使用多支持度的关联规则分类算法
2017-09-23黄亚东
黄亚东 刘 渊
(江南大学数字媒体学院 江苏 无锡 214122)
使用多支持度的关联规则分类算法
黄亚东 刘 渊
(江南大学数字媒体学院 江苏 无锡 214122)
传统关联分类算法使用单一最小项目支持度挖掘关联规则,导致稀有项关联规则无法被发现,从而影响分类的准确性和实用性。提出一种多支持度关联规则分类算法MS-CBAR(Multiple Supports-Classification Based on Association Rules),将多最小项目支持度模型应用于关联分类,以有效挖掘稀有项。该算法为数据库中的规则项提供了用户可定义的最小项目支持度。MS-CBAR算法使用项的最小项支持度阈值、类的最小类支持度值和规则项的最小支持度值决定分类规则是否频繁。生成分类规则集后,使用最高优先度规则覆盖法基于规则集建立分类器。实验表明,所提算法在包含稀有项目及稀有类的数据集中准确率高于传统关联分类算法及其相关算法,表现更稳定。
数据挖掘 多最小项目支持度 基于关联的分类算法 MS-CBAR
0 引 言
分类规则挖掘和关联规则挖掘是两种重要的数据挖掘技术。关联规则[1]挖掘旨在发现数据库中满足最小项目支持度和最小置信度阈值的所有频繁规则。分类规则[2]挖掘使用训练集构建分类器预测新数据对象的类标签。
基于关联的分类算法CBA(Classification Based on Associations)[3]将分类规则挖掘与关联规则挖掘结合,构建更为准确的分类器。CBA分两步建立分类器:第一步使用CBA-RG(CBA-Rule Generator)算法挖掘满足最小项目支持度和最小置信度阈值的所有类关联规则;第二步在CBA-RG算法生成的类关联规则上建立分类器。实验表明,CBA算法比C4.5算法的准确率更高。由于每个事务中的不同项和不同类可能重要程度不同,而CBA算法对数据库中的事务采用单一最小项支持度阈值,因而限制了算法的实际应用。例如对包含100个项目、2个类(健康和疾病)、10 000个事务的卫生状况数据集,“疾病”稀有类的真实支持度为1%,稀有项“发热”真实支持度为2%。如果将最小项支持度设置为20%,稀有项“发热”和稀有类“疾病”将被剪枝,与其相关的规则无法被发掘。而稀有项“发热”和稀有类“疾病”对研究健康状况有重要作用。为了发掘稀有项和稀有类,我们可以将最小项支持度设置为0.5%,但是会引起项组合爆炸,耗费大量计算资源,得到诸多无意义的关联规则,即“稀有项”问题。
稀有项问题会产生低质量的类关联规则集。如果类关联规则集不包含稀有项,那么基于类关联规则集建立的分类器无法覆盖测试集中包含稀有项的事务,影响了分类器的准确性。合适的类关联规则集是影响关联分类器准确性的关键因素。
为了提高CBA算法的分类准确性,文献[4]利用FP-Growth算法建立类关联分布树FP-tree,该算法采用分类规则树结构有效地存储关联规则并基于置信度、相关性和数据库覆盖来剪枝。分类的具体执行采用加权值来分析。文献[5]通过整合关联规则分类和传统的基于规则分类的优点,提出一种预测关联算法。该算法在规则生成时采用贪心算法策略,采用Laplace准确性评价规则,在预测时应用最优的规则,避免产生冗余的规则。同时,采用一种动态方法避免在规则生成时的重复计算,有效避免过拟合,产生所有候选项集的效率较高。
不同于上述文献[4-5],本文从解决稀有项问题出发,提出了一种新的使用多支持度MS(Multiple Supports)[6]的关联规则分类算法,称为多支持度关联分类规则算法MS-CBAR,提高分类器的准确性。算法为每个类和每个项目提供用户可定义的最小支持度,且不会产生大量无意义的类关联规则。
1 基于关联的分类算法
基于关联的CBA分类算法分两步建立分类器。第一步使用规则生成算法挖掘满足最小项目支持度和最小置信度阈值的所有类关联规则;第二步使用算法生成的类关联规则建立分类器。
设T为一个含有m个事务的数据集。每个事务都有一个分类y。设I={i1,i2,…,in}为T中所有项目的集合,Y为所有分类标识,且有I∩Y=∅,一个分类关联规则是指如下形式的关系:
X→yX⊆Iy∈Y
X称为规则前件,y为规则后件。支持度和置信度的定义和Apriori[1]算法一致。分类关联规则挖掘是指生成完整的满足用户指定的最小支持度minsup(minimum support)和最小置信度minconf(minimum confidence)限制的CAR集合。
1.1 生成分类关联规则
CBA-RG的关键操作是找出所有支持度高于最小支持度阈值的规则项。一个规则项可以表示成如下形式:
(condset,y)

condset→y
上述规则的支持度为:
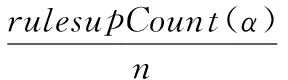
其中n为T中事务的总数量,置信度为:
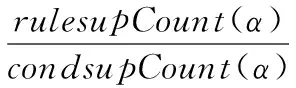
满足最小支持度的规则项称为频繁规则项,其余的称为非频繁规则项。
生成分类关联规则的算法为CAR-Apriori算法。CAR-Apriori算法需要多次遍历数据来生成所有频繁规则项。在第一次遍历中,算法计算每个1-规则项(即在条件集中只包含一个项目的规则项)的支持计数(算法L1行)。所有1-候选规则项的集合为:
C1={({i},y)|i∈I,y∈Y}
C1只是简单地将I中的每个项目和类标相关联。通过循环遍历,生成k-候选规则项的集合Ck。在对数据集的扫描过程中更新每个k-候选规则项的真实支持计数。数据扫描结束后,将具有相同分类的规则项通过合并其条件集进行合并,算法决定Ck中候选k-规则项是否频繁。
1.2 建立分类器
我们使用文献[3]的方法建立分类器。令CBA-RG步骤生成的分类关联规则集为S,训练数据集为D。建立分类器的思想是从S中选择一个可以覆盖数据集D的规则集L(⊆S),L中的规则的选择时基于S中各个规则的排序,另外L中包含一个默认类。
1.3 CBA算法的不足
在CBA算法中,单一最小项目支持度可能无法满足需求。在实际的分类数据集中的类分布可能非常不均匀,一个类占据数据集中大多数数据,而另外一个类占比很小。单一最小项支持度使得包含小数据集的稀有项的CAR无法被发现,影响基于CAR集构建的分类器的准确性。为挖掘包含稀有项的CAR,同时避免生成大量无意义的规则,本文提出了采用多支持度关联分类规则算法。该算法可使用:
(1) 多最小分类支持度,用户可以针对不同的类分别指定不同的最小支持度;
(2) 多最小项支持度,用户可以对每个项指定一个最小支持度值(可以是分类项或者非分类项)。
2 多支持度关联规则分类算法
2.1 相关定义
定义1设I={i1,i2, …,in}为项目集,MIS(ip)表示项ip的最小项支持度MIS(Minimum Item Support)值。项集A={i1,i2,…,ik}(1≤k≤n)的MIS定义为[6]:
MIS(A)=min[MIS(i1),MIS(i2),…,MIS(ik)]
在Apriori算法中,只有一个最小项支持度,所有频繁模式集都满足向下封闭性。即一个项集是频繁的,那么它的所有子集也都是频繁的。在多最小项目支持度模型算法中,向下封闭性就不再适用,即一个频繁项集的某些子集可能是非频繁的。
根据文献[6]提出的排序封闭性规则,假设项集中的所有项按照各自的MIS值升序排列,该项集任何超集的MIS值都等于该项集第一项的MIS值。如果低于其第一项的MIS值,该项目集是非频繁的,其任何超集都不会是频繁的。
基于上述性质,MS-Apriori可以通过减少搜索空间来挖掘所有符合多最小项目支持度的频繁项集。MS-Apriori 中的所有项先根据MIS值升序排列再剪枝。同时,由于某些项集的支持度是不确定的,MS-Apriori还需要计算所有频繁项集子集的支持度。

通过为各项指定不同最小项目支持度,为只包含频繁项目的规则项指定高最小项目支持度,为包含稀有项目的规则指定较低的最小项目支持度。对稀有类,同理。


2.2 MS-CBAR算法描述
MS-CBAR算法分两步建立分类器。具体的过程说明如下。

输出:频繁规则项集Lk
L2 L1= {{i}|i∈I, rulesupCount (i) ≥MRS(i)};
L3 for (k=2;Lk-1≠∅;k++)
L4 ifk=2 then
L5C2=level2_candidate_gen (L1)
L6 elseCk= mscbar_candidate_gen (Lk-1)
L8 for eachc∈Ckdo
L9 mrs = get-MRS(c)
L10 if rulesupCount(c) ≥ mrs then
L11 insertcintoLk;
L12 end
L13 end
L14 return ∪Lk
在多最小项目支持度概念中,向下封闭性不再适用,频繁规则项集的子集不一定是频繁的。为了生成完整的候选规则集,本文提出采用多最小项支持度生成两个候选集。

算法2level2_candidate_gen (L1)
输出:候选2-规则集C2
L1C2=∅
L2 for each rule-item (ia,y1) inL1in the same order do
L3 for each rule-item (ib,y1) inL1that is after (ia,y1) do
L4 ifia≠ibthen
L5C2= ∪ ({ia,ib},y1);
L6 end
L7end

算法3mscbar_candidate_gen(Lk-1)
输出:候选k-规则集Ck,k>2
L1Ck=∅;
L5 else
L7 end
L8 returnCk
MS-CBAR采用候选生成与测试方法来发现所有频繁规则项,需要证明候选生成方法的完整性。MS-CBAR算法采用多支持度的概念,所有频繁规则项必须满足排序封闭性。频繁规则项α的任何子规则项β也是频繁规则项,如果满足MRS(β) =MRS(α)。若rulesupCount(β) ≥MRS(α),rulesupCount(β)也满足MRS(β) =MRS(α),β也是频繁项集。该属性确保侯选生成与测试的方法是可行的,所有k-候选规则项都可以由(k-1)-子规则项生成。
2) 第二步是基于类关联规则集建立分类器的过程。从每个分区汇总所有频繁规则项及其频繁项计数。最后,根据频繁规则项及其相应计数组建分类器。构建分类器算法如下:
算法4分类器
输入:规则集S,训练数据集D
输出:规则集列表(分类器)L
L1S= sort(S);
//根据优先度>对S中的规则排序
L2L=φ;
L3 for each ruler∈Sin sequence do
L4 ifD≠∅ ANDr在D中至少正确覆盖一个事务 then
L5 从D中删除所有被r覆盖的事务;
L6 将r添加至L的尾部;
L7 end
L8 end
L9 将测试集中计数最多的类标签作为默认类加入L的尾部。
其中,规则排序的定义如下。
定义4对于两个规则,ri和rj,当满足以下条件时,ri>rj:
(1)ri比rj具有更高的置信度;
(2)ri比rj具有相同的置信度,ri比rj具有更高的支持度;
(3)ri与rj具有相同的置信度和支持度,产生较早的规则,排名较高。
最终的L具有以下的形式:
L=
其中,ri∈S,如果b>a则ra≻rb。在进行测试数据分类时,第一个能够覆盖测试用例的类作为这个用例的分类。如果任何一个规则都无法覆盖该用例,那么用例属于默认类(default_class)。
3 实验评估
3.1 实验准备
为了验证本文算法的有效性,本文从UCI机器学习库网站上选择了10个数据集,其中5个含有稀有项或稀有类。Annealing为退火数据集,稀有类为“1”;Breast Cancer为乳腺癌数据集,稀有类为“Malignant”;Diabetes为糖尿病数据集;German Credit为德国信用数据集,稀有类为“Bad”;Horse为马绞痛数据集;Iris为鸢尾花数据集;Lymphography为淋巴系造影术数据集,稀有类为“fibrosis”;Vehicle为车辆轮廓数据集;Waveform为波形发射器数据集;Zoo为动物园数据集,稀有类为“5”。这10个数据集均适合于多重变量分析与分类准确性研究。各数据集的属性如表1所示。

表1 实验数据集属性
实验运行在一台macOS Sierra系统的MacBook Pro上,处理器为2.5 GHz Intel Core i7,内存为16 GB。算法使用Java语言实现。在实验中,将C4.5、CBA算法和基于CBA算法改进的CMAR算法加入对比实验。C4.5算法使用机器学习软件WEKA 3.8.0实现;CBA和CMAR和CPAR算法采用其各自文献中的实现方式。在所有实验中,采用K折交叉验证来计算所提出的方法的准确性。将准确性定义为:

其中Acc表示准确性,本实验中取k=10。
为了全面衡量MS-CBAR分类器的性能,除准确性指标,还有查准率(Precision,P)、查全率(Recall,R)、F1值以及宏平均等指标。
查准率(P)定义为:

查全率(R)定义为:

F1值定义为:
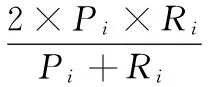
宏平均查准率(MacroP):
宏平均查全率(MacroR):
宏平均F1(MacroF1):
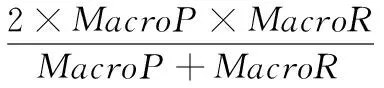
为了在MS-CBAR中的每个项上产生最小项值,采用文献[6]中提出的方法,考虑项的实际出现频率作为MIS值分配的基础。方程表述如下:
M(ip)=σ×f(ip) 0≤ip≤1
f(ip)表示项ip∈I在数据库中出现的次数,MRSall表示所有项中的最小MIS值。σ(0≤σ≤1)可以用于控制在挖掘过程中MIS值的作用。如果σ设置为0,所有项具有相同的MIS值(即MRSall),会产生与传统关联规则挖掘相同的结果。如果σ设置为1且M(ip) ≥MRSall,f(ip)就是ip的MIS值。
对于稀有类cls,我们将其MCS值定义为:

MS-CBAR算法中,稀有类和稀有项目的MCS及MIS值如表2所示。除稀有类以外的项目MIS值为1%,MCS值为10%。MS-CBAR算法的置信度阈值设置为50%。

表2 包含稀有项目数据集的MIS/MCS值
对于CBA算法,设置支持度阈值为1%,置信度阈值为50%,不限制规则数。CMAR算法的支持度和置信度阈值与CBA算法相同。数据集覆盖阈值为4,置信度差别阈值为20%。
3.2 实验结果与分析
本文首先选用10个数据集样本分别运行C4.5、CBA、CMAR 、CPAR和MS-CBAR 5种分类算法。其中,C4.5算法是经典的分类决策树算法, 用信息增益率来选择属性, 在决策树构造过程中进行剪枝,防止过拟合现象发生;CBA算法用关联规则挖掘算法发现频繁规则项,再基于规则项构建分类器;CMAR算法在CBA算法基础上使用FP-tree提升分类规则生成效率,并基于置信度、相关性和数据库覆盖剪枝。CPAR算法则在CBA基础上提出预测关联算法,预测时应用最优的规则,避免产生冗余的规则。本文提出的MS-CBAR算法则利用多支持度模型改进频繁规则项的生成过程,提高分类器的准确性。
从表3中可以看出,本文所提出的算法在10个数据单独表现并非最优,但平均准确度最高平均分类准确率最高。对于包含稀疏项的数据集准确率比其他算法高。对于不包含稀疏项的数据集来说,由于数据集中数据样本分布的不均衡,在不同数据集的性能也不同。同时,由于设置多支持度阈值,可能在部分数据集当中不同阈值的设定也会影响分类的准确率。
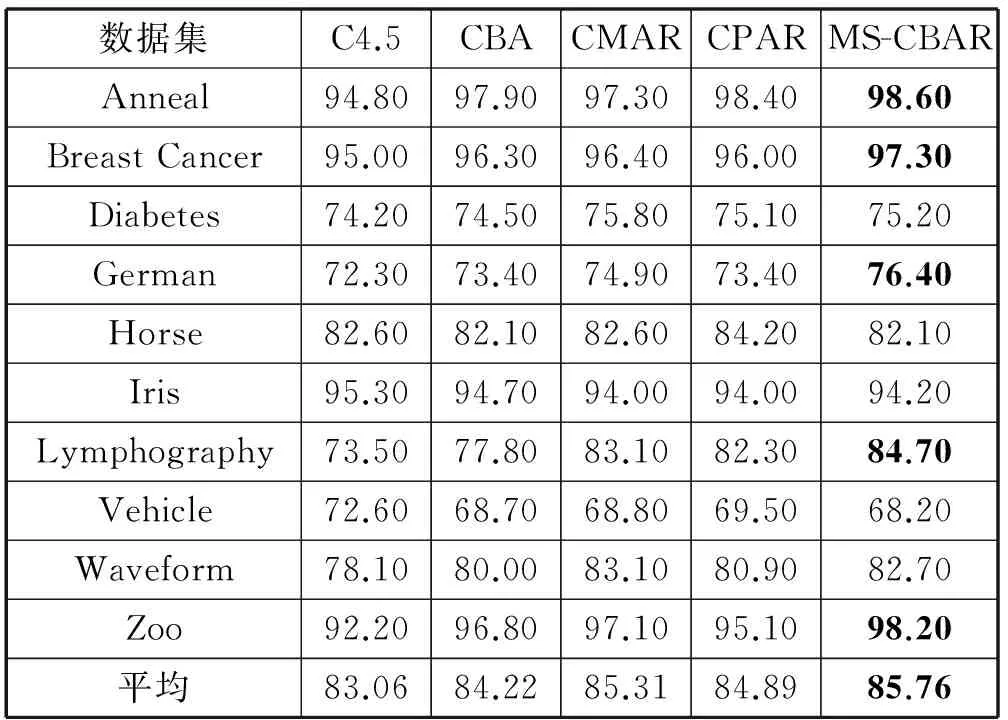
表3 各分类器准确性 %
对于5种分类算法在包含稀有项的5个数据集中的准确性如图1所示。可以看出,在5个包含稀有项目、稀有类的数据集中,本文所提出算法的准确度高于C4.5、CBA、CMAR和CPAR算法。在其他数据集中,MS-CBAR算法表现稳定,其准确性整体优于CBA算法,与CMAR准确性接近。在分类时准确率有所提升,但是提升幅度不大,由于数据集当中的稀有项数据并非大量存在,本文算法在包含稀有项的数据集中准确率最优。
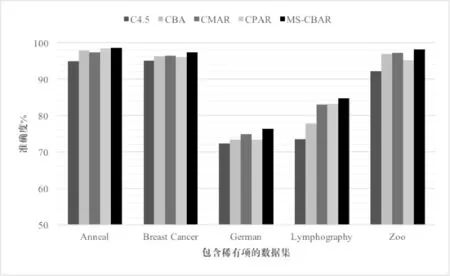
图1 包含稀有项目的数据集分类器对比
为了验证本文算法的有效性,本文通过对MacroP、MacroR、MacroF1分别进行分析,从表4可以看出,在多分类的问题上,本文提出的算法对于带有稀疏项的数据分类效果更好。

表4 各分类器宏平均查准率,宏平均查全率和宏F1在各数据集上的对比 %
4 结 语
在CBA算法中,稀有项问题使单个最小项目支持度很难发现包含稀有项的规则。本文提出将多最小项目支持度模型整合进分类器的算法-MS-CBAR算法。与传统多最小项目支持度方法不同,本文提出使用三个因素-项的MIS值、类的MCS值、规则项的MRS值-决定分类规则。实验结果显示,当数据集中存在稀有项时,MS-CBAR算法表现更好。
在下一步的研究中,我们可以采用本文提出的算法需要生成候选规则项集,但是在生成频繁规则项集阶段采用决策树学习的方法,考虑定义在特征空间上与类空间上的条件概率。根据损失函数最小化的原则建立决策树,无需生成候选规则项集,节约存储空间,提升算法效率。
[1] Agrawal R,Srikant R.Fast algorithms for mining association rules[C]//Proc.20th int. conf. very large data bases,VLDB.1994,1215:487-499.
[2] Quinlan J R.C4.5:programs for machine learning[M].Morgan Kaufmann Publishers Inc.1993.
[3] Liu B,Hsu W,Ma Y.Integrating classification and association rule mining[C]//International Conference on Knowledge Discovery and Data Mining.AAAI Press,1998:80-86.
[4] Li W,Han J,Pei J.CMAR:Accurate and Efficient Classification Based on Multiple Class-Association Rules[C]//IEEE International Conference on Data Mining.2001:19-21.
[5] Han J,Yin X.CPAR:Classification based on Predictive Association Rules[J].SDM,2003:331-335.
[6] Liu B.Mining association rules with multiple minimum supports[C]//ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM,1970:337-341.
[7] Liu B,Ma Y,Wong C K.Classification Using Association Rules:Weaknesses and Enhancements[J].Massive Computing,2001,2:591-605.
[8] Koh Y S,Ravana S D.Unsupervised Rare Pattern Mining:A Survey[J].ACM Transactions on Knowledge Discovery from Data (TKDD),2016,10(4):45.
[9] Pang-Ning Tan,Michael Steinbach,Vipin Kumar.数据挖掘导论[M].范明,范宏建,译.人民邮电出版社,2011.
[10] 吴信东.数据挖掘十大算法[M].清华大学出版社,2013.
[11] 刘兵.Web数据挖掘[M].俞勇,译.2版.清华大学出版社,2013.
[12] 王秀枝,安建成.基于支持度和置信度智能优化的关联分类算法[J].计算机应用与软件,2013,30(11):184-186.
[13] 薛福亮,马莉.利用动态产品分类树改进的关联规则推荐方法[J].计算机工程与应用,2016,52(4):135-141.
[14] 张明卫,朱志良,刘莹,等.一种大数据环境中分布式辅助关联分类算法[J].软件学报,2015,26(11):2795-2810.
[15] Rai D,Verma K S,Thoke A.Classification Algorithm based on MS Apriori for Rare Classes[J].International Journal of Computer Applications,2012,48(22):52-56.
[16] 李学明,杨阳,秦东霞,等.基于频繁闭项集的新关联分类算法ACCF[J].电子科技大学学报,2012,41(1):104-109.
[17] 吴小波,徐维祥.多支持度关联规则在网络使用挖掘中的应用[J].计算机工程与应用,2005,41(31):164-167.
[18] 刘华婷,郭仁祥,姜浩.关联规则挖掘Apriori算法的研究与改进[J].计算机应用与软件,2009,26(1):146-149.
ACLASSIFICATIONALGORITHMBASEDONASSOCIATIONRULESWITHMULTIPLESUPPORTS
Huang Yadong Liu Yuan
(SchoolofDigitalMedia,JiangnanUniversity,Wuxi214122,Jiangsu,China)
Traditional association classification algorithm uses single minimum item support to mining association rules, resulting in rare item association rules hard to find, thus affecting the accuracy of the classifier and practicality. Therefore, we propose a multiple support association rule classification MS-CBAR algorithm (Multiple Supports-Classification Based on Association Rules). Besides, the multi-minimum project support model is applied to association classification to effectively exploit the rare items. This algorithm provided user-definable minimum item support for both rule items and classes in the database. Then, the MS-CBAR algorithm adopted the minimum item support threshold, the minimum class support value of the class and the minimum support value of the rule items to determine whether the classification rules are frequent. Finally, after generating the classification rule set, the top priority rule coverage method was used to build the classifier based on the rule set. Experimental result demonstrates the proposed algorithm is more accurate than traditional association classification algorithms in data sets with rare items and rare classes. And its related algorithms are more stable.
Data mining Multiple minimum item support Classification algorithm based on association MS-CBAR
TP391
A
10.3969/j.issn.1000-386x.2017.09.048
2016-11-23。国家科技支撑计划项目(2015BAH54F00);国家自然科学基金项目(61672264);国家重点研发计划项目(2016YFB0800305)。黄亚东,硕士,主研领域:数据挖掘与机器学习。刘渊,教授。
