基于投影模式支持集的数据挖掘算法研究
2017-08-12杨晓波
杨 晓 波
(浙江财经大学东方学院 浙江 杭州 314408)
基于投影模式支持集的数据挖掘算法研究
杨 晓 波
(浙江财经大学东方学院 浙江 杭州 314408)
为了进一步提高频繁模式数据挖掘算法的效率,提出一种基于投影模式支持集的数据挖掘算法。具体研究过程为:首先分析两种类型模式支持集的数据处理过程,接着研究投影模式的基本策略和实现算法,最后采用对比实验来验证投影模式数据挖掘算法的可行性。研究结果表明:该算法在支持率阈值低于0.1%时,系统处理性能高出其他类型的数据挖掘算法2倍以上,为高效的数据挖掘奠定了理论基础。
投影模式 基本策略 算法分析 数据挖掘
0 引 言
数据挖掘过程中经常采用频繁模式挖掘算法,该算法可以解决数据挖掘的常见问题,因而获得较广泛应用[1-5]。随着应用的逐渐深入以及海量数据库的出现,频繁模式挖掘算法也暴露出一些弊端,如处理长模式的密集型数据库时,挖掘效率较低;处理大型稀疏型数据库时,误差较大;对于密集型数据库的投影与计数操作效率低于基于树型的方法。本文将提出一种基于投影模式支持集的数据挖掘算法,以期解决频繁模式挖掘算法中存在的主要问题。
1 模式支持集的类型与处理过程
模式支持集(简称:PSS)主要用于表示投影事务子集,PSS的投影规则直接影响算法的时间开销。下面通过分析两种类型的PSS,即稀疏型PSS和密集型PSS,研究事务数据的处理过程。
1.1 稀疏型PSS
稀疏型PSS是以数组为基础,通常由局部模式列表(LPL)、块队列(BQ)和数组(Array)组成。其中局部模式列表(LPL)包含三个域,分别为块指针、项目、计数器,块指针将事务与块队列BQ相连,项目根据指定顺序排列,每个事务存放于对应的数组之中,这种基于事务集的稀疏型PSS拓扑结构如图1所示。

图1 事务子集的稀疏型PSS
从图1可知,项目a通过块队列BQ(a)连接事务01、03和05,事务01的模式列表为{a,c,f,m,p},数组中只保留后四项,即{c,f,m,p}。稀疏型PSS的投影过程为:首先,选取LPL中的第一个条目为当前条目,如项目a通过块队列BQ(a)将第一个子节点(a.3)的事务联系起来。然后,通过当前BQ中的事务向下一个BQ转移,如事务01向事务03转移,以此类推,一个事务通过项目子节点与下一个项目产生关联,直到转移到合适的BQ为止。
1.2 密集型PSS
密集型PSS以树结构为基础,它是一种不同于递归构造条件的方法[6-7]。
基于树结构的密集型PSS包含两部分内容,分别为项目列表(PL)和事务数组(BA)。密集型PSS为每个PL条目设置三个参数,分别为项目、计数器和块指针,分别记作item、count和pointer,各条目按照指定的项目次序排列,并利用唯一的路径表示每个事务。每个BA节点采用(i,n)表示,i表示项目,n表示从根节点到该节点路径所访问事务的数目。PL条目应与路径上项目的排列顺序相一致,通过PL条目可以将相同项目的所有节点链接起来,以便于查询,密集型PPS的拓扑结构如图2所示。

图2 树结构的密集型PSS结构图
从图2可知,密集型PSS通过树结构路径来表示事务,如路径(a,2)-(c,2)-(f,2)-(m,1)-(p,1)表示事务01和05,事务2则通过路径(a,2)-(b,2)-(c,3)-(f,1)-(m,2)来表示,项目列表PL的第四个条目的项目为f,通过块指针(虚线箭头)将节点(f,2)、(f,1)和(f,3)联系在一起。
2 投影模式策略及其算法
为了获得最优的时间效率和空间利用率,数据挖掘算法必须使模式生成树的生成和搜索策略、PSS表示方法和投影方法等适应于数据特性,下面分析投影模式的策略及其相关算法。
2.1 投影模式的基本策略
由于在实际应用中数据库规模存在差异,事务数据不能简单地划分为稀疏型或密集型,因此,投影模式的基本策略需兼顾时间效率和空间利用率两方面。
策略1 对于超大型数据库,模式生成树的上半部可以采用宽度优先算法来构建,当所有各层节点都能利用内存表示时,选用深度优先算法构建模式生成树的下半部。
策略2 在模式生成树的高层,采用稀疏型PSS,在模式生成树的中下层,则可采用密集型PSS。
策略3 当使用稀疏型投影模式时,父节点需要有足够的自由内存与子节点建立对应关系;当采用基于树结构密集型投影模式时,首先需界定虚拟子节点的树型结构,如果密集型PSS收缩较快,则需建立过滤型的拷贝。
2.2 投影模式算法
以投影模式的基本策略为基础,本文提出一种融合深度优先与宽度优先的投影模式算法(PMA),该PMA算法基于数组与树状结构,由宽度优先过程和具有向导的深度优先过程组成[8]。
2.2.1 宽度优先投影算法
宽度优先投影算法是以内存作为参数,控制整个递归过程,通过3个步骤创建模式生成树的上半部。
步骤1 为当前层k的每个节点v设计一个向量计数器,用于累计每个节点在PSS中项目的支持数,每个按规定次序排列的子节点,其标注项目在向量计数器中都有唯一的对应向量。
步骤2 将事务t沿根节点路径向第k层节点投影,每投影一次,就将向量计数并累加。如果事务t能够投影至第k层节点并使该节点的向量增值,则t还可以向k+1层节点投影,并将t增加至D,否则,事务数将逐层减少。
步骤3 为每个节点v创建其子节点。当v的值超过支持率阈值的计数分量,则相应地有一个v的子节点,反之,则v没有子节点,可以被删除,如果v是其父节点的唯一子节点,则v的父节点也可被删除。
2.2.2 向导式深度优先算法
假设节点在第k层结束,那么,只有长度为k的路径保存在模式生成树中,模式生成树的第k层以下将按照向导式深度优先算法来构造,实现步骤如下:
步骤1 首先扫描数据库,确定支持节点P及其事务集Dp,并获得Dp的LPL。如果数据库信息以磁盘或稀疏型PSS形式表示,则创建相应的LPL;如果数据库以树状密集型PSS形式表示,则LPL已经保存在父亲列表中。
步骤2 如果数据库以稀疏型PSS形式表示,并且事务集Dp的密度估计值超过设定阈值,则为Dp创建树状密集型PSS表达形式,否则为Dp创建稀疏型PSS表达形式。如果数据库以密集型PSS形式表示,则为Dp创建虚拟的密集型PSS,如果Dp规模远小于事务数据库,则需要为Dp建立过渡型拷贝。
步骤3 为每个事务节点创建与其项目相同的子节点,如果节点所在层次大于设定值,则在此时创建子节点;反之,节点由项目初期创建,如果遍历整个事务数据库检索不到子节点,则表明子节点在模式生成树的分枝最大长度小于设定值,可以不必创建。
向导式深度优先策略在执行效率方面优于无向导的深度优先策略,因为前者可避免重复创建终止于模式生成树上半部分的路径。
2.2.3 PMA算法
PMA算法是融合了宽度优先与深度优先的投影模式算法,该算法结合了宽度优先算法和深度优先算法的优点,是一种比前两种算法计算复杂度更低的算法,因而更有利于实际应用。PMA算法的实现步骤如下:
步骤1 利用搜索树的图论特点,任意一个节点只通过其父节点与其他非子节点发生联系,将父节点与其他节点分隔开,其后代节点便形成独立的区域。
步骤2 将搜索树分成左右相等的两部分,左半部分执行深度优先算法,右半部分执行宽度优先算法,两部分算法可同时进行。
步骤3 为了降低计算复杂度,首先执行深度优先算法,接着执行宽度优先算法,深度优先算法获得的结果可用于宽度优先算法之中。
3 对比实验及性能评价
为了验证投影模式算法的有效性,本文采用对比实验,将投影模式算法与Apriori[9]、FP-Growth[10]和H-Mine[6]算法的效率和有效性进行对比分析,实验数据采用大数据集,实验环境为:2 GHz的Pentium IV CPU、1 GB内存和100 GB硬盘,操作系统采用Microsoft Windows 2008 Server。
3.1 实验数据集
实验数据集采用电器零售商近5年的商业销售数据,这些数据被划分成多个稀疏型数据集,分别为:etailer-POS、etailer-Web-1和etailer-Web-2。其中etailer-POS为POS机的销售数据, etailer-Web-1和etailer-Web-2为两个电子商务网站的点击数据。当支持率阈值设定为0.1%时,etailer-Web-1的频繁模式为3 985,etailer-Web-2的频繁模式达到24 056; 当支持率阈值设定为0.03%时, etailer-Web-1的频繁模式数为1 188 067, etailer-Web-2的频繁模式数为1 352 615。
实验数据集还采用了密集型数据集Connect, 该数据集来自机器学习数据集,当支持率阈值从80%降低到55%时,频繁模式数则大幅增长,从29 137增加到84 315 246。另外,为了提高实验的对比性,实验数据集采用了IBM A.I.人工智能数据集,该数据集介于稀疏型数据集和密集型数据集之间。实验数据集的基本特性如表1所示。
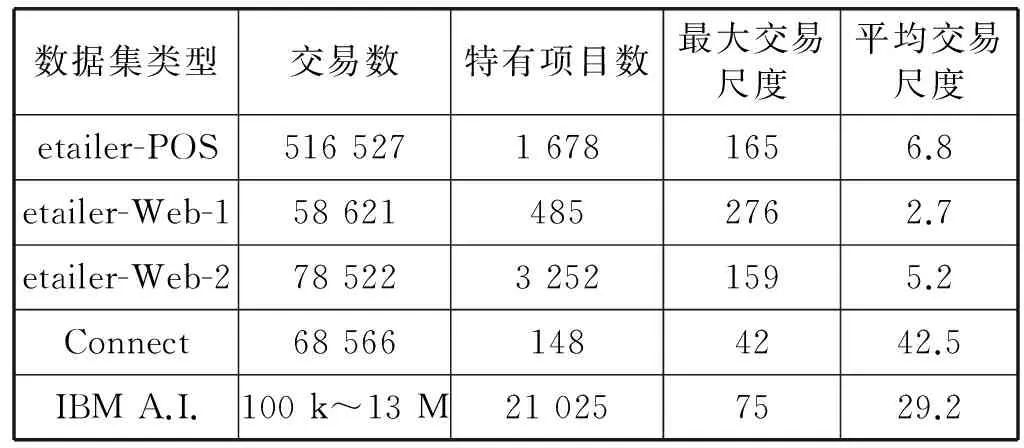
表1 数据集的基本特性
3.2 实验结果
采用四种数据挖掘算法并利用etailer-POS数据集进行对比实验,为了比较不同算法的分析结果,本文采用的性能指标是各算法在不同的支持率阈值运行时间。对比实验的结果如图3所示。图中纵坐标表示时间,横坐标表示支持率阈值,采用对数坐标和百分比。

图3 四种数据挖掘算法对比实验结果
从图3可知,当支持率阈值超过0.4%时,四种算法的性能比较接近;支持率阈值在0.1%和0.2%之间时,FPGrowth算法性能与PMA相似;当支持率阈值低于0.1%时,各算法之间的差异较为显著,处理相同的数据量,FPGrowth需要75秒,H-Mine需要282秒,Apriori需要768秒,而PMA只需要32秒,由此可知,本文提出的PMA算法相对于其他算法在合理的低支持率阈值范围内,具有较高的处理性能。
另外,对于数据集etailer-Web-1、etailer-Web-2、Connect和IBM A.I.的算法性能进行对比分析,所得结果与etailer-POS数据集相类似,这里不再赘述。
4 结 语
本文在频繁模式挖掘算法的基础上,提出了一种基于投影模式支持集的数据挖掘算法,并得到以下结论。
1) 本文提出的数据挖掘算法,对于稀疏型和密集型数据库都能节省算法的时间开销,并能提高传统频繁模式算法的挖掘效率。
2) 由于算法集成了深度优先与宽度优先策略,能够为模式支持集提供基于数组和数状结构的表示形式,并能启发式地应用基于树的虚拟投影和基于数组的过滤型投影等方法,从而达到时间效率的最大化。
[1] Wang Z C, Xue L X. A fast algorithm for mining association rules in image[C]//IEEE International Conference on Software Engineering and Service Science. IEEE, 2014:513-516.
[2] Wang L, Xiwei K E. A Self-Adapted Algorithm for Mining Association Rules Based on Hash Pruning[J].Microcomputer Applications, 2009.
[3] Han J, Fu Y. Discovery of Multiple-Level Association Rules from Large Databases[J].Proc of Vldb, 2010:420-431.
[4] Srivastava S, Gupta D, Verma H K. Comparative Investigations and Performance Evaluation for Multiple-Level Association Rules Mining Algorithm[J].International Journal of Computer Applications,2010,4(10):40-45.
[5] Thakur R S, Jain R C, Pardasani K R. Mining level-crossing association rules from large databases[J].Journal of Computer Science, 2006,2(1):76-81.
[6] Sangam R S, Om H. Hybrid data labeling algorithm for clustering large mixed type data[J].Journal of Intelligent Information Systems, 2015, 45(2):273-293.
[7] Schafer J B, Frankowski D, Herlocker J, et al. Collaborative filtering recommender systems[C]//The adaptive web. Springer-Verlag, 2007:291-324.
[8] Lucchese C, Orlando S, Perego R, et al. Mining Frequent Closed Itemsets from Distributed Repositories[M]//Knowledge and Data Management in GRIDs,2007:221-234.
[9] Han Feng, Zhang Shumao, Du Yingshuang. The analysis and improvement of Apriori algorithm[J].Journal of Communication and Computer,2008,41(9):12-18.
[10] Hewanadungodage C, Xia Y, Lee J J, et al. Hyper-structure mining of frequent patterns in uncertain data streams[J].Knowledge and Information Systems, 2013,37(1):219-244.
RESEARCH ON DATA MINING ALGORITHM BASED ON PROJECTION SCHEME SUPPORT SET
Yang Xiaobo
(CollegeofDongFang,ZhejiangUniversityofFinanceandEconomics,Hangzhou314408,Zhejiang,China)
In order to improve the efficiency of frequent pattern mining algorithms, a data mining algorithm based on projection pattern support set is proposed. The specific research process is as follows. Firstly, it analyzed the data processing of two types projection pattern support set, then it studied the basic strategy and the realize algorithm of projection mode. Finally, the contrast experiment is applied to verify the feasibility of projection pattern data mining algorithm. The algorithm proposed in this paper is more than 2 times higher than other types of data mining algorithms when the threshold of the support rate is lower than 0.1%, which lays a theoretical foundation for the efficient data mining.
Projection scheme Basic strategy Algorithm analysis Data mining
2016-08-12。浙江财经大学东方学院学科专项课题(2013dfy001)。杨晓波,副教授,主研领域:数据挖掘和业务协同等。
TP311.13
A
10.3969/j.issn.1000-386x.2017.07.050
