支持语义信息挖掘的热点路径探测
2017-06-10滕巧爽秘金钟孙尚宇
滕巧爽,秘金钟,孙尚宇
(1.辽宁工程技术大学,辽宁 阜新 123000; 2.中国测绘科学研究院,北京 100830)
支持语义信息挖掘的热点路径探测
滕巧爽1,秘金钟2,孙尚宇1
(1.辽宁工程技术大学,辽宁 阜新 123000; 2.中国测绘科学研究院,北京 100830)
针对现有热点路径探测算法存在缺乏对轨迹语义信息进行分析的问题,提出一种支持语义信息挖掘的热点路径探测算法:首先研究轨迹数据语义空间的建模方法,并据此构建低维语义子空间来计算轨迹数据语义相似度,描述轨迹所属移动对象的社会角色的相似性,最后结合基于轨迹流与轨迹密度的传统热点路径探测算法实现对不同社会角色对应的热点路径的发现。结果表明,该算法能够较好利用轨迹数据的时空和语义信息,有效识别出不同社会角色对应的热点路径的聚类特征,为个性化的位置服务研究提供参考。
热点路径;轨迹流;轨迹密度;轨迹语义相似度;社会角色
0 引言
随着移动定位、无线通信等技术的不断发展和普及,面向不同应用领域的智能终端时刻都会产生大量的轨迹数据。这些数据中包含着丰富的信息,能够用于发现交通状况、移动对象的出行规律等。因此,近年来与之相关的数据挖掘研究受到越来越多的关注,热点路径探测就是其中之一。热点路径是指多个移动对象频繁经过的路径[1],反映了移动对象的活动规律及对某地理区域的关注程度[2]。从轨迹数据中发掘出热点路径,可为城市规划、交通管理等领域提供决策支持[3-5]。
常用的热点路径探测方法主要包括以下几种:轨迹聚类、移动对象聚类、流量密度与连通性分析等。其中:轨迹聚类是依据相似度对轨迹进行聚类分析,进而发现热点路径;移动对象聚类则是分析移动对象的分布模式,将聚类中的轨迹认定为热点路径;而流量密度与连通性分析通过计算相邻路径的密度可达性来确定热点路径。这些方法主要是对原始轨迹数据的数值特性、空间特性和时间特性进行分析处理,而忽略了其语义特征,难以在探测热点路径的同时发掘其潜在语义信息。挖掘轨迹的时空和语义信息,可以发现其所属移动对象的社会角色特性,结合热点路径的探测算法,即可得到不同社会角色对应的热点路径,进而为不同移动对象提供针对性的服务。
本文提出一种支持语义信息挖掘的热点路径探测算法,首先研究轨迹数据语义相似性的计算方法,进而借鉴流量密度与连通性分析的方法实现对不同社会角色对应的热点路径的空间分布探测。
1 理论基础

定义2 轨迹[7]:1条轨迹TR={trid,p1,p2,…,pn}为1个按时间排列的点序列,其中trid表示该轨迹的唯一标识符,pi=(xi,yi,ti)分别表示pi点的地理位置及采样时间。
定义3 轨迹段[6]:1个轨迹段SubTR={trid,sid,pkpk+m}表示1条轨迹中落于相同路段上的连续轨迹点的集合,即pi.trid=pj.trid,pi.sid=pj.sid(∀i,j:k≤i,j≤k+m)。如图1所示,1条轨迹依照路段划分为3个轨迹段SubTR1、SubTR2、SubTR3。


2 支持语义信息挖掘的热点路径探测
2.1 轨迹数据语义相似性度量
轨迹数据中包含丰富的时空和语义信息(如经过的区域类型信息),有助于从移动对象的活动规律中发现隐含的社会角色信息,如从轨迹中获知移动对象早上6:00—7:00出现在政府机关办公室,则其社会角色倾向于是清洁人员,而早上8:00—12:00出现在政府机关办公室的移动对象则更可能是公务人员。挖掘轨迹的语义相似性可以发现轨迹间在空间、时间和语义维度上的邻近程度[8],即2条轨迹在某时间段内经过同种类型区域的概率大小,概率越大,表明其相应的社会角色越接近,便于轨迹依照其隐含的社会角色信息进行聚类[9-11]。为探测不同社会角色对应的热点路径,本文在获取轨迹数据的语义信息后,首先采用奇异值分解(singular value decomposition,SVD)构建轨迹数据的语义空间,然后通过轨迹数据的潜在语义信息的欧式距离度量其相似性。
2.1.1 轨迹数据语义信息获取
本文所指的轨迹语义信息是指其经过的区域类型信息,可以采用如下方法获取:通过调用百度应用程序编程接口(application programming interface,API)获取与轨迹点直线距离最短的地理标签,借鉴文献[12]的方法,即使用语义代替词并通过考虑关键候选词的语义信息来提高关键词提取性能的方法,来提取所得地理标签的关键词,并按照图3所示的分级图对其进行分类,最终得到轨迹点所属的区域类型,将其作为轨迹点的空间语义信息。
2.1.2 轨迹数据语义空间建模
面对海量轨迹数据,本文采用建立轨迹语义空间模型的方法进行数据的存储和分析,即统计某时间段内每条轨迹经过的区域类型及相应的次数,并将其按照一定顺序排列,来构建轨迹语义特征矩阵。假设输入n辆车的轨迹,每辆车的轨迹gj(1≤j≤n)占矩阵1列,每种区域类型vi(1≤i≤10)占矩阵1行,构成1个10×n的轨迹语义特征矩阵X为

(1)
式中:矩阵元素xi,j(1≤i≤10,1≤j≤n)表示轨迹j在某时间段内经过区域类型i的次数。由于交通堵塞等原因,可能出现连续多个轨迹点的地理标签相同,显然不能认为是多次经过,在统计时应只计数1次。该方法将非结构化的轨迹数据转化为结构化的数据矩阵进行存储,结合潜在语义分析,有望发现轨迹数据的语义相似度,为挖掘轨迹数据的社会角色特征提供支持。
2.1.3 轨迹数据语义相似度计算
为满足大规模轨迹数据的处理需求,本文首先采用SVD去除轨迹语义特征矩阵X中的噪声和冗余信息,生成低维潜在语义空间来描述元素间的语义结构,在此基础上选取欧氏距离计算两两轨迹间的相似程度并利用计算结果构建轨迹相似度矩阵。上述方法可提高后续计算相连路段间的轨迹语义相似度的准确性和运算效率,降低探测不同社会角色对应的热点路径的搜索时间。
根据SVD原理[13-14],首先将轨迹语义特征矩阵X分解成3个矩阵U、Σ、VT,即
X=UΣVT。
(2)
式中:对角矩阵Σ=diag (σ1,σ2,σ3,…,σr)(r=rank (X))中包含了矩阵X的奇异值,并按照从大到小的顺序排列;正交矩阵U=(u1,u2,u3,…,ur)和V=(v1,v2,v3,…,vr)的列向量分别为XXT和XTX的特征向量。
然后提取U与V中前k个列向量和Σ中前k个最大的奇异值,得到式(3)所示的降维矩阵Xk,其为原始矩阵X在秩为k条件下的最小二乘意义上的最优近似,可反映原始矩阵的绝大部分信息,即
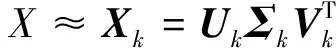
(3)
式中维数k的选取与奇异值的大小相关。若奇异值(σ1,σ2,…,σk)的平方和累积达到所有奇异值平方和的90 %,则认为这个k值是合适的。

(4)
式中A [i]、B [i](i=1,2,…,k)分别表示轨迹A、B的潜在语义序列。整理所有计算结果最终可生成如下所示的对称的轨迹相似度矩阵为
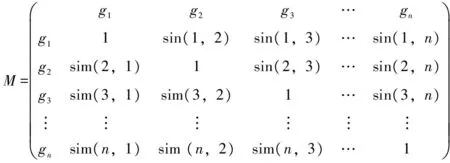
(5)
2.2 热点路径探测2.2.1 轨迹数据划分
首先采用文献[15]的算法在综合考虑轨迹曲线与路径曲线的相似性、路段几何拓扑和连通性的基础上进行轨迹数据的地图匹配,之后采用(trid,sid,x,y,t)的形式存储轨迹点信息,并根据定义3将轨迹划分成若干轨迹段。例如针对轨迹TRk={tridk,p1,p2,…,pn},需从p1到pn依次检查每2个连续轨迹点的sid,若pi.sid≠pi+1sid,则可使用2个轨迹点pi、pi+1所在路段的连接点对轨迹进行划分,重复该过程至每个轨迹段中轨迹点的sid均相同。
2.2.2 热点路径检测算法
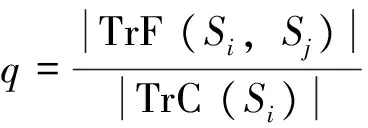
(6)

(7)
依据式(5)的轨迹相似度矩阵,即可计算2个相连路段Si、Sj间的轨迹语义相似度m,m的值越大,表示经过2个路段的轨迹所对应的社会角色越接近,计算方法为
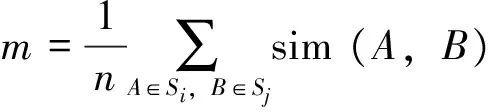
(8)
探测不同社会角色对应的热点路径时,可采用算法为:
1)衡量所有路段的“热度”和经过该路段的轨迹间的语义相似性,计算方法如式(9)所示,选择获得最大值的路段作为初始路段,即

(9)

2)评价初始路段与其指定一侧邻接路段间的轨迹语义相似度、连通性及邻接路段的使用频率,计算方法如式(10)所示,选取获得最大值的路段作为初始路段的连接路段,即
F=wqq+wkk+wmm。
(10)
式中:权重wq、wk、wm为1/3;q、k、m分别表示轨迹流、轨迹密度和轨迹语义相似性。
3)重复使用式(10),依次获得上一次式(10)运算结果的连接路段,直至式(10)计算结果为空,即没有连接路段,至此获得初始路段一侧的连接路段集。
4)重复步骤2)和3),获得初始路段另一侧的连接路段集,将初始路段和2侧的连接路段集存储于1个数据集中,并将其从原始路网数据集中剔除,不再参加其后的运算。设置阈值C,当经过所得路段集的轨迹数目小于C时,则将其删除。
5)重复步骤1)~4),直至路网数据集为空,获得若干热点路段集。
采用以上算法获取热点路径时,可能会出现如下问题:利用式(9)和式(10)选取初始路段及连接路段时,有若干路段对应的计算结果相同且为最大值。针对初始路段的选择问题,本文采用随机选取的原则,即可任意选择1个计算结果为最大值的路段作为初始路段。而面对连接路段的选择问题,以图4选取路段S的连接路段为例,本文遵守如下4条原则:
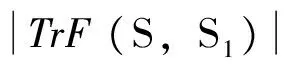
2)分别计算待选连接路段S1、S4另一侧邻接路段上的轨迹段数目,比较max(TrC(S2)、TrC(S3))与max(TrC(S5),TrC(S6)),选取最大值对应的唯一待选连接路段,否则参照原则3)。
3)计算路段S与待选路段S1、S4间的轨迹语义相似度m (S,S1)和m (S,S4),选取获得最大值的唯一的连接路段,否则参照原则4)。
4)若前3条原则均无法确定,则可任意选择1个待选连接路段作为最终结果。
3 实验与结果分析
本文使用微软亚洲研究院收集的部分GPS轨迹数据作为实验数据集,该数据集包含13:00—17:00间经过北京三环内区域的60条GPS轨迹数据,共计240 281个轨迹点,其覆盖的路网包含61 442个路段。
基于以上数据集,经过轨迹数据的地图匹配与划分之后,首先采用上文所述的轨迹数据语义信息获取方法得到轨迹点所属的区域类型信息,即可根据式(1)所示方法构建10×60的轨迹语义特征矩阵;其后对该矩阵运用SVD分解成3个矩阵,并依据所得奇异值计算确定维数k为2,进而生成降维语义空间;以此为基础采用式(4)所示方法便可得到两两轨迹间的语义相似度,整理计算结果即可得到形如式(5)所示的60×60的轨迹相似度矩阵;在此基础上采用上文所述的热点路径检测算法,综合考虑轨迹流、轨迹密度和轨迹语义相似性3种因子,最终探测到如图5(a)所示的9条热点路径,每条热点路径均代表着一类社会角色在一定时空范围内经常行驶的路线。其中实验阈值C设置为5,通过计算9条热点路径上的轨迹数目的平均值得到。
针对该数据集,在不考虑轨迹语义特征的情况下,采用流量密度与连通性分析最终获得如图5(b)所示的10条热点路径。通过对比图5(a)和图5(b)可知,2种方法探测到的热点路径大致相同,图5(a)可认为是基于轨迹的语义特征对图5(b)进行分析重组的结果,验证了本文算法的合理性。
4 结束语
本文在综合考虑轨迹流、轨迹密度和轨迹语义相似性3种因子的基础上,提出了一种支持语义信息挖掘的热点路径探测算法,实现了对不同社会角色对应的热点路径的发现。实验结果表明,该方法有效利用了轨迹数据的时空和语义特性,充分反映移动对象的社会角色和运动模式。但是本实验的结果仅给出了1个时间段内的若干条热点路径,并未对其他时间段内的热点路径进行分析,并且对热点路径的社会角色属性挖掘得不够深入,后续将展开进一步研究。
[1] 锻炼,李峙,胡宝清.时空约束下的热点路径空间分布检测算法[J].计算机工程与设计,2014,35(3):861-866.
[2] 吴俊伟,朱云龙,库涛,等.基于网格聚类的热点路径探测[J].吉林大学学报(工学版),2015,45(1):274-282.
[3] 曹政才,韩丁富,王永吉.面向城市交通网络的一种新型动态路径寻优方法[J].电子学报,2012,40(10):2062-2067.
[4] 马林兵,李鹏.基于子空间聚类算法的时空轨迹聚类[J].地理与地理信息科学,2014,30(4):7-12.
[5]HUNGCC,PENGWC,LEEWC.Clusteringandaggregatingcluesoftrajectoriesforminingtrajectorypatternsandroutes[J].TheVLDBJournal, 2011, 24(2):169-192.
[6]HANB,LIUL,OMIECINSKIE.Road-networkawaretrajectoryclustering:integratinglocality,flowanddensity[J].IEEETransactionsonMobileComputing, 2015, 14(2): 416-429.
[7] 邹永贵,万建斌,夏英.基于路网的LBSN用户移动轨迹聚类挖掘方法[J].计算机应用研究,2013,30(8):2410-2414.
[8] 廖律超,蒋新华,邹复民,等.一种支持轨迹大数据潜在语义相关性挖掘的谱聚类方法[J].电子学报,2015,43(5):956-964.
[9] 马宇驰,杨宁,谢琳,等.基于轨迹时空关联语义和时态嫡的移动对象社会角色发现[J].计算机研究与发展,2012,49(10):2153-2160.
[10]袁书寒,陈维斌,傅顺开.位置服务社交网络用户行为相似性分析[J].计算机应用,2012,32(2):322-325.
[11]LIJ,QINQ,XIEC,etal.Integrateduseofspatialandsemanticrelationshipsforextractingroadnetworksfromfloatingcardata[J].InternationalJournalofAppliedEarthObservationandGeo-information, 2012, 19(5): 238-247.
[12]方俊,郭雷,王晓东.基于语义的关键词提取算法[J].计算机科学,2008,35(6):148-151.
[13]刘云峰,齐欢,代建民.基于潜在语义空间维度特性的多层文档聚类[J].清华大学学报(自然科学版),2005,45(增刊1):1783-1786.
[14]LANDAUERTK,DUMAISST.Latentsemanticanalysis[J].AnnualReviewofInformationScience&Technology, 2008, 3(11): 683-692.
[15]李清泉,黄练.基于GPS轨迹数据的地图匹配算法[J].测绘学报,2010,39(2):207-212.
Hot routes detection based on semantic information mining
TENGQiaoshuang1,BEIJinzhong2,SUNShangyu
(1.Liaoning Technical University, Fuxin, Laoning 123000, China;2.Chinese Academy of Surveying and Mapping, Beijing 100830, China)
Aiming at the problem that it is lack of the analysis on semantic information of trajectories in the existing algorithms of hot routes detection, the paper proposed a detection method supporting semantic information mining: firstly, the modeling method of semantic space of trajectory data was studied; secondly, the low-dimensional semantic subspace was constructed to compute the semantic similarity which describes the comparability of the social roles of the moving objects; finally, combined with the traditional hot routes detection algorithm based on trajectory flow and density, the discovery of hot routes corresponding to different social roles was realized.Result showed that the proposed method could make use of the spatial-temporal and semantics information of the trajectory data, and effectively identify the clustering characteristics of the hot routes corresponding to different social roles, which would provide a reference for related study on personalized location-based services.
hot routes; trajectory flow; trajectory density; trajectory semantic similarity; social roles
2016-08-16
国家863计划项目(2015AA124001);中国测绘科学研究院基本科研业务费支持项目(7771604);国家重点研发计划项目(2016YFB0502105)。
滕巧爽(1990—),女,辽宁沈阳人,博士研究生,研究方向为位置服务、数据挖掘。
滕巧爽,秘金钟,孙尚宇.支持语义信息挖掘的热点路径探测[J].导航定位学报,2017,5(2):27-31,37.(TENG Qiaoshuang,BEI Jinzhong,SUN Shangyu.Hot routes detection based on semantic information mining[J].Journal of Navigation and Positioning,2017,5(2):27-31,37.)
10.16547/j.cnki.10-1096.20170205.
P228
A
2095-4999(2017)02-0027-06
