基于科研论文合著网络的社区发现算法研究*
2017-09-25夏欢,刘辉,詹隽
夏 欢,刘 辉,詹 隽
(安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243002)
基于科研论文合著网络的社区发现算法研究*
夏 欢,刘 辉,詹 隽
(安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243002)
为了更好地为广大学者阅读文献提供个性化的推荐服务,针对中国知网学术论文发现科研社区,提出了一种科研社区发现算法:首先利用Pajek构建出科研论文合著网络,并将网络公共数据集Dining-table partners和Sampson作为测试数据集,对科研社区发现算法和社区发现经典算法GN算法进行性能对比分析,验证科研社区发现算法的性能更优;最后利用算法发现科研社区结构,实验结果表明社区划分的效果较好。
科研社区发现算法;科研论文合著网络;性能对比分析;科研社区结构
现实世界中的很多真实网络都可以用图结构或者网络结构来描述。近年来,越来越多的学者将目光转移到复杂网络中社区结构的研究上。Newman等[1]于2004年提出社区发现的经典算法GN算法。由于GN算法的思想是从网络全局的角度来划分网络社区,而且准确率较高,因此,它成为社区发现领域的标准算法。后来的研究人员也提出了各种社区发现算法。例如,Chen等人[2]提出了一种重叠社区发现算法,其发现过程包括社区抽取和社区合并两个阶段。
文献[3]对某高校的科研论文合著网络的社区结构进行了试探性研究,将在其基础上进行更深一步的研究并对算法进行性能对比分析。对科研社区发现算法和GN算法进行性能对比分析,并基于某高校计算机学院研究生导师的知网论文集发现社区结构,研究成果可为个性化推荐[4]服务提供支持。
1 相关理论
1.1 合著网络
合著网络定义为:合著网络由节点组V={v1,v2,...vn}和边组E={e1,e2,…,en}构成,其中节点组中的各个节点分别对应各个作者,边组中的各条边分别对应学者之间的论文合著关系。如果两个作者有过论文合著关系,则存在边ei在边组E中,如果没有过论文合著关系,则在边组E中不存在边。由上述过程形成的网络称为合著网络。
1.2 节点与社区的连接度L(u,c)
u,v为当前网络中任意两个节点,c为一个社区,式(1)给出了u和c之间的连接度L(u,c)[2]的计算方式,其中,当u与v之间存在边相连时,wuv=1,否则,wuv=0,Du为节点u的度。如图1所示,假设当前的网络被划分为两个社区c1和c2,其中,社区c1包含1,2,3,4,5,6节点,社区c2包含7,8,9节点,则节点6与社区c1的连接度值即为节点6与社区c1的相连的边数与节点6的总度的比值,计算方式为L(6,c1)=3/5=0.6。
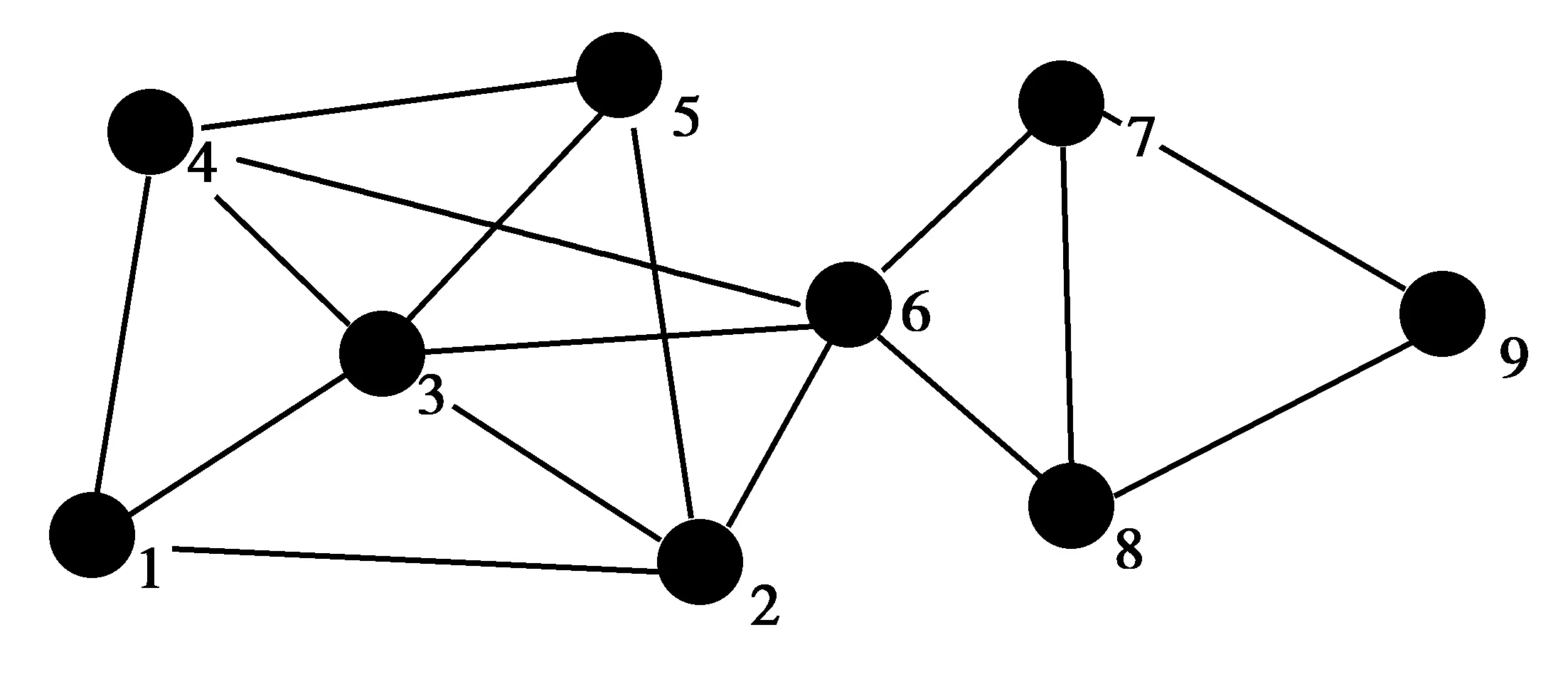
图1 网络示意图Fig.1 Sketch map of network
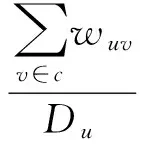
(1)
1.3 模块度函数EQ
选用的模块度是由Shen[5]等人定义的,可同时适用于发现网络中的重叠社区结构和非重叠社区结构的情形,模块度的定义方式如式(2),其中,Oi表示节点i所属于的社区个数,m表示当前网络中存在的总边数,Aij为网络的邻接矩阵,Ki,Kj分别表示节点i和节点j的度,当节点i,j在同一个社区时,δ(Ci,Cj)的值为1,否则为0。
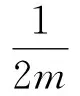
(2)
2 算法设计
科研社区发现算法的步骤可描述如下,其中的L(v,c)表示连接度,LV表示连接度阈值,取0.5。
算法描述:
① 标记科研论文合著网络中所有节点为F,将当前发现的社区放在集合List中,并对其赋初值为φ;
② 在标记为F的节点中,选取拥有最大度值的节点和其邻居节点,形成一个初始社区c;
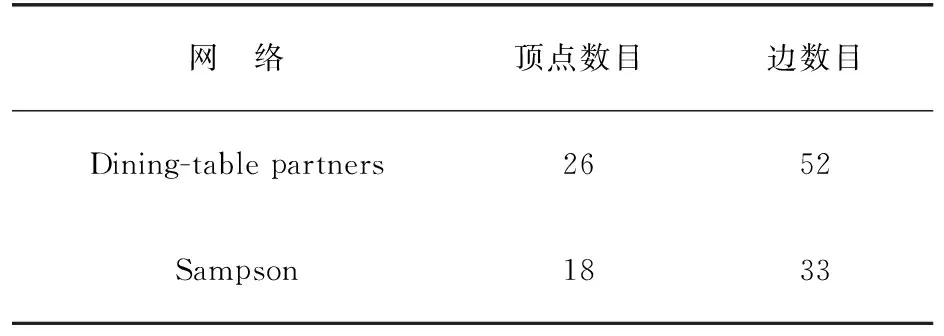
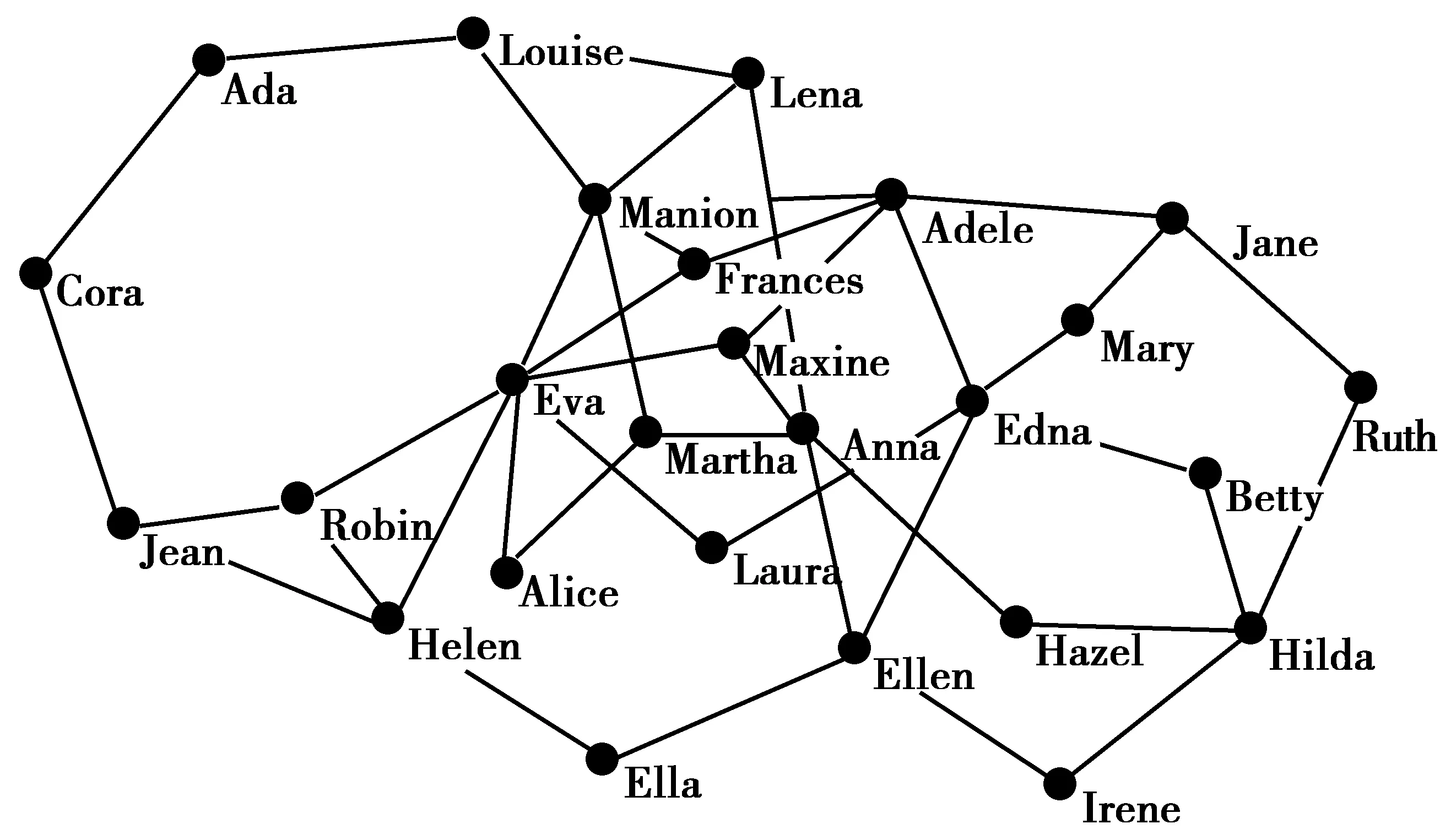
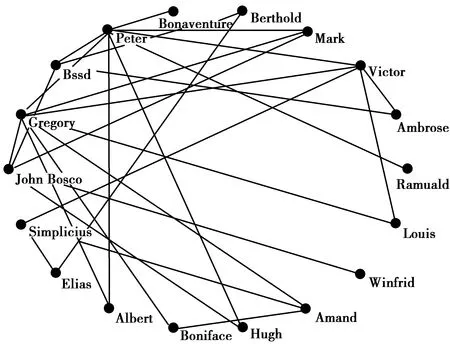
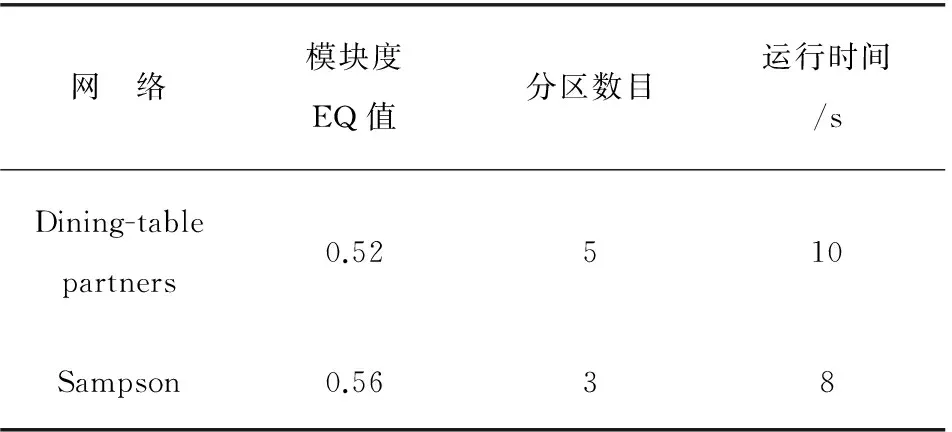
③ 依次判断社区c内的每一个节点v,计算节点v与社区c的连接度L(v,c);
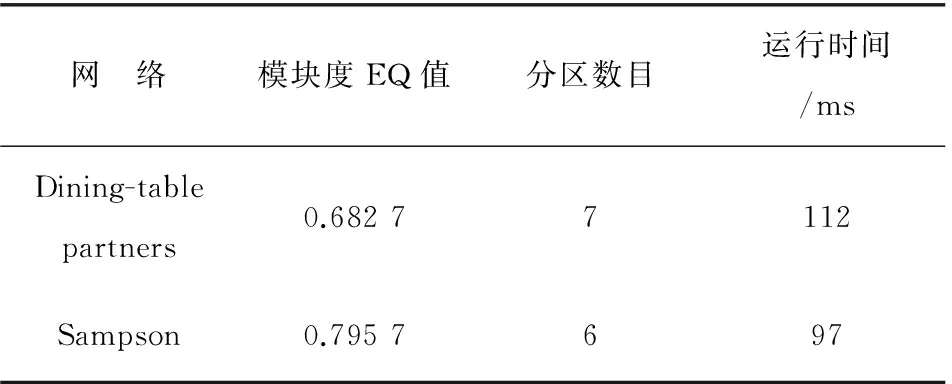
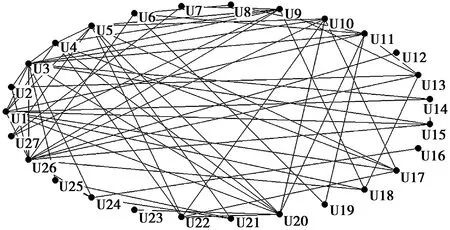
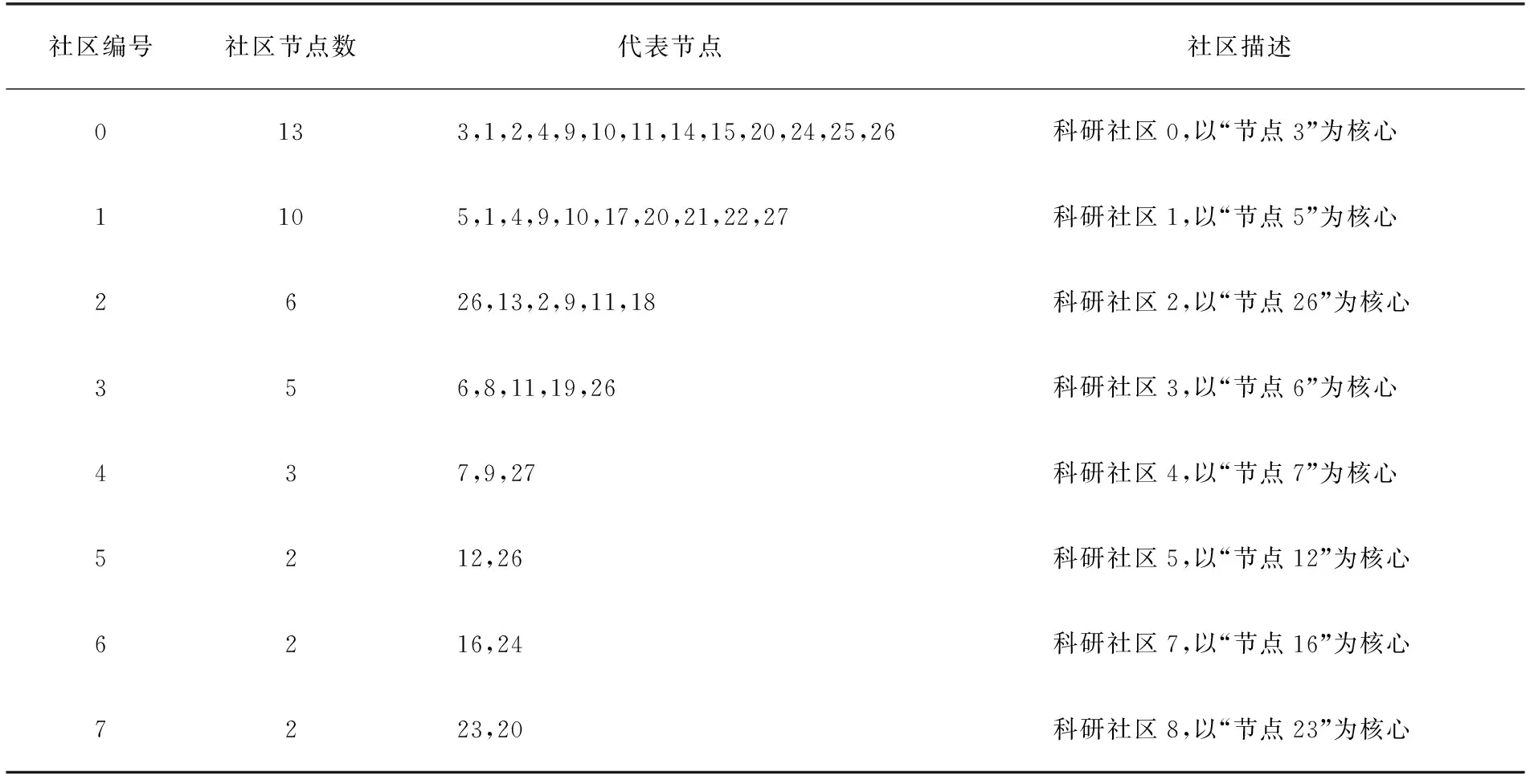
④ 当L(v,c) ⑤ 将社区c的所有邻居节点放入集合Nc中; ⑥ 依次判断Nc中的每一个节点v与社区c的连接度L(v,c); ⑦ 当L(v,c)≥LV时,将节点v并入社区c中,同时,更新社区结构,仍记为c; ⑧ 标记此时社区c中的所有节点为T; ⑨ 重复上述2~8步,则社区发现的最终结果为:PList=PList∪{c}。 由上面的算法描述,科研社区发现算法的执行流程可用图2表示。 图2 科研社区发现算法的工作流程Fig.2 Working process of scientific research community detection algorithm GN算法[1]是社区发现领域的经典算法,是一种分裂型算法,它从网络全局的角度考虑,准确率较高,并且可运用于较大网络的社区划分,局限性较小,适用范围更广,因此将GN算法作为科研社区发现算法的性能分析对比算法,从而验证算法的有效性。首先用Dining-table partners[6]和Sampson[7]这两个测试数据集对GN算法和科研社区发现算法进行社区发现性能测试,进行优越性比较后,得到算法效果较好,性能更优。选取某高校计算机学院研究生导师发表的论文合著情况作为原始数据源进行数据分析处理,得到导师彼此之间的论文合著关系,再用Pajek构建出科研论文合著网络,也就是实验数据集。最后,用提出的科研社区发现算法对网络进行社区划分,得到科研论文合著网络的社区结构。 3.1GN算法与科研社区发现算法的性能对比分析 下面将借用于两个合著网络的公共数据集,来比较得出科研社区发现算法性能相比较于GN算法的优越性。 3.1.1 测试数据集 采用的测试数据集是合著网络的公共数据集Dining-table partners和Sampson[6],都是无向无权网络,可在Pajek官网下载获取。实验中,算法与GN算法都分别用这两个数据集进行社区划分性能的测试。 3.1.2 实验结果 用Pajek对两个数据集进行网络结构分析,如表1所示,并分别构建网络图,是无向无权网络,如图3和图4所示。 表1 数据集的网络特征Table 1 Network characteristics of data set 图3 Dining-table partners网络图Fig.3 Network diagram of Dining-table partners 图4 Sampson网络图Fig.4 Network diagram of Sampson 然后用Java编程分别实现GN算法和科研社区发现算法对这两个数据集进行社区划分,从而对两种算法进行社区划分性能的测试。GN算法对两个数据集的划分结果汇总分析如表2所示,科研社区发现算法对两个数据集的划分结果汇总分析如表3所示。 表2 GN算法社区划分结果Table 2 Community division result of GN algorithm 表3 算法社区划分结果Table 3 Result of community division of the algorithm 由表2和表3可以看出,科研社区发现算法相对于经典社区发现算法的GN算法而言,运行时间更短,从而算法效率更高,并且模块度EQ值更高,因此,算法性能更好。在具有社区结构的网络中,社区内部的节点之间可被认为联系更加紧密,社区之间的节点之间可被认为联系相对稀疏。因此,对于某个社区而言,增加或减少节点数对于社区的紧密度应当有一定的影响,当某个社区内的节点个数越多时,紧密度变大就越困难,节点个数越少时,紧密度变大就越容易,即节点个数越多,可认为社区越稀疏。社区划分个数越多,每个社区内的节点数相对就变少,紧密度增加,社区划分越好。社区划分算法比GN算法划分的分区数目多,社区紧密度更好,社区划分的效果更好。因此再次得到科研社区发现算法在性能上优于GN算法。 3.2 科研社区发现算法实验 首先用Pajek对实验数据集Teacher进行初步的结构分析,并构建得到科研论文合著网络,然后用Java编程实现科研社区发现算法对数据集进行社区划分,最后对社区划分的结果进行分析评测。 3.2.1 数据处理过程 针对某高校计算机学院研究生导师发表的学术论文情况,将截至2016-12月份前,每个导师为第一作者发表的论文数据进行网络爬虫获取,并建立合著关系后进行分析处理,作为实验数据集。分析论文数据后得到他们之间的论文合著情况,然后进行科研论文合著网络的构建,此处剔除非研究生导师身份的不相关作者后,共有27人。首先,各研究生导师发表的论文信息(论文题目,作者)通过网络爬虫算法从中国知网获取,用mysql数据库存储这些信息,包括编号id、论文标题title和论文作者author,如图5所示。然后,在author列的每一项中都剔除非研究生导师的不相关作者,将数据处理成复杂网络分析软件Pajek的数据格式,最后,利用Pajek构建出高校计算机学院研究生导师之间的科研论文合著网络,是一个无向无权网络,有27个节点,67条边。科研论文合著网络中的节点代表论文作者,两个节点之间若有边相连,则说明两个作者之间存在论文合著关系。同时这里把实验数据集命名为Teacher。 图5 科研人员发表的论文信息(部分截图)Fig.5 Published paper data of scientific research workers(partial printscreen) 3.2.2 实验结果 用Pajek对Teacher数据集进行网络结构分析,如表4所示,并构建科研论文合著网络图,是一个无向无权网络,如图6所示。 表4 Teacher数据集的网络特征Table 4 Network characteristics of data set of Teacher 图6 Teacher网络图Fig.6 Network diagram of Teacher 在构建出科研论文合著网络后,进行科研社区发现算法的研究,并用Java语言编程实现。科研社区发现算法对科研论文合著网络的社区划分结果如图7所示,对划分结果进行汇总分析后如表5所示。其中模块度函数EQ值较高,为0.495 0,再次得出算法的性能较好。 图7 社区划分结果Fig.7 Result of community division 表5 社区划分结果汇总分析Table 5 Result summary analysis of community division 3.2.3 实验结果分析 科研社区发现算法可挖掘出高校计算机学院研究生导师之间存在的科研社区结构,共有8个科研社区,分别是以 “U3”,“U5”,“U26”,“U6”,“U7”,“U12”,“U16”,“U23”为核心的科研社区,同一社区内的用户可认为在学术研究上有着一些相通之处。将社区划分的结果与实际的学术科研团队进行对比后发现,相符度将近90%。由此可见,科研社区发现算法能准确有效地发现高校计算机学院科研论文合著网络中的社区结构,其成果可为接下来的网络结构分析、好友推荐以及论文推荐等个性化服务提供支持。 通过网络公共数据集将GN算法与科研社区发现算法进行性能对比分析,得到科研社区发现算法性能更优,并对科研论文合著网络进行社区划分,得到与现实的团队基本一致,更能得出科研社区发现算法具备的性能优越性。 [1] NEWMAN M E J,GIRVAN M.Finding and Evaluating Community Structure in Networks[J].Physical Review E,2004,69(2):113-119 [2] 陈端兵,尚明生,李霞.重叠社区发现的两段策略[J].计算机科学,2013,40(1):225-228 CHEN D B,SHANG M S,LI X.Two-phase Strategy on Overlapping Communities Detection[J].Computer Science,2013,40(1):225-228 [3] 夏欢,刘辉,张春.某高校科研社交网络社区结构的研究[J].常州工学院学报,2016,29(3):56-59 XIA H,LIU H,ZHANG C.Research on Community Structure of Scientific Research Social Networks for a Certain University[J].Journal of Changzhou Institute of Technology,2016,29(3):56-59 [4] 贾志洋,石宜金,李丁,等.基于协同过滤的在线教学视频推荐方法[J].重庆工商大学学报(自然科学版),2012,29(7):103-107 JIA Z Y,SHI Y J,LI D,et al.Online Teaching Video Recommendation Method Based on Collaborative Filter-ing[J].Journal of Chongqing Technology and Business University(Natural Science Edition),2012,29(7):103-107 [5] SHEN H,CHENG X,CAI K,et al.Detect Overlapping and Hierarchical Community Structure in Networks[J].Statistical Mechanics and its Applications,2009,388(8):1706-1712 [6] SAMPSON S.Exploratory Social Network Analysis with Pajek[M].Camb-ridge:Cambridge University Press,2005 Research on Community Detection Algorithm Based on Scientific Research Paper Coauthor Networks XIAHuan,LIUHui,ZHANJuan (School of Computer Science,Anhui University of Technology,Anhui Ma’anshan 243002,China) Detecting scientific research community based on CNKI’s academic papers could provide personalized recommendation service for reading documents of the majority of scholars.This paper put forward a scientific research community detection algorithm,firstly,established the scientific research paper coauthor network by Pajek,regarded Dining-table partners and Sampson of network common data set as testing data set to have a performance comparison and analysis on the scientific research community detection algorithm and classical GN algorithm,verified that the performance of the scientific research community detection algorithm was more superior and finally found scientific research community structure using the algorithm,and the experimental results showed that the effect of community division was pretty good. scientific research community detection algorithm; scientific research paper coauthor network; performance comparison analysis; scientific research community structure TP301 :A :1672-058X(2017)05-0050-06 责任编辑:田静 10.16055/j.issn.1672-058X.2017.0005.009 2017-03-06; :2017-04-01. 安徽工业大学研究生创新基金资助项目(2015065);国家大学生创新基金资助项目(201510360053). 夏欢(1992-),女,安徽滁州人,硕士研究生,从事社区发现算法研究.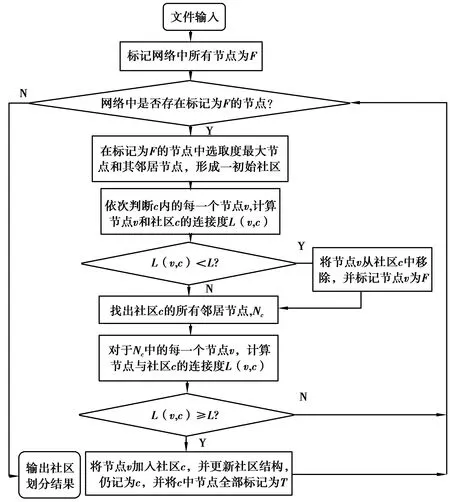
3 实 验


4 结 语
