移动用户信用评估系统的设计与开发研究
2017-08-10黄英持郑婷婷
黄英持,郑婷婷
(1.中国移动通信集团广东有限公司数据和产品研发中心,广州 510623;2.广东开放大学信息与工程学院,广州 510091)
移动用户信用评估系统的设计与开发研究
黄英持1,郑婷婷2
(1.中国移动通信集团广东有限公司数据和产品研发中心,广州 510623;2.广东开放大学信息与工程学院,广州 510091)
运营商的数据资源优势,为信用评估系统的发展带来新的机遇。建立消费者的指标体系,借鉴已有信用评估模型,使用Apache Spark实现决策引擎,并经过数据采集、数据标准化、数据训练等过程提高计算的准确度,计算结果以Web Service提供,用户可通过多种方式实现个人信用值的快速计算与查询。
信用评估;指标体系;决策树;Apache Spark
0 引言
对企业组织和个人的信用信息进行采集、整理、保存和加工,称为征信,其本质在于利用信用信息对金融主体进行数据刻画[1]。长期以来,中国征信市场是以央行为主导的单一格局,但在用户覆盖面和数据多样性方面,央行征信系统有很大的局限性,例如对于蓝领工人、学生、个体户、自由职业者等用户,无法建立较准确的个人信用记录,且金融机构和民间团体了解这些用户信用记录的成本也比较高。
大数据为信用评估提供了丰富的数据资源,也改变了信用评估产品的设计和生产方式。大数据的出现,特别是互联网金融的蓬勃发展,为信用评估活动提供了全新的发展视角[2-3]。例如互联网征信,主要是通过采集个人在互联网交易或使用互联网各类服务过程中留下的信息数据,并结合线下渠道采集的信息数据,利用大数据、云计算等技术进行信用评估的活动[3-4]。互联网征信为征信发展提供了丰富的信息来源,改变了征信服务理念和传统的信用评分模式,从而更好地推动我国个人征信市场的建立及社会信用体系的完善。
目前较有代表性的互联网征信系统包括阿里巴巴的“芝麻分”的信用评级产品和“花呗”的个人信用消费产品,京东的“白条”的个人信贷消费产品等,这些产品在需要支付押金或预授权等现实中的各种履约场景都可以得到应用。
移动运营商具有先天的数据资源优势,充分利用移动运营商所拥有的优质数据建立个人信用记录,并与其他征信平台合作整合,既能挖掘移动运营商的资产潜力,也能顺应“互联网+”的发展潮流。
1 移动用户信用评估指标体系构建
基于移动用户的消费行为,选择合适的特征指标体系,可以尽量以较少的变量反映数据的主要特征[5]。综合可获取的指标以及专家意见,可大致建立用户信用评估的主要指标体系,如表1所示。
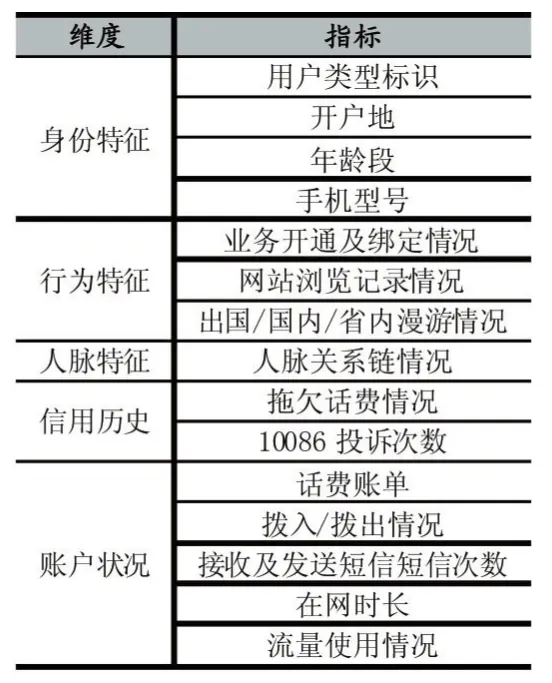
表1 移动用户征信主要指标体系
第一层分为身份特征、行为特征、人脉特征、信用历史、账户状况5个维度。身份特征维度主要是利用运营商实名制的优势获取用户年龄、居住工作地等与通信和行为无关的基本特征;行为特征衡量用户对移动通信,移动互联网的使用情况;人脉特征主要反映用户的社交圈子的信用程度;信用历史和账户状况反映了用户过去和现在的基本信用情况。
2 信用评估计算的实现
概括而言,消费者信用评估方法可以分为统计模型和非统计模型两类,统计模型包括判别分析、逻辑回归、K近邻规则、决策树等;非统计模型包括数学规划、支持向量机、神经网络、遗传算法等[6]。为了获取更准确的计算结果,可以将上述两种或几种方法有机地结合起来,实现更有效的信用评估计算。例如可以把决策树和非统计模型的方法结合起来计算用户的消费特征,使用贝叶斯网络分类模型训练得到的数据,这都是系统中可以借鉴的实现方式。
信用评估计算的关键是科学合理地选出信用变量,并产生一个公式。常用于个人信用评估的数据挖掘方法包括分类、聚类、关联规则分析、预测、孤立点检测等[7]。数据挖掘的前提是需要采集到足够的数据样本,但样本中有些特征指标的变量需要经过归一标准化处理后才能进行下一步的计算,例如对于离散变量,可通过标准化计算把它的值映射到[0,1]区间。然后使用熵值法计算指标的权重。熵值法的基本思路是求出指标的熵,然后根据指标熵的冗余度求权重。
当样本库中采集到足够数量和经处理后满足质量要求的样本数据,就可以根据样本的指标特征值,对样本集进行分析,得到决策树。决策树是一个类似于流程图的树状结构,以树的形式采用自上而下的方式给出分类规则[6]。决策树方法包括两个主要步骤:构建和剪枝。每个决策树都可由其分支,对该类型的对象依靠属性进行分类,在构建决策树时,一般采用基于信息熵定义的信息增益来选择内部结点的测试属性。而决策树剪枝主要是识别并消除由数据集中的噪声或异常数据所产生的分枝,以帮助改善决策树对未知类别对象分类的准确性。
当完全采用决策树方法时,由于它使用信息熵或其他的启发式信息来选择充当分支结点的属性,用几率代替概率来计算信息熵,随着树的深入构造,误差将会越来越大。因此,采用决策树的方法往往要结合其他方法,例如聚类分析、神经网络等,以减少累积误差。基本思路是先根据决策计算的结果作区段划分,然后对每一个大类别进行聚类分析,得到多个子聚类,再对每个子聚类建立一个能拟合包含所有样本的子模型。这样,就得到一种类似树状的结构——聚类树。对于基层的子聚类,当某些子聚类满足指定条件时,就可实现节点的合并。
3 信用评估系统架构与实现
在本系统中将采用分布式计算、离线更新模式。首先进行训练数据采集,再对数据进行整理、清洗,使数据标准化,并通过训练构建模型的离线更新,最后通过在线加载模型进行预测。后端机器学习子系统中涉及大数据的部分计算量较大、实时性要求较低,独立运行不会影响到在线子系统的运作。系统架构示意图如图1、图2所示。

图1 移动用户信用评估系统数据流程图
信用评估接口将从基础数据模块获取待评估用户的基础数据,然后调用决策引擎进行评估。决策引擎根据策略,将不定时地从已有的决策模型库加载决策模型以进行预测。分析维度框架包括通信行为、行为偏好、身份特征等指标体系,并使用聚类分析、决策树、关联分析等方法进行数据挖掘与建模。在离线部分,数据采集模块定期从数据库采集增量数据进行标准化,然后训练、更新模型。
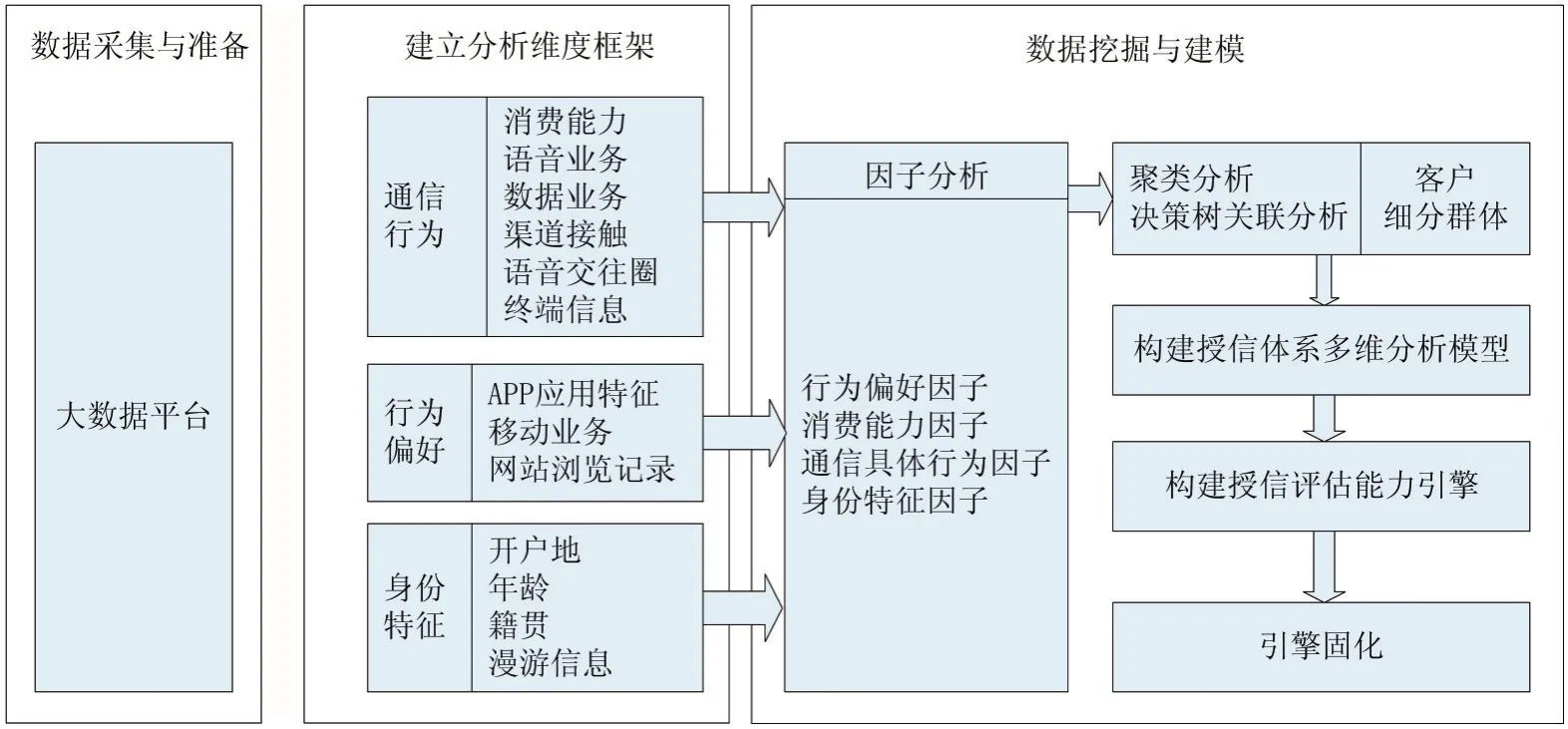
图2 移动用户信用评估系统模块图

图3 MLlib算法库
系统决策引擎采用Apache Spark MLlib[7-8]作为核心框架。Apache Spark是一个开源集群运算框架,由加州大学柏克利分校AMPLab所开发。Apache Spark允许将数据加载至集群内存,并多次对其进行查询,非常适合用于机器学习算法。Apache Spark MLlib是一种基于Spark的高效、快速、可扩展的分布式计算框架,它实现了常用的机器学习,如:聚类、分类、回归等算法。MLlib算法库核心如图3所示。
信用评估接口管理接入平台和移动用户信用历史,接入平台通过Web Service接口获得移动用户信用值,用户可以通过多种渠道,例如公众号、App等查看自己的信用值。
4 结语
本文给出了基于移动用户消费行为数据的征信评估系统的设计思路,先提取用户的特征指标体系,通过决策引擎根据需要调用信用评估方法,如决策树、聚类分析等,利用Apache Spark MLlib算法库实现高效、快速的分布式计算。该系统充分利用了运营商大数据的优势,可以高效、灵活、准确地完成用户信用评估与预测。实践表明,经过一定时期的训练及试运行后,系统计算的准确率可达到80%以上,具备一定的实用性。
[1]徐鑫.大数据征信“大有可为”[J].上海信息化,2016,10:29-33.
[2]张健华.互联网征信发展与监管[J].中国金融,2015,01:40-42.
[3]人民银行石家庄中心支行征信管理处课题组,刘旭,赵玉清.大数据环境下互联网征信发展与监管研究[J].河北金融,2016,04:3-8.
[4]邓舒仁.关于互联网征信发展与监管的思考[J].征信,2015,01:14-17.
[5]赖辉,帅理,周宗放.个人信贷客户信用评估的一种新方法[J].技术经济,2014,33(9):97-103.
[6]王昱.基于组合分类的消费者信用评估[J].管理工程学报,2015,29(1):30-38.
[7]葛继科,赵永进,王振华,等.数据挖掘技术在个人信用评估模型中的应用[J].计算机技术与发展,2006,16(12):172-174.
[8]Apache Spark.Spark文档[EB/OL].[2017-04-14].http://spark.apache.org/docs/latest/.
[9]宁永恒.基于Spark的若干数据挖掘技术研究[D].杭州:计算机应用技术,2016.
Research on the Design and Development of Credit Evaluation System for Mobile Communication Customers
HUANG Ying-chi1,ZHENG Ting-ting2
(1.China Mobile Guangdong Digital Research Center,Guangzhou 510623;2.The Open University of Guangdong,Guangzhou 510091)
The advantages of data resources of telecommunications operators bring new opportunities for the development of credit evaluation system.Establishes the index system of consumers,uses the existing credit evaluation model,and uses Apache Spark to realize the decision engine.After the procedure of date acquisition,data standardization,and data training,improves the accuracy of the calculation.The results are provided by Web Service,and users can realize the rapid calculation of querying personal credit value through a variety of ways.
黄英持(1983-),男,广东江门人,硕士研究生,从事领域为大数据创新产品研发工作
2017-06-02
2017-06-10
1007-1423(2017)17-0081-04
10.3969/j.issn.1007-1423.2017.17.017
郑婷婷(1984-),女,广东湛江人,硕士研究生,讲师,研究方向为移动应用技术、大数据技术
Credit Evaluation;Index System;Decision Tree;Apache Spark
