基于Hive的支付SDK日志分析系统的设计研究
2017-08-12王建辉
王建辉 李 涛
(南京邮电大学通信与信息工程学院 江苏 南京 210003)
基于Hive的支付SDK日志分析系统的设计研究
王建辉 李 涛
(南京邮电大学通信与信息工程学院 江苏 南京 210003)
UniPay支付SDK是联通沃商店为了给开发者提供手机话费和第三方支付能力而推出的一站式应用内统一支付插件,支付SDK日志记录海量的用户终端信息、用户使用手机应用的行为记录等数据。针对传统数据仓库难于满足海量日志数据存储及处理等问题,设计一种基于Hive的支付SDK日志分析系统。测试结果表明,使用Hadoop框架及Hive数据仓库对海量支付SDK日志进行存储和处理,能很好地满足业务需求,对手机应用的设备激活量、日活跃用户数(DAU)、分时日志量以及用户支付转化率等指标的分析结果,对应用开发者升级优化其应用及运营人员的营销策略调整具有重要的参考价值。
Hive SDK日志 应用分析 用户行为
0 引 言
据工信部最新发布的数据显示,2016年1月,我国移动互联网用户净增1 942.1万户,同比增长11.8%,总数达9.8亿户[1]。截止2016年2月,我国第三方应用商店累计应用分发量已达到8 350亿次,以分发规模计,我国用户渠道实力已领先于覆盖全球移动用户的谷歌官方商店,仅我国 Android应用实际市场规模已近谷歌全球市场的近五倍[2]。随着移动互联网的迅速发展和移动智能终端的广泛应用,移动端应用有取代PC成为最大的互联网用户入口的趋势。互联网企业、电商平台及传统企业都积极将自己的服务部署到移动端,在为用户提供便捷服务的同时产生了海量的日志数据,这些日志客观反映用户消费行为及影响用户消费行为的内外因素,分析这些日志,挖掘数据背后的规律,具有重要的商业价值[3]。深入挖掘这些数据隐含的信息,可获取海量有价值的用户信息。分析用户的行为规律,可以为产品营销人员提供客观可靠的数据支持,实现精细化运营,为用户提供更加个性化的服务,提升用户体验,最终为企业带来可观的经济效益。随着日志数据量的爆炸式增长,处理海量日志数据的任务也日益增多,如何将海量数据集中、存储、分析并产生商业价值,成为运营和研发人员亟待解决的难题。
面对海量数据,传统数据仓库使用成本高、效率低、扩展性差,难以满足业务发展需求,严重制约着移动应用运营收入的增长。基于分布式思想的Hadoop框架很好地解决了这个难题,并迅速成为大数据处理领域事实上的标准。采用Hive/Hadoop方案应对大数据处理问题,具有成本低、扩展性好、可靠性高、效率高等优势,采用HDFS[4]和MapReduce[5-6]编程模型解决了海量数据存储和处理的难题,可实现对海量数据进行挖掘的目标。
1 相关技术介绍
1.1 Apache Hive数据仓库
Apache Hive是一种基于Hadoop的数据仓库构架,提供一种存储、查询和分析HDFS中海量数据的机制[7]。Hive提供类SQL语言HQL,简化了用户处理海量数据的操作。Hive架构分为以下几部分:
用户接口:通常指命令行界面CLI,启动时会同时启动一个Hive副本;
元数据:通常存储在关系数据库中,包括表名、表的列和分区及其属性、表数据所在目录等信息;
解释器、编译器、优化器、执行器:该部分是Hive数据处理功能的核心,解释编译优化HQL语句,将其转换为MapReduce任务,完成对存储在HDFS中数据的处理。
1.2 Hadoop集群
Hadoop集群是Hive数据仓库功能实现的基础,Hadoop框架核心是HDFS和MapReduce,功能分别是为海量的数据提供存储和计算框架。HDFS保证应用程序以高吞吐量访问海量数据时的可用性;MapReduce完成海量数据的分布式计算,开发者无需掌握分布式编程的相关知识,就能完成海量数据分析。Hive数据仓库是支付SDK日志分析系统的功能核心,海量日志的分析处理主要由该部分完成。
2 基于Hive的支付SDK日志分析系统设计
基于Hive的支付SDK日志分析系统如图1所示,系统由日志收集、日志处理、结果汇总、数据展示四个模块组成[8]。
日志收集模块:应用客户端和服务端之间的交互数据以JSON格式进行传输,通过HTTP协议将交互信息以日志形式记录并上传至Tomcat服务器,通过脚本预处理(数据去重、过滤异常数据、小文件合并等),再由FTP上传存储于HDFS。

图1 基于Hive的支付SDK日志分析系统架构图
日志处理模块:后台服务器使用crontab命令定时执行脚本,将日志解析并导入到Hive数据仓库中表相应分区,按业务需求对数据去重、汇总、统计,结果通过Sqoop导出到Mysql和Oracle等关系型数据库。该模块是分析系统的核心,数据处理脚本的执行时间决定系统效率及稳定性,调优也在该模块完成。
结果汇总模块:该模块通过传统关系型数据库对日志数据做进一步处理,如编写调用存储过程等,也可通过JDBC直接访问查询。
数据展示模块:系统中数据展示分为三种形式:对SDK日志的整体监控,定时给相关人员发送监控邮件,如对每日设备激活量、支付SDK日志总量、分时日志量及DAU/WAD/MAU(日/周/月活跃用户数)等指标的监控报表;对用户在应用中的支付转化率、应用在不同日期、省份、版本等维度的支付转化率等指标则给运营人员提供Web页面查询功能,供其根据具体业务需求查询;对于异常省份、应用、用户的查询分析则通过实时查询的方式,以便及时发现问题、调整运营策略。
3 系统测试结果分析
系统测试数据来源于联通沃商店支付SDK日志文件。测试环境:测试集群含4台服务器,一个主节点:处理器32核,内存192 GB,磁盘容量300 GB;3个数据节点:处理器32核,内存128GB,磁盘容量1 TB,集群磁盘总容量:4.3 TB;软件版本:Hadoop-2.6.0;hive-1.2.1;sqoop-1.4.3。
沃商店每天支付SDK日志大小约200 GB,系统可提供T+1的日志分析结果,每天00∶30开始执行定时任务,09∶00之前即可执行完毕,完成前一天支付SDK日志的分析及入库,及时为运营、产品及研发人员提供数据支持。
沃商店客户端和服务端的业务实现采用标准HTTP/1.1协议作为承载协议,采用请求<->应答的同步处理方式处理信息,不同类型消息通过URL区分。消息记录即支付SDK日志,每次请求生成一条记录,支付SDK日志数据大致分为7种类型:设备信息、注册、登录、支付、退出、SDK版本升级、崩溃日志等。
支付SDK日志由JSON格式的数据串、时间戳、ip地址等组成,以设备信息为例,日志格式如下:
{″model″:″HUAWEI_A199″,″IMEI″:″A0000043CD6EDC″,″logtype″:″device″,″lcd″:″1280X720″,″mac″:″24:69:a5:a5:97:d2″,″IMSI″:″460030979228177″,″channel″:″00018756″,″osversion″:″4.1.2″}|20160910115959|192.168.31.166
日志含手机设备序列号IMEI、SIM卡唯一编号IMSI、渠道号、时间戳等信息。IMSI唯一确定一个用户,通过IMSI、时间戳可统计每日活跃用户数(DAU)。DAU常用于评价应用的运营情况,结合月活跃用户数量(MAU),可测量应用的衰退周期和用户粘性。分时日志统计用于监控每天各时间段的日志量,分析应用在各时间段的使用状况。通过IMSI、终端型号统计各运营商用户、各终端品牌占比和用户留存率,可针对不同运营商、终端品牌的用户制定更具针对性的营销策略;用户留存率是用来评定用户粘度的关键指标,通过日留存率、周留存率、月留存率等指标监控应用的用户流失情况,可在用户流失之前及时采取措施挽留用户;日志分析结果以监控邮件的方式每天定时发送,及时为运营和产品等部门提供数据支持。
支付日志分析是监控沃商店运营状况及评估应用优化效果的主要手段,也是增加运营收入的关键。支付日志记录了用户在每个页面跳转情况,可分析每个页面的到达率,跟踪洞察用户从进入应用到离开应用的全过程。通过分析支付日志,跟踪各计费点,分析用户付费行为,识别用户付费偏好,发现用户支付行为的规律,帮助开发者优化计费点及计费模式,为不同类型的应用设置相应的计费点,积极引导用户消费,提高支付转化率。支付转化率是指从当前页面进入下一页面的用户数比率,由用户访问路径可统计各页面到下个页面的转化率及每一步的流失情况。
借助一些图表工具可更加形象地展示结果,转化率统计场景适用漏斗模型。漏斗模型既能显示用户在进入流程到实现目标的最终转化率,也能展示关键路径中每一步的转化率。通过漏斗模型,应用开发者及运营人员可以准确判断流程的设计是否合理,各个步骤的优劣,是否存在优化的空间,从而有针对性地对产品进行改进,为用户提供更合理的访问路径或操作流程,以提升用户体验。
系统测试以沃商店某款应用325版本的支付转化数据为例,如图2所示:从进入支付页面到一次确认转化率为22%,一次确认到二次确认转化率为72%,二次确认到成功支付转化率为53%,整体转化率为7.60%。从漏斗模型上看,进入支付到一次确认这一步用户流失率最高,达78%,说明对该环节进行改进或优化的空间很大,在该环节挽留用户的效果相对明显,开发者可在此环节增加挽留用户的功能。对应用升级优化后,还可从转化率漏斗模型观察改进效果。
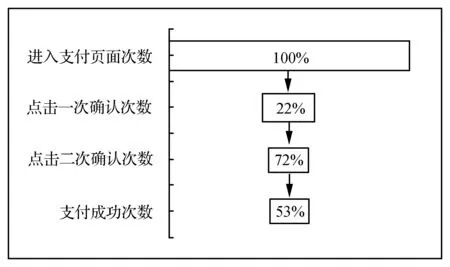
图2 支付转化率漏斗模型
支付日志分析结果以Web页面查询的方式展现,运营及产品人员通过后台管理系统界面查询,系统提供日期、版本、应用、开发者等维度的查询。
Hive数据仓库与传统Oracle数据库对同一日志文件的去重操作耗时对比如图3所示:横坐标表示待处理日志文件的大小,单位MB/GB,纵坐标表示耗时,单位是毫秒。

图3 Oracle数据库与Hive去重操作耗时对比
系统测试以常见的日志去重为例,数据量较小时,即日志文件小于2 GB时,Oracle数据库比Hive数据仓库耗时少;随着数据量的增加,当日志文件大于2 GB并继续增加时,Oracle数据库耗时急剧增加,Hive数据仓库在处理少量数据的耗时大于传统数据库,面对海量数据处理任务时,Hive的优势会随着数据量的增加越来越明显。
4 结 语
分析用户行为是评价、运营和优化一个手机应用的重要方式,支付SDK日志记录的用户终端信息、应用升级、支付等信息可客观反映用户行为。针对传统系统难以满足海量数据处理且成本越来越高的问题,设计并实现了一种基于Hive数据仓库的支付SDK日志分析系统,借助Hadoop集群强大的数据处理能力和hive构建数据仓库的集成、分析和快速查找能力,对支付SDK日志进行分析,挖掘用户的行为规律。测试结果表明:利用Hive数据仓库对海量支付SDK日志的分析效率明显优于传统数据库,还有成本优势。分析结果对应用的精细化运营和优化具有一定的指导意义,不但能为用户提供更个性化的服务,提升用户体验、产生商业价值,还在一定程度上突破了传统系统处理海量数据的局限性。
[1] 工业和信息化部. 2016年1月份通信业经济运行情况[OL]. http://www.miit.gov.cn/n1146312/n1146904/n1648372/c4658448/content.html.
[2] 中国信息通信研究院.国内移动互联网应用市场运行分析报告[OL]. (2016-2). [2015-9].http://www.catr.cn/kxyj/qwfb/zdyj/201604/P020160414387395395899.pdf.
[3] 王正也,李书芳. 一种基于Hive日志分析的大数据存储优化方法[J]. 软件,2014,35(11):94-100.
[4] 王来,翟建宏. 基于HDFS的分布式存储策略分析[J].智能计算机与应用,2016(1):5-8.
[5] Tom White. Hadoop权威指南[M].曾大聃,周傲英,译.北京:清华大学出版社,2010.
[6] Dean J, Ghemawat S. MapReduce:Simplified Data Processing on Large Clusters[J]. Communications of the ACM,2008, 51(1):107-113.
[7] 江三锋,王元亮. 基于Hive的海量web日志分析系统设计研究[J]. 软件,2015,36(4):93-96.
[8] 周鹤,朱晓民,赵锐,等. 手机阅读平台仓库管理模块的设计与实现[J]. 电信工程技术与标准化,2016(2):84-87.
DESIGN AND RESEARCH OF HIVE-BASED PAYMENT SDK LOG ANALYSIS SYSTEM
Wang Jianhui Li Tao
(CollegeofTelecommunicationandInformationEngineering,NanjingUniversityofPostsandTelecommunication,Nanjing210003,Jiangsu,China)
UniPay payment SDK is Unicom Wo store launched a one-stop application within the unified payment plug-in for developers to provide mobile phone calls and third-party payment capabilities. Payment SDK log records a large number of user terminal information, the use of mobile phone application behavior records and other data. Aiming at the problem that the traditional data warehouse can not satisfy the massive log data storage and processing, a Hive-based payment SDK log analysis system was designed. The test results show that using Hadoop framework and Hive data warehouse to store and process the massive payment SDK log, can meet the business demand well. The analysis result of user behavior in device activation, daily active user, quantity of time-log and the user payment conversion rate can provide important references for application developers to optimize and upgrade their mobile applications, and for operational personnel to adjust their marketing strategy.
Hive SDK log Application analysis User behavior
2016-07-25。王建辉,硕士生,主研领域:大数据分析。李涛,副教授。
TP3
A
10.3969/j.issn.1000-386x.2017.07.011
