基于RNN进行面向主题的特征定位方法
2017-07-10尹春林
尹春林 王 炜,2* 李 彤,2 何 云
1(云南大学软件学院 云南 昆明 650500)2(云南省软件工程重点实验室 云南 昆明 650500)
基于RNN进行面向主题的特征定位方法
尹春林1王 炜1,2*李 彤1,2何 云1
1(云南大学软件学院 云南 昆明 650500)2(云南省软件工程重点实验室 云南 昆明 650500)
软件特征定位是软件演化活动得以顺利展开的前提条件。当前特征定位研究的性能仍有待于进一步提高。为了获得较好的性能,在文件夹粒度上获取主题知识,将系统中同一个文件夹下的所有类(class)划分为同一个主题知识类,提出利用深度学习算法——循环神经网络RNN(Recurrent Neural Networks) 进行面向主题的特征定位。同时,在该方法的基础上提出了一种改进的模型。为了使实验结果更具现实意义,与基线方法和其他一些方法相比,将实验数据从10组提高到531组和将检索率从15%缩小到10%,即使在这种情况下,所获得的实验结果,无论是从正面与基线方法相比还是从侧面与目前的一些特征定位方法相比,该方法都获得了不错的性能。
软件特征定位 软件演化 深度学习 循环神经网络 面向主题
0 引 言
特征定位[1]也被称为概念定位[2-3]、软件侦测[4],是程序理解领域一个重要的组成部分[5-6]。该研究旨在建立特征与源代码之间映射关系,而特征[1]是指可被定义和评估的软件功能属性。
对特征定位的研究最早可以追溯到1992年,Wilde[4]在其论文中提出了最早的特征定位方法——软件侦测。经过20多年的发展特征定位研究领域取得了长足进步,并且在软件维护/演化、波及效应分析、可追溯性复原等多个研究领域得到了应用。在软件维护/演化领域,没有任何一个维护/演化任务能够脱离特征定位的支持[1,7]。维护/演化活动是原有开发活动的继续,但是两者之间存在本质的差别:维护/演化活动是在现有系统的约束下实施的受限开发。因此,理解特征与代码之间的映射关系,并据此确定执行维护/演化活动的起始点和范围,是成功实施维护/演化活动的基础。确定维护/演化活动影响范围的过程称之为波及效应分析[8-9]。该分析的前提通常是使用特征定位方法确定维护/演化活动的起始点[1]。可追溯性复原[10]试图建立软件实体(代码、需求文档、设计文档等)之间的映射关系。由于特征定位旨在建立软件功能属性与源代码之间映射关系,因此可以认为特征定位研究是可追溯性复原研究和进行波及效应分析的一个重要组成部分。建立高效的特征定位方法不仅对丰富程序理解研究内涵,同时对推动多个研究领域的共同发展具有重要意义。
根据分析思路的不同,目前的特征定位方法可归结为四类[1]:静态特征定位方法、基于文本的特征定位方法、动态特征定位方法和集成特征定位方法。
静态方法是试图对软件源代码的依赖关系和结构的进行分析,并建立特征和代码间的映射关系[1]。动态方法试图建立用例与执行迹之间的映射关系实现特征定位[11]。基于文本的特征定位方法[12-14]认为,源代码中的标识符、注释和其他文档中蕴含有丰富的主题知识,所以源代码与特征的关系就可以通过文本分析的方式获得。当前基于文本的特征定位方法大致可以分为3类:基于模式识别、基于自然语言处理和基于信息检索的特征定位方法。目前基于自然语言的特征定位查准率是最高的。基于自然语言处理的特征定位方法试图将自然语言处理研究在词性标注、分词、组块分析等研究成果嫁接于特征定位问题。本文试图利用基于自然语言的文本特征定位方法进行研究。本文认为不同粒度的划分、不同的程序模块代表了不同的领域知识,即代表了不同的主题知识。本文希望获得一个好的语言模型LM(Language Model),该模型拥有良好的分类能力,能将源代码系统中不同的主题知识进行准确的区分。所以问题的关键转化为了如何获得一个拥有良好特征表达的LM。
目前常用的信息检索方法模型有隐语义索引LSI(Latent Semantic Indexing)[15]、隐狄利克雷分布LDA(Latent Dirichlet Allocation)[16]、向量空间模型VSM(Vector Space Model)[17]、依赖性语言模型DLM(Dependence Language Model)[18]。虽然这些方法都获得了一定的效果,但并不令人满意,在实践中也暴露出一些问题。不难发现,这些方法都不能够将程序主题知识完整地传递给计算机,所以机器也就难以获得良好的主题知识。良好的数值化方法和良好的上下文语义获取方法是良好的主题知识表达的第一步。深度学习在自然语言处理NLP(Natural Language Process)方面给出了一些很好的数值化处理方法,如word embedding,即“词向量”,典型的例子是google的word2vec。循环神经网络RNN(Recurrent Neural Networks)通过不断循环的方式更完整的保存上下文语义关系。为此,本文希望通过利用深度学习算法——循环神经网络来进行基于文本的特征定位以期获得更好的效果。
本文的创新点和贡献如下:
(1) 利用RNN语言模型来获取文本上下文语义;
(2) 文件夹粒度做主题分类;
(3) 两组实验对照获得更有普遍性意义结果。
1 本文方法
本文方法主要分为三个步骤:主题知识生成、主题建模以及特征定位。图1为本文框架图。

图1 本文方法框架图
1.1 主题知识划分
一个源代码系统由不同的程序模块构成,不同的模块对应于不同的功能/主题,即不同的功能/主题对应着不同的特征。特征定位的目的就是获得特征与源代码之间的映射关系。本文的方法是先将源代码系统利用RNN按主题知识进行划分,然后利用获得的模型将程序员给出的功能描述语句进行分类,抽象地描述就是“输入功能描述就能输出目标代码”,形式化描述:Y=f(X),X表示功能描述,Y表示输出的目标代码,f是这种映射关系的表示。研究的目标就是希望获得这一个能够准确地建立起特征与源代码之间的一致性关系的模型。因此,好的主题划分是获得好的特征定位的前提条件。
本文提出以下几种划分粒度:(1)方法/函数级;(2)类级;(3)文件夹级;(4)包级。方法/函数级划分将源代码系统按方法/函数进行拆分,将一个方法/函数看做是一个数据,认为多个方法/函数共同表示一个主题。类级划分将源代码系统按“类”进行划分,将一个类看做是一个数据,认为一个或者几个类共同代表一个功能/主题。文件夹级划分将源代码系统中同一个文件夹下的所有方法或者函数看做是同一个类簇,认为同一个文件夹下的所有类或者函数共同代表着一个功能/主题。包级划分将源代码系统中同一个包下的所有文档看做是同一个类簇,认为同一个包下的所有文档代表着一个主题。函数级和类级的划分粒度比较小,所以可能一个功能就对应多个函数或者多个类,这样的划分就需要先对数据进行聚类,认为聚类后获得的结果中的一个类簇就对应一个主题。包级的划分是一种大的模糊的划分方式,适合应用到大的源代码系统中进行试验。程序员在进行软件开发时通常会将实现了相同功能的类放到同一个文件夹下,相同文件夹下的所有类的相关关系更紧密,所以认为同一个文件夹下的所有类更能良好地表达同一个主题,并且这样的划分方式无需进行聚类处理就可以直接将同一个文件夹下的所有类标注到同一个类簇中。所以综合以上考虑,本文选择文件夹粒度进行试验。
1.2 主题建模
基于文本的特征定位方法通常希望获得一个好的语言分类模型,该模型能够良好地表达主题知识。数值化抽象是特征定位的基础,该过程依赖于代码语言模型的建立,通常语言模型可以抽象为关键词的概率分布函数。假设源代码SC由关键词{w1,w2,…,wn}构成的文本序列,则SC对应的概率分布函数如公式(1):
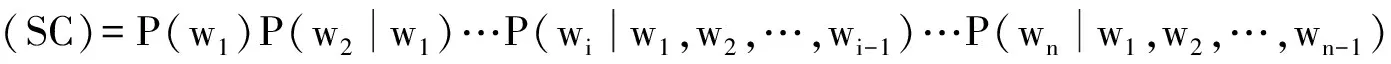
(1)
式(1)可以被链式地分解为:
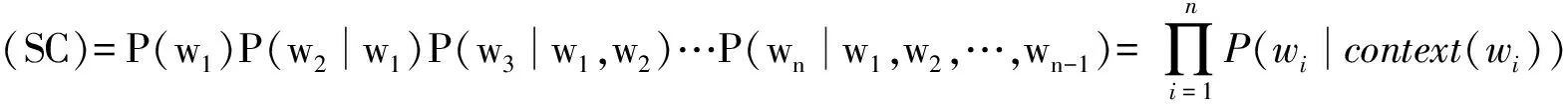
(2)

(3)
(4)
式(4)中count(wi-(n-1),…,wi-1)表示文本序列wi-(n-1),…,wi-1在语料库中出现的次数。
1.3 特征定位

(5)
Softmax回归其实就相当于多类别情况下的逻辑回归,式(5)中Softmax有k个类,也就是对应实验中的38个类,并且函数将-θ×X作为指数的系数,所以就有j=1…k项。然后除以他们的累加和,这样做就实现了归一化,使得输出的k个数的和为1,而每一个数就代表那个类别出现的概率。因此:Softmax的假设函数输出的是一个k维列向量,每一个维度的数就代表那个类别出现的概率。这样计算出每个特征描述与每一个类相关的概率,然后依次按概率相关程度降序排列。为此,我们获得一个概率相关列表,越在最前面的类就是就是相关度越大的类。我们获得的特征定位的结果就是每个查询语句与每个类的相似度。
2 实验过程及数据
2.1 实验所用数据数码
文章使用源代码系统是jedit4.3source[1],该系统包含531个class,6 400余个method,1.9万行代码。同时,还有272个通过使用IST(issue tracking system)和SVN(subversion)工具分析获得的特征。其中150个特征用例搜集过执行迹,这些特征以ID作为标识,在jEdit更新日志中可查(http://sourceforge.Net/p/jedit/bugs/search/)。每个特征对应于3个数据文件:Queries、Traces以及GoldSet。实验中所用到的RNN模型代码是基于http: //github.com/IndicoDataSolutions/passage.git中的模板进行修改得到的,该网站上提供的是一个用于二分类的代码模板,修改后可以用于多分类。
2.2 实验过程及参数设置
本文选用的源代码系统jedit4.3包含分布在38个文件夹下的531个class,每个class是一个以“.java”为后缀名的文件。RNN属于监督学习,需要使用标签数据,于是我们就进行了人工标记,将同一个文件夹下的class标注为同一个类簇,数据的标签名就选用阿拉伯数字0到37进行表示。表1是38带标签的数据示意图,其中一个数据用一个类的路径来表示(后同)。
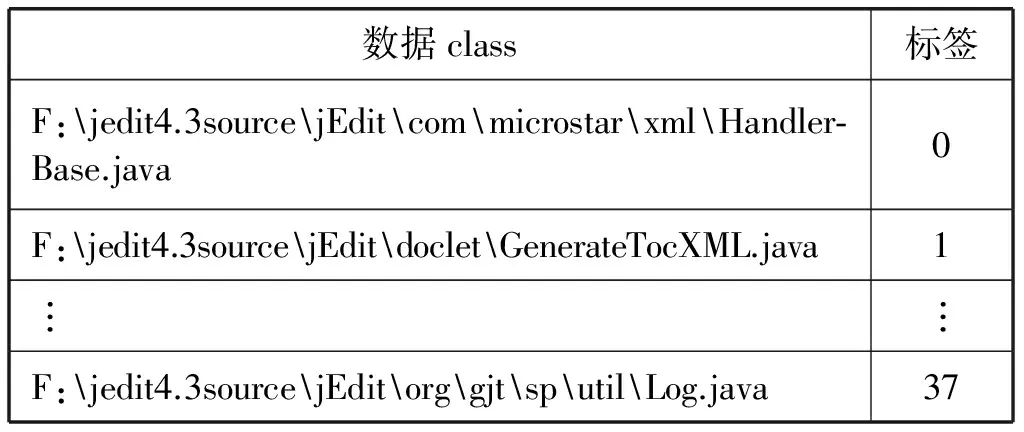
表1 标签数据示意
表2表示同一个文件夹下的所有类,这些类属于同一个类簇,都被划分到类“0”中。

表2 同一文件夹下所有类标注为同一类
模型的输入是分别属于38个类的531个数据。首先是对获得的训练数据集和预测数据集进行简单的预处理。每一个.java文件都包含大量的注释,我们认为注释更能很好地表达主题知识,所以也将其保留下来不做特殊处理。由于RNN可以获取上下文语义关系,所以与传统的预处理不同,本文的预处理不做停词、分词和词干还原等操作,仅仅只是将文本中对表达主题毫无帮助的那些注释符号去掉,如分割线“————”。训练模型的数据准备完毕,接下来就可以训练生成RNN模型了。实验数据集被划分成两部分:训练数据集和预测数据集,训练数据集用来训练生成模型,预测数据集用来挑选模型。从每一个类簇中挑选出一个数据作为预测数据集,剩余的作为训练数据集,如果存在一个类簇,该类簇只含一个数据则该数据既作为训练数据也作为预测数据。而我们的模型不但对预测数据集进行预测也对训练数据集进行预测。挑选出对训练数据集和对预测数据集预测准确率高的模型进行特征定位的实验。下面是我们选用的RNN模板需要设置的几个参数:
(1) 隐藏层layers:[ Embedding(size=128);GatedRecurrent(size=256,activation=′tanh′, gate_activation=′steeper_sigmoid′,init=′orthogonal′,seq_output=False);Dense(size=531,activation=′softmax′, init=′orthogonal′)]
(2) 模型model=RNN(layers=layers, cost=′cce′)
“cce”在模板中是一个设置为多分类并用softmax进行输出的参数,在训练生成RNN模型同时获得用于计算相似度的softmax的参数θ。在训练了多个模型之后文章使用了一个预测准确率相对较高的模型:预测训练数据集准确率为91%,预测预测数据集准确率为52%。该模型每次训练100个数据,迭代训练150次获得。模型选定之后接下来的工作就是进行特征定位。本文选用的是Queries里面的“ShortDescription[ID].txt”作为查询语句,提交查询语句之后输出该查询语句与每一个class的相似度,选取相似度最高的前10%进行输出。
3 实验结果及分析
3.1 实验结果分析
本文主要将文献[13]作为基线方法与本文的方法进行对比。基线方法在函数级粒度上进行预处理后生成语料库,然后进行Single Value Decomposition(SVD)生成LSI space,最后输入query进行查询,详细介绍看文献[13]。同时也与文献[23-24]中提出来的方法进行一个侧面的对比,文献[24]是动态特征定位和静态特征定位相结合获得的结果,文献[23]中使用的数据集是ArgoUML,ArgoUML数据集比iEdit大,包含1 562个类和96个包。为了验证本文方法的有效性,我们还设计了一组自我对照实验,即测试了与基线方法和文献[24]相同的10个数据。为了获得一个较公平的评价标准通常使用信息检索中提供的查全率、查准率和调和平均数F(F-measure)来度量特征定位技术的综合性能[11]。表3是各种实验对比情况。
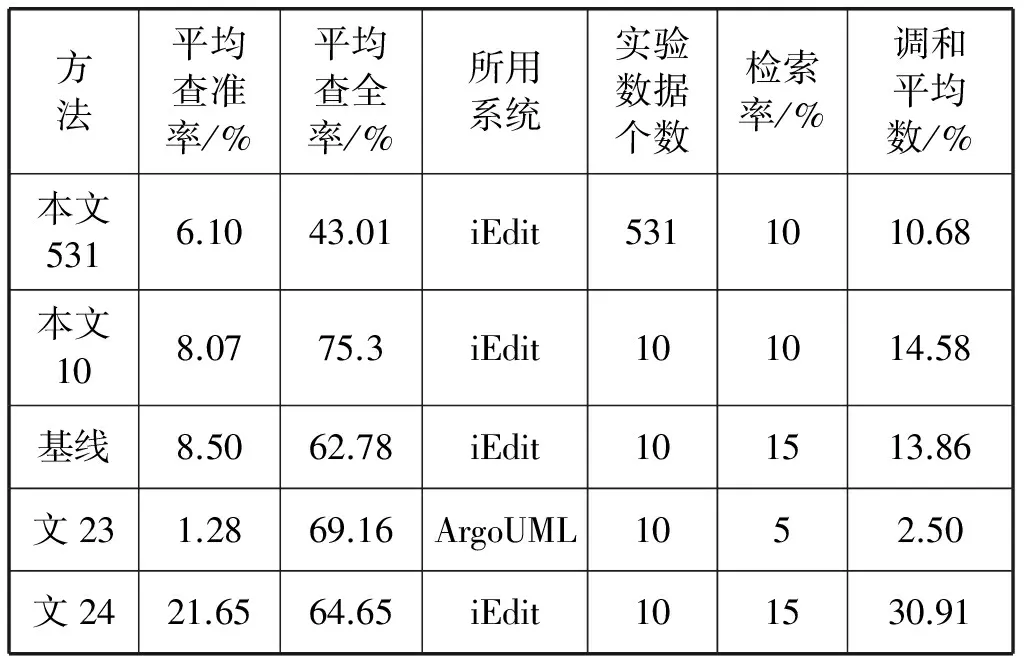
表3 实验结果对比
在表3中“本文531”是指利用本文提出的方法测试了531个数据的实验,“本文10”是指利用本文提出的方法测试了10个数据的对照试验。表3的检索率是指输出与查询语句相似度高的实验数据个数占实验数据总个数的比例,一般用文献[13]推荐的方法取相似度高的前10%~15%。从表3可见,在同样取10个相同的数据进行测试的情况下,本文方法的平均查准率为8.07%,平均查全率为75.30%,调和平均数为14.58%,检索率为10%;基线方法平均查准率8.50%,调和平均数13.86%,检索率为15%,而平均查全率只有62.78%。在我们将实验数据个数从10个扩大到531(全部实验数据)个且检索率依然为10%的情况下,仍然取得了6.1%的查准率、43.01%的查全率和10.68%的调和平均数。虽然较基线方法有所下降,但是我们的实验数据对象是全部的试验数据。我们也认为只有在所有的数据上进行试验才更具有普遍意义和更具有可信度,单纯从几个数据来说可能存在一定的偶然性,就本实验来说,在我们取10个数据的情况下获得的查全率为75.3%就比基线方法和其他方法都要高很多。同时特征定位的理想目标是获得特征与源代码的准确映射关系,所以认为越低的检索率对特征定位越有意义。由于文献[23]是在另一个数据集上的实验,该数据集个数要远大于我们的实验数据集,虽然他的检索率为5%,但计算下来也跟iEdit 4.3的15%仅相差1个数据。综合以上比较发现,本文方法综合性能更优。
3.2 实验不足
由于实验检索出来的结果是按相似度进行降序,与查询语句相似度高的类簇排在前面,而一个类簇里至少包含一个以上类,多的包含实验总数据的10%(约53个)以上,由于每一个类簇里面的数据是无序的,所以存在这样的一些数据,虽然这些数据包含在我们检索出来的类簇中,但是没有办法计算在查准率和查全率中。比如在一组实验中检索出了两个与特征相关的类簇,这两个类簇包含的类的个数加起来超过了53个,这样就得将相似度低的第二个类簇的一些类去除,然而第二个类簇里的类与特征的相似度是未知的,所以保留哪些类难以确定。
3.3 基于本文方法提出的新模型
混合特征定位的方法通常会获得更好的结果,一种方法是:“动态+文本”,该方法先利用动态特征定位约减搜索空间再进行基于文本的特征定位。这种方法的缺陷是每进行一次特征定位就需要进行一次建模,即需要对每一个查询语句都进行一次“动态+文本”的特征定位。这样的方式工程量大没有什么现实意义的。然而利用RNN可以先对所有的数据建一个文本模型,该模型的作用是计算每一个类与查询语句的相似度并进行排序,然后再在该模型的顶部加一层动态层,与前面提到的方法不同的是此处的动态层的作用是通过将动态层输出的结果与基于文本的方式输出的结果进行交集计算来提高准确率和查全率。模型形式化见式(6):
F=f(X)∩R=g(Z)
(6)
式中,F是基于文本的特征定位的输出,该输出包含每一个类的类名及其与查询语句的相似度,X是基于文本的输入,f是映射关系;R是动态特征定位的输出,Z是动态特征定位的输入,g是映射关系。最后将式(6)得到的结果按F的相似度进行降序,排在最前面的就是模型定位的最终结果。此模型是以利用RNN行进基于文本的特征定位为前提,划分粒度选择类级别。该模型的好处是可以保证在当前的模型的基础上提高综合性能,并且相对与“动态+文本”的特征定位来说减少了工程量。
4 结 语
软件特征定位是软件演化活动得以顺利展开的保证。然而目前的特征定位无论是查准率还是查全率都还处于一个很低水平。本文从基于文本的特征定位出发提出在文件夹粒度上利用RNN进行面向主题的特征定位。本文认为主题划分的好坏直接影响到特征定位的结果,本文还提出了几种不同的主题划分方式,同时选择了“文件夹级”粒度的划分方式来进行试验。通过实验结果的对比得知虽然我们的方法存在一定的缺陷,但还是对利用深度学习进行特征定位进行了一定的探索,试验的综合性能也较优。最后还提出了一个“基于文本的特征定位+动态特征定位”模型,未来的工作分两部分:一是继续探索用其他粒度划分主题,二是利用本文提出的新模型进行试验论证。
[1] Dit B, Revelle M, Gethers M, et al. Feature location in source code: a taxonomy and survey[J]. Journal of Software: Evolution and Process, 2013, 25(1): 53-95.
[2] Abebe S L, Alicante A, Corazza A, et al. Supporting concept location through identifier parsing and ontology extraction[J]. Journal of Systems & Software, 2013, 86(11):2919-2938.
[3] Scanniello G, Marcus A, Pascale D. Link analysis algorithms for static concept location: an empirical assessment[J]. Empirical Software Engineering, 2015, 20(6): 1666-1720.
[4] Wilde N, Gomez J A, Gust T, et al. Locating user functionality in old code[C]// Software Maintenance, 1992. Proceerdings. Conference on. IEEE Xplore, 1992:200-205.
[5] Alhindawi N, Alsakran J, Rodan A, et al. A Survey of Concepts Location Enhancement for Program Comprehension and Maintenance[J]. Journal of Software Engineering and Applications, 2014, 7(5): 413-421.
[6] Dit B, Revelle M, Poshyvanyk D. Integrating Information Retrieval, Execution and Link Analysis Algorithms to Improve Feature Location in Software[J]. Empirical Software Engineering, 2013, 18(2): 277-309.
[7] Rajlich V, Gosavi P. Incremental change in object-oriented programming[J]. IEEE Software, 2004, 21(4): 62-69.
[8] Li B, Sun X, Leung H, et al. A survey of code-based change impact analysis techniques[J]. Software Testing Verification & Reliability, 2013, 23(8):613-646.
[9] 王炜, 李彤, 何云,等. 一种软件演化活动波及效应混合分析方法[J]. 计算机研究与发展, 2016, 53(3):503-516.
[10] Lucia A D, Marcus A, Oliveto R, et al. Information retrieval methods for automated traceability recovery, in Software and systems traceability[M]. London: Springer, 2012.
[11] Ju Xiaolin, Jiang Shujuan, Zhang Yanmei, et al. Advanced in Fault Localization techniques[J]. Journal of Frontiers of Computer Science and Technology, 2012, 6(6):481-494.
[12] Petrenko M, Rajlich V, Vanciu R. Partial domain comprehension in software evolution and maintenance[C]// Proceedings of the 16th IEEE International Conference on Program Comprehension (ICPC ’08), Amsterdam, Netherlands, Jun 10-13, 2008. Washington, DC, USA: IEEE Computer Society, 2008: 13-22.
[13] Marcus A, Sergeyev A, Rajlich V, et al. An information retrieval approach to concept location in source code[C]// Proceedings of the 11th Working Conference on Reverse Engineering (WCRE’04), Delft, Netherlands, Nov 8-12, 2004. Washington, DC, USA: IEEE Computer Society, 2004: 214-223.
[14] Hill E, Pollock L, Vijay-Shanker K. Automatically Capturing Source Code Context of NL-Queries for Software Maintenance and Reuse[C]// Proceedings of the 31st IEEE International Conference on Software Engineering (ICSE’09), Vancouver, BC, May 16-24, 2009. Washington, DC, USA: IEEE Computer Society, 2009: 232-242.
[15] Dumais S T. Latent semantic analysis[J]. Annual review of information science and technology, 2004, 38(1): 188-230.
[16] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3:993-1022.
[17] Salton G. A vector space model for automatic indexing[J]. Communications of the Acm, 1974, 18(11):613-620.
[18] Gao J, Nie J Y, Wu G, et al. Dependence language model for information retrieval[C]// SIGIR 2004: Proceedings of the, International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, Uk, July. 2004:170-177.
[19] Xu W, Rudnicky A. Can artificial neural networks learn language models?[C]// International Conference on Spoken Language Processing, Icslp 2000 / INTERSPEECH 2000, Beijing, China, October. DBLP, 2000:202-205.
[20] Bengio Y, Senecal J S. Adaptive importance sampling to accelerate training of a neural probabilistic language model[J]. IEEE Transactions on Neural Networks, 2008, 19(4):713-22.
[21] 来斯惟.基于神经网络的词和文档语义向量表示方法研究[D].北京:中国科学院自动化研究所,2016.
[22] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]// Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. 2010.
[23] 韩俊明, 王炜, 李彤,等. 演化软件的特征定位方法[J]. 计算机科学与探索, 2016, 10(9):1201-1210.
[24] 何云, 王炜, 李彤,等. 面向行为主题的软件特征定位方法[J]. 计算机科学与探索, 2014, 8(12):1452-1462.
TOPIC ORIENTED FEATURE LOCALIZATION METHOD BASED ON RNN
Yin Chunlin1Wang Wei1,2*Li Tong1,2He Yun1
1(SchoolofSoftware,YunnanUniversity,Kunming650500,Yunnan,China)2(KeyLaboratoryforSoftwareEngineeringofYunnanProvince,Kunming650500,Yunnan,China)
Software feature localization is a prerequisite for the smooth development of software evolution. The performance of the current feature location study still needs to be further improved. In order to obtain better performance, get the subject knowledge in the folder granularity was gotten. All the classes under a folder in the system were divided into the same subject knowledge class, This paper proposed a topic-oriented feature locating using depth learning algorithm-Recurrent Neural Networks(RNN). At the same time, an improved model was proposed based on this method. In order to make the experimental results more realistic, compared with the baseline method and other methods, this article will test data from 10 to 531 group and the retrieval rate from 15% to 10%. The experimental results show that this method has better performance than either the baseline method or the feature orientation method.
Software feature localization Software evolution Deep learning Recurrent neural network Topic oriented
2016-07-23。尹春林,硕士生,主研领域:软件过程,软件演化,特征定位等。王炜,副教授。李彤,教授。何云,博士生。
TP311.52
A
10.3969/j.issn.1000-386x.2017.06.003
