基于神经网络语言模型的分布式词向量研究进展
2017-09-22郁可人傅云斌董启文
郁可人,傅云斌,董启文
(华东师范大学数据科学与工程学院,上海200062)
基于神经网络语言模型的分布式词向量研究进展
郁可人,傅云斌,董启文
(华东师范大学数据科学与工程学院,上海200062)
单词向量化是自然语言处理领域中的重要研究课题之一,其核心是对文本中的单词建模,用一个较低维的向量来表征每个单词.生成词向量的方式有很多,目前性能最佳的是基于神经网络语言模型生成的分布式词向量,Google公司在2012年推出的Word2vec开源工具就是其中之一.分布式词向量已被应用于聚类、命名实体识别、词性分析等自然语言处理任务中,它的性能依赖于神经网络语言模型本身的性能,并与语言模型处理的具体任务有关.本文从三个方面介绍基于神经网络的分布式词向量,包括:经典神经网络语言模型的构建方法;对语言模型中存在的多分类问题的优化方法;如何利用辅助结构训练词向量.
词向量;语言模型;神经网络
0 引言
在自然语言处理(Natural Language Processing,NLP)领域中,用向量表示单词是一种非常常见的建模方式,向量各维度代表单词的各个特征,也称为单词转换词向量.单词转换词向量的方法大致可分为两大类:独热表示(one hot representation)和分布式表示(distributional representation).
独热表示即独热编码,或称局部表示(local representation),是一种极为直观的表现方式.向量中的每一位都是比特位,一个比特位只能表示一种状态的存在与否.在自然语言环境中,一种状态对应一个单词,要表示一个单词时令该单词对应状态位取1,其余状态位全部取0.但是,汉语常用字有6 763个(GB2312-80),英语单词常用词数量在10 000以上,无论哪种语言,使用独热向量表示单词都意味着向量的维度会等于词汇表大小,进行矩阵计算时计算量大,极易陷入“维度灾难”.这种词向量是稀疏的,且不带有任何语义信息.
分布式表示同样将单词看作向量对象,但向量各维可以取连续值.分布式表示的根本目的是希望用更少的维度表达更完整的单词信息,显然,其难点在于对单词特征的提取以及度量各项特征的强弱.早在20世纪50年代,Harris和Firth等就提出过分布假说(Distributional Hypothesis):“单词的词义可以由其上下文表征,具有相似意义的单词通常出现在相似的上下文环境中”[1-2].以分布假说为理论依据,可以将单词的上下文作为单词的语义特征,而特征的强弱可以用单词与上下文的共现次数来量化表示,这种表示方法称为单词的分布表示(distributed representation).分布式表示与分布表示这两个概念虽然产生来源不同1.分布式表示(distributed representation)有别于分布表示(distributional representation).分布式表示强调用多个维度分布地表示对象,为了区别于独热表示提出;而分布表示强调基于分布理论,即共现上下文影响词义.绝大多数分布式词向量都是分布表示的,而分布表示都基于分布假说.,但两者在多数场合下可以互相替代,本文统一使用分布式表示.
近年来,随着深度学习和神经网络的发展,很多研究者开始关注如何利用神经网络模型完成NLP任务.利用神经网络生成分布式词向量就是其中之一.大致做法是,首先初始化单词向量,随后将词向量作为神经网络语言模型的参数参与训练,语言模型训练优化的同时词向量也得到优化.训练得到的词向量可以独立使用,也可以作为参数进一步参与其他任务的训练.这种词向量称为基于神经网络的单词分布式表示,也是本文的主要关注对象.
1 相关背景
分布式表示可以按照实现方式进行分类,包括:基于矩阵的单词分布式表示(matrix based word distributed representation),基于聚类的单词分布式表示(clustering based word distributed representation)和基于神经网络的单词分布式表示(neural network based word distributed representation)[3-4].
依据分布假说,单词的语义与其上下文相关,因此选择一个包含上下文信息能力强的模型是生成分布式词向量的基础.
1.1 n-gram语言模型
n-gram语言模型是一种统计语言模型,用于计算一段文本在自然语言环境中出现的概率.n-gram语言模型用大小为n的n-gram滑动窗口提取文本中的每个单词及其前(n-1)个上下文单词,在每一个窗口中,根据上下文单词的出现频率来预测目标单词的出现概率,最终利用贝叶斯法则算得整段文本的出现概率.
当n取1时,n-gram模型退化为unigram模型,unigram模型不包含任何上下文信息;当n取2时,n-gram称为bigram,每个单词的上下文是该单词的前一个单词,也称为一阶马尔可夫模型;以此类推.虽然n越大表示上下文越丰富,但当n较大时可能导致采得的样本频数过少甚至采不到样本.n-gram语言模型希望采得的样本符合长尾分布,并需要对样本进行数据平滑,这种强依赖于样本准确性的性质导致其性能一般.
1.2 基于矩阵的分布式表示
在基于矩阵的分布式表示中,矩阵指共现矩阵(cooccurrence matrix),对共现矩阵进行降维后可以得到分布式表示的词向量.以生成词向量为目的的共现矩阵,其共现对象的一方必然是单词,另一方可以是多种类型的上下文,共现矩阵中的值表示某个单词在对应上下文中的出现频率.共现矩阵初始化方法对词向量和语言模型的影响较大,影响因素主要包括对单词上下文的选择和共现次数的统计方式[4].比较常见的基于矩阵的分布式表示模型包括LSA(LSI)[5]和GloVe[6].
1.3 基于聚类的分布式表示
基于聚类的分布式表示对具有相似上下文的单词对象进行层级聚类,希望同一类中的单词具有相似的语义,再为每一类中的单词分配词向量,比较常见的做法是基于布朗聚类的单词表示[7-8].此外,用聚类方法作为神经网络语言模型的辅助,可以很好地解决一词多义问题,效果不错[9].
2 神经网络语言模型
Hinton在1986年提出可以对“概念”(concepts)进行分布式表示[10],之后这种做法被引入到单词表示中,核心思想是将高维空间中的单词映射到低维空间中,也称为词嵌入(word embedding).
神经网络语言模型属于统计语言模型,根本目的是为了评估与预测语言序列.神经网络语言模型中使用低维的词向量作为单词建模对象,提取单词的语义特征并用于完成NLP任务.随着神经网络语言模型的不断优化,词向量携带语义信息的能力也不断增加,两者不是严格正相关,但在大部分范围内模型的优化能够提高词向量的性能.本节介绍几种经典的神经网络语言模型,及伴随模型产生的分布式词向量.
2.1 Xu&Alex模型
神经网络语言模型的概念在1991年[11]就已被提出,W.Xu和Alex Rudnicky[12]在2000年再次尝试用神经网络对自然语言建模.
2.1.1 模型描述
设词汇表中单词个数为|V|,则神经网络输入层输出层各有|V|个结点.输入层用独热向量表示,只有上下文单词所对应的维度取1,其余取0.输出层表示为目标单词的概率分布,各维度概率和为1.激活函数采用softmax.损失函数采用困惑度(perplexity)的对数和,计算预测值与目标值之间的误差.神经网络模型函数为

其中,权重矩阵W的形状是|V|×|V|;x是输入的上下文单词向量,形状是|V|×1;输出向量y的形状也是|V|×1.
2.1.2 模型分析
Xu&Alex模型效果较n-gram模型更优,但是该模型一次训练所需的计算复杂度为|V|×(|V|+1),考虑到|V|较大,即使采用了规模更小的词汇表复杂度仍然很高.
矩阵W的每一行Wi都蕴含了该上下文与词汇表中第i个单词共现的可能性信息,可能性权值为Wijxj,xj表示独热词向量的第j维.随着多次迭代训练,Wi能够根据上下文单词x推断出目标单词是第i个单词的概率.因此Wi可以说是一种代表目标单词的“目标单词词向量”.但是,Xu和Alex没有参考Hinton提出的分布式表示,没有增加隐藏层来提高模型拟合能力.另外,伴随模型产生的词向量的维度仍然是|V|,并没有降维.
2.2 NPLM模型
Bengio参考了Hinton提出的分布式表示方法以及Xu&Alex神经网络语言模型构建方法,在2003年提出了神经网络概率语言模型(Neural Probabilistic Language Model, NPLM)[13].
Xu&Alex模型的缺点在于词向量维度过大,并且难以收敛,对此NPLM的解决方案是在输入层采用低维的词向量代替独热编码词向量.降维后的分布式词向量是稠密、低维(远小于词汇表维度)的,且每一维都是实数[4].此外,在Xu&Alex模型中目标单词的上下文单词数增加时,其复杂度将指数增长,而NPLM模型中将不再有这个问题.
2.2.1 模型描述
设分布式词向量维度为m,选用目标单词前n-1个单词作为上下文,输入层是对n-1个m维词向量的级联,输入层有(n-1)m个结点.NPLM有一个隐藏层,隐藏层负责提供非线性的激活函数,设隐藏层向量维度为|H|.输出层仍然是对目标单词出现概率分布的预测,因此仍然采用softmax激活函数.损失函数采用对数极大似然估计.模型函数为
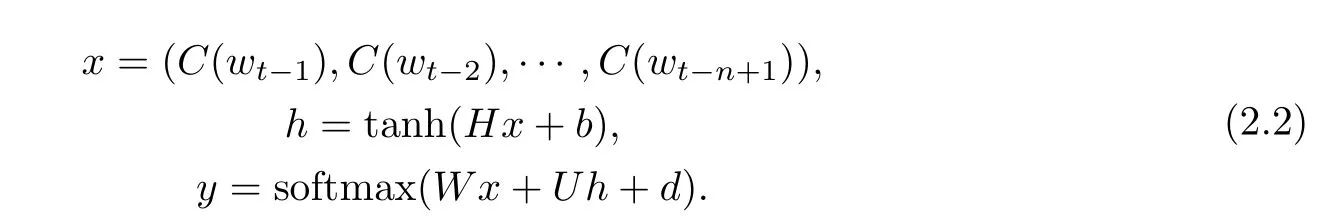
其中,C(w)是每个上下文单词初始化的词向量,维度为m,远小于|V|;输入向量x形状为(n-1)m;权重矩阵H形状是|H|×(n-1)m;权重矩阵U形状是|V|×|H|;权重矩阵W的形状是|V|×(n-1)m;h作为隐藏层的输出,形状是|H|×1;y是最终输出,形状为|V|×1,y中的每一个yi表示目标单词是单词表中第i个单词的概率.
2.2.2 模型分析
从公式(2.2)中可以看出,模型大致可以拆分成两个部分:非线性部分U tanh(H x+b)以及线性直连部分W x.如果只激活直连部分,模型会退化为Xu&Alex模型,如果只激活非线性部分,模型收敛速度会变慢,但是最终效果可能更好.
2.2.3 词向量
在模型中出现的词向量一共有三组,输入层初始化的词向量C(w),权重矩阵W的行向量Wi以及权重矩阵U的行向量Ui.词向量C(w)有m维,每一维可以看作是单词的一个隐含特征,在Benjio[13]的实验中m取30或60.在n-gram模型中,使用独热编码后n-1个上下文单词所占的空间复杂度为O(|V|n),而分布式表示后空间复杂度仅有O(nm).向量Wi与Xu&Alex模型中伴随产生的词向量类似,不过其维度远小于词汇表大小.向量Ui与Wi出现情况类似,但其维度等于词汇表大小.Ci、Ui、Wi是三套独立的词向量,Ci是单词作为上下文输入单词时的词向量,Ui、Wi是单词作为目标单词时的词向量,通常讨论词向量时取词向量Ci.
2.3 LBL模型
对数双线性模型(Log-Bilinear Language Model,LBL)由Mnih和Hinton[14]于2007年提出,文中同时提出的还有FRBM和TFRBM模型,构造思路都源于受限玻尔兹曼机(Restricted Boltzmann Machine,RBM).基于RBM构建的语言模型中,上下文单词与目标单词同位于可视层,另一侧隐含层表示隐含特征,模型训练目的是计算出两层间的权重矩阵. FRBM在RBM基础上引入了分布式表示的初始化词向量.TFRBM在FRBM模型基础上,参考了文献[15]中的策略,提出可以将较大的上下文序列分成多个有重叠的小规模上下文并进行训练,在此基础上n可以取值较大而参数数量不会暴增.
FRBM和TFRBM能量函数描述词向量与隐藏层向量之间的相互作用,表面上上下文单词与目标单词需要通过隐藏层产生作用,实际上上下文单词与目标单词之间仍然是线性关系.LBL模型修改了隐藏层,用可视层中的目标单词词向量代替原有的隐藏层向量,这样直接描述了上下文词向量与目标词向量的相互作用.简而言之,LBL模型抽取了从上下文单词到目标单词的词向量之间的直接线性关系,构成了一个对数双线性模型.
2.3.1 模型描述
假设初始化词向量的维度是m,单词表大小为|V|,隐藏层维度是|H|.FRBM的能量函数为
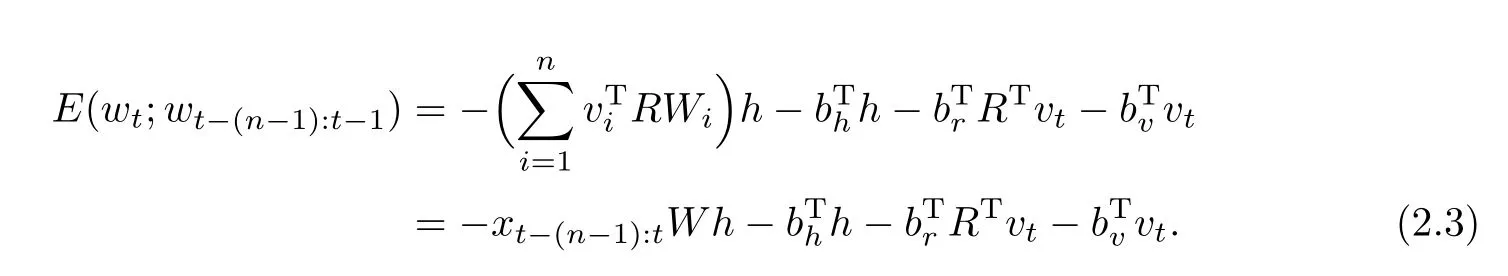
其中,vi是独热词向量,R是分布式表示词向量组成的矩阵,vTiR表示从R中提取第i个分布式词向量,形状是1×m,也可以级联成xt−(n−1):t,形状是1×nm;h是隐藏层向量,形状是|H|×1;W表示可视层与隐藏层之间的权重关系矩阵,形状是nm×|H|;bh、br、bt分别是角标对应位置的偏置项.
LBL用目标单词词向量代替隐藏层向量,能量函数为
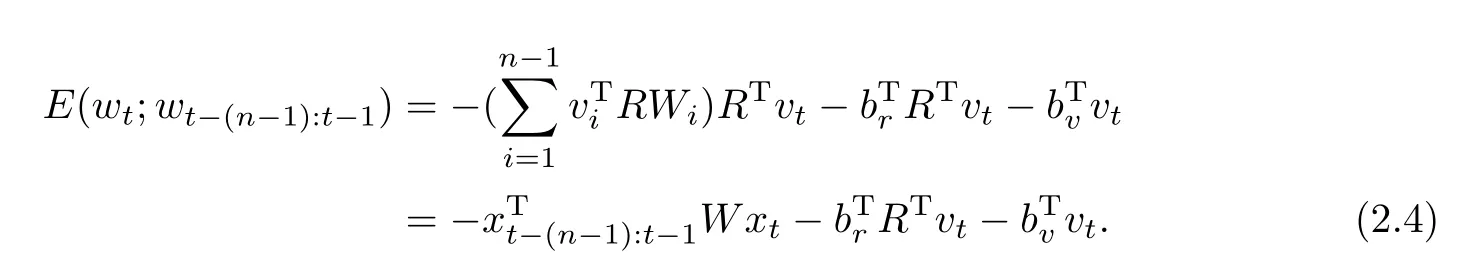
LBL中使用点积,即双线性结构计算上下文与目标单词词向量之间的关系,得到的其实是未对数归一化的概率.这种简单却有效的计算结构在之后的很多模型中被采用.
2.3.2 词向量
在其他模型中,往往对上下文单词与目标单词分别建模,并从产生的两组词向量中选用一组.LBL模型与其余模型最大区别之处在于该模型只产生了一组分布式词向量,即公式(2.3)和公式(2.4)中的矩阵R.
目标单词与上下文单词共用一套词向量是比较理想的思路,在神经网络语言模型中并不多见.但是,比较公式(2.3)和公式(2.4)可知,由于RBM模型中权重矩阵W的存在,目标单词词向量已经由矩阵W投影到了新的空间中,实际上构成了一组新的词向量,因此对LBL的进一步改进[16-17]中仍然采用了两套词向量.
2.4 RNNLM模型
大多数语言模型只能捕捉与目标单词相邻的有限个上下文单词对目标单词的影响,而距离较远的上下文则不在考虑范围内,这显然不符合真实的自然语言情境.在2.3.小节中提到的TFRBM模型虽然考虑到了上下文窗口不够大的问题,但并没有跳出使用单层神经网络的思维.
RNNLM[18-19]使用循环神经网络(Recurrent Neural Network,RNN)构建语言模型.与NPLM相比,RNNLM希望能够使用更完整的上下文预测目标单词,这符合人的阅读方式.设计与实现上,RNNLM需要在移动上下文窗口的同时,保留历史上下文的信息,并利用历史上下文与当前上下文共同预测目标单词.通常选用n层首尾相连的RNN循环单元(recurrent unit)来收集大小为n的上下文窗口中的信息,可以看作对样本收集方式进行的优化.RNNLM非常适合收集逻辑性强的文本信息,捕捉其中存在的单词共现或依赖关系.
RNN网络在训练长序列时可能出现的梯度消失或梯度弥散问题,即长时依赖(Long-Term Dependencies)问题[20].RNN的变式GRU-RNN(简称GRU)和LSTM-RNN[21](简称LSTM)可以解决梯度消失问题,而梯度弥散问题可以通过设置训练阈值来解决.LSTM将RNN模型细分为四个门:输入门(Input Gate)、新记忆门(New Memory Gate)、忘记门(Forget Gate)和输出门(Output Gate).Cho[22]提出可以对LSTM进行简化,将忘记门和输入门合并成更新门(Update Gate),并在文献[23]中将其总结为GRU模型.
2.4.1 模型描述
RNNLM与NPLM结构相似,除了输入层和输出层,也有一个隐藏层用来收集上下文信息,但是该隐藏层还需要存储信息并传递到下一次训练中.RNN中需要维护时间信息,用t表示,wt表示t时刻所取的目标单词.模型函数为

RNNLM的参数描述与NPLM基本一致:C(w)表示每个上下文单词的词向量,维度为m;xt形状也是m×1;ht表示以t为目标单词时上下文映射成的隐藏层向量,形状为|H|×1;权重矩阵H形状是|H|×m;权重矩阵U形状是|H|×|H|;权重矩阵W的形状是|V|×|H|.
LSTM模型函数为

其中,xt是输入单词词向量,形状是m×1;ht是当层计算得到的隐藏层词向量,形状是|H|×1;权重矩阵Wf、Wi、WC、Wo形状是|H|×m;权重矩阵Uf、Ui、UC、Uo形状是|H|×|H|;f、i、C、~C、o形状是|H|×1.符号“*”表示两个向量逐元素相乘(element-wise product).
2.4.2 模型分析
可变长上下文的最大问题是上下文向量的维度不同,RNN则不存在这个问题.公式(2.5)和(2.6)中ht代表目标单词为t时的隐藏层向量,其直接来源是历史上下文信息ht−1和当前上下文xt.理论上RNNLM可以保留任何长时信息,但实际上由于参数个数的有限,单纯的RNN甚至难以收敛[20].
基础RNN模型处理时序信息能力出众但存在缺陷,而LSTM学习到了RNN难以学到的长时依赖信息,已基本成为RNN的替代.不过LSTM以及其变式的复杂程度使其一直饱受争议,GRU在保留LSTM性能的前提下降低了复杂度.文献[24]讨论了tanh-RNN、LSTM与GRU的性能,发现tanh-RNN性能略差但训练速度快,LSTM和GRU则各有千秋.论文[25]进一步讨论了LSTM及其八种变式的性能优劣,发觉这些变式并没有本质上的性能提升,但另一方面,变式中对LSTM结构进行的一些简化也不会降低模型性能.论文[26]测试了一万种不同的RNN结构,最终找到三种相对最佳的结构:MUT1、MUT2、MUT3,他们的结构类似GRU.
2.4.3 词向量
RNNLM模型训练方式与NPLM模型类似,其伴随词向量产生过程也类似于NPLM. RNNLM模型产生的词向量有两组,一组是上下文词向量,另一组蕴含在模型输出层权重矩阵中,是目标单词的词向量.
2.5 CBOW&skip-gram模型
CBOW(Continuous Bag-of-Words)和skip-gram模型同出自Mikolov的论文[27],同时也是Google著名的开源项目Word2Vec的理论基础.两个模型的任务分别是根据上下文预测目标单词,和根据目标单词预测上下文,是专门用来训练分布式词向量的模型.CBOW模型的结构类似于NPLM,而skip-gram可以认为在CBOW基础上反转了整个模型数据流动方向.这两个模型的核心思想是减少对上下文词序的关注来提高训练速度和词向量性能.
早期设计的NPLM中,隐藏层将输入层的所有上下文词向量级联.级联连接可以保留全部信息,但会导致隐藏层的维度很大,从而导致待训练权重参数过多.CBOW对目标单词的上下文词向量逐维度求均值,得到的向量作为隐藏层向量,并在梯度反馈时将梯度增量分配给每个上下文词向量进行更新.通常把这样不保留任何词序信息,窗口内每一个上下文单词权重相同的上下文称为词袋(Bag-of-Words),CBOW的命名也由此而来.CBOW可能会牺牲部分词序信息,但对生成词向量的影响不会太大,且可以大大减少待训练参数.
skip-gram取CBOW中目标单词作为上下文单词,而CBOW中的上下文词袋作为skipgram中的预测目标,因此上下文单词只有1个,而目标单词个数为n-1,上下文单词与目标单词组成n-1组一对一的<上下文单词,目标单词>对.相比CBOW,skip-gram训练得到的词向量效果更好.
3 多分类问题
多分类问题描述为:已知一组训练样本(xi,Ti),其中xi是已知信息,Ti是希望预估的分类种类,分类的种类和总量固定且已知,最终希望学习出其中的分类规则.对应到NLP领域中可以转化为“已知上下文单词,希望从词汇表找出最有可能的目标单词”的问题.
对于这类问题,如果要求给出对每个单词是否是目标单词的预测概率,以便从中选择top-N项单词时,需要使用softmax函数和交叉熵损失函数,其时间复杂度通常是O(|V|),复杂度主要集中在归一化项上.这类方案使用范围较广,优化方案也很多,大致可以分为两类:非采样方法,如分层softmax可以将复杂度降到O(log|V|);基于采样的方法,也称为候选人采样(Candidate Sampling).
如果只需要给出预测的目标单词,则可以使用多分类SVM(Multiclass Support Vector Machine)损失函数代替交叉熵损失函数.多分类SVM只能给出对候选词的打分,无法给出概率信息.但另一方面多分类SVM避免了归一化需要的大量计算,降低了复杂度.
3.1 分层softmax
语言模型中softmax函数形式为

其中,函数g(wv,wt−1…,wt−n+1)表示以n-gram序列wv,wt−1…,wt−n+1为输入的能量函数.由公式(3.1)可知,softmax函数需要计算以词汇表中所有单词为目标单词时的能量函数之和,时间复杂度为O(|V|).
为了降低复杂度,Morin和Bengio提出了分层softmax(Hierarchical Softmax,HS)[28],并构建了一个基于HS的NPLM模型.该想法来源于Goodman的工作[29],利用二叉分类树结构,树的每一个叶结点代表一个单词,可以将一个|V|分类问题优化成log|V|次二分类问题,有效地降低了复杂度.
Morin最初构建的二叉分类树是基于WordNet[30]的带有一定语义信息的分类树.文献[31]进一步讨论了单词分类树的几种构建方法,该文构建了基于HS的LBL模型——HLBL,同时提出可以在模型构建过程中训练携带分布式语义的二叉分类树.文献[32]对HS的构建进一步优化,提出了一种在输出层对单词聚类的分层方法——SOUL NNLP模型.文献[33]则用HS对RNN模型的输出层进行了优化,并改用根据单词出现频率构造了分类树.文献[27]在[33]的基础上进一步改进,采用基于Huf f man树的HS优化,并且效果不错.
3.2 C&W模型
最早采用负样本训练分布式词向量可以追溯到C&W模型[34-35],也是第一次为训练分布式词向量单独构建神经网络.除了使用负样本,C&W模型使用多分类SVM损失函数代替了softmax概率归一化函数和交叉熵损失函数,只计算得分不统计概率,这也是其能够加速的原因之一.
C&W模型以其提出者Collobert和Weston命名,其初衷是构建一个可以解决多个NLP问题的通用神经网络语言模型,本文不展开介绍.C&W模型将训练词向量看成一个二分类问题,输入包括正样本(positive example)、负样本(negative example),正样本指真实存在的自然语言样本,负样本指随机更改正样本得到的非自然语言样本.神经网络语言模型负责区分两类样本,这需要在损失函数中激励正样本、抑制负样本.这样做的优点是可以达到利用更少采样样本更快完成训练.C&W模型没有抽取部分负样本,而是使用单词表中除目标单词外的全部单词代替目标单词来构建负样本.
C&W使用的是多分类SVM模型,需要最小化的损失函数是

其中,s(x)=W tanh(H x+b)+d;x是长度为n的单词序列,通常取目标单词前后各(n-1)/2个单词作为上下文;S指上下文窗口集合;w指单词;D指单词集合;x(w)指使用D中的任意单词w代替x中的目标单词,得到的随机负样本;s(x)是以单词序列x为输入的能量函数,代表对样本是否为真进行的打分.权重矩阵H的形状是|H|×nm;权重矩阵W的形状是1×|H|.该损失函数希望对正类的打分比对其他负类的打分至少高1分.
3.3 噪声比对估计采样
噪声比对估计采样(Noise Contrastive Estimation,NCE)由Gutmann[36]在2010年提出,用来训练未归一化的概率模型(unnormalized probability model)[37],Mnih在文献[38]中用其优化神经网络语言模型.类似于C&W中给出的方法,NCE的损失函数中包括对正样本的激励和对负样本的抑制,但NCE优化的对象是softmax函数.NCE的思路来自重要性采样(Important Sampling)[39],使用了采样的方法来估算softmax函数的标准化项,降低了计算复杂度.当采样样本足够多时,NCE采样结果接近softmax归一化结果,当采样样本数等于全部负样本数时,计算结果及时间复杂度就完全等同于softmax归一化.
NCE需要最小化的损失函数是

其中,

x是长度为n的单词序列,包括(n-1)个上下文单词和一个目标单词;vx是x中上下文单词向量级联得到的输入向量,形状是1×(n-1)m;x(wi)指使用采样到的单词wi代替窗口x中的正确目标单词后,得到的随机负样本n-gram窗口;k表示对每一个正样本需要采集k个负样本;类似C&W模型,P(y=1|x)是正确判断正样本为真的概率,P(y=0|x(wi))是正确判断负样本为假的概率,两者都需要最大化.另外,对P(y=1|x)中正则化项的计算采用的是其近似解,有关讨论可以参考文献[40]和[41].
从神经网络结构的角度分析,NCE模型修改自NPLM模型,但其核心的对数双线性函数的构造思路却是来自LBL模型.NCE中得到的词向量有两组,vx是对上下文单词的词向量级联而成的向量,是与vx构成对数双线性结构的目标单词词向量,形状与级联后的vx一样.
论文[42]介绍的负采样(Negative Sampling,NEG)技术可以看作对NCE的优化,用sigmoid函数代替了NCE采样中判断样本真假的函数.NEG损失函数是对NCE损失函数的近似估计,但不会影响模型效果和分布式词向量的效果.损失函数改写为

3.4 其他
除以上介绍的方案外还有许多对分类问题进行优化的方案.对softmax的优化中,Chen提出差分softmax(dif f erentiated softmax)[43],可以为不同出现频率的单词分配不同个数的参数.除了重要性采样、噪声比对估计采样和负采样这三种候选人采样方法外,Devlin提出了自标准化方法(Self-Normalisation)[44],令标准化项取常数1,并增加了惩罚项,该方法可以不用进行负采样,效果相当且速度更快.Andreas在文献[44]基础上进一步提出了低频标准化方法(Infrequent Normalisation)[45],对正样本同样进行了采样.
4 利用辅助结构优化训练词向量
分布式词向量伴随神经网络语言模型产生,对神经网络结构的优化使得模型能够更加准确地拟合自然语言单词的分布,不仅减少了神经网络的训练时间,也优化了神经网络中的分布式词向量.在讨论神经网络语言模型中词向量的优劣时,提取的通常是输入层的词向量,而在某些场景中可能只需要用到分布式词向量,对神经网络语言模型的效果并不关心.
2008年,Collobert和Weston提出的C&W模型中首次出现了以训练分布式词向量为目的的独立的神经网络模型.2009年,Mikolov再次提到可以将词向量与语言模型分开建模[46].此后,对词向量模型的优化改进以及专门针对词向量提出的任务开始逐渐增多.
神经网络语言模型与其伴随词向量的性能并不严格正相关.抛开对语言模型的优化,单单考虑如何提高词向量语义的准确性,既需要考虑目标语言的构词特点,又要考虑词向量的具体使用环境.对于前者,不同语系的语言构词方法虽然不同,但可以互相借鉴;而对于后者,需要考虑选取不同的上下文来适应具体环境.总结常见的方法有两类:一类是修改神经网络结构,利用附加信息联合训练,包括单词短语联合训练、词缀单词联合训练,以及根据各自语种对词向量进行特别优化等等;另一类方法是为了解决一词多义或词义消歧问题,对词向量的形式进行一定修改,比如为多义词的每个含义分别分配词向量.本节会分别介绍这两类方法.
4.1 联合训练
联合训练是最常见的优化手段通常来说指在训练语言模型时利用多种类型的信息强化训练效果.联合训练利用了神经网络自动调节各输入单元权重的优点,通常优化效果不错.可以在联合训练中使用的信息包括:单词(word),是词向量训练的最基础元素;短语(phrase),尤其是对于固定搭配短语,其语义与构成它的单词可能没有直接联系,比如舶来语,需要将这些短语当作单词共同训练;字母(character),是构成单词的基本元素,字母本身不携带语义,但字母构成的子词(subword)可能提供时态信息、情感信息等等,称为词缀;全局上下文信息,指比共现上下文范围更大的文本,或是从中提取的先验知识;其他单词信息,例如单词词性、单词情感程度等等.
单词短语联合训练构建方法简单,效果也最明显.这是因为英语环境中大量存在固定短语,且与构成短语的单词词义无关,可以很直观地将这些短语当作不可再分的“单词”. Mikolov在文献[42]中讨论并给出了联合训练方案.
单词字母联合训练神经网络的构造较为复杂,往往会根据具体任务设计模型.文献[47]构建了单词字母联合训练的深度卷积神经网络,为每个字母、每个单词都设置了分布式向量,希望可以解决涉及单词构词信息的任务,如词性标注(POS),而对字母使用卷积神经网络可以找到并利用字母构成的子词.文献[48]希望构词形态相似的词可以拥有相似的词向量表达,并依此构建网络.文献[49]使用了字母级别的n-gram模型,提取单词中的n-gram子词,并对子词向量求和,得到另一个可用于联合训练的词向量.中文方面,由于中文中构成词的字拥有更丰富且独立的语义信息,因此字词联合训练对中文词向量来说是极好的处理方案[9].此外,文献[50]使用偏旁部首作为中文汉字辅助训练的对象.
用RNNLM可以在一定程度上获取长时信息,但难以获取更加宏观的信息,单词全局信息联合训练可以弥补这点.文献[49]以用词袋模型收集的全文本词汇信息作为输入,构建了神经网络.文献[51]和[52]用先验知识构建了单词之间的关系模型,再与语言模型联合训练.
4.2 词向量变式
多义词表达的独立词义不止一个,为每个单词分配同样维度的词向量实际上是不公平的.作为改进,为每个单词的每种词义分别构建词向量是解决多义词问题的很好思路, Reisinger首先提及这点[53].为多义词构建多个词向量的理论基础同样是分布表示,区分单词的词义需要基于上下文进行聚类,聚类对象和聚类方法的选择是关键,文献[9]和[54]依此继承并进行了发展.
分布式词向量可以表示为多维空间中的一个点,而具有多个词向量的单词在空间上表示为数个点的集合,也可以看作在一个椭球分布上采集的数个样本.文献[55]基于该思想提出可以使用高斯分布代表单词,优点有:高斯分布可以直观地表示不同的单词携带的信息量可能不同的特点;使用概率分布表示单词后,可以用KL散度计算单词语义上的包含或依赖等不对称关系.
5 评测任务与模型比对
从整体上说,影响神经网络分布式词向量效果的主要因素包括上下文、目标单词的选择以及神经网络语言模型的构建.同时,不同神经网络语言模型复杂度不同,训练时间差距很大.早期,对词向量的认识停留于使用词向量可以提高神经网络语言模型效果,因此常用神经网络语言模型的评判指标来展示词向量的优劣.这类指标通过关注词向量对复杂NLP任务的贡献,从而间接地考察词向量.这种评价方式固然有效,但对更细粒度的单词对象关注较少,难以考察单词携带语义的准确度,因此需要使用面向单词的评判任务.
常见的面向单词的评判任务有两种:相似度(Similarity)任务和类推(Analogy)任务.相似度任务用词向量之间的向量距离来表示两个单词之间的关系紧密程度,并与人为判断的单词关系进行对比,与人为判断结果越接近说明词向量携带的语义越准确,这类任务有SimLex-999[56]、WordSim-353[57]等等.类推任务的形式为“a is to a*as b is to b*”,一般给定单词a、a*、b,求单词b*,评分指标为利用模型类推命中的单词占总测试单词数量的百分比,这类任务有MSR[58]、Google[27]、BATS[59]等等.Mikolov则在文献[42]和[60]中描述了如何用词向量间简单的加减运算完成类推任务,形如“King-Man+Woman=Queen”,也称为利用词向量间的线性偏移完成类推任务.
不同词向量模型处理不同问题的效果略有区别,这里选择了skip-gram、RNN、C&W三个模型进行比对.这三个模型性能都较优且比较经典,模型中的词向量可以独立完成面向单词的评判任务,同时也可以嵌入在其他模型中完成复杂NLP任务.表1分析了三个模型的优缺点.
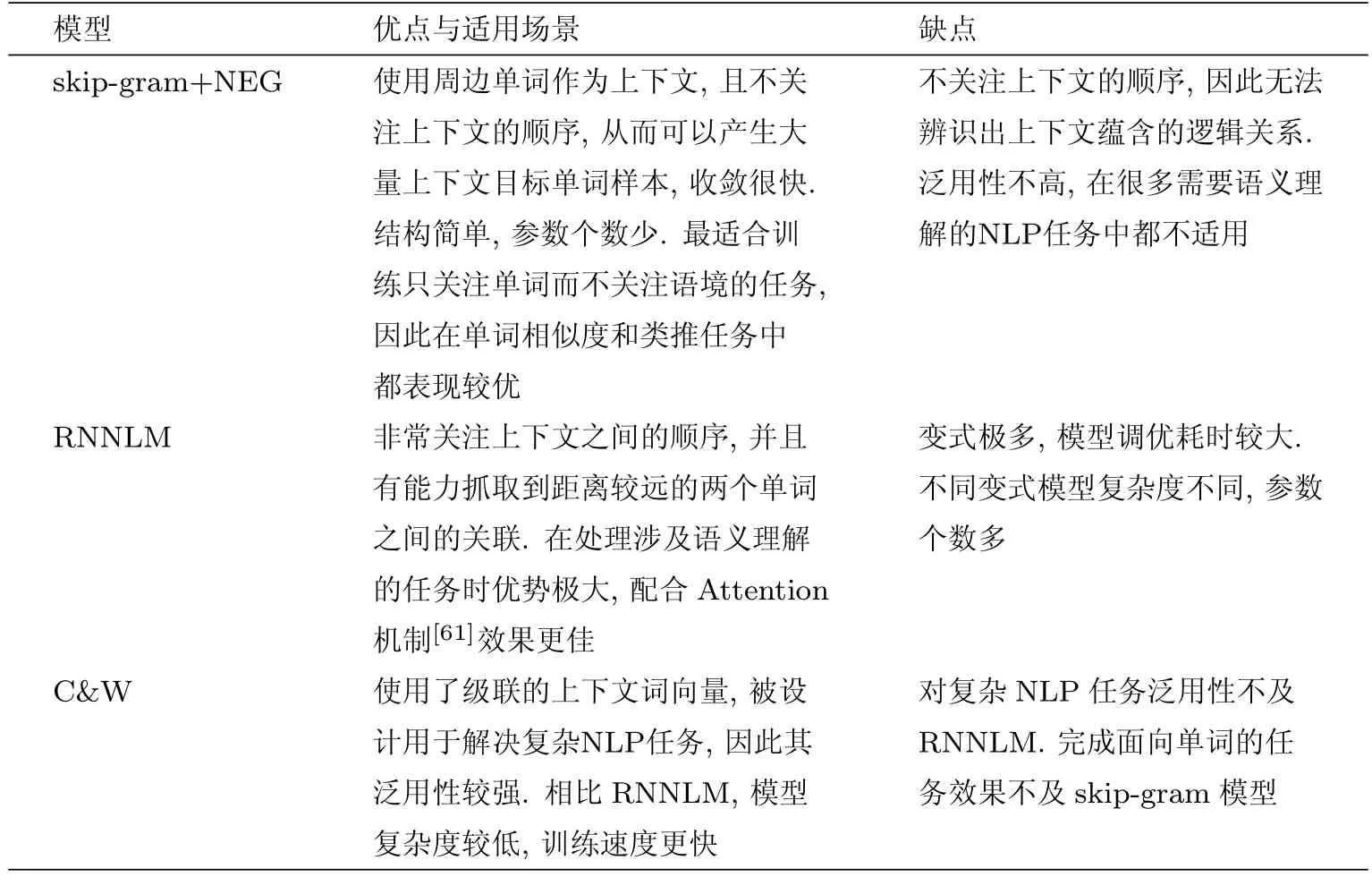
表1 模型优缺点比对表Tab.1 Comparison of the advantages and disadvantages of models
6 总结与展望
本文从三个方面介绍了基于神经网络语言模型的分布式词向量的研究进展.分布式词向量不仅可以完成相似度计算、类推任务等传统自然语言任务,还在机器翻译、问答系统等复杂的系统型NLP任务中表现不俗.如今,对神经网络语言模型结构的研究已经比较成熟,近年来对词向量的研究大都集中在使用多种神经网络混合模型生成词向量的设计上,其中利用门结构来综合多种模型成为最近两年词向量的研究热点.另外,分布式表示(embedding)将单词的上下文共现关系表示成了词向量,可以推广为将任一稠密连通图中的点转换为向量.这种策略已经在点击率预测[62]等领域进行了推广,并有可能成为未来的研究热点.
[1]HARRIS Z S.Distributional structure[J].Word,1954,10(2/3):146-162.
[2]FIRTH J R.A synopsis of linguistic theory,1930-1955[J].Studies in linguistic analysis,1957(S):1-31
[3]来斯惟.基于神经网络的词和文档语义向量表示方法研究[D].北京:中国科学院大学,2016.
[4]TURIAN J,RATINOV L,BENGIO Y.Word representations:a simple and general method for semi-supervised learning[C]//ACL 2010,Proceedings of the Meeting of the Association for Computational Linguistics,July 11-16,2010,Uppsala,Sweden.DBLP,2010:384-394.
[5]DEERWESTER S,DUMAIS S T,FURNAS G W,et al.Indexing by latent semantic analysis[J].Journal of the American Society for Information Science,1990,41(6):391.
[6]PENNINGTON J,SOCHER R,MANNING C.Glove:Global vectors for word representation[C]//Conference on Empirical Methods in Natural Language Processing,2014:1532-1543.
[7]BROWN P F,DESOUZA P V,MERCER R L,et al.Class-based n-gram models of natural language[J].Computational linguistics,1992,18(4):467-479.
[8]GUO J,CHE W,WANG H,et al.Revisiting embedding features for simple semi-supervised learning[C]// Conference on Empirical Methods in Natural Language Processing,2014:110-120.
[9]CHEN X,XU L,LIU Z,et al.Joint learning of character and word embeddings[C]//International Conference on Artif i cial Intelligence.AAAI Press,2015:1236-1242.
[10]HINTON G E.Learning distributed representations of concepts[C]//Proceedings of the Eighth Annual Conference of the Cognitive Science Society,1986:12.
[11]MIIKKULAINEN R,DYER M G.Natural language processing with modular neural networks and distributed lexicon[C]//Cognitive Science,1991:343-399.
[12]ALEXRUDNICKY.Can artif i cial neural networks learn language models?[C]//International Conference on Spoken Language Processing.DBLP,2000:202-205.
[13]BENGIO Y,DUCHARME R,VINCENT P,et al.A neural probabilistic language model[J].Journal of Machine Learning Research,2003,3(6):1137-1155.
[14]MNIH A,HINTON G.Three new graphical models for statistical language modelling[C]//Machine Learning, Proceedings of the Twenty-Fourth International Conference.DBLP,2007:641-648.
[15]SUTSKEVER I,HINTON G E.Learning multilevel distributed representations for high-dimensional sequences[J]. Journal of Machine Learning Research,2007(2):548-555.
[16]MNIH A,HINTON G.A scalable hierarchical distributed language model[C]//Conference on Neural Information Processing Systems,Vancouver,British Columbia,Canada,December.DBLP,2008:1081-1088.
[17]MNIH A,KAVUKCUOGLU K.Learning word embeddings effi ciently with noise-contrastive estimation[C]// Advances in Neural Information Processing Systems,2013:2265-2273.
[18]MIKOLOV T,KARAFI´AT M,BURGET L,et al.Recurrent neural network based language model[C]//INTERSPEECH 2010,Conference of the International Speech Communication Association,Makuhari,Chiba,Japan, September.DBLP,2010:1045-1048.
[19]MIKOLOV T,KOMBRINK S,DEORAS A,et al.Rnnlm-recurrent neural network language modeling toolkit[C]//Processingof the 2011 ASRU Workshop,2011:196-201.
[20]BENGIO Y,SIMARD P,FRASCONI P.Learning long-term dependencies with gradient descent is diffi cult[J]. IEEE Transactions on Neural Networks,2002,5(2):157-166.
[21]HOCHREITER S,SCHMIDHUBER J.Long short-term memory[J].Neural computation,1997,9(8):1735-1780.
[22]CHO K,VAN MERRIENBOER B,GULCEHRE C,et al.Learning phrase representations using RNN encoderdecoder for statistical machine translation[C]//Empirical Methods in Natural Language Processing,2014:1724-1734.
[23]CHO K,VAN MERRI¨ENBOER B,BAHDANAU D,et al.On the properties of neural machine translation: Encoder-decoder approaches[J].ArXiv preprint arXiv:1409.1259,2014.
[24]CHUNG J,GULCEHRE C,CHO K H,et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[J].ArXiv preprint arXiv:1412.3555,2014.
[25]GREFF K,SRIVASTAVA R K,KOUTN´IK J,et al.LSTM:A search space odyssey[J].IEEE Transactions on Neural Networks&Learning Systems,2015(99):1-11.
[26]JOZEFOWICZ R,ZAREMBA W,SUTSKEVER I,et al.An empirical exploration of recurrent network architectures[C]//International Conference on Machine Learning,2015:2342-2350.
[27]MIKOLOV T,CHEN K,CORRADO G,et al.Effi cient estimation of word representations in vector space[J]. ArXiv preprint arXiv:1301.3781,2013.
[28]MORIN F,BENGIO Y.Hierarchical probabilistic neural network language model[C]//Aistats,2005:246-252.
[29]GOODMAN J.Classes for fast maximum entropy training[C]//IEEE International Conference on Acoustics, Speech,and Signal Processing.IEEE,2001:561-564.
[30]FELLBAUM C,MILLER G.WordNet:An Electronic Lexical Database[M].Cambridge,MA:MIT Press,1998.
[31]MNIH A,HINTON G.A scalable hierarchical distributed language model[C]//International Conference on Neural Information Processing Systems.Curran Associates Inc,2008:1081-1088.
[32]LE H S,OPARIN I,ALLAUZEN A,et al.Structured Output Layer neural network language model[C]//IEEE International Conference on Acoustics,Speech and Signal Processing.IEEE,2011:5524-5527.
[33]MIKOLOV T,KOMBRINK S,BURGET L,et al.Extensions of recurrent neural network language model[C]// IEEE International Conference on Acoustics,Speech and Signal Processing.IEEE,2011:5528-5531.
[34]COLLOBERT R,WESTON J.A unif i ed architecture for natural language processing:Deep neural networks with multitask learning[C]//International Conference.DBLP,2008:160-167.
[35]COLLOBERT R,WESTON J,BOTTOU L,et al.Natural Language processing(almost)from scratch[J].Journal of Machine Learning Research,2011,12(1):2493-2537.
[36]GUTMANN M,HYV¨ARINEN A.Noise-contrastive estimation:A new estimation principle for unnormalized statistical models[J].Journal of Machine Learning Research,2010(9):297-304.
[37]GUTMANN M U,HYVARINEN A.Noise-contrastive estimation of unnormalized statistical models,with applications to natural image statistics[J].Journal of Machine Learning Research,2012,13(1):307-361.
[38]MNIH A,TEH Y W.A fast and simple algorithm for training neural probabilistic language models[C]//International Conference on Machine Learning,2012:1751-1758.
[39]BENGIO Y,SEN´ECAL J S.Quick Training of Probabilistic Neural Nets by Importance Sampling[C]//AISTATS, 2003:1-9.
[40]ZOPH B,VASWANI A,MAY J,et al.Simple,Fast Noise-Contrastive Estimation for Large RNN Vocabularies[C]//Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2016:1217-1222.
[41]DYER C.Notes on noise contrastive estimation and negative sampling[J].ArXiv preprint arXiv:1410.8251, 2014.
[42]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed Representations of Words and Phrases and their Compositionality[J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[43]CHEN W,GRANGIER D,AULI M,et al.Strategies for training large vocabulary neural language models[C]// Meeting of the Association for Computational Linguistics,2015:1975-1985.
[44]DEVLIN J,ZBIB R,HUANG Z,et al.Fast and robust neural network joint models for statistical machine translation[C]//Meeting of the Association for Computational Linguistics,2014:1370-1380.
[45]ANDREAS J,DAN K.When and why are log-linear models self-normalizing?[C]//Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2015:244-249.
[46]MIKOLOV T,KOPECKY J,BURGET L,et al.Neural network based language models for highly inf l ective languages[C]//IEEE International Conference on Acoustics,Speech and Signal Processing.IEEE,2009:4725-4728.
[47]SANTOS C D,ZADROZNY B.Learning character-level representations for part-of-speech tagging[C]//Proceedings of the 31st International Conference on Machine Learning(ICML-14),2014:1818-1826.
[48]COTTERELL R,SCH¨UTZE H.Morphological word-embeddings[C]//Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2015:1287-1292.
[49]BOJANOWSKI P,GRAVE E,JOULIN A,et al.Enriching word vectors with subword information[J].ArXiv preprint arXiv:1607.04606,2016.
[50]LI Y,LI W,SUN F,et al.Component-enhanced Chinese character embeddings[C]//Empirical Methods in Natural Language Processing,2015:829-834.
[51]YU M,DREDZE M.Improving lexical embeddings with semantic knowledge[C]//Meeting of the Association for Computational Linguistics,2014:545-550.
[52]WANG Z,ZHANG J,FENG J,et al.Knowledge graph and text jointly embedding[C]//Conference on Empirical Methods in Natural Language Processing,2014:1591-1601.
[53]REISINGER J,MOONEY R J.Multi-prototype vector-space models of word meaning[C]//Human Language Technologies:The 2010 Conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2010:109-117.
[54]HUANG E H,SOCHER R,MANNING C D,et al.Improving word representations via global context and multiple word prototypes[C]//Meeting of the Association for Computational Linguistics:Long Papers.Association for Computational Linguistics,2012:873-882.
[55]VILNIS L,MCCALLUM A.Word representations via gaussian embedding[R].University of Massachusetts Amherst,2014.
[56]HILL F,REICHART R,KORHONEN A,et al.Simlex-999:Evaluating semantic models with genuine similarity estimation[J].Computational Linguistics,2015,41(4):665-695.
[57]FINKELSTEIN R L.Placing search in context:the concept revisited[J].Acm Transactions on Information Systems,2002,20(1):116-131.
[58]ZWEIG G,BURGES C J C.The Microsoft Research sentence completion challenge[R].Technical Report MSRTR-2011-129,Microsoft,2011.
[59]GLADKOVA A,DROZD A,MATSUOKA S.Analogy-based detection of morphological and semantic relations with word embeddings:what works and what doesn’t[C]//HLT-NAACL,2016:8-15.
[60]MIKOLOV T,YIH W,ZWEIG G.Linguistic regularities in continuous space word representations[C]//HLTNAACL,2013:746-751.
[61]BAHDANAU D,CHO K,BENGIO Y.Neural machine translation by jointly learning to align and translate[C]//ICLR,2015:1-15.
[62]GROVER A,LESKOVEC J.Node2vec:Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:855-864.
(责任编辑:李万会)
Survey on distributed word embeddings based on neural network language models
YU Ke-ren,FU Yun-bin,DONG Qi-wen
(School of Data Science and Engineering,East China Normal University, Shanghai 200062,China)
Distributed word embedding is one of the most important research topics in the f i eld of Natural Language Processing,whose core idea is using lower dimensional vectors to represent words in text.There are many ways to generate such vectors,among which the methods based on neural network language models perform best.And the respective case is Word2vec,which is an open source tool developed by Google inc.in 2012.Distributed word embeddings can be used to solve many Natural Language Processing tasks such as text clusting,named entity tagging,part of speech analysing and so on.Distributed word embeddings rely heavily on the performance of the neural network language model it based on and the specif i c task it processes.This paper gives an overview of the distributed word embeddings based on neural network and can be summarized from three aspects,including the construction of classical neural network language models,the optimization method formulti-classification problem in language model,and how to use auxiliary structure to train word embeddings.
word embedding;language model;neural network
TP391
A
10.3969/j.issn.1000-5641.2017.05.006
1000-5641(2017)05-0052-14
2017-05-01
国家重点研发计划(2016YFB1000905);国家自然科学基金广东省联合重点项目(U1401256);国家自然科学基金(61672234,61402177);华东师范大学信息化软课题
郁可人,男,硕士研究生,研究方向为自然语言处理.E-mail:yu void@qq.com.
傅云斌,男,博士后,研究方向为数据科学与机器学习.E-mail:fuyunbin2012@163.com.
