基于并行Adaboost-BP网络的大规模在线学习行为评价
2017-08-12曹建芳郝耀军
曹建芳 郝耀军
(忻州师范学院计算机科学与技术系 山西 忻州 034000)
基于并行Adaboost-BP网络的大规模在线学习行为评价
曹建芳 郝耀军
(忻州师范学院计算机科学与技术系 山西 忻州 034000)
针对传统的在线学习行为评价方法在处理大规模数据集时面临的问题,提出一种基于并行Adaboost-BP神经网络的在线学习行为评价方法。将BP神经网络作为弱预测器,由Adaboost算法组合15个BP神经网络的输出,构建了强预测器;充分利用了Hadoop平台下MapReduce并行编程模型,提出了大规模在线学习行为的自动评价模型,设计了并行Adaboost-BP神经网络算法的Map和Reduce任务。多组实验表明,提出的算法准确率高、运行耗时少,取得了良好的加速比,效率大于0.5,适合大规模在线学习行为的自动评价。
Adaboost-BP神经网络 在线学习行为 特征提取 MapReduce并行编程模型
0 引 言
网络技术和多媒体技术的快速发展打破了传统的学习方式,网络环境下开放的教学资源(MOOC、网易公开课、视频公开课等)为用户学习提供了愈来愈多的便利,基于网络的学习逐渐成为一种新型的学习方式。然而,网络环境下学习者处于自主学习的状态,学习行为有很大的随意性和片面性。随着在线学习用户数量的增多,学习效果受到愈来愈多师生的关注。而网络学习师生分离,教师无法很好地监控学生的学习行为,学生也由于是自主学习而表现出更多的主观随意性。因此,针对大规模的网络在线学习者,建立学校效果评价模型,自动监督学习者的学习行为,评价其学习效果并将结果反馈给学习者,激发学习者的学习主动性,用以指导学习者进行有效的自主学习,是高校教学工作者和学习者关心的热点问题,也成为计算机智能信息处理的重要内容。
1 相关工作
近年来,随着网络学习用户的急剧增加,研究学者们逐渐展开了对在线学习的分析研究。石娟[1]通过对学习绩效的研究,提出了一种使用网络协作进行知识建构的基于问题的学生学习绩效评价方法。之后,石娟[2]又使用该方法构建了学习行为评价体系,并实施应用,检验其提出的方法的可行性和有效性。针对MOOC平台产生的教育大数据,蒋卓轩等[3]对其做了数据分析和预测,为MOOC教学的测评提供了一种依据。刘士喜等[4]对MOOC环境下学习者的学习行为进行了分析并做出了学习效果的预测。李爽等[5]通过分析学习者学习行为的投入,建立了学习行为投入框架和21个测量指标,为促进有效学习提供理论指导。但上述研究虽然对在线学习行为做了一定程度的分析,但大多是基于人工方式的,都没有做自动的评价分析和预测。信息技术和计算机技术的发展使得研究学者们开始探讨如何让计算机对在线学习行为进行自动分析。姜华等[6]使用BP神经网络构建了学习行为评价模型,在小样本集上进行了训练和测试,取得了较好的评价效果。刘明春[7]也使用BP神经网络对网络环境下学习者的学习行为做了评价分析。戴慧珺等[8]将决策树算法应用于MOOC历史数据的分析中,提出了一种教学评估方法。上述机器学习算法对在线学习行为的分析和预测都是基于小样本数据集的,然而网络教育的迅速发展以及在线学习人数的急剧增长已导致海量数据的产生,随着数据量的急剧膨胀,这些基于小样本集的算法效率会骤然下降。MapReduce是近几年发展起来的Hadoop平台下的并行编程框架,能够在基本不增加硬件成本的前提下实现分布式并行处理,这使得传统机器学习算法实现并行处理成为可能。江小平等[9]实现了基于MapReduce的并行K-Means聚类算法,实验测试取得了很好的加速比和扩展性。吴昊等[10]提出了MapReduce环境下的蚁群算法。为解决BP神经网络处理海量数据存在的时间效率低下等问题,苑超等[11]提出了基于MapReduce的BP神经网络算法并将其应用于农业领域的精准施肥中,有效地指导了施肥过程。
海量数据的产生给传统的机器学习算法带来了极大的挑战,而Hadoop平台下MapReduce并行编程框架为海量数据的处理提供了新的思路。本文针对网络环境下学习者在线学习产生的教育大数据,为提高预测性能,提出了并行Adaboost-BP神经网络算法,在MapReduce环境下将BP神经网络作为弱预测器,由Adaboost算法组合弱预测器的结果构建了强预测器,对在线学习行为进行评价分析。
2 基于MapReduce的Adaboost-BP神经网络算法
2.1 Adaboost-BP神经网络算法
为构造出一个好的网络结构,传统的BP神经网络算法根据经验和反复实验不断测试网络,以保证获得好的泛化能力。Hansen等[12]证明,反复训练多个神经网络并组合其输出可以显著提高神经网络算法的泛化能力。而由Freund等[13]在1999年提出的Adaboost迭代算法,通过反复搜索样本特征空间,获取样本权重,并在迭代过程中不断调整训练样本的权重,增加预测精度低的样本的权重、减小预测精度高的样本的权重,并通过线性组合形成一个强预测器,显著提高学习算法的预测性能,而且Adaboost算法由于不需要事先知道弱预测学习算法的精度下限而被广泛应用于各类实际问题中。Adaboost-BP神经网络算法就是将Adaboost算法与BP神经网络算法有机结合,将BP神经网络作为弱预测器,由Adaboost算法组合多个BP神经网络的输出构建强预测器。算法的执行步骤[14]为:
(1) 初始化样本数据的分布权值和BP神经网络。
确定BP神经网络的结构,输入层节点数根据样本特征维数确定,输出层个数根据输出结果维数确定,隐含层节点数由以下公式确定:
(1)
式中,ni、no、nh分别表示BP神经网络输入层、输出层和隐含层的节点数;α为[0,1]之间的随机数。
将BP神经网络的初始权值和阈值初始化为[0,1]之间的随机数。
(2) 单个BP神经网络弱预测器预测。训练BP神经网络,根据每个神经网络的输出计算预测序列g(t)的预测误差和εt:
(2)
式中,gt(xi)为BP神经网络的预测结果,yi为期望的预测结果。
(3) 计算预测序列的权重αt:
(3)
(4)
式中,Bt为归一化因子,作用是使得在权重比例不变时权值总和保持为1。
(5) 构造强预测函数。组合T轮训练后得到的T组弱预测函数f(gt,αt),得到强预测函数h(x):
(5)
2.2 MapReduce并行编程模型
MapReduce是Hadoop平台分布式并行处理的核心技术之一,它采用标准的函数式编程计算模型,将计算分为Map和Reduce两个任务,分别对应mapper()和reducer()两个函数,主要是以键值对的形式,按照一定的映射规则将输入的键值对
2.3 并行Adaboost-BP神经网络算法
为克服传统的Adaboost-BP神经网络算法在面对海量样本数据时存在的硬件开销大、训练时间长等问题,本文利用MapReduce并行编程模型对Adaboost-BP神经网络算法进行了并行化设计,有效地缩短了训练时间,提高了预测精度。其模型结构如图1所示。

图1 算法并行化模型
2.3.1 Adaboost-BP-mapper()设计及实现
Map阶段,mapper()函数针对每个BP神经网络弱预测器,逐层计算网络输出,并与期望值相比较,得出预测误差εt,然后以此更新连接权值,进行重新标记。函数伪代码如下:
输入:<弱预测器ID, 样本特征值>
输出:<弱预测器ID,εt>
{
//对每个弱预测器
训练弱预测器:
{
计算网络各层的输出;
计算网络的学习误差;
更新网络连接权值;
}
截至2017年底,全国铁路营业里程达12.7万公里,其中高铁2.5万公里;公路总里程477.15万公里,其中高速公路13.6万公里;港口万吨级以上泊位达2317个;民航运输机场发展到229个。交通与物流融合发展,物流基础设施网络基本成型。
获取弱预测器的预测函数gt;
计算预测误差εt;
输出(弱预测器ID,εt);
}
2.3.2 Adaboost-BP-combine()设计及实现
在MapReduce并行编程模型中,使用Combine()函数可以对Map阶段产生的中间结果做本地处理,从而大大降低通信开销。因此,本文在Reduce阶段之前先设计Adaboost-BP-combine()函数对Adaboost-BP-mapper()函数产生的中间结果进行了本地处理。函数伪代码如下:
输入:<弱预测器ID,εt>
Adaboost-BP-combine (弱预测器ID,εt)
{
count←0;
//统计训练弱预测器数
//对每个弱预测器
解析并处理εt的各维坐标值;
count←count+1;
}
2.3.3 Adaboost-BP-reducer()设计及实现
Reduce阶段,reducer()函数接收combine()函数的输出,合并、计算,形成最终输出结果。函数伪代码如下:
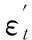
{
}
3 大规模在线学习行为评价
3.1 特征提取
使用机器学习算法对在线学习行为自动评价之前,需要首先确定能够反映学习者学习行为的主要特征,即影响学习行为的主要因素。根据学习者在网络环境下学习的轨迹和调研,确定了以下11个特征作为本文设计的算法中BP神经网络的输入:登录次数(x1)、停留时间(x2)、已浏览的媒体类型数(x3)、提交作业的次数(x4)、作业打分(x5)、参与测验次数(x6)、上传资源次数(x7)、浏览资源次数(x8)、下载资源次数(x9)、讨论发言次数(x10)和在线交流时间(x11)。这些都是定量指标,为方便处理,BP神经网络对数据都做了归一化。最终输出的结果为3个评价标准:学习积极性(y1)、知识点掌握情况(y2)和分析、解决实际问题的能力(y3),本文对这3个定性指标做了量化,取值范围都在0-1之间,分3档,[0.8,1]表示“优”,[0.5,0.8)表示“中”,[0,0.5)表示“差”。
3.2 评价模型的构建
根据学习者常采用的在线学习方式,并结合目前网络教育的现状,本文提出的基于并行Adaboost-BP神经网络的大规模在线学习评价模型如图2所示。
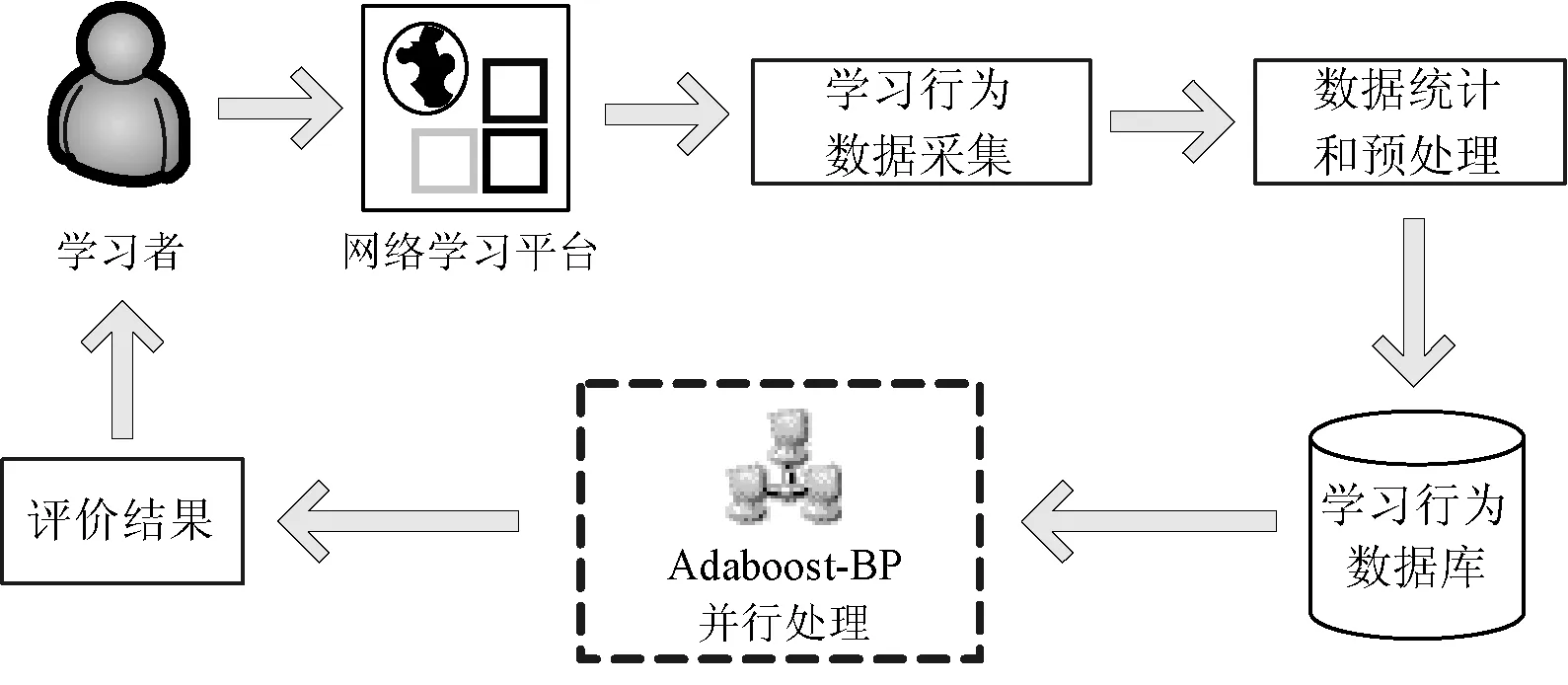
图2 大规模在线学习评价模型
3.3 在线学习行为评价的实现
基于并行Adaboost-BP神经网络的大规模在线学习行为评价模型,根据采集到的学习者在线学习行为特征,在Hadoop平台下利用MapReduce并行编程模型实现并行处理,实现在线学习行为的自动评价。具体步骤为:
(1) 确定模型的拓扑结构。本文将15个BP神经网络作为弱预测器,对于每个BP神经网络,由于输入是x1至x1111个在线学习行为特征,输出是y1至y33个评价指标,所以根据式(1)构建了11-4-3的网络结构。
(2) 确定学习样本数据,并根据式(6)对数据做归一化处理。
(6)
式中,xi为样本特征值,xmax、xmin分别为样本空间中对应特征的最大值和最小值,ri为归一化处理后的特征值。
(3) 并行训练Adaboost-BP神经网络。根据本文提出的并行Adaboost-BP算法,搭建Hadoop集群,不断更新连接权值,反复修正误差,训练网络,组合各网络输出结果。
(4) 评价预测。使用训练好的网络结构,对在线学习者的学习行为进行预测,并将结果反馈给学习者。
4 实验结果及分析
4.1 实验环境和数据来源
实验环境:5台计算机搭建Hadoop集群,1台为Master节点,其余4台为Slave节点。所有节点计算机都采用4 GB内存、主频3.4 GHz的四核处理器,1 TB硬盘空间的基本配置,使用Ubuntu操作系统。
数据来源:本文使用的实验数据来源于中国大学MOOC上的在线学习者的学习行为,由于数据采集和统计工作量较大,因此共收集整理了20 000条有效数据作为本文的实验数据集(今后会进一步扩大数据集进行实验),采用计算机随机选择的方法构造了5个数据集Data1、Data2、Data3、Data4、Data5,各数据集包含的样本数据量分别为:500、2 000、5 000、10 000、20 000。
4.2 性能测试与分析
为验证提出的算法的评价效果,本文从预测准确率、运行耗时以及加速比和效率等几个方面进行了实验对比。
(1) 预测准确率
预测准确率是常用的一个评测标准,指的是在一次预测过程中,系统得到的在线学习行为评价准确(与专家的人工评价相比较)的学习者数目占参与评价的所有学习者数目的比例。
(7)
式中,n为一次预测过程中得到的在线学习行为评价准确的学习者数目;T为参与评价的学习者总数。
本文在不同的数据规模下,在训练样本与测试样本分别为3∶2、2∶1、3∶1、5∶1的比例下,对Adaboost-BP神经网络算法、文献[11]中提出的并行BP神经网络算法以及本文提出的并行Adaboost-BP神经网络算法的预测准确率进行了比较。实验结果如表1所示。

表1 不同数据规模下不同算法性能比较
从表1的数据可以看出,本文提出的并行Adaboost-BP神经网络算法的预测准确率明显优于传统的Adaboost-BP神经网络和文献[11]提出的并行BP神经网络算法。随着样本数据集的不断增大,虽然三种算法的准确率都有下降,但传统的Adaboost-BP神经网络算法由于是串行处理导致准确率急剧下降,而并行BP神经网络和本文提出的算法下降的幅度不是很大,这也充分说明了MapReduce并行编程模型更适合于处理大数据集。另外,从标准差的统计结果看,无论在哪种数据规模下,本文提出的算法标准差最小,这说明使用并行Adaboost-BP神经网络算法进行在线学习行为评价产生的波动最小,相对于Adaboost-BP算法和并行BP算法,本文提出的并行Adaboost-BP算法算法性能优越。
(2) 运行耗时
为进一步验证提出的算法的有效性,本文使用15 000条数据训练网络,其余的5 000条数据做测试,在不同的从节点数情况下对并行BP神经网络算法和本文的算法做了运行耗时的实验对比。比较结果如图3所示。

图3 运行耗时比较
图3的数据表明,由于本文提出的算法并行使用Adaboost算法构建了强预测器,而且设计了Combine()函数降低了通信开销,因此训练网络和预测的运行耗时较少,取得了较理想的实验效果。
(3) 加速比和效率
加速比[15]是指同一任务在单个计算节点的运行时间与多个计算节点的运行时间的比值,效率[15]是加速比与计算节点数量的比值,二者都是衡量Hadoop集群下并行算法效率的重要指标。图4(a)和(b)分别是在Data1-Data5不同数据规模下的加速比与效率的实验结果。


图4 性能对比
理想状态下,加速比应随着节点数的增加而线性增长,效率始终保持1不变。但由于受到通信开销、负载平衡等因素的影响,加速比不能线性增长,效率也达不到1,一般认为,只要效率达到了0.5,就认为获得了很好的性能。从图4(a)和(b)可以看出,在不同的数据规模下,加速比随着节点个数的增加而增加,系统效率也始终在0.5以上,充分说明系统获得了很好的性能。另外,面对大规模数据集,节点个数愈多,加速比与效率性能愈好,这也进一步说明了MapReduce并行编程模型更适合于处理大规模数据集,数据集愈大,愈能充分发挥各节点的计算能力。
5 结 语
本文对基于并行Adaboost-BP神经网路的大规模在线学习行为评价做了深入的探讨和研究,研究了如何并行使用Adaboost算法构建强预测器,并将其应用于在线学习行为的评价和预测中,在Hadoop平台上实现了大规模在线学习行为的自动评价,用以指导学习者的学习行为。实验结果表明,提出的算法预测准确率高,运行耗时少,搭建的Hadoop集群能充分利用各计算节点的资源,提高训练和预测速度,相对于单节点架构,系统获得了很好的性能,充分体现了分布式并行处理架构的强大运算能力。
伴随着大数据时代的到来,对于各类大数据的分析和处理已成为新的研究热点。本文下一步的研究工作主要包括:(1)扩展Hadoop集群的节点数,调节系统的相关参数,进一步提高分布式并行系统的工作效率;(2) 调整BP神经网络的参数和弱预测器的个数,进一步提高预测的准确率;(3) 优化MapReduce并行编程模型的Map任务和Reduce任务的设计,从而实现更快、更精确的评价预测。
[1] 石娟. 基于问题的Web-CKB学习绩效评价研究[J].中国远程教育,2011(11):17-21,95.
[2] 石娟. 基于问题的Web- CKB学习行为评价体系的构建及教学应用[J].中国电化教育,2015(3):115-118.
[3] 蒋卓轩,张岩,李晓明.基于MOOC数据的学习行为分析与预测[J].计算机研究与发展,2015,52(3):614-628.
[4] 刘士喜,胡晓静,徐志红,等. MOOCs环境下学习者学习行为分析与学习效果评估[J]. 巢湖学院学报,2015,17(6):143-148.
[5] 李爽,王增贤,喻忱,等. 在线学习行为投入分析框架与测量指标研究[J].开放教育研究,2016,22(2):77-88.
[6] 姜华,赵洁. 基于BP神经网络的学习行为评价模型及实现[J].计算机应用与软件,2005,22(8):89-91.
[7] 刘明春. 基于BP神经网络的在线学习行为评价模型[J]. 无线互联科技,2015(14):36-37,43.
[8] 戴慧珺,桂小林,张成,等. 基于历史大数据决策树分类的MOOC教学评估方法研究[J]. 计算机教育,2015(22):52-55.
[9] 江小平,李成华,向文,等. K-Means聚类算法的MapReduce并行化实现[J]. 华中科技大学学报(自然科学版),2011,39(SI):120-124.
[10] 吴昊,倪志伟,王会颖. 基于MapReduce的蚁群算法[J]. 计算机集成制造系统,2012,18(7):1503-1509.
[11] 苑超,李东明,李岩. 基于MapReduce的BP神经网络在精准施肥中的应用[J]. 中国农机化学报,2016,37(2):191-195.
[12] Hansen L K.,Salamon P. Neural network ensembles[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(10):993-1001.
[13] Robert E S. Theoretical views of boosting[C]//Proceedings of European Conference on Computational Learning Theory. Nordkirchen, Germany, Springer-Verlag,1999:1-10.
[14] 曹建芳,陈俊杰,李海芳. 基于Adaboost-BP神经网络的图像情感分类方法研究[J]. 山西大学学报(自然科学版),2013,36(3):331-337.
[15] 王贤伟,戴青云,姜文超. 基于MapReduce 的外观设计专利图像检索方法[J]. 小型微型计算机系统,2012,33(3):626-632.
EVALUATION OF LARGE-SCALE ONLINE LEARNING BEHAVIOR BASED ON PARALLEL ADABOOST-BP NETWORK
Cao Jianfang Hao Yaojun
(DepartmentofComputerScienceandTechnology,XinzhouTeachersUniversity,Xinzhou034000,Shanxi,China)
Aiming at the problems that traditional online learning behavior evaluation methods face when dealing with large-scale data sets, an online learning behavior evaluation method based on parallel Adaboost-BP neural network is proposed. The BP neural network was used as the weak predictor, and 15 BP neural networks were combined by the Adaboost algorithm to construct the strong predictor. The MapReduce parallel programming model of Hadoop platform was fully utilized. An automatic evaluation model of large-scale online learning behavior was proposed. The Map and Reduce tasks of parallel Adaboost-BP neural network algorithm were designed. The experimental results show that the proposed algorithm has high accuracy rate, low running time and good speedup ratio. The efficiency is more than 0.5, which is suitable for the automatic evaluation of large-scale online learning behavior.
Adaboost-BP neural network Online learning behavior Feature extraction MapReduce parallel programming model
2016-07-23。山西省自然科学基金项目(2013011017-2);山西省高等学校教学改革重点项目(J2015099);2014年度忻州师范学院重点学科专项课题(XK201308)。曹建芳,教授,主研领域:智能信息处理,大数据技术。郝耀军,副教授。
TP391
A
10.3969/j.issn.1000-386x.2017.07.049
