基于领域自适应语言模型的机器翻译
2017-07-18
(东莞理工学院城市学院,广东 东莞 523419)
机器翻译[1]是自然语言处理领域具有挑战性的任务。统计机器翻译在大规模的双语语料库上训练统计模型,使其能自动翻译源语言到目标译文。语言模型则通过计算目标句子的概率来帮助翻译系统评价翻译结果是否流畅。基于KN平滑的语言模型[2]是统计机器翻译里应用最为广泛的语言模型。常用的语言模型工具SRILM[3]和KenLM[4]都实现了修改后的KN平滑模型[2]。
当前主流的翻译系统[5-6]在同领域的大规模平行语料训练下,翻译同领域的文本的质量会很高。但是对于某些领域获取一定规模的双语语料是非常困难的,甚至大规模的单语语料也并不容易。在这种情况下,跨领域的文本上的翻译结果就不是很理想。另一方面,即使训练数据再大,也很难克服跨领域数据稀疏问题。由于目标数据的缺失,语言模型就不能使用目标数据的信息。比如目前流行的基于KN平滑的语言模型,在训练集上训练折扣平滑的参数,这样的语言模型也就很难仅仅通过训练集数据来准确地预测跨领域的目标测试数据。研究领域自适应的翻译模型和语言模型是解决这些问题一种可行的解决方法。
面对这些问题,本文提出了一种应用于机器翻译系统的基于领域自适应的语言模型。该语言模型通过一个参数调节步骤来适应不同的领域。该模型在大规模的训练集数据上训练出基本模型,然后通过目标领域的开发集数据来调整模型的折扣参数。另外,本文的语言模型还可以和一个小规模的领域语言模型进行线性插值。模型里所有参数调节的目标都为了使语言模型在目标领域开发集上的困惑度最小化。最后本文实现了这一新的语言模型并应用于标准的机器翻译过程。同时,本文提出了基于领域语言模型来断定测试数据领域并自动选取目标领域语言模型的方法,利用该方法,可以自动完成上面提到的语言模型的线性插值。
在实验里,把该领域自适应语言模型和知名的SRILM中的广泛使用的KN平滑模型进行了比较。在同一领域数据里,本文的模型比KN平滑模型有更小的困惑度。在跨领域的数据下,该模型的困惑度与KN平滑模型比与有显著的降低。在中文到英文的翻译任务里,用Moses[7]框架下基于短语[5]和基于层次短语[6]的翻译模型来评测该语言模型。机器翻译的结果显示本文的模型与KN平滑基线模型相比,显著提高了翻译质量。这一提高在跨领域的情况下表现明显。
一、语言模型
这一部分将回顾分析相关的语言模型并提出我们的模型。本文中的符号标记都在表1中列出。

表1 符号标记
语言模型是通过统计向字符串赋予概率的方法[8]。机器翻译中的语言模型可以通过句子概率判断哪个译文更符合语法。最大似然估计(MLE)概率模型是最直接的方法,它可以简单地利用训练语料中的相对频率来预测概率。但是,对于训练语料中未出现的词,这个模型就会得到0概率。解决未知元素带来的0概率问题有回退、折扣等平滑方法。通过减少已经观察到的事件的概率,来把少量概率分配给未出现事件上的方法就是折扣法。Ney等提出的绝对折扣模型[8]就是在所有非0的MLE频率上使用一个较小的常数折扣,这样留出概率分配到未知事件上。Chen和Goodman提出的修改后的KN平滑模型[2]则用一个函数,作为折扣参数。函数见式(1),它根据不同的n元组的词频,有三个不同的折扣值D1、D2和D3,针对不同的n元组模型就有n×3个折扣值。比如,如果要训练一个5元的语言模型,这样就需要15个折扣参数。这些折扣参数都是在训练集上训练出来的常数。模型所有的参数都在训练集上训练,用该模型来预测测试集上的数据,带来的缺点就是不能很好地适应跨领域数据。
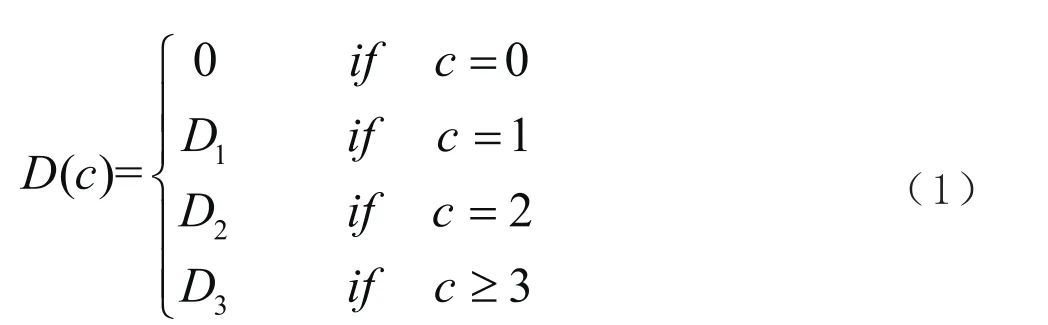
Schütze[9]在基于类插值[10-11]的POLO模型里提出了一种多项式折扣[9]方法。Guo等把这种多项式折扣应用到更简单的n元模型里,提出一种可调的语言模型[10]。在这个模型里,多项式替换了KN平滑的折扣函数,其中的参数ρ和γ都需要在开发集上进行优化。这样的一个优化的步骤就使折扣函数能够更好地适应不同的领域。
然而,这种可调模型[10]针对不同的n元组(一元组、二元组、三元组和n元组),只有一个折扣函数,而且这个函数的两个参数在任何元组条件下都相同。考虑到不同的n元组,语言模型应该用不同折扣能更准确的预测。比如原始的KN平滑模型对不同的n元组都有不同的折扣。为了同时应用多项式折扣和KN平滑折扣的优点,对于不同的词频情况,在KN平滑折扣上添加不同的可调折扣和多项式折扣。这样,提出了一种混合两种折扣的方法。本文用折扣函数如(2)式所示,替换了KN平滑模型的折扣函数
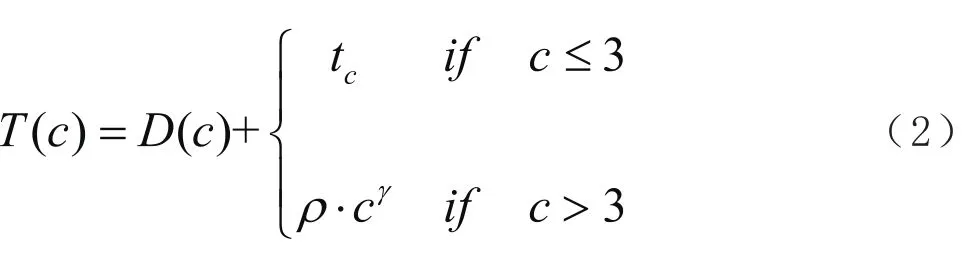
这个模型是一个可调折扣参数的递归模型,同时用回退法来做平滑。模型里所有的参数都在开发集上优化并采用启发式的网格搜索方法来搜索优化的参数。

为了保证语言模型的概率分布和为1,设置模型中参数如(4)式所示:

本文在SRILM工具里实现了该模型,并生成ARPA格式的n元语言模型[3]。
二、实验
(一)实验设置
在语言模型实验中,采用了语言模型训练工具SRILM,在大约8百万的MultiUN[15]英文数据上,用KN平滑模型训练出5元的ARPA格式的语言模型。在SRILM上修改并实现了TPKN模型,并用与KN平滑模型相同的MultiUN数据来训练该语言模型。前面已经提到,该模型还将在一个小的开发集上调整折扣参数。在启发式的网格搜索优化折扣参数过程中,搜索空间里设置步长为0.01。实验评测的方法是困惑度[13],这是度量语言模型的表现标准方法,更低的困惑度意味着更好的语言模型。
机器翻译实验采用统计机器翻译Moses[7]框架。Moses支持基于短语的翻译模型[16]和基于层次短语的翻译模型[17]。它支持SRILM生成的ARPA格式的语言模型。中文句子全部使用斯坦福的分词系统[18]进行处理。同时利用GIZA++在双语料上获得双向词汇对齐,并使用Grow-Diag-Final的启发式方法进行对称融合,多对多的词语对齐。经过句子长度过滤,翻译模型在大约1.8百万对双语料上训练。机器翻译结果采用BLEU[14]值来评测测试集上的翻译质量。
(二)语料
本文采用了句子对齐的MultiUN[15]语料中的一个版本作为训练集。该语料是从联合国2000年到2009年间的官方文件中抽取的多语言平行语料。该语料包含联合国6种官方语言,每种语言有300多万字。其中中文到英语的部分于2011年8月在IWSLT上发布。实验中使用了其中的2百万行中文到英文的双语料句子作为训练集。
评测的数据主要采用的是NIST评测集数据,具体用NIST2002、2004、2006的数据作为开发集,同时使用了NIST2005作为测试集。NIST由LDC收集,语料包含了新闻、口语广播新闻、等网络挖掘数据。NIST的数据从文件样式和语言上都不同于MultiUN的官方文件。所以MultiUN和NIST数据属于不同的领域。同时,使用了来自NIST2009年到2014年大约15 000句的领域数据,用于领域语言模型的训练。很明显,这些NIST数据和测试集是属于同一领域。有了这些领域数据就能把本文的语言模型和这个从领域数据训练出来的语言模型进行插值。
三、实验结果及分析
下面分别来讨论三组实验过程和结果。它们显示了本文提出的语言模型在跨领域数据上的表现和在跨领域机器翻译系统中的应用。
(一)语言模型的困惑度实验
第一个实验研究不同语言模型在跨领域数据上的困惑度表现。为了便于比较,同时展示了在同领域数据上的结果。实验过程为:在训练集上训练模型,并在不同领域的开发集和测试集上评测语言模型的困惑度。
在同领域数据的实验中,训练集、开发集、测试集都来自于MultiUN的英文部分。训练集有2百万句,开发集和测试集都有2千句。所有语言模型的困惑度都在开发集和测试集上计算。
在跨领域数据的实验中采用8.8百万句的MultiUN的英文部分语料作为训练集。前面提到,实验用NIST2002、04、06英文部分做开发集,用NIST2005做测试集来评测结果。
所有模型的表现如表2所示。本文的基线系统是SRILM工具集提供的修改后的KN平滑模型。在同领域的情况下,和基线相比较,可以发现困惑度在开发集上有所降低(从54.55到52.50)。同样在测试集上的困惑度也有所降低,从60.64到58.34。这些结果显示TPKN语言模型的表现即使在同领域情况下也有所提升。
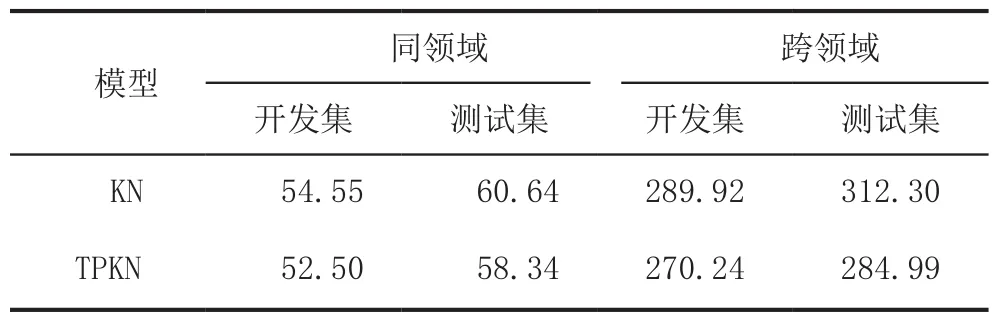
表2 语言模型的困惑度
当把同领域和跨领域的表现进行对比时,很快发现困惑度从50多提高到了270多。这显示出NIST数据的领域非常不同于训练数据。比较各模型在跨领域的数据上的表现,本文模型的困惑度,能够在很大程度上的降低。模型的困惑度从289.92(KN)下降到270.24(TPKN)。这个结果在测试集上也有同样的表现,模型的困惑度从312.30(KN)降低到284.99(TPKN)。开发集、测试集的困惑度比较相似是因为NIST数据集的领域是相似的。
综上,困惑度的实验表明TPKN模型在同领域的数据上表现比KN平滑模型要好。在跨领域的情况下,TPKN模型有更显著的表现。
(二)跨领域的机器翻译实验
在困惑度实验之后,进一步将这些语言模型应用到“中文-英文”的翻译任务里。这里使用Moses框架下的基于短语的翻译模型和基于层次短语的翻译模型。不同的翻译系统都采用BLEU自动评测。
在翻译实验中,使用了大概两百万来自于MultiUN的中英文双语料作为训练集。在本实验中,仍使用上一实验中相同的开发集和测试集,只是这里同时使用中文部分的数据。在这个实验里开发集,同时作为Moses框架下的Tuning集。实验用BLEU来评价所有的翻译质量。
试验结果的BLEU值如表3所示。在同领域的机器翻译实验里,所有模型的BLEU值都高于30。这样好的翻译结果验证了机器翻译系统翻译同领域的文本质量较高。在同领域的机器翻译实验里,能发现TPKN模型比基线模型在两种翻译模型的情况下的结果都要好。TPKN模型在基于短语的翻译系统(PBMT)里从31.32(KN)提高到了31.43(TPKN)。在基于层次短语的翻译系统(HPBMT)里从34.30(KN)提高到了34.87(TPKN)。这个结果也验证了在中英文的翻译系统中基于层次短语的翻译模型比基于短语的翻译模型的翻译质量要提高[6]。
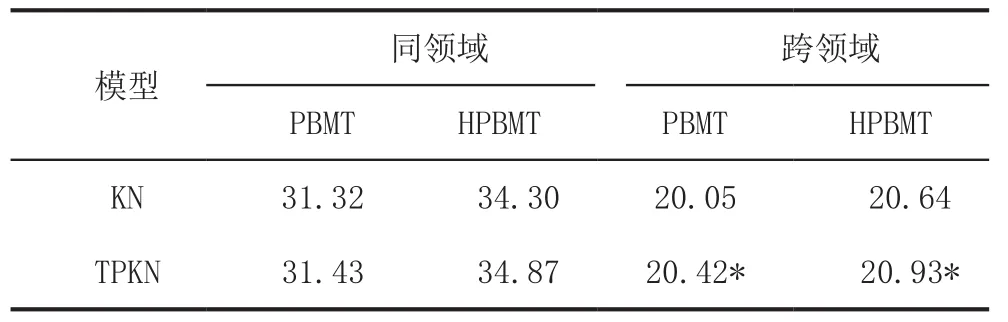
表3 同领域跨领域机器翻译BLEU值
跨领域的机器翻译结果与同领域表现相比,能很快发现BLEU值从30多下降到20多。上文提到,训练集与测试集都来自于相同的语料(MultiUN),机器翻译系统就能取得比较好的结果。但是,当训练集与测试集来自不同的领域时,翻译质量就会下降。比如本实验中训练集与测试集分别来自MultiUN和NIST,也就是实验里BLEU值降低的原因。另外,即使是再大的训练集也很难克服跨领域的数据稀疏的问题。这些现象表明在没有足够多同领域训练数据的情况下,研究自适应模型提高跨领域翻译质量的重要性。
在跨领域数据的实验中,发现TPKN模型始终在两种翻译模型下能表现良好。翻译质量都取得了显著的提高,TPKN模型在基于短语的翻译系统里从20.05(KN)提高到了20.42(TPKN)。在基于层次短语的翻译系统里从20.64(KN)提高到了20.93(TPKN)。表3中“*”号表示这些显著提高的置信水平为95%。
综上所述,以上实验结果表明TPKN模型和基线KN平滑模型相比,不管是困惑度还是翻译任务的评测都有更优的结果。在跨领域的情况下,表现显著提高。
(三)领域插值语言模型的机器翻译
解决领域自适应问题的另一个方法是将现有模型与在目标领域数据上训练的语言模型进行插值。这个混合模型的插值权重可以在开发集上调整。这种方法会使用到跨领域数据信息,这样也能提高模型质量。当然,要想在目标领域上训练模型,这就需要补充跨领域的训练数据。
这个实验里使用了少量的目标领域训练数据,这些数据来自于NIST2009-14。这些NIST数据和目标测试数据都来自相同的领域。同时,本实验的开发集和测试集都与前面的实验一致。所有的语言模型与前面的实验一样在大的训练集MultiUN上训练。同时在NIST2009-14这个小的目标领域数据集上训练了另一个语言模型。最后,将大的语言模型和这个小的领域语言模型混合。混合语言模型的权重通过在开发集上模型的困惑的最小化来优化。有了优化的插值权重参数,我们将这个混合插值模型在测试集上进行评测。因为这个目标领域训练数据比较小,就简单地用KN平滑模型来训练这个领域语言模型。最后将训练出的混合模型应用到机器翻译系统中进行评测,实验中Moses的设置和先前的实验是一致的。这样就可以研究不同的插值模型在跨领域的机器翻译里的表现。
翻译的结果如表4所示。为了比较插值模型和前面的未插值的模型,把前面未插值模型的结果也放到了表4的上面两行里。从表里的BLEU值,能发现插值的语言模型(+domain表示原始模型与领域模型插值后的混合模型)比没有使用领域数据的原始模型的翻译质量更高。KN插值模型在基于短语的翻译系统里的BLEU值从原始的KN平滑模型的20.05提高到20.50。KN插值模型同样在基于层次短语的翻译系统里,BLEU值从20.64提高到了20.87。TPKN插值模型同样比原始的TPKN模型的翻译质量要提高。在基于短语的翻译系统里从20.42提高到了20.60。在基于层次短语的翻译系统里从20.93提高到了20.98。这些提高并不是显著的。然而,它仍然比其他所有模型的质量都好,同时和基线模型比仍然是显著的提高(*表示翻译结果BLEU值显著提高)。这里置信水平为95%。

表4 跨领域机器翻译BLEU值
把原始的未与领域模型插值的TPKN模型和KN插值的模型相比,能发现原始的TPKN和插值的KN模型结果很接近。甚至在基于层次短语的翻译模型下,TPKN模型的BLEU值20.93比KN插值模型(20.87)要高。TPKN模型翻译质量并没有提升很多,但是在没有领域数据的情况下,能略高于KN插值模型的翻译质量,这个结果更能说明TPKN模型在跨领域数据下表现出来的领域自适应性。
综上,这个实验结果表明基于少量的目标领域数据的插值模型能够一定程度上提高语言模型在跨领域数据上的表现。插值的TPKN模型仍然比KN的插值模型表现要好。与所有的插值的模型相比,原始TPKN模型在没有领域数据的情况下也有较好的表现。
(四)机器翻译中领域的判定
机器翻译模型要想将领域自适应方法自动应用到系统中,首先需要解决领域的判定问题。比如Google翻译中能先自动判断用户所输入的语言。如果翻译系统也能像检测输入语言一样来判断用户输入的领域,并自动选择目标语言模型,将有助于翻译系统准确率的提高。
为此,本文提出了基于语言模型判定源语言领域的方法。验证实验选取了不同领域的小规模的双语开发集和测试集。在源语言中,在开发集上训练出小规模的语言模型,用这些语言模型来计算测试集的困惑度,然后利用困惑度的分布来判断该源语言属于哪个领域。最后,机器翻译系统就可以自动的使用该领域平行的目标语言开发集来作为TPKN模型的参数估计开发集或者领域插值语言模型的训练集。
验证实验选取6个不同领域的数据进测试,其领域包含生物(Bio)、食物(Food)、新闻(News)、半导体(Semi)、社交媒体(Social)、网络新闻(Web)这些领域。语料取自于标准的中英文机器翻译系统的开发集和测试集,其大小大致为2千行左右的语料。实验把中文作为源语言。在中文的开发集中用SRILM工具集训练5-gram的语言模型。用该语言模型(LM),在中文的测试集(Tst)上计算各个领域的困惑度。得到困惑度分布如表5。
表5可以比较到各个不同领域开发集训练的语言模型在不同领域测试集上的困惑度。比如第一行是用生物领域开发集训练出的语言模型,在生物(Bio)、食物(Food)、新闻(News)等不同领域下测试集的困惑度。可以发现在生物领域测试集上的困惑度(340.6)明显小于其他领域的困惑度(从2403.8到6155.5)。同样,后面几行里困惑度最低的情况都是当开发集和测试集属于相同领域(如表5中加粗数据所示)。这个结果表明最小的困惑度,意味着最匹配的领域。这样,就可以用不同领域的开发集训练的语言模型的最小的困惑度来判定测试集的领域归属。

表5 不同领域语言模型在不同领域测试集上的困惑度
通过源语言(中文)来判断其领域的归属,在机器翻译系统里,就可以将源语言所属领域的平行开发集作为目标语言(英文)领域插值语言模型的训练集或者TPKN模型的参数训练集。选好领域,并自动训练出领域适应的语言模型。这样进行上文所提到的领域插值的机器翻译,从而最终提高机器翻译的翻译质量。
四、结论
本文提出了一个领域自适应语言模型TPKN,它能够通过调整折扣参数自适应到目标领域,还可以与领域语言模型进行插值。同时本文提出了一种基于领域语言模型自动判定测试集领域并自动选取目标领域的方法。实验表明本基于TPKN模型的翻译系统,困惑度下降,BLEU评测值显著提高。比基线KN模型的表现更好,特别是在跨领域的情况下表现更优。
下一步工作,计划进一步改进参数优化算法,完善机器翻译系统的自动化程度,并且将模型应用到其他语言和自然语言处理中去。
