基于变量概率信息的因子分析监控方法
2017-07-18胡婷婷王帆侍洪波
胡婷婷,王帆,侍洪波
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
基于变量概率信息的因子分析监控方法
胡婷婷,王帆,侍洪波
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
因子分析(factor analysis,FA)将噪声因素加入到建模过程中,可通过最大期望(expectation maximum,EM)算法建立模型。传统的 FA(ST)指标仅利用了变量的期望信息而忽略了更能代表不确定性的方差信息,这可能会导致故障的漏报。通过对过程变量的概率分析,从本质上揭示了FA(ST)的这一缺陷。建模过程中的另一个重要因素是确定因子个数,使得在降维的同时能最大程度地保留对过程有用的信息。针对传统监控指标信息不足的问题,提出的负对数似然概率(negative log likelihood probability,NLLP)指标整合了更全面的概率信息;针对因子个数给定的问题,提出了一种整体-局部因子数确定法,使得因子和变量对于过程的信息解释率都达到收敛。最后通过数值例子和Tennessee Eastman(TE)过程验证了所提方法的有效性和优越性。
因子分析;参数估计;过程控制;信息解释率;统计分析
引 言
过程监控对于提高工业生产过程的安全性和稳定性具有重要的意义[1]。分散控制系统(distributed control system,DCS)技术的发展促进了生产过程数据的采集和存储[2-3],多元统计过程监控(multivariate statistical process monitoring,MSPM)方法可以从具有高维度、强耦合等特性的大量数据中挖掘出有利于过程监控的信息[3-5]。目前应用最广泛的MSPM方法如主元分析(principal component analysis,PCA)方法[6-10]是在主元空间和残差空间分别建立统计量,而二者的量度不同,往往会造成监控结果不一致的问题[11-13]。另一方面,环境噪声等非确定性因素是客观存在的,忽略噪声因素而建立的模型是不准确的。概率潜变量生成模型可以同时解决这两个问题。概率主元分析(probabilistic principle component analysis,PPCA)[13]和因子分析[14]是两种噪声条件假设下的概率潜变量模型,其中FA释放了PPCA中噪声各向同性的约束,更符合实际工况,应用于过程监控领域可取得较 PPCA更好的效果。由于生成模型的特点可以使用一个综合指标来进行过程监控,从而避免了监控结果不一致的缺陷[15]。Ge等[16]将ICA与FA结合来处理含有非高斯成分变量的过程,介绍了一种具有新型相似因子的ICA-FA监控方法。文献[17]在FA的基础上,提出了极大似然混合因子分析模型(MLMFA)以解决噪声因素、非高斯成分和多模态问题。文献[18]在混合因子分析(MFA)的基础上,提出了一种直接极大似然估计方法。Zhao等[19]在FA框架的基础上,从过程数据的内在特性和数据丢失现象出发,说明了方差信息对于过程监控的必要性。然而以上列举方法中的监控统计量仅仅利用了变量的期望信息,而更能代表非确定性的方差信息却被忽略了。
用EM算法建立FA模型时,需给定因子数,目前确定因子数的方法[11,20-23]中应用最多的是基于信息解释率的方法,但是这些方法只能从整体或者局部上保证方差贡献度达到收敛。MSPM过程包含了各种量纲不一致的变量,且这些变量之间存在着某种联系,使得整体解释率和单个变量解释率之间存在不对等的关系,然而整体的信息解释率并不能理解为单个变量解释率的简单叠加,这种联系必然与整个系统的结构和功能等有关。为确保整体和变量的信息解释率都达到收敛,本文介绍了一种基于FA模型的可自动确定因子数的整体-局部因子数确定法。此外,本文从本质上证明了传统的FA(ST)指标只包含变量的期望信息而忽略了更能代表不确定性的方差信息,为了克服这一不足,本文利用增加了变量方差信息的 NLLP[24]来构造监控统计量。由于NLLP是过程变量概率分布的函数,因此其包含了更全面的概率信息,且只用一个监控量可以避免多监控图监控结果不一致的问题,其监控控制限用核密度估计(kernel density estimation, KDE)得到。最后,通过两个仿真验证了本文所提算法的有效性。
1 基于FA(NLLP)模型的过程监控
设经过归一化预处理后的过程观测数据x ∈ℜd×n,其中d为过程变量个数,n为样本观测数,生成模型将x看成是由不相关的因子z的线性组合外加服从一定高斯分布的噪声变量e组合而成[12],该生成模型认为因子z是输入,观测变量x是输出,即

其中,A∈ℜd×m为载荷矩阵,m<d为主元个数,z∈ℜm,e ∈ℜd,同时假设z~N(0,I),e ~N(0,Ψ),则x~N(0,C),C=AAT+Ψ,其中Ψ=diag(λ1,λ2,…,λd)为噪声协方差矩阵。若λ1=λ2=…=λd,则 FA退化成 PPCA;当λ1=λ2=…=λd≈0时,PPCA 就退化成 PCA[19],因此FA的限制条件更少,更能反映过程数据的本质特性。
1.1 因子数的确定
为了建立精确的FA模型,需合理地选择因子数,利用因子数增加到一定程度时信息解释率收敛的性质[11],本文提出整体-局部的因子数选取法,保证整体解释率和单个变量解释率都达到收敛。
因子数选取步骤如下。
(1)根据文献[25]可确定因子数m的上限m0

(2)计算因子数l取不同值时的整体解释率per1(l)

其中,Al和Ψl为不同l值下的由EM算法估计出的参数值,为因子数为l时的所有变量的总信息,为当前因子数所包含的信息,tr()为求迹算子。
(3)计算整体解释率的增长值rep1(l)

(4)判断整体解释率的收敛性,确定整体解释率达到收敛的因子数m1

其中,为足够小的数。判断式(5)是否成立,选择式(5)成立时的最小因子数l为m1。
(5)计算因子数l取不同值时对变量i的解释率per2(l,i)

式中,diag()i表示取矩阵对角线上第i 个元素。
(6)计算每个变量解释率的增长值rep2(l,i);
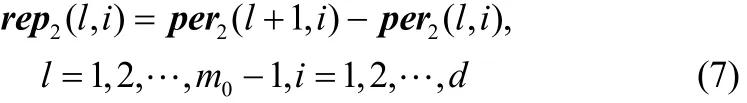
(7)判断每个变量解释率的收敛性,确定每个变量解释率都达到收敛的因子数m2

式中,li表示第 i个变量解释率达到收敛时的最小因子数。
(8)确定综合因子数m

需要说明的是,步骤(2)~步骤(4)为计算整体信息解释率过程,步骤(5)~步骤(7)为计算局部信息解释率过程,这两部分没有先后顺序之分,实际操作时同时进行。
1.2 FA概率生成模型的建立
由式(1)可知,给定因子数m后,该FA模型就由A和Ψ决定。对这些参数的估计可通过最大化测量值的似然函数来确定,但是直接进行极大似然计算存在困难,因为A和Ψ都与因子z有关,而z又是未知的,能得到的仅是观测数据 x,EM 算法将因子z视为遗失变量,利用完整数据集(x, z)来进行参数估计,以期实现参数的极大似然估计[14,18-19]。EM算法一般分为E步(求期望)和M步(最大化),具体计算公式见文献[14]。
1.3 监控指标的确定
1.3.1 过程变量的概率分析 根据概率生成模型,可以推导出过程变量x在第i个采样时刻的期望和方差

其中,β=ATC-1,E[·]和分别表示·的期望和方差。由式(11)和式(12)可以看出,过程变量的方差在任意采样时刻都保持恒定,而期望与采样时刻有关,是随着观测值变化的。
1.3.2 基于过程变量的综合监控指标 由历史正常数据离线建立好FA模型后,可以直接用一个综合指标ST实现对过程的在线监测。ST统计量的定义如下[11]

其中,ST服从自由度为d的χ2分布,控制限(d)表示χ2分布χ2(d)的上侧分位数,为置信度。从式(13)可知 ST是过程变量对其空间中心马氏距离的检验,但公式中仅仅利用了过程变量观测值的在线期望,而不随观测值变化的方差信息却被忽略了。在线监测时,即使实际过程变量的方差因为故障的发生而导致变化了,由于 ST本身的缺陷使得故障数据的特征仍符合正常模型,这可能会造成更多的漏报。
1.3.3 基于NLLP的监控指标 基于以上的讨论,为了获得更好的监控性能,除了利用变量的期望信息外,还需要将方差信息也加入到监控指标的构建中,本文使用NLLP作为监控统计量。对于一个给定的FA模型,NLLP衡量了新测试样本与FA模型之间概率分布的匹配程度。当故障发生时,故障样本的NLLP值会明显高于正常点的NLLP值,NLLP定义为
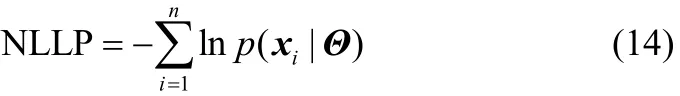

从NLLP的定义式(14)可以看出,NLLP是关于观测变量x的概率分布的函数,其必然同时包含期望和方差信息,可检测出导致变量期望和方差变化的故障。相较于ST,NLLP包含更全面的过程变量概率信息,能更有效地检测故障的发生。
1.4 算法步骤
基于 FA(NLLP)算法的过程监控方法具体步骤如下。
(1)对正常样本数据集进行归一化预处理;
(2)由式(2)~式(10)确定因子数m;
(3)用EM算法建立FA模型;
(4)计算正常样本的NLLP并用KDE估算控制限limNLLP(α);
(5)对新的测试数据集进行归一化预处理;
(6)计算测试数据的 NLLP值,判断其是否超过控制限。
其中,步骤(1)~步骤(4)为离线建模过程,步骤(5)~步骤(6)为在线监测过程。
2 仿真实验
本节将进行以下两个例子的仿真以验证本文所提算法的有效性,一个是数值例子,另一个是Tennessee Eastman(TE)过程。为了比较结果的公平性,因子数的选取方法均采用本文提出的整体-局部确定法,将FA(ST)和FA(NLLP)仿真结果进行对比。
2.1 数值仿真
为了说明方差信息对于过程监控的必要性,Zhao等[19]提出了一个数据结构模型,本节将采用这一模型来验证本文所提方法的有效性。具体模型结构如下
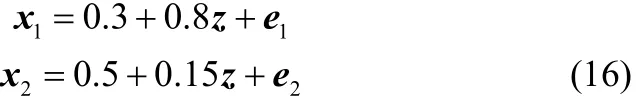
其中,z ~N(0,0.4),过程噪声e1和e2都服从N(0,0.1)。很显然,这两个变量的过程仅含有一个因子,由结构式(16)产生的1000个正常训练样本用于建立FA模型。故障数据的产生通过在过程变量上施加如下故障

其中,h和Ξ分别表示故障幅度和方向。假设Ξ是A的第1列,h=1.8。故障在第51个采样点处加入,共采集100个测试样本,前50个样本为正常样本,后50个样本为故障样本。分别用ST和NLLP作监控统计量,其控制限分别由χ2(d)分布和 KDE确定,取99%置信度。表1列出了这两种方法的误报率和漏报率,监控图如图1所示。
显然该故障导致了变量方差的变化,由图1可以看出,虽然 FA(ST)能迅速地检测到故障的发生,但是在故障持续期间仍有很多采样点的 ST值落到了控制限以下,造成了高的漏报,从表1的数据可以看出FA(ST)的漏报率高达46%。相比而言,FA(NLLP)的漏报率降低到4%,从图1的部分放大图可以看出,只有第57和第78个点的NLLP值落到控制限以下,这说明 FA(NLLP)能更有效地检测出故障。

表1 数值例子的误报率和漏报率Table 1 Fault alarm rate and miss alarm ratein numerical example
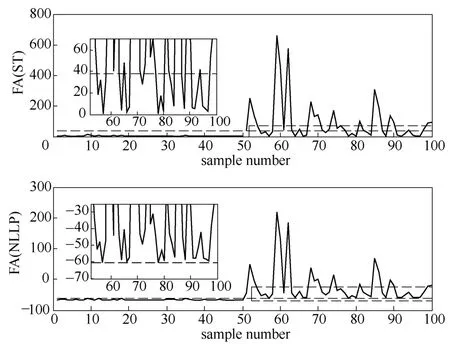
图1 FA(ST)和FA(NLLP)对数值例子的监控结果Fig 1 Monitoring result of FA(ST) and FA(NLLP) methods in numerical example
2.2 TE过程仿真
TE过程[28-29]是一个复杂的多变量化工反应过程,已经被广泛地用于评价MSPM方法的有效性。TE过程共有41个测量变量(22个连续过程测量变量和19个非连续过程测量变量)和12个控制变量。在仿真过程中,控制变量5、9和12保持不变,因此本节选取剩下的9个控制变量和22个连续过程测量变量进行仿真实验。TE过程运行一次的时间为48h,采样间隔 3min,因此运行一次能采集到 960组数据。TE过程预设21种故障,每一种故障都在480min后开始加入,即故障数据从第161次采样开始产生,这样就得到了21种故障类型的960组测试数据,其中故障3、9、15的测试数据在均值、方差上没有明显的变化,所以统计方法的故障监测率都很低[6],本节不对这3种故障进行分析。
本节的TE过程中n=960,d=31,根据式(2)计算因子数的上限m0=23。用EM算法分别估算出因子数从1~23的FA模型参数 A和Ψ,根据式(3)计算出不同因子数下的信息解释率,如图 2所示。
根据式(4)和式(5)确定m1=14。由图2也可以看出,因子数达到14及以上时,整体解释率收敛并达到了 95%以上。根据式(6)计算出不同因子数下每个变量的信息解释率,如图3所示。
根据式(7)~式(9)确定出m2=18。由图3可以看出,因子数达到18及以上时,每个变量的解释率都收敛到70%以上。最终选取的因子数确定为m=18。需要说明的是,计算不同因子数下的 FA模型参数时都要通过EM算法,由于EM算法是局部最优算法,使得解释率曲线会出现波动的情况,但总体趋势是上升收敛的[30]。另外每次得到的m1和m2的值会在一定小范围内波动且相对大小也会不同,即因子数m会有不同,但总能保证在该因子数下的总体和局部信息解释率都达到收敛。

图2 不同因子数下的整体信息解释率Fig.2 Global information explanation ratio under different numbers of factors

图3 不同因子数下的每个变量的信息解释率Fig.3 Variable information explanation ratio under different numbers of factors
确定好因子数m后,利用EM算法获得该因子数下的FA模型参数的估计值,用NLLP建立统计量,取0.99置信度,用KDE确定控制限。测试数据由48 h采集到的960个采样点组成,其中前160个为正常样本,后800个为故障样本点,这样的数据大小和规格被普遍应用于比较算法性能,从而保证了算法比较的公平性。表2列出了PPCA(NLLP)、FA(ST)和FA(NLLP)这3种方法对于TE过程的 18个故障的漏报率,黑体部分为监测结果的最佳值。

表2 TE过程故障数据的漏报率Table 2 Miss alarm rate of fault database in TE process
从表2的监控效果数据可以看出,基于FA模型的监控性能要优于基于PPCA的监控性能,而FA(NLLP)的故障监测性能最佳。对比FA(NLLP)与PPCA(NLLP),故障5和10的漏报率分别减少了47.875%和43%,这两种方法对故障5的监测图如图4所示,其他故障类型(故障11、16、17、19、20和 21)的故障检测率也有明显的提高,这说明FA模型的约束条件更少,更符合实际过程的本质特性,监控性能更好。
对比FA(NLLP)与FA(ST),对于故障1、4、5、6、7和14,这些故障的发生造成了过程数据期望的明显变化,所以这两种方法的故障检测率都达到了100%。此外,这两种方法对故障2、8、12的漏报率都在2%以内,且FA(NLLP)的故障漏报率都略好于FA(ST)。对于其他的故障类型,如故障10、11、16、19、21,FA(NLLP)的监控性能较FA(ST)提高得较明显,其中故障16的FA(NLLP)性能提高了10.375%,其他故障的FA(NLLP)性能都提高了5%左右。从整体上来看,FA(NLLP)的故障监测效果最佳,这是因为NLLP统计量作为概率分布的函数,包含了变量的期望和方差信息,监测性能要优于比只包含了期望信息的ST统计量。

图4 故障5的监测结果图Fig 4 Monitoring result of PPCA(NLLP) and FA(NLLP) for fault 5
3 结 论
在FA模型的基础上,本文提出了一种可自动确定因子数的方法,同时建立了包含更全面的变量概率信息的统计量 NLLP。从因子和变量的信息解释率角度出发,本文提出的因子数确定法能保证因子和变量对于过程的信息解释率都达到收敛。相较于传统的FA(ST)指标,本文提出的NLLP统计量加入了更全面的统计信息,并通过数值例子和TE过程仿真说明了加入方差信息后的NLLP的优越性。
[1] ZHOU D H, HU Y Y. Fault diagnosis techniques for dynamic systems[J]. Acta Automatica Sinica, 2009, 35 (6): 748-758.
[2] SONG B, TAN S, SHI H B. Process monitoring via enhanced neighborhood preserving embedding [J]. Control Engineering Practice, 2016, 50: 48-56.
[3] GE Z Q, SONG Z H, GAO F R. Review of recent research on data-based process monitoring [J]. Industrial & Engineering Chemistry Research, 2013, 52 (10): 3543-3562.
[4] QIN S J. Survey on data-driven industrial process monitoring and diagnosis [J]. Annual Reviews in Control, 2012, 36 (2): 220-234.
[5] 王帆, 杨雅伟, 谭帅,等. 基于稀疏性非负矩阵分解的故障监测方法 [J]. 化工学报, 2015, 66 (5): 1798-1805.WANG F, YANG Y W, TAN S, et al. Fault detection method based on sparse non-negative matrix factorization [J]. CIESC Journal, 2015, 66(5): 1798-1805.
[6] GE Z Q, SONG Z H. Distributed PCA model for plant-wide process monitoring [J]. Industrial & Engineering Chemistry Research, 2013,52 (5): 1947-1957.
[7] JIN H D, LEE Y H, LEE G, et al. Robust recursive principal component analysis modeling for adaptive monitoring [J]. Industrial& Engineering Chemistry Research, 2006, 45 (2): 696-703.
[8] DENG X G, TIAN X M. Multiple component analysis and its application in process monitoring with prior fault data [J].IFAC-PapersOnLine, 2015, 48 (21): 1383-1388.
[9] KRUGER U, ZHOU Y Q, IRWIN G W. Improved principal component monitoring of large-scale processes [J]. Journal of Process Control, 2004, 14 (8): 879-888.
[10] WOLD S, ESBENSEN K, GELADI P. Principal component analysis[J]. Chemometrics & Intelligent Laboratory Systems, 1987, 2 (1/2/3):37-52.
[11] KIM D, LEE I B. Process monitoring based on probabilistic PCA [J].Chemometrics & Intelligent Laboratory Systems, 2003, 67 (2):109-123.
[12] TIPPING M E, BISHOP C M. Mixtures of probabilistic principal component analyzers. [J]. Neural Computation, 1997, 11 (2): 443-482.
[13] TIPPING M E, BISHOP C M. Probabilistic principal component analysis [J]. Journal of the Royal Statistical Society, 1999, 61 (3):611-622.
[14] GHAHRAMANI Z, HINTON G E. The EM algorithm for mixtures of factor analyzers [J]. University of Toronto Technical Report, 1997.
[15] GE Z Q, SONG Z H. Mixture Bayesian regularization method of PPCA for multimode process monitoring [J]. AIChE Journal, 2010,56 (11): 2838-2849.
[16] GE Z Q, LEI X, SONG Z H. A novel statistical-based monitoring approach for complex multivariate processes [J]. Industrial &Engineering Chemistry Research, 2009, 48 (10): 4892-4898.
[17] GE Z Q, SONG Z H. Maximum-likelihood mixture factor analysis model and its application for process monitoring [J]. Chemometrics &Intelligent Laboratory Systems, 2010, 102 (1): 53-61.
[18] MONTANARI A, VIROLI C. Maximum likelihood estimation of mixtures of factor analyzers [J]. Computational Statistics & Data Analysis, 2011, 55 (9): 2712-2723.
[19] ZHAO Z G, LI Q H, HUANG B, et al. Process monitoring based on factor analysis: probabilistic analysis of monitoring statistics in presence of both complete and incomplete measurements [J].Chemometrics & Intelligent Laboratory Systems, 2015, 142: 18-27.
[20] QIN S J, DUNIA R. Determining the number of principal components for best reconstruction [J]. Journal of Process Control, 2000, 10 (2/3):245-250.
[21] TAMURA M, TSUJITA S. A study on the number of principal components and sensitivity of fault detection using PCA [J]. Computers& Chemical Engineering, 2007, 31 (9): 1035-1046.
[22] VALLE S, LI W H, QIN S J. Selection of the number of principal components: the variance of the reconstruction error criterion with a comparison to other methods [J]. Industrial & Engineering Chemistry Research, 1999, 38 (11): 653-658.
[23] VIROLI C. Choosing the number of factors in independent factoranalysis model [J]. Metodološki Zvezki, 2005, 2 (2): 219-229.
[24] WANG F, TAN S, YANG Y W, et al. Hidden Markov model-based fault detection approach for a multimode process [J]. Industrial &Engineering Chemistry Research, 2016, 55 (16): 4613-4621.
[25] FEITAL T, KRUGER U, XIE L, et al. A unified statistical framework for monitoring multivariate systems with unknown source and error signals [J]. Chemometrics & Intelligent Laboratory Systems, 2010,104 (2): 223-232.
[26] CHEN Q, WYNNE R J, GOULDING P, et al. The application of principal component analysis and kernel density estimation to enhance process monitoring [J]. Control Engineering Practice, 2000,8 (5): 531-543.
[27] CHEN Q, KRUGER U, LEUNG A T. Regularised kernel density estimation for clustered process data [J]. Control Engineering Practice,2004, 12 (3): 267-274.
[28] DOWNS J J, VOGEL E F. A plant-wide industrial process control problem [J]. Computers & Chemical Engineering, 1993, 17 (3):245-255.
[29] CHIANG L H, RUSSELL E L, BRAATZ R D. Fault Detection and Diagnosis in Industrial Systems [M]. London: Springer, 2001:103-109.
[30] 赵忠盖, 刘飞. 因子分析及其在过程监控中的应用 [J]. 化工学报,2007, 58 (4): 970-974.ZHAO Z G, LIU F. Factor analysis and its application to process monitoring [J]. Journal of Chemical Industry and Engineering (China),2007, 58 (4): 970-974.
Factor analysis process monitoring method based on probabilistic information of variables
HU Tingting, WANG Fan, SHI Hongbo
(Key Laboratory of Advanced Control and Optimization for Chemical Processes of Ministry of Education, East China University of Science and Technology, Shanghai 200237, China)
Factor analysis (FA), which noise factors are taken into consideration, can establish probabilistic generative model by the expectation maximum (EM) algorithm. However, traditional FA (ST) index may lead to missed fault alarms by utilizing only expectation information of variables and ignoring variance information of variables that is more representative of uncertainty. The drawback of FA (ST) index was revealed by probabilistic analysis of process variables. Another important part in the modeling process was to determine number of factors,which could preserve most useful process information in the meantime of dimension reducing. A negative log likelihood probability (NLLP) index, which integrated more comprehensive probabilistic information, was proposed to overcome dilemma of insufficient information of traditional monitoring index. For the determination of number of factors, a novel global-local method was introduced so that information explanation ratios of global factors and variables over process information reached convergence simultaneously. Numerical simulation and Tennessee Eastman (TE) process study illustrated effectiveness and superiority of the proposed method.
factor analysis; parameter estimation; process control; information explanation ratio; statistical analysis
date: 2017-01-13.
Prof. SHI Hongbo, hbshi@ecust.edu.cn
supported by the National Natural Science Foundation of China (61374140, 61673173) and Fundamental Research Funds for the Central Universities (222201714031, 222201717006).
TP 277
A
0438—1157(2017)07—2844—07
10.11949/j.issn.0438-1157.20170057
2017-01-13收到初稿,2017-03-23收到修改稿。
联系人:侍洪波。
胡婷婷(1991—),女,硕士研究生。
国家自然科学基金项目(61374140,61673173);中央高校基本科研业务费专项资金(222201714031);中央高校基本科研业务费重点科研基地创新基金项目(222201717006)。
