基于聚类分析技术的教师识别过程研究
2017-06-10陈春燕叶枫
陈春燕,叶枫
(蚌埠医学院 卫生管理系,安徽 蚌埠 233000)
基于聚类分析技术的教师识别过程研究
陈春燕,叶枫
(蚌埠医学院 卫生管理系,安徽 蚌埠 233000)
分析合肥10所学校学生的考试试卷,从试卷知识点和试卷成绩两个方面共提取5类特征,使用这5类特征进行教师识别,进而验证教师对学生成绩的影响。从试卷成绩方面提取3类特征,分别是班级均得分率*试题难度、得分率分段比例、错选项比例;从试卷知识点方面提取2类特征,分别是班级均掌握情况、知识点/抽象能力掌握情况分段比例。将这5类特征作为特征向量,使用聚类分析的方法进行教师识别,实验结果表明识别正确率达到73%。
聚类分析;教师识别;特征提取
本文通过数据挖掘技术对学生考试试卷分析,对不同班级的任课教师进行识别,把这个过程称之为教师识别。进一步验证不同老师是否对学生的成绩有影响,如果识别率高,可以间接说明老师对学生的成绩有影响。数据为合肥10所学校学生的考试数据,十所学校分别标记为A、B、C、D、E、F、G、H、I、J,每所学校的班级数分别是15、8、11、6、14、8、9、12、3、4。数据中包括每个班的人数,试卷情况和每个学生每一题的得分情况。为了能够顺利完成识别任务,进行了以下五方面的工作。
一、学生诊断
学生诊断的主要工作是考察学生对知识点的掌握程度,使用DINA模型①Brian W Junker and Klaas Sijtsma,"Cognitive assessment models with few assumptions,and connections with nonparametric item response theory",Applied Psycho-logical Measurement,Vol.25,No.3,2001,pp.258-272. Louis V DiBello,Louis A Roussos,and William Stout,"31a review of cognitively diagnostic assessment and a summary of psychometric models",Handbook of statisticsNo1.26,2006,pp.979-1030.进行学生诊断。DINA模型以学生各小题得分以及各小题的考察知识点/抽象能力标注为输入,通过数学模型来推导学生对知识点/抽象能力的不同掌握情况下的后验概率,借助最大化似然度的方法来估计学生的具体掌握情况。DINA模型假设学生的知识点/抽象能力掌握程度是离散的二元值,即掌握或不掌握。在这里利用每一种掌握模式下的后验概率来对结果进行平滑,将学生的掌握程度变为一个连续的概率值(0~1之间),从而得到每一个学生的知识结构的量化分析,用Xitk表示学生对知识点的掌握程度,k表示第k个班级,i表示第i个学生,t表示第t个知识点。每个学生对于每个知识点的掌握程度,选取一小部分如表1所示。

表1 每个学生知识结构量化分析
二、试卷诊断
试卷诊断是确定试卷的难度系数,本文中应用IRT模型进行试卷诊断。IRT模型以学生在试卷上的表现为输入,答对为1,答错为0。将学生在该题目上答对的概率用项目反应函数②戴海琦,罗照盛:《项目反应理论原理与当前应用热点概览》,《心理学探新》2013年第33期,第392-395页。晏子:《心理科学领域内的客观测量——Rasch模型之特点及发展趋势》,《心理科学进展》2010年第8期,第1298-1305页。表示,即用学生能力与该题难度的logistic函数来表示。然后用极大似然估计对IRT模型进行拟合,得出学生参数(能力)和试题参数(难度)①KONG Q C,MAO W J.,"Predicting popularity of forum threads based on dynamic evolution",Journal of Software,Vol.25,No.12,2014,pp.2767-2776.陈春燕,张钰,常标等:《基于ARMA模型的在线电视剧流行度预测》,《计算机科学与探索》2016年第3期,第425-432页。。试卷难度系数,选取一小部分如表2所示。

表2 试卷难度系数
三、特征提取
共提取5类特征,学生成绩在试卷方面的情况提取三类特征,试卷知识点情况提取两类特征。
(一)试卷成绩方面特征
1.班级均得分率*试题难度
首先计算每个学生在每道试题上的得分率(学生得分/试题分值),然后求班级在每道试题上的均得分率,最后乘以试题的难度,得到第一类特征T1,如公式(1)所示:
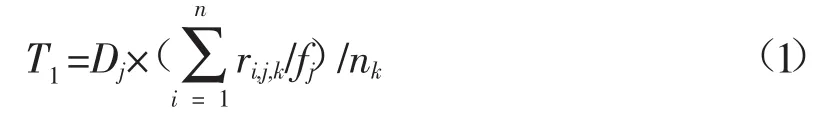
其中ri,j,k为学生在每道题上的实际得分,i指第i个学生,j指第j题,k指第k个班级,fj为第j题的试题分值,nk为第k个班级人数,Dj为第j题的试题难度。
2.得分率分段比例
第二类特征是得分率分段比例,客观题和主观题分别计算。客观题的得分只有两种情况,完全得分或不得分,所以得分率只有0或者1,因此只需计算得分率为0的学生所占的比重,自然就有了得分率为1的学生的比重。主观题的得分是连续值,得分率范围为0~1,所以对学生的得分情况进行分段,本文中把主观题得分率分为三段,分别为0、0~0.7、0.7~1,然后计算班级内落在每个分段上的学生所占的比重。
把第二类特征表示为T2,客观题和主观题分别计算。
客观题分为两段计算得分率分段比率,得分率为0的比例记为T20,得分率为1的比例记为T21,如公式(2)、(3)所示:

其中,T20为该题得分率为0的比例,T21为该题得分率为1的比例,S0jk为第k班第j题得分为0的学生人数,nk为第k个班级的学生人数。
主观题分为三段计算得分率分段比例,得分率为0的比例记为T20,得分率为0~0.7的比例记为T22,得分率为1的比例记为T21,如公式(2)、(4)、(5)所示:

其中,S7jk为第k班第j题得分率为0~0.7的学生人数,nk为第k个班级的学生人数。
3.错选项比例
第三类特征是错选项比例,这类特征只针对选择题,针对每个错选项,计算班级内选该错选项的学生所占的比重,每题正确选项有一个,错选项有三个,因此第三类特征T3分三次计算,分别记为T3x,x取值为1、2、3。
第三类特征记为T3x,表示如公式(6)所示:

其中,Sjxk为第k班第j题选第x个错选项的学生人数,nk为第k个班级的学生人数。
(二)试卷知识点方面特征
1.班级均掌握情况
第1节学生诊断工作中,计算了每位同学,针对每个知识点/抽象能力的掌握情况。因为本文是要识别两个班级的学生是否为同一名老师所带,所以需要知道针对每个知识点/抽象能力,班级的平均掌握情况。
第四类特征记为T4,如公式(7)所示。

其中,Xitk为第k班第i个学生对第t个知识点的掌握程度,nk为第k个班级学生人数。
2.知识点/抽象能力掌握情况分段比例
知识点/抽象能力的掌握情况为连续值,取值范围在0~1之间。为了有更好的区分度,本文中将知识点/抽象能力的掌握情况分段表示,分为四段,分别是0~0.35、0.35~0.5、0.5~0.55、0.55~1。针对每段计算班级内落在此段的学生比重,即为班级掌握情况分段比率。
第5类特征记为T5,本文把学生掌握情况分为四段,所以分四次计算。掌握情况在0~0.35、0.35~0.5、0.5~0.55、0.55~1之间的每班学生比例分别记为T50、T51、T52、T53,如公式(8)(9)、(10)、(11)所示。

其中,Q0t、Q3t、Q5t分别为第k班对第t个知识点,学生掌握情况落在0~0.35、0.35~0.5、0.5~0.55这三段中学生的人数,nk为第k个班级学生人数。
四、特征分析
在选取特征过程中,使用TPP方法辅助特征的选择②罗芬,丁树良,胡小松等:《基于IRT若干参数估计方式的比较》,《江西师范大学学报》(自然科学版)2003年第27期,第56-60页。,以T1特征为例,最初选取了班级均得分率,实验表明聚类效果类间距离较大。把特征1作了改变,使用班级均得分率*试题难度,实验结果表明比直接使用班级均得分率类内数据靠拢效果显著。班级均得分率和班级均得分率*试题难度使用TPP方法结果如图1所示。其它四类特征也使用TPP方法进行了分析,实验表明本文所提取的5类特征进行聚类分析,数据靠拢效果都比较显著。

图1 班级均得分率VS班级均得分率*难度系数
五、教师识别
教师识别的过程其实就是做聚类分析的过程①ROGER W,ALEXANDRE T,INDIKA P.Autoregressive moving average models under exponential power distributions.Probstat forum,pp.65-77.张晓,周敏:《基于K-means算法的教师评价研究》,《伊犁师范学院学报》(自然科学版)2015年第4期,第59-63页。,每个班级都抽取以上5类特征,用这五类特征表示班级,即选取这5类特征,使用EM算法进行聚类②Xu R,Wunsch D,"Survey of clustering algorithms,Neural Networks",IEEE Transactions on,Vol.16,No. 3,2005,pp.645-678.,将一个中学的所有班级划分为了若干簇,同一个簇内的班级的授课教师相同。如果相同教师教的班级真在同一个簇,则这些班级识别正确,对应班级后加1。
实验结果如表3所示,给出了合肥市A学校15个班级的数学课程的聚类结果,该校共有15个班级,有11个班级识别正确,4个班级识别错误,正确率达到了73%。
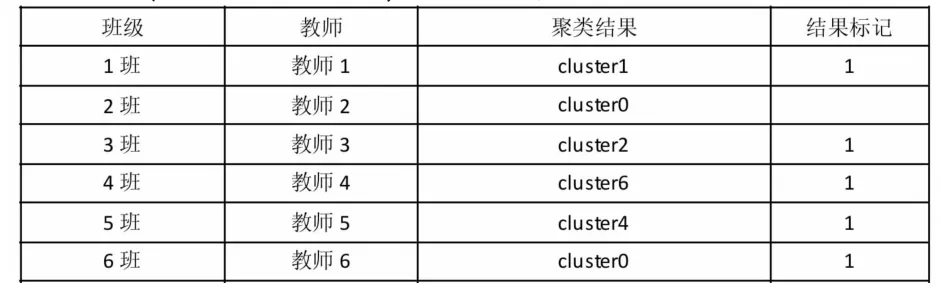
表3 合肥A学校15个班级识别结果
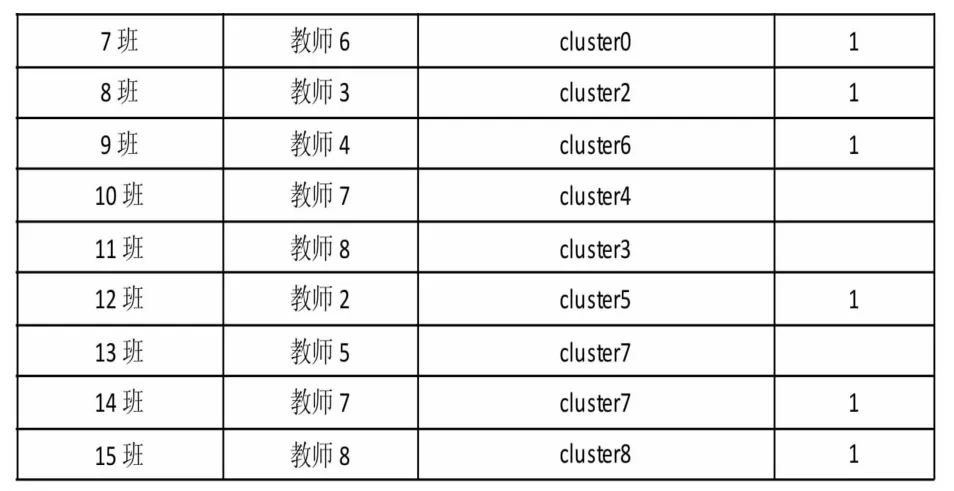
表3中共有4个班级没有识别正确,如5班识别正确,但13班没有识别出来,原因在于13班是快班,而5班是慢班,各题班级均得分率如图2所示,由于快慢班的影响导致识别错误,下一步争取消除快慢班的影响。
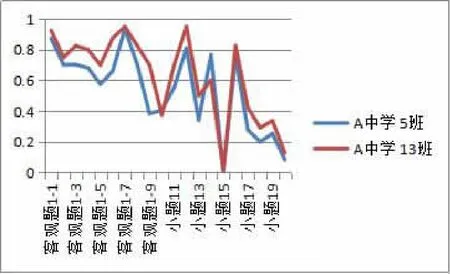
图2 快慢班班级均得分率
六、总结
本文分析学生考试成绩,试图从考试成绩中提取有效特征进行教师识别,在分析比较多种特征后,最终确定从试卷成绩和试卷知识点方面提取5类特征进行聚类分析,用于识别两个班的学生是否为一个老师所教。实验准确率达到73%,还有部分班级没有准确识别,原因是快慢班的影响,同一个老师同时带一个快班和慢班,不能准确识别。下一阶段的工作主要考虑消除快慢班的影响,争取能够把快慢班是由同一个老师教的情况准确识别。
Teacher recognition process research with clustering analysis technology
CHEN Chunyan,YE Feng
The paper analyzed the students'test papers in ten schools in Hefei.Five types of features were extracted from testing scores and examination paper knowledge.The five types of feature were used to proceed teacher recognition,judge whether teachers had an impact on students'achievement.The three types of features were mean scoring rate of class*item difficulty,scoring rate segment ratio and wrong option ratio from testing scores.The two types of features were class mean mastery and knowledge point mastery segment ratio from examination paper knowledge.Taking the five types of features as feature vector,the author used clustering analysis technology to proceed teacher recognition.The experimental results showed that the recognition accuracy reached 73%.
clustering analysis;teacher recognition;feature retraction
TP399
A
1009-9530(2017)02-0122-03
2017-01-04
安徽省高校人文社科研究重点项目(SK2017A0182)
陈春燕(1981-),女,蚌埠医学院卫生管理系讲师,硕士。
