElectronicsandSafety. Beijing: IEEE, 2011:161-164.
[2] CHEN Y, LI G. Safety belt detetion system based on Adaboost[J].ElectronicMeasurementTechnology, 2015(4):123-127.
[3] LEE H, HERO A O. Efficient learning of sparse, distributed, convolutional feature representations for object recognition[C]//2011IEEEInternationalConferenceonComputerVision. Barcelona :IEEE, 2011:2643-2650.
[4] OUYANG W, WANG X. Joint deep learning for pedestrian detection[C]//IEEEInternationalConferenceonComputerVision. Sydney:IEEE, 2013:2056-2063.
[5] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J].IEEETransactionsonPatternAnalysis&MachineIntelligence, 2017, 39(6):1137.
[6] ZHENG L, ZHANG H, SUN S, et al. Person Re-identification in the wild[J].ComputerVisionandPatternRecognition, 2016(4):1-10.
[7] MATHUR A, FOODY G M. Multiclass and Binary SVM Classification: Implications for Training and Classification Users[J].IEEEGeoscience&RemoteSensingLetters, 2008, 5(2):241-245.
[8] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//InternationalConferenceonNeuralInformationProcessingSystems. USA:Curran Associates Inc. 2012:1097-1105.
[9] HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J].ComputerScience, 2012, 3(4): 212-223.
[10] RU X, LIU Z, HUANG Z, et al. Normalized residual-based constant false-alarm rate outlier detection[J].PatternRecognitionLetters, 2016, 69:1-7.
Safetybeltdetectionbasedondeeplearning
YANG Kaijie, ZHANG Dongping, YANG Li
(College of Information Engineering, China Jiliang University, Hangzhou 310018, China)
2096-2835(2017)03-0326-08
10.3969/j.issn.2096-2835.2017.03.010
2017-07-07 《中国计量大学学报》网址zgjl.cbpt.cnki.net
浙江省自然科学基金资助项目(No.LY15F020021),浙江省科技厅公益性项目(No.2016C31079).

TP181
A
