基于异常检测的尿沉渣图像分割
2017-07-10嵇启春
李 悦 嵇启春
(西安建筑科技大学 陕西 西安 727000)
基于异常检测的尿沉渣图像分割
李 悦*嵇启春
(西安建筑科技大学 陕西 西安 727000)
在尿沉渣图像中,由于其样本特性,使得在细胞图像采集时会有大量的杂质。这些杂质形状不规则,颜色不单一,用传统的图像分割算法难以去除。针对这个问题,提出一种基于异常检测的图像分割算法。该方法用形态学的方法对二值图像进行轮廓提取,根据其轮廓进行特征提取并且进行标记,然后用提取的轮廓特征以及标记构建异常检测模型。最终根据该模型对图象进行分割,并且定量地对该模型进行评价。实验结果表明,基于异常检测模型的尿沉渣检测方法能够以较高精度将杂质从细胞图像中分离。
尿沉渣图像 形态学 异常检测
0 引 言
在医学细胞图像处理研究中,细胞的识别和分割是最重要也是最困难的,其中,细胞的分割将图像分割为前景和背景,是把图像中感兴趣的部分提取出来的过程,它是细胞识别的前提。在尿沉渣图像中,我们需要将红白细胞从图像中分割出来,但是如图1所示,在尿沉渣的拍摄过程中,由于尿沉渣本身易受污染,使得图片有很多未知的不规则杂质,这些杂质干扰了尿沉渣的图像分割,进而影响到了细胞的准确识别,所以这是尿沉渣图像分割需要首要解决的问题。
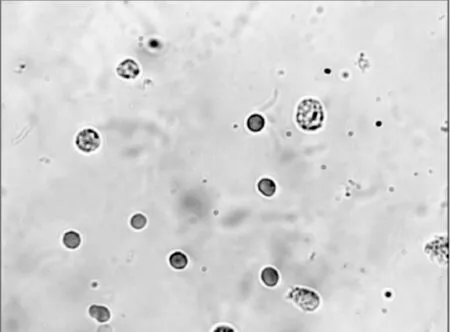
图1 尿沉渣图片
由于尿沉渣图像中的杂质没有固定的模式,所以尿沉渣的分割比较困难。在细胞图像分割中常用的几种方法中,谢凤英等[1-2]用分水岭算法分割免疫细胞图像,该算法虽然分割精度较高,并且比较简单,但是其需要手动选取种子点,并且对微弱边缘会产生响应,以至于对杂质也会产生响应。印勇等[3]用改进的canny算子分割尿沉渣图像,该算法能够自适应地选取canny算子中所需要的双阈值,并且能够产生连续性和闭合性更好的边缘,但是该算法没有办法去除面积较大的、形状不规则的杂质,所以当图像中有大面积不规则杂质时,该算法无法达到较好的分割效果。程培英等[4]将OSTU算法用于图像分割,该算法是基于最大化类间方差法[5],能够对图像进行快速的分割。当图像的灰度直方图是双峰结构时,该算法能够很好地将目标从背景中快速分割出来,但是当背景较为复杂,目标和背景的灰度有交叉的时候,该算法则无法很好的工作,会将大量的杂质当做目标分割出来。
针对上述分割算法的不足,本文结合尿沉渣图像的特点,提出了一种基于异常检测的图像分割算法。该算法使用形态学算法提取二值图像的轮廓,计算样本的轮廓特征并对样本进行标记,接着对标记为红白细胞的部分样本进行训练和建模,最后用没有进行训练的细胞和杂质样本进行检验,以检验的准确率评价模型的优劣。
1 基于数学形态学的轮廓提取
1.1 数学形态学
数学形态学是建立在严格数学理论基础上的学科,其算法已经成为许多图像处理和计算机视觉技术中的理论基础,被广泛应用于轮廓的提取中[6]。数学形态学是一种非线性滤波方法,其中,二值数学形态学变换是一种针对集合的处理过程, 基本运算包括腐蚀、膨胀、开运算和闭运算,这些运算的实质是表达物体或形状的集合与结构元素间的相互作用,这里结构元素的形状将决定所提取信号的形状信息。其中图像中的每一点x的腐蚀运算定义为:
X=E⊗B={x:B(x)⊂E}
(1)
膨胀运算定义为:
X=E⊕B={x:B(x)∩E≠O}
(2)
式中B(x)表示结构元素,E代表二值图像。腐蚀的结果是将结构元素B平移后使其完全包含在E中的点的集合。膨胀的结果是平移B使其与E的交集为非空的集合。除了腐蚀运算和膨胀运算,形态学滤波还包含开运算与闭运算。开运算定义为对图像先使用腐蚀,再进行膨胀,闭运算定义为先对图像进行膨胀,再进行腐蚀。开运算可以去除图像中的细小杂质,闭运算可以填充图像中的小洞。
1.2 基于形态学的轮廓提取
基于形态学的轮廓提取是基于形态学的方法提取轮廓,提取流程如图2所示。

图2 基于形态学的轮廓提取流程
首先对图像进行高斯滤波平滑图像,然后对平滑后的图像进行二值化,OSTU算法能够根据最大化类间方差的方法找到进行二值化的阈值,但是由于细胞图像的灰度直方图并不为双峰的,所以二值化后会产生杂质以及孔洞,需要用形态学滤波去除二值图像中的部分细小杂质和孔洞。接下来再使用形态学方法对图像进行轮廓提取,本文先使用3×3的结构元素S对二值图像A进行腐蚀得到被腐蚀的图像B,然后用原始边缘图像减去被腐蚀后的图像从而得到轮廓图像H,公式表示为:
H=A-B=A-A⊗B
(3)
使用二值图像腐蚀算法提取的医学细胞图像的边缘轮廓有单像素宽的特点,克服了传统轮廓提取算法边缘粗壮的特点,而且方便了轮廓跟踪。在对轮廓进行跟踪时,我们按照从下到上,从右到左的顺序依次扫描图片,当扫描到一个未标记的目标点时,将其标记为起点,然后按照8邻接的方式依次扫描被标记点的右、右上、上、左上、左、左下、下、右下8个顺序(如图3所示),找到下一个属于轮廓的点并进行标记,然后根据新标记的轮廓点继续寻找下面的点进行标记,直到搜寻到原点或者没有满足条件的点为止。其过程如图4所示,将最下面的一个点当做起始点,按照逆时针的方向进行标记。

图3 8链码方式 图4 轮廓提取过程
1.3 轮廓特征的提取
轮廓特征主要有面积、周长、似圆性以及对比度。根据这些特征,结合尿沉渣图像中红细胞,白细胞等的特点,我们可以过滤掉大部分的杂质,以得到一个较好的分割效果。其中面积的定义为轮廓域内的像素总和:
(4)
周长定义为轮廓边界的长度:
(5)
似圆性定义为:
(6)
对比度定义为:
(7)
式中,S表示被度量的轮廓域,f(x,y)表示点(x,y)上的像素值,Ne表示链码为偶数的数量,No表示链码为奇数时的数量,c(x,y)为点(x,y)的4邻域。当似圆性Bs越接近为1时,表示该轮廓越接近为圆。当对比度Cs越大时,说明轮廓内像素灰度变化越大,灰度越不均匀。
2 基于轮廓特征的异常检测模型
根据已经采集好的特征,我们首先要对特征进行转换,消除特征之间的相关性,接下来使用转换后的特征作为异常检测算法的输入,通过异常检测模型,对杂质进行筛选,该流程如图5所示。

图5 基于轮廓特征的异常检测算法流程
其中异常检测方法使用使用基于密度估计构建模型的方法,在2.1节中进行介绍,特征转换使用PCA算法,在2.2节中进行介绍。
2.1 异常检测模型算法简介
在疾病检测、细胞分割等领域,一般只有目标物(如细胞)有相对固定的模式,而对于异常(如噪声,杂质等)往往呈现出很大的随机性,所以在分类时,我们只能通过对目标物特征的学习并建立模型来进行异常检测[7-8]。
因为异常检测中异常类的数据常常缺乏,所以不能直接使用有监督的方法来进行学习分类,只能够通过对已有正常类的数据进行建模,从而归为无监督学习的范畴。无监督的学习也可以分为基于密度估计、基于重构和基于支撑等几类,本文主要使用基于密度估计构建异常检测模型,所以主要对基于密度估计构建异常检测模型做介绍。
在基于密度估计构建的异常检测模型中,我们假设目标类服从多元高斯模型,即:
(8)
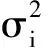
2.2 基于PCA的轮廓特征选择
PCA(即主成分分析)是一个可以对特征进行降维,用更少的特征代替原有特征的算法,其可以让数据在损失最少信息的情况下使新特征之间互不线性相关[9-10]。本文对采集好的轮廓特征进行降维,以得到新的线性无关的特征,其降维过程分为以下几步:
步骤1 特征中心化,即对每一维的特征都做归一化,其归一化方法如式(9)所示:
(9)

步骤2 将归一化的数据组合成一个矩阵A,其每一行为一个样本,求矩阵A的协方差矩阵B,由于A矩阵已经进行归一化,所以协方差矩阵B的计算公式如下:
(10)
矩阵B为对称矩阵,ai、bi表示不同的特征,m为样本数。矩阵B对角线上的元素为对应特征的方差,非对角线上的元素为对象两个特征之间的协方差,当其数值为正数时,说明两个特征之间为正相关,为负值时说明两个特征之间为负相关,当为0时,说明两个向量之间不相关。
步骤3 协方差矩阵对角化,由步骤2可以得出,如果协方差矩阵的非对角线上的元素为0,则说明两个特征之间是线性无关的,并且由于协方差矩阵B为对称矩阵,其在线性代数上,其具有以下非常好的性质:
定理1 实对称矩阵不同特征值对应的特征向量必然正交。
定理2 若实对称矩阵的某个特征值是r重的话,则必然存在r个线性无关的特征向量对应于该特征值,并可以将这r个特征向量正交化。
所以,根据以上性质,一个n维的实对称矩阵一定可以找到n个正交的特征向量所组成的矩阵Q,并对应着n个特征值,假设由n个特征值组成的矩阵为Λ,它们具有以下关系:
(11)
λi越大则说明其所对应的特征i越重要,将其对应的特征向量与样本特征做乘积,则可以将样本特征转换为新的特征,并且我们可以根据式(12)计算新特征信息量占原特征信息量的比例pi,pi越大则说明该特征包含的信息量与原有特征相差不大。
(12)
其中n为特征数目,最后我们可以根据P的大小以及期望降低的维数对特征进行选择。
使用MATLAB对该算法进行实现的方法如下。
input=mapminmax(input_train);
%对训练数据按照式(9)的方式进行归一化
[V,D] = eig(input);
%计算归一化后的数据input的特征值和特征向量,V是由特征向量构成的矩阵,D是对角线矩阵,其对角线上的每一个值是对应特征向量的特征值
最后,我们根据D中特征值的大小按照式(12)选取特征向量对输入特征进行转换。
2.3 基于轮廓特征构建异常检测模型
异常检测是机器学习中的一个概念,对于给定的一个数据集,对其概率分布建立一个模型并设立一个阈值,当输入一个新样本,用建立好的模型对其进行预测并与阈值进行对比,若其预测值小于设定的阈值则认为其是异常。该模型要求输入特征服从高斯分布,并且特征之间是线性无关的。异常检测模型的搭建为以下几步[11-12]:
步骤1 选择特征xi作为指示异常的特征,本文选择对轮廓特征用PCA进行特征提取后的特征;
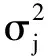
(13)
(14)
其中m表示样本总数,x(i)表示第i个特征;
步骤3 给定一个新样本x,按照式(8),计算p(x),若p(x)<ζ,则该样本为异常。ζ为常数,可以根据交叉验证来选择,其越大,则错识别率越高,其越小,则未识别率越高。
步骤4 模型由查准率P和查全率R来进行评判,查准率P定义为:
(15)
衡量的是检测结果为细胞的样本中实际输入也为细胞样本所占的比例;查全率定义为:
(16)
衡量的是被识别为细胞的样本占总细胞样本的比例。
使用MATLAB计算p(x)的方法如下:
P=zeros(1,cell_number);%初始化P值
for i=1:cell_number
for j=1:4
P(i)=1/sqrt(2*pi*sigma(j))*exp(-(x(i,j)-u1)^2)
/(2*sigma(j)^2);
%按照式(8)计算每个样本的p(x)
end
end
3 实验结果分析
本文使用NIKON显微镜在100倍物镜下拍摄的尿沉渣图像,图像大小为640×480,选择其中的50幅图片中的细胞进行训练,其中一共有697细胞,用10幅图像中的细胞进行测试,其中有128个细胞以及120个杂质作为测试数据。在Matlab2012下搭建软件开发环境,我们将细胞作为正例,杂质作为反例,先对特征进行提取,细胞特征的统计结果如表1所示。接下来对特征进行选择,按照2.2节所示的算法计算得细胞的四个特征根分别为:λ1=180.5,λ2=130.1,λ3=91.5,λ4=20.5。可以看出前3个特征根明显大于第4个,根据式(12)计算,前三个特征所包含的信息量占原有特征信息量的95.2%,所以我们只使用前3个特征构建异常检测模型,它们所对应的特征向量矩阵为:

(17)
将所有样本进行特征转换,即将QT与特征向量D相乘,可以得到新的特征,接下来,用转换后的特征按照2.3节的方法构建异常检测模型,结果如表2所示。
D=[d1d2d3d4]
(18)
其中D代表每个样本按照式(9)归一化后的特征向量,d1表示归一化后的面积特征,d2表示归一化后的周长特征,d3表示归一化后的似圆性特征,d4表示归一化后的对比度特征。

表1 细胞特征分布

表2 实验结果
由式(15)和式(16),得到模型查准率P=93%,查全率R=93.7%,查准率以及查全率都在90%以上,即可以满足一般的监测需要。
最后本文用其中的一幅测试图片的分割结果与其他算法进行对比,得到如下结果:
从图6可以看出,在尿沉渣图片中有大量形状,颜色不同的杂质,当我们使用分水岭算法对图像进行分割时(图7),其可以将细胞分割出来,但同时也将一些面积比较大,颜色与细胞图像相近的杂质分割出来了。当使用OSTU进行细胞图像分割时(图8),该算法找到能够最大化类间方差的阈值,将此阈值作为分割点进行分割,当图片中的杂质与细胞颜色接近时,该算法会将杂质当作细胞分割出来。并且由于细胞内部颜色不均匀,在分割时会在细胞内部产生孔洞,用OSTU算法做图像二值化后,需要用形态学的方法消除孔洞和一些小的杂质,但是无法消除面积比较大的杂质。从图9可以看出,当使用异常检测模型去分割图片时,由于使用了更多的特征,所以可以很好地将不规则的杂质轮廓剔除,并且可以定性地分析分割效果,人为选择一些参数,从而达到较好的分割效果。

图6 原始图片 图7 分水岭算法

图8 OSTU算法 图9 异常检测算法
4 结 语
尿沉渣检测是医院常规的检测项目,传统的检测方法主要依靠医务人员操作显微镜去人工识别尿沉渣中所含的成分,这种方法消耗大量的人力,所以需要开发自动化程度更高的尿沉渣检测仪,而尿沉渣的自动检验中尿沉渣的图像分割是一个难题,怎样能够比较准确地分割图像,对尿沉渣自动识别来说是关键的一步。本文通过结合传统的OSTU分割算法,用轮廓特征构建异常检测模型,具有以下优点:(1)识别精度高,由于结合了多个特性,异常检测模型能够更好地将细胞从图像中分割出来;(2)可以定量地分析结果,传统的算法只能从最后的分割图像中定性地判断分割的好坏,但是异常检测模型可以根据查准率和查全率定量分析分割结果。基于这些特点,该算法比较适合在尿沉渣自动检测仪上使用,有很大的应用前景。
[1] 谢凤英,姜志国,周付根.基于数学形态学的免疫细胞图象分割[J].中国图象图形学报,2002,7(11):1119-1121.
[2]WangD.Unsupervisedvideosegmentationbasedonwatershedsandtemporaltracking[J].IEEETransactionsonCircuits&SystemsforVideoTechnology,1998,8(5):539-546.
[3] 印勇,刘平,刘丹平.采用改进Canny算子分割尿沉渣图像[J].计算机工程与应用,2010,46(14):196-198.
[4] 程培英.一种新颖的OSTU图像阈值分割方法[J].计算机应用与软件,2009,5(26):228-231.
[5]OTSUN.Athresholdselectionmethodfromgraylevelhistograms[J].IEEETransonSMC,1979,9(1):62-69.
[6] 邹柏贤,林京壤.图像轮廓提取方法研究[J].计算机工程与应用,2008,44(25):161-163.
[7] 田杰,韩冬,胡秋霞.基于PCA和高斯混合模型的小麦病害彩色图像分割[J].农业机械学报,2014,45(7):267-270.
[8] 郭伟,刘鑫焱,肖振久.基于边缘前景的混合高斯模型目标检测[J].计算机工程与应用,2015,51(18):209-213.
[9] 朱志洁,张宏伟,韩军,等.基于PCA-BP神经网络的煤与瓦斯突出预测研究[J].中国安全科学学报,2013,23(4):45-50.
[10] 何晓群.多元统计分析[M].北京:中国人民大学出版社,2012:135.
[11] 陈斌,陈松灿,潘志松,等.异常检测综述[J].山东大学学报(工学版),2009,12(39):12-21.
[12] 李百惠,杨庚.混合高斯模型的自适应前景提取[J].中国图象图形学报,2013,18(12):1620-1625.
URINARY SEDIMENT IMAGE SEGMENTATION BASED ON ANOMOLY DETECTION
Li Yue*Ji Qichun
(Xi’anUniversityofArchitectureandTechnology,Xi’an727000,Shaanxi,China)
In the urine sediment image, due to its sample characteristics, it makes a lot of impurities in the cell image acquisition. These impurities are irregular in shape, and the color is not single, using traditional image segmentation is difficult to remove. Aiming at this problem, an image segmentation algorithm based on anomaly detection is proposed. The algorithm uses the morphological method to extract the binary image contour, according to its contour feature extraction and marking, and an anomaly detection model is constructed using the extracted contour features and the markers. Finally, the image is segmented according to the model, and the model is evaluated quantitatively. The experimental results show that the urine sediment detection method based on the anomaly detection model can separate the impurity from the cell image with high accuracy.
Urinary sediment image Morphology Anomaly detection
2016-05-30。李悦,硕士生,主研领域:图像处理,机器学习。嵇启春,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.06.038
