一种结合众包的排序学习算法
2017-07-10王小平奚凌然
王小平 奚凌然
(同济大学电子与信息工程学院 上海 200092)
一种结合众包的排序学习算法
王小平 奚凌然
(同济大学电子与信息工程学院 上海 200092)
针对有监督排序学习所需带标记训练数据集不易获得的情况,引入众包这种新型大众网络聚集模式来完成标注工作,为解决排序学习所需大量训练数据集标注工作耗时耗力的难题提供了新的思路。首先介绍了众包标注方法,着重提出两种个人分类器模型来解决众包结果质量控制问题,同时考虑标注者能力和众包任务的难度这两个影响众包质量的因素。再基于得到的训练集使用RankingSVM进行排序学习并在微软OHSUMED数据集上衡量了该方法在NDCG@n评价准则下的性能。实验结果表明该众包标注方法能够达到95%以上的正确率,所得排序模型的性能基本和RankingSVM算法持平,从而验证了众包应用于排序学习的可行性和优越性。
排序学习 众包 众包质量控制 排序支持向量机
0 引 言
在当今大数据时代,搜索引擎是人们获取所需信息的重要手段,搜索引擎经过信息爬取、索引、搜索结果排序这几步工作最终将结果返回给用户,在这个过程中搜索结果的排序技术是结果处理的核心技术,其排序算法的性能在很大程度上影响了整个搜索引擎的效率和用户体验。传统的排序模型使用人工拟合的方式处理各种对排序产生影响的因子,但随着互联网的飞速发展,一方面排序影响因子的数量飞速增加,另一方面用户对更加精准排序结果的需求大大提高,这两方面原因促使基于机器学习的排序方法得到了业界的重视,排序学习LTR(Learning to Rank)就是这种使用机器学习的方法进行排序模型训练的新技术。作为一种监督学习方法,排序学习依赖大量有标记训练数据集,而训练数据集的标注质量、数据量大小和多样性都会对最终所得排序模型的效果产生重要的影响。若标注质量差会对排序结果造成较大的偏差,而数据量大小和多样性也会影响排序模型的泛化性能。因此,用于训练目的的数据集标注工作是制约排序学习应用效果的关键问题。而传统的训练数据集处理方式是依靠专业团队人工标注,耗时耗力,且没有充分利用查询结果之间的相关性,故LTR所需训练数据集的标注工作不仅关系到效率问题,而且影响到学习模型的性能。
众包最早由美国的Howe Jeff于2006年在《连线》杂志上提出。Howe Jeff对众包的定义为:一个公司或机构把过去由员工执行的工作任务以自由自愿的形式外包给非特定大众网络的做法[1],即众包是一种新型的大众网络聚集模式,众包项目的发起者能够以向广大互联网用户公开招标的方式将大规模众包任务分包并发给每一个众包工作者去完成。众包的优点是能够利用大众智慧去完成计算机算法难以胜任的大规模工作。众包从其被提出开始在许多领域都得到了学界和业界广泛的关注和研究,这些领域包括人机交互[2-3]、数据库[4-5]、机器学习和人工智能[6]、信息检索[7]等。众包工作流如图1所示,一个众包任务涉及众包任务发布者、众包工作者、众包平台三种角色,众包任务发布者完成任务设计并在平台上发布任务,众包工作者在平台上接受并完成众包任务,而众包平台则负责将所有众包工作成果整合并返还给众包任务发布者。众包平台的关键作用之一是采取手段对众包工作质量进行控制,发现并过滤不良工作者的工作成果以尽量提高最终众包结果的质量。众包为LTR所需大量训练数据的标注工作提供了新的解决思路。

图1 众包工作流程示意图
本文提出一种结合众包的排序学习方法,利用众包解决训练数据的标注难题。
1 基于Pairwise的排序学习模型RankingSVM
LTR使用机器学习的方法基于有标注训练数据集学习得到一个排序模型,并用该排序模型计算某查询下所有结果文档和该查询keyword之间的关联程度,称该关联程度为排序分数,最后以排序分数为依据将所有查询结果文档降序排列。根据不同的输入表示以及损失函数,LTR可分为基于Pointwise、基于Pairwise和基于Listwise三类模型方法:
(1) Pointwise方法单独针对每一个查询结果文档进行训练,将某查询下的每一个结果文档的特征和标注值作为训练样本。基于Pointwise的LTR算法有Prank[8]、SubsetRegression[9]等,这类LTR算法的缺点是忽视了样本间蕴涵的偏序关系,割裂了某查询下的所有结果文档之间并将其视为独立个体进行训练,其得到的排序模型在实际应用中性能较低。
(2) Pairwise方法针对Pointwise方法的不足考虑了某查询下所有结果文档之间的偏序关系,将其中具有不同相关度的两个文档组成“文档对”的形式作为训练样本。在训练数据集中标注出每一对“文档对”之间相关度偏序关系,该偏序关系取值只可能为“大于”或者“小于”,从而巧妙地将问题转化为分类问题,可用分类的机器学习工具解决,代表算法有RankingSVM[10]和RankNet[11]。
(3) Listwise方法理想化地以某查询所对应的所有结果文档作为训练样本,这样做的好处是能够公平地对待每一个结果文档,理论上排序性能更好。但在实际环境中由于文档特征值分布的稀疏性易产生某一特征缺失的情况,对排序模型的性能造成影响。代表方法有ListNetp[12]、SVMMAP[13]等。
综上,本文选择Pairwise模型进行排序学习研究。基于Pairwise的排序学习过程包含四个步骤:训练数据标注、文档特征抽取、排序模型训练和文档排序[6]。其中文档特征抽取步骤将所有文档样本表示成数值化的特征向量。训练数据集标注步骤将所有待标注样本表示为如下三元组格式:
RankingSVM是一种基于Pairwise模型的排序学习算法[10]。它将排序问题转化为二元分类问题,应用支持向量机模型进行训练学习得到分类器模型[14]。在查询集合Q中的某查询Qi对应Ni个查询结果文档{Di1,Di2,…,DiNi},其中,每个查询结果文档的相关度为Ri,利用两个结果文档之间相关度存在的偏序关系,即对于x∈{1,2,…,Ni},y∈{1,2,…,Ni},构造训练样本对S={Dix, Diy, Ri}。具体而言,若Rix>Riy,则得到一个正相关样本S1={Dix, Diy, 1},反之,则得到一个负相关样本对S2={Dix,Diy, -1}。通过该算法可以获得一个学习模型f,使得对训练集的任意查询Qi,若其对应的两个结果文档相关度满足Rix>Riy,则f(Dix)>f(Diy)。
考虑到RankingSVM目标函数为求线性函数f使得总的错误偏序对数量最少,基于支持向量机的分类器优化模型可以用下列二次规划表示为:
(1)
s.t. ∀(x,y)∈Pi:yixy
(2)
式中, Pi为查询Qi中所有偏序关系对
2 众包在训练集标注中的应用
众包的出现和发展为大规模标注工作提供了新的解决方案,它利用广大大众智慧“众人拾柴火焰高”,特别适合于人工完成并且仅依靠计算机很难完成的工作。但同时众包也有缺点,即众包工作的质量难以控制。相比于传统的专家团队标注模式,众包工作者的工作能力和工作态度是未知的,在实际众包应用中可能出现众包工作结果质量低下的情况。本文研究众包在LTR所需训练数据集标注中的应用,重点关注众包质量控制问题,即通过质量控制手段发现并过滤不良标注结果,提高整体标注质量。
2.1 众包质量控制方法概述
目前领域内学者已经针对众包质量控制方法进行了相关研究,研究重点集中于准确对众包工作者的工作能力进行衡量,最大限度地发现众多工作者中的不良标注者。传统的众包质量控制方法主要有黄金数据法[15]和多数投票法[16]。其中黄金数据法基于数据驱动的冗余思想,通过在待标注样本中加入已知正确结果的样本作为黄金数据,以众包工作者对黄金数据的标注结果来评判该工作者的工作能力。其优点是简单易行很早就被使用,缺点是未考虑样本难度的区别,对所有难度的样本对结果的影响没有进行区分从而影响了最终的准确率。多数投票法基于机制驱动思想,基于重复标注的思想,令多个标注者对同一样本多次标注,以最多的答案作为标准答案,这种方法同样简单易行,但其平等对待了所有的标注者未考虑到不同标注者工作能力的区别。针对这两种经典众包质量控制方法的缺点有学者提出使用机器学习的方法来解决,Raykar等[17]提出了一种基于EM算法的分类器模型和能力分数的概念来评估众包工作者的能力,通过区分不同能力标注者的工作结果来找出不良标注者。Kajino等[18]基于Raykar等人的研究工作对该分类器模型进行了优化,提出了个人分类器的概念,即以每个标注者所对应的个人分类器参数距离基于所有标注者个人分类器参数平均值的真实值的距离作为其能力分数,示意如图2所示。这种方法使用某众包任务下所有工作者的众包工作结果作为训练集训练出一个适用于该众包任务的个人分类器对所有工作者进行能力评估,同时考虑了不同众包工作者能力的区别和不同众包任务难度的区别从而更准确、客观地衡量众包工作者的能力。

图2 个人分类器能力分数示意图
2.2 优化迭代的个人分类器
个人分类器模型基于逻辑回归实现,LogisticRegression公式为:
P(y=1|x)=π(x)
(3)
其中π(x)是sigmod函数:
(4)
对于众包所得样本,将正确标注结果对应的参数向量记作ω0,为了克服过拟合,假设其服从以0为均值的Gaussian分布:
O(ω0|η)=N(μ,η-1I)
(5)
其中η是超参数,I是一个单位矩阵。其协方差矩阵表达式如下:
P(ωj|ω0,λ)=N(ω0,λ-1I)
(6)
针对第j个标注者,参考文献[18]中假设该标注者的众包工作结果由其对应的参数ωj来决定,并作为其对应的分类器,则其标注结果可表示为:
(7)
综上分析结果,得到目标函数,是一个负对数似然函数:

(8)
其中W={ωj|j∈{1,2,…,J}}。该目标函数为凸函数,可以使用迭代的算法进行参数估计,迭代步骤分为两个步骤。第一步将W固定来更新并得到解:
(9)
第二步固定ω0来更新W,采用Newton迭代法来更新每一个参数:
(10)
其中α是学习速率,H是Hessian矩阵:
(11)
其中梯度g(ωj,ω0)为:
(12)
经过上述两个步骤,即可得到最佳参数W和ω0。
本文考虑到众包实际进行中会存在的欺诈工作者,他们的工作结果和正确结果大相径庭,他们的存在会对个人分类器均值造成较大影响,大大降低了分类器的准确性。针对这个问题,本文对迭代过滤的方法进行了优化,在迭代求解真实分类器的过程中就先剔除这些明显的垃圾标注者。具体做法是在每一步迭代过程中将所有标注者按照各自的分类器能力分数排名,将排名最后的若干标注者进行过滤,算法如下:
输入 迭代次数iter_max,超参数η, 过滤不良标注者的迭代次数间隔iter_gap,每次剔除标注者百分比p。
输出 W,ω0。
While iter_num < iter_max:
将W固定来更新并得到解;
固定W0来更新W,采用Newton迭代法来更新每一个;
iter_num++;
if(iter_num%iter_gap)
对所有标注者按照分类器能力分数排名;
剔除排名最后p%的标注者;
endwhile
2.3 多分类支持个人分类器
上节中提出的个人分类器模型适用于二元分类问题,而LTR所需训练数据集一般有多相关度等级的需求,例如微软提出的OHSUMED数据集就包含了“相关”、“部分相关”、“不相关”三个相关度等级,故本节提出了一种基于DAGSVM的多分类支持个人分类器。
DAGSVM是一种基于有向无环图的多分类算法(DAG)[19],有完善的理论基础。在训练阶段,DAGSVM通过将样本两两组合的方式进行训练得到子分类器;在分类阶段,DAGSVM将所有子分类器作为节点构造一个有向无环图,测试样本将从根节点开始,由其当前所在节点分类器的计算结果来决定其下一步走向哪个分类器节点,如此迭代经过k-1步达到叶子节点时即完成分类。实验结果表明,用于决策的有向无环图中节点的排列顺序对最终结果影响不大,具有较好的分类性能且训练速度较快。图3展示了一个三元分类的DAGSVM分类示例。
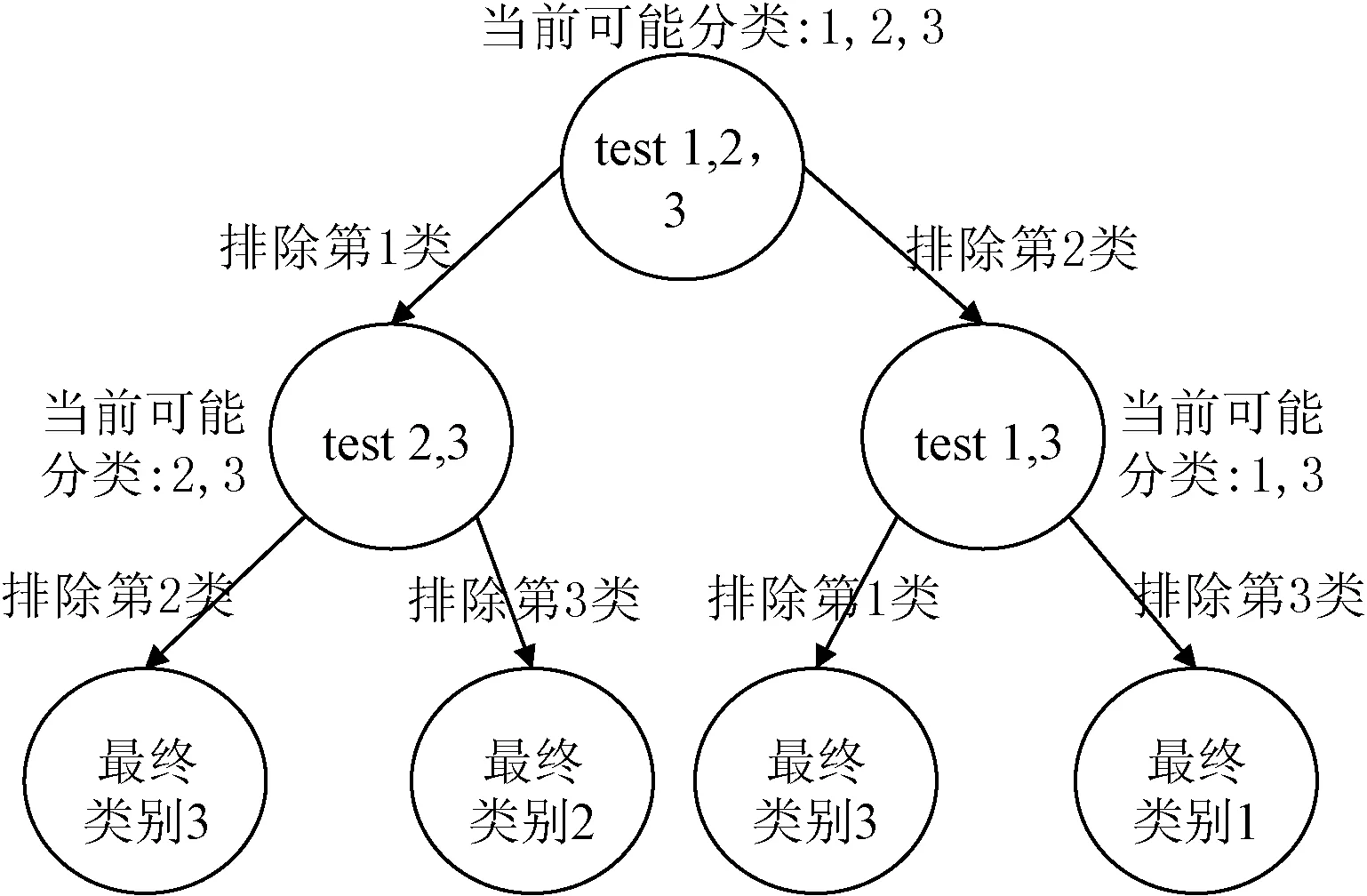
图3 DAGSVM分类过程示意图
由于DAGSVM基于SVM实现,其需要解决如下最优化问题:
(13)

(14)

对于多分类支持个人分类器,由于其分类超平面有多个,故能力分数的定义改进。若有k个分类超平面,某样本S其到k个超平面的距离分别为{Ds1,Ds2,…,Dsk},则其能力分数Q_mark可以定义为:
(15)
3 实验结果分析
3.1 实验方案设计
本文实验分为两个阶段,首先针对提出的优化迭代个人分类器和基于DAGSVM的多分类支持个人分类器验证其众包质量控制性能,再基于OHSUMED数据集[20]验证结合众包的排序学习算法性能,具体方案如下:
1) 数据集
针对优化迭代的个人分类器实验,本文采用计算机生成的仿真数据集模拟出众包中好的和坏的标注者,考虑到LTR所需样本的标注难度较低,按照80%到100%的正确率生成他们的标注结果;考虑到不良标注者会随机给出标注值,故以50%的概率随机生成0或者1作为他们的标注结果。实验设置样本维度为10,特征值区间设置为[-0.5,0.5]。样本的真实标签根据Logistic模型公式生成。实验以0为均值的使用Gaussian分布生成分类器参数。
针对多分类支持的个人分类器实验,本文使用微软亚研院的Letor3.0 OHSUMED数据集[15],OHSUMED数据集包含106个查询共16 140个查询-文档对,每个查询-文档对都被标注为相关、部分相关、不相关三种不同的相关度,分别对应于标注值2、1、0。每个文档都由45维特征向量进行表示。本文通过选取其中s_num条样本修改其相关度值为标注值区间内随机值的方法来模拟不良标注者的标注结果。
2) 衡量标准
本文通过对众包标注的准确率和机器学习领域广泛使用的AUC指标来衡量个人分类器众包质量控制性能;通过信息检索领域经典的NDCG指标衡量最终所得排序模型的性能。
3) 参数设置
本实验需要控制的参数如表1所示。

表1 优化迭代个人分类器实验参数含义
3.2 实验结果分析
优化迭代个人分类器和多数投票法、经典个人分类器在AUC指标下的性能对比如表2所示,本实验依次设置total_num={100,200,300},g_num=5,s_num={10,50,90},iter_num=10进行实验,固定iter_gap=2,filter_num=1。从表中数据可知,在不同参数前提下经典个人分类器的性能都较多数投票法有大幅提升,而优化迭代的个人分类器在此基础上又能将性能提高约2.5%。

表2 仿真数据集AUC对比
对本文提出的优化个人分类器方法影响最大的两个参数是iter_gap和filter_num,本文分别将这两个参数作为自变量进行实验和优化分析。
图4为随着iter_gap的增加AUC指标的变化情况,此时iter_gap的取值范围为{1,2,3,4,5},g_num=5,s_num=10,filter_num=1。

图4 iter_gap参数对优化迭代个人分类器AUC指标的影响
由图4可见,当每次都过滤掉一个认为是不良的标注者时,AUC指标低于传统的个人分类器方法,因为最初的几次迭代中对于不良标注者的判断不够准确,容易出现误判的情况,对结果造成影响。当iter_gap从2增加到4时,AUC指标也呈上升趋势,因为随着迭代次数的增多,分类器也越准确,进一步提高了过滤不良标注者的效果。当iter_gap为5时,AUC指标出现了略微的下降,因为iter_num为10,此时只进行了两次过滤过程,过滤力度相对不足。综上,在实际应用中推荐使用iter_gap=能获得较好的性能。
为了验证filter_num参数对实验结果的影响,以filter_num为变量,令total_num=300,g_num=5,s_num=50,iter_gap=2。因为设置了iter_num=10,故会过滤5次,故filter_num变化范围为[1,10],实验结果如图5所示。从图中可见,当filter_num在[1,4]区间内呈上升趋势,在[5,10]区间内呈下降趋势,其中在filter_num=4时达到最高,当filter_num位于[7,9]区间时性能介于传统个人分类器和多数投票法之间,而当filter_num=10时性能甚至低于多数投票法,因为当每次过滤过多标注者也容易误将好的标注者也过滤掉从而对最后的结果造成较大影响,这也符合实际情况。

图5 filter_num参数对优化迭代个人分类器AUC指标的影响
图6给出了三种众包质量控制方法下众包最终得到的标签正确率对比。其中J=100,横轴为不良标注者数量,纵轴为最终得到的标签正确率。由图6可见,本文提出的方法性能优于个人分类器和多数投票法,且当不良标注者增多时优势越来越明显,当100个标注者均为不良标注者时,三种方法的正确率都为50%,因为此时所有的标注者都随机给出标签结果,符合实际情况。

图6 仿真数据集整体标注正确率对比
本文选择高斯核函数进行基于DAGSVM的多分类支持个人分类器实验,需要控制的影响因子包括s_num和drop_num。图7给出了随着不良标注结果数量的增加众包标注整体正确率的变化情况。从图7中可以看出,当不良标注者占比小于20%时,基于多分类支持个人分类器的众包标注正确率较高,基本达到了DAGSVM分类正确率,当不良标注者占比在30%到70%区间内,正确率缓慢下降,当不良标注者占比大于70%时,正确率下降曲线斜率陡增,最终当全部都是不良标注者时达到30%左右的正确率,基本符合三元分类的随机概率。实验结果表明,当不良标注者占比小于20%时,基于多分类支持的个人分类器众包标注准确率能达到95%左右。
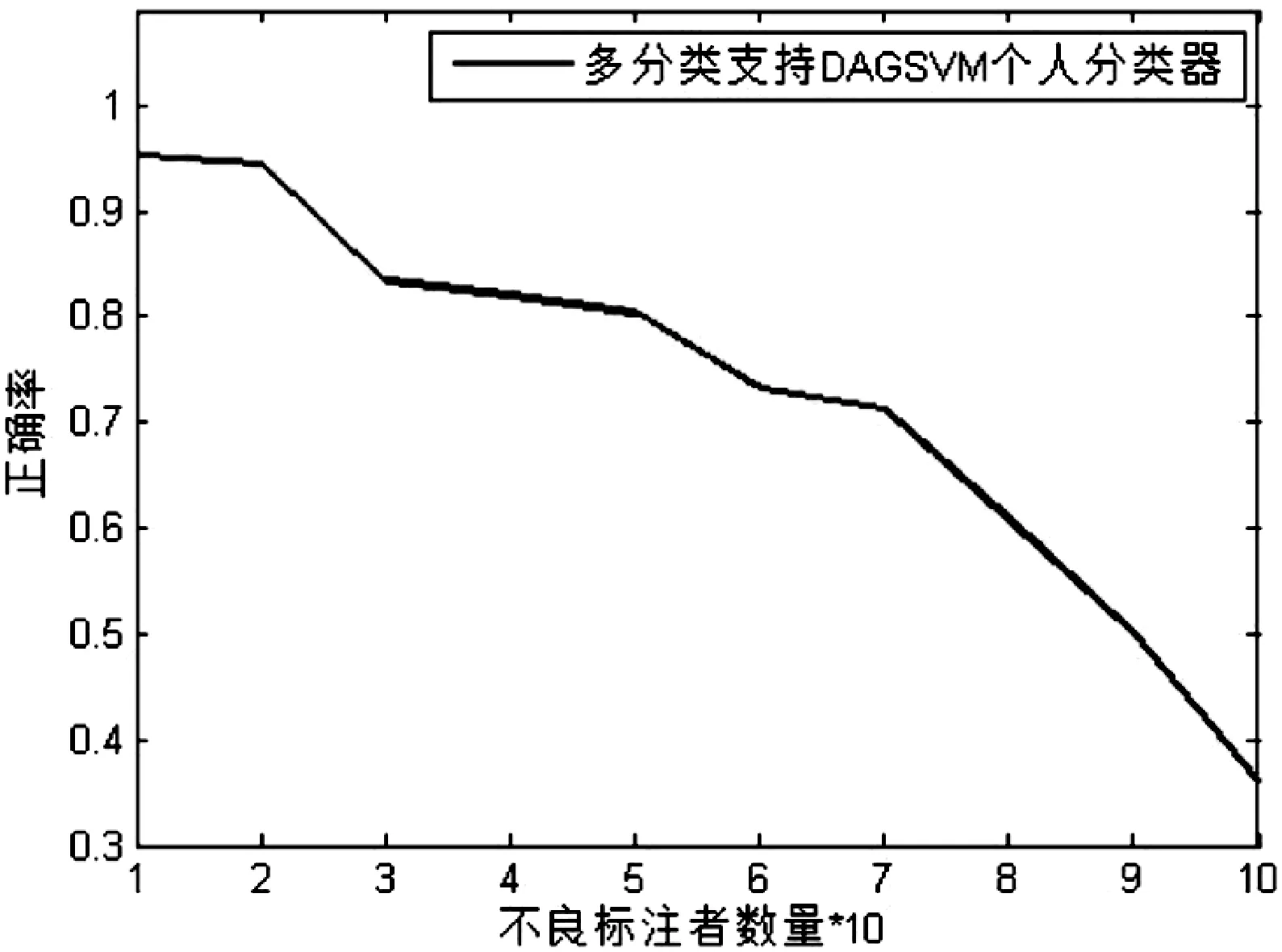
图7 不良标注数量对标注正确率的影响
为了验证按照质量分数排序后过滤的不良标注结果个数drop_num对最终众包结果正确率的影响,本文以OHSUMED数据集中qid={85,1,22,43,64}的实验数据集进行实验,共812个样本。为了让实验结果更加明显,设置了较多的不良标注结果,设置s_num=200。x轴为drop_num,y轴为正确率,实验结果如图8所示。由图可知,当drop_num从0增长到200时最终标注正确率一直在提高,符合实际情况,其中drop_num从20到40的变化范围内正确率提高的速度最快,当drop_num在60到160的范围内增加时,正确率的增长基本保持线性同步增长;当drop_num大于200时,理论上分类器能够将所有的不良标注数据都分类出来并删除,此时的正确率达到95%左右;但随着drop_num的增加,在200到300的范围内变化时正确率出现震荡,因为此时分类器在对不良标注样本的判定上存在误判,有可能过滤掉一部分好的标注结果从而对最终的正确率造成不良影响,由此可见drop_num过小会影响整体标注正确率,而drop_num过大对最终正确率的提升并没有实质性的帮助,反而会浪费更多的有效标注样本。综上,在多分类支持的个人分类器的实际应用中寻找合适的drop_num时,可以通过抽取一部分样本验证的方式确定大概的不良标注结果比例从而找到合适的drop_num值。

图8 过滤不良标注者的个数对正确率的影响
排序学习阶段使用RankingSVM作为排序模型训练算法,使用DAGSVM个人分类器作为众包质量控制方法,并设置最优的drop_num参数,重点验证在使用了个人分类器的前提下不良标注者个数即s_num参数对最终所得排序模型性能的影响情况。由前文实验结果可知此时drop_num=200,本文以传统RankingSVM算法作为比较的baseline。图9是当s_num=100和200时结合众包的排序学习方法在NDCG指标下的实验结果,图中纵轴是NDCG得分,横轴是结果列表中的不同位置,分别从NDCG@1至NDCG@10。

图9 不同s_num下结合众包的LTR在NDCG指标下的性能
由图9可知,当s_num=200时,此时不良标注占比为24.6%,此时结合众包的排序学习方法在NDCG指标下从第1个位置到第10个位置的性能结果都低于传统的RankingSVM算法,在NDCG@6和NDCG@8这两个位置的性能接近于RankingSVM算法,可以认为是排序支持向量机本身的性能原因造成。当s_num=100时,此时不良标注占比为12.3%,由图9可见,此时结合众包的排序学习方法性能相比s_num=200的情况有了明显提升,基本接近了基于全量标注训练集的传统RankingSVM的排序性能,在实际应用中能够达到较好的排序效果,以提升搜索引擎整体性能。
4 结 语
本文提出了一种结合众包的排序学习方法,创新地将众包这种大众网络聚集新模式应用于有监督排序学习所需大量训练数据集耗时耗力的标注工作中。针对众包可能出现的质量不良问题提出了个人分类器模型,使用机器学习的方法训练出可同时考虑众包工作者能力和众包任务难度的众包质量评估模型。在实验部分第一阶段,本文首先验证了优化迭代的个人分类器模型和适用于排序学习应用场景的多分类支持个人分类器模型,重点验证了个人分类器在迭代过程中的迭代次数、过滤人数等参数对其性能的影响情况。在实验部分的第二阶段,本文基于OHSUMED数据集和多分类支持个人分类器模型进行了仿真实验,验证了在不同的不良标注者占比的情况下结合众包的排序学习方法在NDCG指标下的性能,得到了结论:当不良标注者在众包总参与者中的占比为12.3%时本文所提出的方法能够基本达到传统RaningSVM算法的排序性能,证明了将众包和排序学习进行结合的可行性。考虑到在实际众包应用中,不良标注者数量占比经过对众包参与人员的基本的筛选过滤可较容易地低于12.3%这个比例,故本文的方法具有一定的实际指导意义。如何进一步提高众包质量控制能力,从而能在不良标注者占比更高的情况下依然获得良好的排序性能,在未来值得进行进一步的研究。
[1]HoweJeff.TheRiseofCrowdsourcing[J].06JenkinsHConvergenceCultureWhereOld&NewMediaCollide,2006,14(14):1-5.
[2]GuyI,PererA,DanielT,etal.Guesswho?:enrichingthesocialgraphthroughacrowdsourcinggame[C]//InternationalConferenceonHumanFactorsinComputingSystems,CHI2011,Vancouver,Bc,Canada,May.2011:1373-1382.
[3]SakamotoY,TanakaY,YuL,etal.Thecrowdsourcingdesignspace[C]//FoundationsofAugmentedCognition.DirectingtheFutureofAdaptiveSystems-,InternationalConference,Fac2011,HeldAs.2011:346-355.
[4]ParameswaranAG,Garcia-MolinaH,ParkH,etal.CrowdScreen:algorithmsforfilteringdatawithhumans[J].Sigmod,2011:361-372.
[5]MarcusA,WuE,MaddenSR,etal.CrowdsourcedDatabases:QueryProcessingwithPeople[C]//CIDR2011,FifthBiennialConferenceonInnovativeDataSystemsResearch,Asilomar,CA,USA,January9-12,2011,OnlineProceedings.2011:211-214.
[6]BrewA,GreeneD,CunninghamP.UsingCrowdsourcingandActiveLearningtoTrackSentimentinOnlineMedia[J].SentimentAnalysis,2010:145-150.
[7]KazaiG.Insearchofqualityincrowdsourcingforsearchengineevaluation[C]//EuropeanConferenceonAdvancesinInformationRetrieval.Springer-Verlag,2011.
[8]CrammerK,SingerY.PrankingwithRanking[J].AdvancesinNeuralInformationProcessingSystems,2002,14:641-647.
[9]CossockD,ZhangT.SubsetRankingUsingRegression[C]//ConferenceonLearningTheory.Springer-Verlag,2006:605-619.
[10]JoachimsT.TraininglinearSVMsinlineartime[C]//ACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.ACM,2006:217-226.
[11] Burges,Chris,Shaked,et al.Learning to rank using gradient descent[J].Inproceedings,2005:89-96.
[12] Cao Z,Qin T,Liu T Y,et al.Learning to rank:from pairwise approach to listwise approach[C]//Machine Learning,Proceedings of the Twenty-Fourth International Conference.2007:129-136.
[13] Yue Y,Finley T,Radlinski F,et al.A support vector method for optimizing average precision[C]//SIGIR 2007:Proceedings of the,International ACM SIGIR Conference on Research and Development in Information Retrieval,Amsterdam,the Netherlands,July.2007:271-278.
[14] Joachims T,Finley T,Yu C N J.Cutting-plane training of Structural SVMs[J].Machine Learning,2009,77(1):27-59.
[15] Joglekar M,Garcia-Molina H,Parameswaran A.Evaluating the crowd with confidence[J].Computer Science,2014:686-694.
[16] Liu X,Lu M,Ooi B C,et al.CDAS:a crowdsourcing data analytics system[J].Proceedings of the Vldb Endowment,2012,5(10):1040-1051.
[17] Raykar V C,Yu S,Zhao L H,et al.Learning From Crowds[J].Journal of Machine Learning Research,2010,11(2):1297-1322.
[18] Kajino H,Kashima H.A Convex Formulation of Learning from Crowds[J].電子情報通信学会技術研究報告.ibisml,情報論的学習理論と機械学習,2011,111(275):231-236.
[19] Platt J C,Cristianini N,Shawe-Taylor J.Large Margin DAGs for Multiclass Classification[J].Advances in Neural Information Processing Systems,2000,12(3):547-553.
[20] Liu T Y,Xu J,Qin T,et al.LETOR:Benchmark Dataset for Research on Learning to Rank for Information Retrieval[J].Proceedings of Sigir Workshop on Learning to Rank for Information Retrieval,2007,41(2):76-79.
A RANK LEARNING ALGORITHM COMBINED WITH CROWDSOURCING
Wang Xiaoping Xi Lingran
(SchoolofElectronicsandInformationEngineering,TongjiUniversity,Shanghai200092,China)
Aiming at the situation that it is difficult to obtain the large scale training data set with labels for supervised learning to rank, this paper introduces crowdsourcing, a new public network aggregation model, to complete the labeling work. It provides a new way to solve the problem of time consuming and labor consuming in the training dataset. We first introduce the crowdsourcing labeling method, and put forward two personal classifiers model to solve the problem of crowdsourcing quality control. At the same time, we consider the two factors that affect the quality of the crowdsourcing, including the marker ability and the difficulty of crowdsourcing tasks. Ranking SVM is used to rank learning based on the training set, and the performance of the method is evaluated on Microsoft OHSUMED data set under the NDCG@n criterion. The results show that the proposed crowdsourcing labeling method can achieve more than 95% correctness, and the performance of the ranking model is equal to Ranking SVM algorithm, which verifies the feasibility and superiority of crowdsourcing in ranking learning.
Learning to rank Crowdsourcing Crowdsourcing quality control Ranking SVM
2016-05-24。王小平,教授,主研领域:分布式智能系统,自然计算和社会计算。奚凌然,硕士生。
TP181
A
10.3969/j.issn.1000-386x.2017.06.050
