指标选取方法对财务预警准确率的影响研究
2017-07-05王娇娇
王 飞,王娇娇
(河海大学 商学院,江苏 南京211100)
指标选取方法对财务预警准确率的影响研究
王 飞,王娇娇
(河海大学 商学院,江苏 南京211100)
基于财务预警模型的原理,首先使用适当方法从公司众多指标中选出与预测财务危机相关性较高的指标,然后使用模型对这些指标形成预期,最后根据以后年度的业务指标对是否发生财务危机进行检测。由于不同指标选取方法的原理不同,因此用不同的指标选取方法选出的指标进行财务预警的准确率也不同。通过逐步回归分析法、主成分分析法及均值差异检验法3种方法选取指标,将选出的指标通过Logistic回归模型检测各自的预警准确率,可为财务预警提供参考。
财务预警;逐步回归分析法;主成分分析法;均值差异检验法
目前股票投资已成为百姓投资方式中一个不可或缺的选择方式,一个上市公司的发展如何不仅关系着公司的所有者、经营者和员工,还对众多的股票持有者产生影响,可见一个公司建立财务预警模型的必要性。伴随着我国市场经济体制的进一步发展,各微观个体公司之间的竞争加剧,财务危机日益成为企业管理者需要关注和避免的事项。财务预警模型引入我国已30年有余,对于财务预警模型的建立一直都是理论界讨论的热门话题。财务模型的建立包括两大步骤:①指标选取,②建立模型。而以往研究大多都集中在模型的选择和建立上,忽视了对指标选取方法的研究;且在建立财务预警模型时对指标的选取一般根据经验或已有的研究,而根据经验可能由于主观意识导致选取的指标做不到公允反映公司状况的情形,已有的研究也可能存在错误。综上可看出对指标选取方法研究的必要性。
ALTMAN[1]把财务危机定义为“法律意义上的破产、被接管和企业重整”,而根据我国实际情况在上市公司被ST时,很可能会被其他公司购买从而达到被借壳上市,几乎不可能出现破产结算现象,所以笔者将公司因财务状况异常被证券交易所区分为“特别处理”的公司,认定为发生财务危机的公司。财务状况异常是指从审计结论中得出最近两个会计年度财务报表中显示净利润小于零、连续两年亏损或每股净资产小于股票面值(一般情况下,公司股票面值为1)。
Logistic模型的基本原理是基于选取的指标形成对模型的预期来预测公司陷入财务危机的概率。国外对Logistic模型的研究较早,如JONES等[2]采用混合Logistic模型,建立财务困境预测模型,该研究中因变量为有序变量,相对于标准Logistic,混合Logistic在模型拟合度及预测准确度方面均有所提高。国内对于财务危机的研究较晚,吴世农等[3]率先应用线性判别分析、多元线性回归分析和Logistic回归分析3种方法进行比较,结果表明,相对同一样本集而言,Logistic预测模型误判率最低;雷振华[4]对Logistic模型的财务预警准确度检验研究中,t-3年的准确率为77%,t-2与t-1年的准确率均达到100%;郑玉华等[5]在公司财务预警Logistic模型最优分界点实证研究中证明了1∶3,1∶5,1∶10的样本配比均小于0.5。笔者样本配比为1∶4,所以选用0.4作为最优分界点。人工神经网络模型、遗传算法、案例推理、支持向量机等智能模型近年来不断涌现,尽管这些方法具有数据挖掘能力强、预测效率高等优点,但也存在运算复杂、要求大量训练样本、无法对结构进行分析等缺点。所以基于可理解和准确率的综合考虑,笔者选择Logistic模型对选取的指标进行预警。
1 选取样本公司及原始指标
由于上市公司的数据经独立的第三方审计,所以某种程度上指标被认为是可靠的,考虑到控制变量及样本数据的可获取性,笔者选取制造行业2014—2015年首次被ST的31家上市公司作为危机样本,根据配比比例1∶4确定124家未被ST的上市公司作为良好样本。笔者将危机样本定义为“0”,良好样本定义为“1”。
为避免因经验、主观判断选取指标,笔者尽可能多地从偿债能力、盈利能力、现金能力、营运能力及发展能力[6-7]5个方面的45个财务指标及根据数据的可获取性选取7个非财务指标作为原始数据。由于我国证券交易所区分公司是否被ST几乎与上一年度公司年报对外公布在同一时间,即根据上年年报判断本年是否被ST,所以若认为公司在t年被ST,则根据t-1年的指标预测t年是否会被ST有失妥当,所以笔者根据t-2,t-3,t-4年的指标预测公司财务危机发生的概率。对选取指标和预测准确率,笔者均选用SPSS软件包进行筛选,样本和原始指标均取自国泰安数据库,笔者所选指标均来自A类型财务报表,具体如表1所示,其中某些指标之间的相关性较高。
2 选取指标
2.1 逐步回归分析法
逐步回归分析法的基本思想是,在考虑Y对已知的一群变量(X1,X2,…,Xk)回归时,从变量中逐步选出对已解释变差贡献最大的最先进入方程,且最末进入方程的变量也应满足:统计量值Fj的显著性概率p,小于等于选定的置信度水平α(一般为0.05)。
设Z0:λj=0,而设Z1:λj≠0(Z0不成立)。
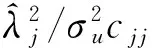
2.1.1 逐步回归分析法选取指标
运用逐步回归分析法进行选取时,选用逐步增加自变量的方法,将置信区间定为95%。各年的输出结果为(按先后顺序):t-2年的X31、X23、X39、X33、X44;t-3年的X39、X27、X25、X15;t-4年的X21、X33、X19、X50、X40。指标的记录以进入回归方程的先后为序,进入回归方程指标的sig均为0.000<0.01,说明每个模型的总体回归效果都是显著的。在t-2年公司的所有指标中盈利能力最先进入预警模型,可见一个公司是否发生财务危机的关键衡量标准是该公司的盈利能力,且在盈利能力中营业净利率又是最先进入预警模型的指标,可知营业净利率是一个企业是否发生财务预警的最关键指标;在t-3年公司的所有指标中衡量现金能力的全部现金回收率最先进入预警模型,可见为了预防财务危机公司应重视收回经营活动中产生的现金,不能为了增加销售额而采取大额赊销,这样可能导致企业资金链断裂;在t-4年财务指标中衡量盈利能力和发展能力的指标进入预警模型,可知较远期间企业是否会发生财务危机主要取决于该企业的盈利能力和发展潜力,且t-4年的非财务指标进入预警模型,可看出非财务指标作为企业文化的一部分对企业发展趋势有潜移默化的影响。

表1 指标及代码
注:X1~X45为财务指标;X46~X52为非财务指标
2.1.2 运用Logistic模型预测准确率
由于因变量Y有2种取值(0、1),所以在SPSS模型中应选用二元Logistic模型进行回归分析,笔者将净利润大于零的定义为1,小于零的定义为0,将净利润作为协变量,分类标准值定为0.4[8],最大迭代次数增加为50(下同)。
对t-2年选中的指标进行回归分析,得出自由度df为6,由于显著性水平为0.05,得出卡方临界值=CHIINV(0.05,6)=12.59,计算出卡方值为99.044,且sig为0.000小于0.05,在0.05的显著性水平下,所以检验通过。笔者计算的最大似然对数值为56.081>12.59,且Cox&SnellR拟合优度为0.472,一般情况下当拟合优度大于0.4时,就认为拟合优度是合格的;作为补充的H-L检验中卡方临界值=CHIINV(0.05,8)=15.51,计算的卡方值为1.876,但是sig=0.985>0.05,所以检验通过。t-2年的预测准确率为92.9%,t-3年的预测准确率为84.5%,t-4年的预测准确率为82.6%。
2.2 主成分分析法
主成分分析法[9]的基本思想是为了降低原始指标的相关性,选用能解释原始变量85%以上但少于原始变量个数的公共因子来解释原始变量。设第i(i=1,2,…,y)个公共因子的因子值ei可由X1,X2,…,Xk的样本值计算出来,即ei=αδi,由于δ是未知的,而e需要计算,在式子两端左乘αT,得αTei=αTαδi,等式左侧正好是αi和ei的内积,而右侧刚好有矩阵R。所以可表达为xi=Rδi。由于δi=R-1xi,从而ei=αδi,可计算出因子值ei。
2.2.1 主成分分析法确定因子
在运用主成分分析法选定公共因子时,笔者选定特征值大于1的因子。t-2年选出12个因子,共解释了89.48%的原始指标。同理t-3年共选出12个因子,t-4年共选出13个因子。
2.2.2 用Logistic模型预测准确率
对t-2年的因子进行回归分析,因为自由度df为13,显著性水平为0.05,可得卡方临界值=CHIINV(0.05,13)=22.36,笔者计算的卡方值为100.885,且sig=0.000<0.05,所以检验通过。Cox&SnellR拟优合度为0.481>0.4,检验合格;作为补充的H-L检验,计算的卡方值为11.412,自由度为8,卡方临界值=CHIINV(0.05,8)=15.51,而sig=0.179>0.05,所以检验通过。t-2年的预测准确率为94.2%,同理t-3年的准确率为82.6%,t-4年的准确率为81.3%。
2.3 均值差异检验
均值差异检验选取指标的步骤为:①用K-S检验区分符合正态分布和不符合正态分布的指标[10];②符合正态分布的指标使用T检验的方法选取出对建立财务预警模型有贡献的指标;③不符合正态分布的数据采用非参数检验中的Mann-Whitney U非参数检验法选取出对建立财务预警模型有贡献的指标。
Man-WhitneyU检验的基本原理:有(x1,x2,…,xa),(y1,y2,…,yb)两组独立样本,把两组样本的序号加总,分别为w1和w2。
2.3.1 均值差异检验选取指标
运用SPSS软件包中的非参数假设检验下K-S检验对数据是否符合正态分布进行区分,在精确检验上采用渐进法,对于缺失值按列表排除个案,在0.01的显著性水平下解释指标。当渐进显著性>0.01时,表明样本与正态分布没有显著差异,即符合正态分布,否则不符合正态分布。可知t-2年符合正态分布的指标是X6、X28、X29、X36、X37、X39、X46、X47、X48、X50;同理,t-3年符合正态分布的指标是X6、X28、X29、X36、X39、X44、X46、X47、X48、X50,t-4年符合正态分布的指标有X6、X28、X29、X36、X39、X46、X47、X48、X50。
独立样本T检验和Mann-WhitneyU检验均遵守显著性结果>0.05时,ST公司与非ST公司的指标不存在显著差异性;反之,存在显著差异性,则该指标最终可以选作该公司的预警模型指标。t-2年检验结果如表2所示。
从表2可看出t-2年众指标中对预警模型有贡献的指标有X1、X2、X3、X4、X5、X6、X7、X8、X15、X19、X20、X21、X22、X23、X24、X25、X26、X27、X30、X31、X32、X33、X34、X37、X39、X41、X42、X43、X44、X45、X49;同理t-3年对预警模型有贡献的指标有X1、X2、X3、X5、X15、X22、X30、X32、X35、X37、X39、X45、X49;t-4年对预警模型有贡献的指标有X1、X2、X15、X20、X21、X22、X24、X25、X30、X32、X34、X49、X51。
2.3.2Logistic模型预测准确率
对t-2年的因子进行回归分析,因为自由度df为30,显著性水平为0.05,可得卡方临界值=CHIINV(0.05,30)=43.77,笔者计算的卡方值为117.356,且sig=0.000<0.05,所以当显著性水平为0.05时,检验通过。Cox&SnellR拟合优度为0.533>0.4,检验合格。H-L检验中,卡方临界值=CHIINV(0.05,8)=15.51,计算的卡方值为1.430,但是sig=0.994>0.05,所以检验通过。t-2年的检验准确率为95.5%,t-3年的预警准确率为83.9%,t-4年的预警准确率为83.9%。
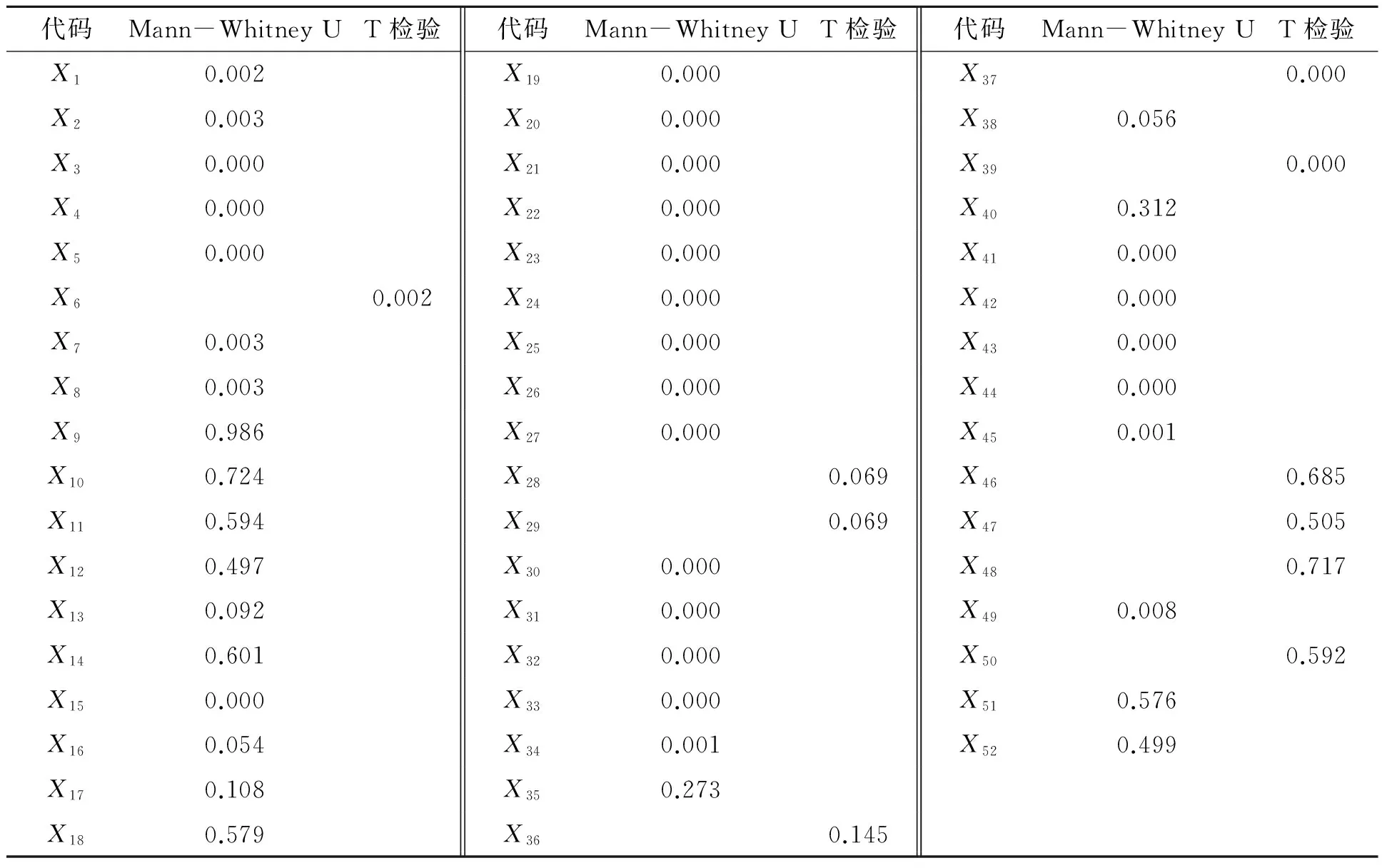
表2 T检验与Mann-Whitney U检验结果
3 结论
笔者着重于研究财务预警模型中的指标选取方法,通过研究得出:t-2、t-3、t-4这3年运用逐步回归分析法的预警准确率分别为92.9%、84.5%、82.6%,运用主成分分析法的预警准确率分别为94.2%、82.6%、81.3%,运用均值差异检验得到的预警准确率为95.5%、83.9%、83.9%。从这3种方法来看,随着被预警年度的接近,预警准确率逐步增加。虽然3种方法的预警准确率较为接近,但是均值差异检验方法的预测效果最好。综上所述,企业在建立财务预警模型时选用均值差异检验方法选取指标,得出的指标更能代表原始指标,以此为基础建立的财务预警模型的预警准确率更高,可为企业避免财务危机作出更大贡献。
[1] ALTMAN E L.Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J]. Journal of Finance,1968,23(4):589-610.
[2] JONES S, HENSHER D A. Predicting firm financial distress:a mixed Logit model[J]. Accounting Review,2004,79(4):1011-1038.
[3] 吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001(6):46-55.
[4] 雷振华.Logistic模型的财务预警准确度检验研究[J].求索,2012(11):54-56.
[5] 郑玉华,崔晓东.公司财务预警LOGIT模型最有分界点实证研究[J].商业研究,2014(6):76-82.
[6] 张新明,钱爱明.财务报表分析[M].北京:中国人民大学出版社,2014:221-238.
[7] 冯丽.非营利性组织财务风险及预警指标体系设计[J].武汉理工大学学报(信息与管理工程版),2012,34(5):629-632.
[8] 鲜文铎,向锐.基于混合Logit模型的财务困境预测研究[J].数量经济技术经济研究,2007,24(9):68-76.
[9] 刘丹,陈丽芳.基于主成分分析的运输型物流企业竞争力研究[J].武汉理工大学学报(信息与管理工程版),2012,34(6):742-745.
[10] 马庆国.管理统计[M].北京:科学出版社,2002:160-327.
WANG Fei:Assoc. Prof.;School of Business, Hohai University, Nanjing 211100, China.
Effect Study of the Indicator Selection Method on the Accuracy Rate of Financial Early Warning
WANG Fei, WANG Jiaojiao
Based on the principle of financial early warning model, firstly,some method is used to elect the highly correlated financial crisis and warning indicators from company's many indicators, and then use these indicators form the expectation ,finally, according to the following annual business indicators on whether the financial crisis to detect.The different select model use different select principle,so the different selection methods to select indicator will form different accuracy. This article uses stepwise regression analysis,principal component analysis and mean difference test to select indicators, then tests the accuracy by Logistic regression model to provide a reference for financial early warning.
financial early warning;stepwise regression analysis;principal component analysis;mean difference test
2095-3852(2017)03-0348-05
A
2016-11-22.
王飞(1959-),男,江苏南京人,河海大学商学院副教授,主要研究方向为财务与会计、金融、税务.
F830
10.3963/j.issn.2095-3852.2017.03.021
