面向健康大数据的数据清洗技术
2017-08-10陈永红廖欣郑欣陈雷霆
陈永红,廖欣,郑欣,陈雷霆,4
(1.电子科技大学计算机科学与工程学院,成都 611731;2.东莞成电金盘软件技术有限公司,东莞 523808;3.四川大学华西妇产儿童医院,成都 611731;4.电子科技大学广东电子信息工程研究院,东莞 523808)
面向健康大数据的数据清洗技术
陈永红1,2,廖欣3,郑欣1,陈雷霆1,4
(1.电子科技大学计算机科学与工程学院,成都 611731;2.东莞成电金盘软件技术有限公司,东莞 523808;3.四川大学华西妇产儿童医院,成都 611731;4.电子科技大学广东电子信息工程研究院,东莞 523808)
提出一套完整的健康大数据清洗方案。首先剔除原始数据集中的重复数据,然后,对数据集进行完整性、有效性及一致性验证,最后,使用基于密度的改进孤立点检测算法剔除局部孤立点及全局孤立点。为验证所提方案的有效性,使用Tri-training算法在健康大数据集上进相关实验。实验表明,所提数据清洗方案能够同时识别局部孤立点和全局孤立点,从而显著提高后续数据分类模型的性能。
基于健康大数据的关键共性技术研究的企业科技特派员工作站建设(No.2014A090906004)
0 引言
随着大数据时代的到来,海量数据的不断剧增给医疗健康领域带来了深刻变革[1]。医疗健康行业可通过大数据技术的支持,实现对现有资源的整合和重新调整,提高行业运行效率,挖掘产业巨大潜力[2]。然而现有的数据清洗技术方案对健康大数据适应性较差,严重影响了数据挖掘的效率,因此,针对健康大数据的清洗已经成为数据分析过程中必须面对的问题[3]。
1 健康大数据清洗技术面临的挑战
原始采集的健康大数据通常具有不完整性、不一致性和内容模糊性,很难能够直接满足数据分析的要求[4]。首先,健康大数据集中存在着大量的重复数据,即在原始数据集中同一条数据出现了两次或两次以上[5]。其次,原始数据集中很多数据信息不全,存在某些记录属性值丢失的情况,造成数据不完整[6]。同时,由于健康大数据的多元采集方式,不同系统采集的数据缺乏统一标准的定义方式,导致各系统间的数据不一致。此外,大数据本身还存在着一部分不符合预先定义的规则或约束条件的数据和不符合一般模型的数据,这些异常数据也会给后续的大数据分析造成干扰[7]。
针对健康大数据的清洗已经成为大数据分析中必须面对的问题。通过分析健康大数据所面临的挑战,针对其特点,提出一套完整的数据清理方案,并对相关算法进行了改进。实验表明,该方案显著提高了后续数据分类模型的性能。
2 健康大数据数据清洗流程
本节针对现有算法进行改进,提出新的健康大数据清洗方案,使之能更有效地对健康大数据进行清洗。
2.1 数据清洗流程
所提数据清洗方案包含4个步骤:首先,检查数据集,剔除重复数据。然后,对数据的完整性进行验证,以提高分析结果的准确率。接着,对数据的有效性、一致性进行检验,从而降低不合格数据对后续数据分析造成的影响。最后,进行孤立点检测。算法流程如图1所示,具体步骤如下。
(1)清洗重复数据。在数据导入数据库时,使用主键和联合主键唯一性限制,完成对重复数据的清洗。
(2)数据完整性检查。对于含有缺损值的数据项,采用均值估算法处理,将该数据项前n位数据的均值作为其缺损值填补。
(3)数据有效性、一致性验证。根据专家规则,确定各属性项的合理取值范围及统一标准的定义方式,对不同系统间的数据进行有效性和一致性检验,剔除不满足约束条件的记录,将不同定义方式的属性项按专家规则进行统一。
(4)孤立点检测及删除。在数据数据清洗过程中,孤立点属于干扰信息或异常数据,需要删除。通过孤立点检测减少或消除孤立点,并避免有效信息丢失[8]。针对该步处理,提出基于密度的孤立点检测改进算法,算法细节如2.2节所述。
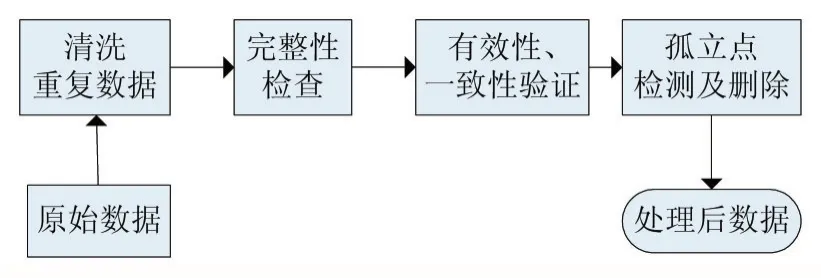
图1 大数据数据清洗算法流程
2.2 基于密度的孤立点检测的改进算法
基于密度的孤立点检测算法在孤立点检测中得到了普遍应用。该算法根据对象所处区域的密度来判定其是否为孤立点[9-10],对检测局部孤立点有着很好的处理效果,然而对于全局孤立点却不太敏感,无法有效检测。其中,密度定义为到k个最近邻的平均距离的倒数[11],密度较低区域中的对象即为孤立点。本文针对此缺陷以及健康大数据的特点对上述算法进行了改进,使之能同时识别局部孤立点和全局孤立点。改进孤立点算法的流程如图2所示,具体步骤如下。

图2 基于密度的孤立点检测改进算法流程
(1)原始数据集的归一化。健康数据各项参数的量纲不同,使用原始数据直接计算,会造成量纲较大的参数对结果的影响显著提高,与实际情况不符。故在将原始数据集用于计算前,应对数据集各数据项进行归一化处理。
对原始数据集进行min-max标准化,使各属性项值映射到[0,1]之间,转换函数如下:

其中max是x所在列的最大值,min是x所在列的最小值。
(2)计算任意点Xi与其他点Yj的欧几里得距离。Xi与Yj是m维空间内的两个点,它们的欧氏距离的计算方式如下:
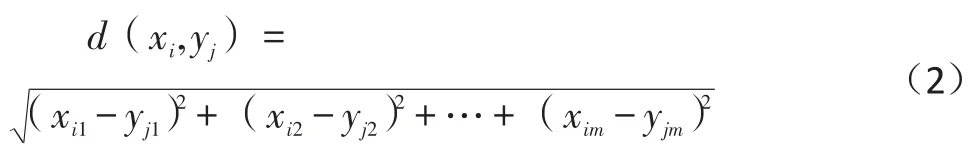
(3)对Xi到其他点的欧几里得距离进行升序排序,找到前k位的点(即离Xi最近的k个点),加入到Xi的k-邻域 Ωik中,并得到 Xi的 k 距离 k-d(Xi)( k-邻域中各点到Xi欧氏距离的最大值),即:

同时,找到最后n位的点(即离Xi最远的n个点),加入到Xi的n-最远域Ωik中,并给n-最远域Ωik中各点的得票数加一,即:

这意味着对于Xi而言,离它最远的这n个点最有可能成为全局孤立点。对于原始数据集而言,得票越高的点,成为全局孤立点的可能性越大。
(4)计算每个点Xi的可达密度。首先计算得到Xi的k-邻域Ωik中每个点Zj的可达距离Reach()Zj:Zj的 k-距离与 Zj到 Xi的欧氏距离 d( )Xi,Zj的较大值,即:
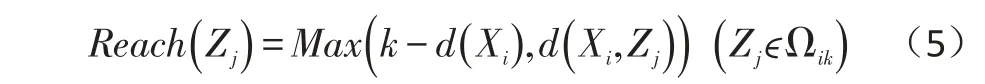
随后计算Xi的可达密度的 k-邻域中每个点Zj的可达距离之和的倒数与k的乘积,即:

(5)计算Xi的局部离群点因子邻域中各点的可达密度的可达密度的比值的均值,即:
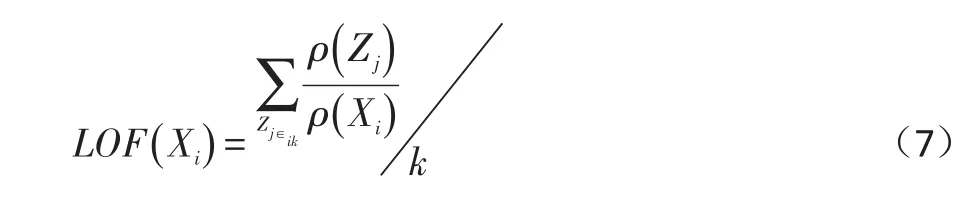
(6)将各点的局部离群点因子进行排序,根据设定的阈值进行判定。设置局部离群点因子阈值VALUE与全局孤立点阈值Ticket,在第一次的筛选中,离群点因子大于VALUE的点即为局部离群点。
(7)在第二次的筛选中,得票数超过阈值Ticket的点即为全局孤立点。VALUE值与Ticket值的确定都与具体样本的大小和取值分布有关,经过多次试验,调整阈值,能够较好的实现剔除局部和全局孤立点的目的。因子阈值VALUE和n、得票数Ticket,来识别局部孤立点和全局孤立点。各参数设定表4所示:

表2 原始算法数据清洗后部分数据表
3 实验及分析
3.1 实验设置
(1)实验数据
本实验所用数据包括原始数据集、原始算法数据清洗后的数据集、改进算法数据清洗后的数据集。本文采取的原始数据集为肝病检测指标数据集“Indian Liver Patient Dataset(ILPD)”,包含各项生理指标 11 项,经过数据清洗后,剔除的异常点约占总数据的18%。
原始数据部分数据如表1所示:

表3 改进算法数据清洗后数据部分数据表
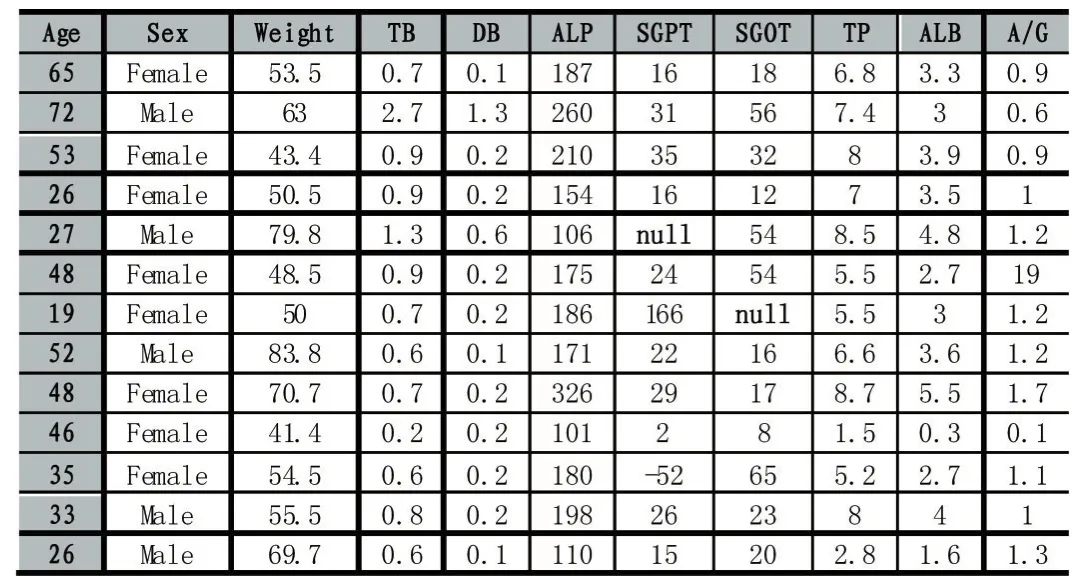
表1 原始数据集部分数据表
原始算法数据清洗过后部分数据如表2所示。
改进算法数据清洗过后部分数据如表3所示。
(2)关键参数设定
按照2.1中(1)-(3)中所述方法对原始数据集进行重复数据清理及完整性检查、有效性和一致性的验证后,将处理过后的数据用于改进后的孤立点检测算法,进行孤立点检测。在(4)中,分别设定参数k、离群点

表4 参数设定表
3.2 实验结果及分析
本文采用Tri-training算法进行验证。Tri-training是半监督算法,通过训练一部分有标签数据,给未标签数据进行标记,然后使用测试数据检验其正确率[12],故而噪声数据对其结果影响比较大。本文将实验分为两个部分,一部分为局部孤立点检测部分,主要对比未数据清洗的错误率与原始算法(仅检测局部孤立点)的错误率来验证数据清洗方案的有效性;第二部分为在局部孤立点检测过后的数据集上进行全局孤立点检测,通过对比原始算法的错误率与改进算法后的错误率来验证改进算法的有效性。
(1)局部孤立点检测
由于当k与VALUE取值不当时,“孤立点”太多,造成过拟合,故经试验后,取k值为5到8,步长为1,VALUE从1.1到1.4,步长为0.05,经Tri-training算法验证的部分结果如表5(原始数据经Tri-training算法验证错误率为0.2906):
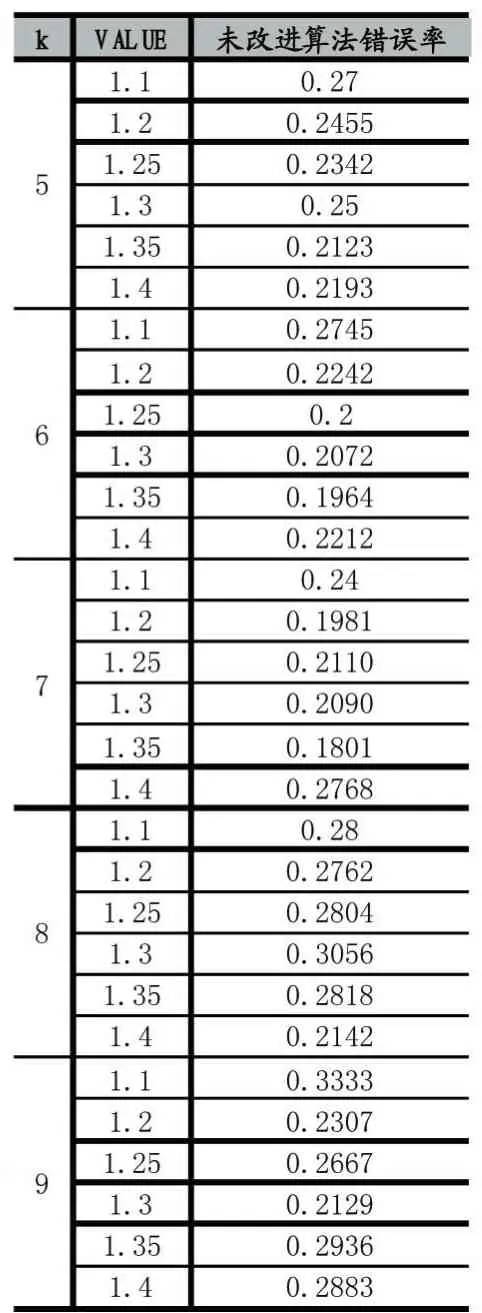
表5 原始算法验证结果表

表6 改进算法验证结果表
(2)全局孤立点检测
根据上表,可以看到当k值不同时,所对应的VALUE值不同,错误率也不同。当k值不同时,取使错误率最低的VALUE值,取n值为8到11,步长为1,固定Ticket值为10(由于当Ticket值过大时会造成部分全局孤立点无法被检测出,Ticket值过小时,会有一部分非全局孤立点被误认为是全局孤立点,且Ticket小范围的变动对结果影响不大,经试验后当Ticket取值为10时能取得不错的效果),经Tri-training算法验证的部分结果见表6。
调整各参数取值,使得在k取不同值时,错误率降到最低。改进算法前后最小错误率对比如图3所示:

图3 改进算法前后最小错误率对比图
分析实验部分(1)与(2)的结果可知,使用Tri-training对原始数据集、原始算法数据清洗后的数据集和改进算法数据清洗后的数据集进行验证,最低错误率分别为:0.2906、0.1801、0.1111,因此,可得到如下信息:
首先,经数据清洗后,最低错误率从0.2906降低到0.1801,降幅38.02%,验证了数据清洗方案的有效性。故本文所提出的数据数据清洗方案有着较好的效果,数据清洗后的数据对大数据分析的性能有着显著的提高。
其次,改进后的算法,经参数调整后,最低错误率从算法改进前的 0.1801降低到了 0.1111,降幅38.31%,算法性能有着明显的提升。证明了改进后的算法能够很好的识别全局孤立点,并极大提高大数据分析的效果,验证了改进算法的有效性。
4 结语
本文将数据清洗技术应用到健康大数据上,首先介绍了健康大数据所面临的挑战,然后根据其特点提出了一套完整可行的大数据清理方案,并针对该方案中孤立点检测算法所存在的不足进行改进,在检测局部孤立点的同时也能检测出全局孤立点。最后通过使用基于Tri-training的半监督分类模型进行检验,实验结果验证了该健康大数据清洗方案的可行性与改进算法的有效性。
参考文献:
[1]卿苏德,吴博.大数据时代亟需强化数据清洗环节的规范和标准[J].世界电信,2015(7):55-60.
[2]阳娜.大数据助力健康产业之路[J].金融世界,2015(7):106-107.
[3]黄健青,黄浩.Web日志分析中数据数据清洗的设计与实现[J].河南科技大学学报自然科学版,2009,30(5):45-48.
[4]Groves P,Kayyali B,Knott D,et al.The"Big Data"Revolution in Healthcare.Accelerating Value and Innovation[J].Mckinsey&Company,2013:4,13-16.
[5]栾江.数据质量控制:数据数据清洗研究、设计与实现[D].四川大学,2004.
[6]梅亮,葛世伦,闫仁武.数据清洗技术在餐饮营业数据库中的实证应用[J].计算机与信息技术,2009(9):32-34.
[6]Wang X,Zhang A D,Yan J.Application Prospects of Big Data in Healthcare[J].Chinese General Practice,2015.
[7]鄢团军,刘勇.孤立点检测算法与应用[J].三峡大学学报(自然科学版),2009,31(1):98-103.
[8]Shi H J,Zhou S Y,Xing-Yi L I,et al.Average Density-Based Outliers Detection[J].Journal of University of Electronic Science&Technology of China,2007,36(6):1286-1285.
[9]祝世东,李卓玲.数据挖掘的异常检测技术分析[J].沈阳工程学院学报(自然科学版),2009,5(3):265-268.
[10]王重阳,无线传感器网络中基于多属性的异常检测技术的研究[D].东北大学,2008.
[11]DENG Chao,GUO MaoZu.Tri-Training and Data Editing Based Semi-Supervised Clustering Algorithm[J].软件学报,2008,19(3):663-673.
Data Cleaning Technology Oriented Health Big Data
CHEN Yong-hong1,2,LIAO Xin3,ZHENG Xin1,CHEN Lei-ting1,4
(1.College of Computer Science and Engineering,University of Electronic Science and Technology of China,Chengdu 611731;2.Dongguan ChengDian gold plate software Technology Co.,Ltd,Dongguan 523808;3.West China Second University Hospital.SU,Chengdu 611731;4.University of Electronic Science and Technology of Dongguan Electronic Information Engineering Research Institute,Dongguan 523808)
Presents a complete scheme of health data cleaning.The scheme removes the duplicate data from the original data set first,then,verifies the integrity,validity and consistency of data set,finally,uses the density-based improved isolated point detection algorithm to eliminate lo⁃cal isolated points and global isolated points.To verify the effectiveness of the proposed scheme,uses the Tri-training algorithm to perform experiments on big healthy data set.Experiments show that the proposed data cleaning scheme can simultaneously identify local isolated points and global isolated points,and significantly improves the performance of the subsequent data classification model.
陈永红(1992-),男,湖北仙桃人,硕士研究生,研究方向为大数据分析、机器学习
陈雷霆(1966-),男,重庆人,教授/博导,研究方向为计算机图形学、数字媒体技术、虚拟现实技术、数字图象处理,
E-mail:richardchen@uestc.edu.cn
2017-04-25
2017-06-10
1007-1423(2017)17-0021-05
10.3969/j.issn.1007-1423.2017.17.004
健康大数据;数据清洗;数据清洗;孤立点检测
廖欣(1981-),女,四川成都人,主诊医师,硕士,研究方向为妇产科临床病理诊断、人工智能在疾病诊断、病理分析中的应用
郑欣(1981-),男,四川绵阳人,博士后,研究方向为大数据分析、人工智能、机器学习。
Health Big Data;Preprocessing;Data Cleaning;Outlier Detection
