基于频繁项集与协同过滤的混合推荐方法
2017-06-01宋威刘朋
宋威,刘朋
(1.北方工业大学 计算机学院,北京 100144;2.大规模流数据集成与分析技术北京市重点实验室,北京 100144)
基于频繁项集与协同过滤的混合推荐方法
宋威1,2,刘朋1
(1.北方工业大学 计算机学院,北京 100144;2.大规模流数据集成与分析技术北京市重点实验室,北京 100144)
为解决协同过滤方法存在的评分稀疏及用户喜好程度区分能力不足的问题,提出一种基于频繁项集与协同过滤的混合推荐方法RFICF(Recommendation based on Frequent Itemset and Collaborative Filtering)。在频繁项集的基础上,分别给出了补充评分和增强评分的定义,扩充了评分的数量,细化了评分的数值。在此基础上,分别使用基于频繁项集的推荐方法和协同过滤方法,并按一定比例展现结果。将提出的方法分别与协同过滤、基于频繁项集的推荐方法及相关的混合推荐方法进行了实验比较,结果表明,RFICF方法在覆盖率、准确率以及综合测度3个参数上的整体效果良好。
推荐系统;频繁项集;协同过滤;评分修订
0 引言
作为解决信息超载问题的重要手段,推荐系统[1-2]已成为当前多领域交叉的热点研究内容,在社交网络[3-4]、现代教育[5-6]等诸多领域有着广泛的应用。不但各大社交网站、大型电子商务系统都不同程度地使用了各种形式的推荐系统,而且推荐系统的应用平台也由原来的PC机向智能手机等移动终端发展[7-8]。
作为应用最广泛的推荐技术之一,协同过滤[9]根据相似历史评分将有可能评分最高的若干项目推荐给目标用户。根据相似度计算对象的不同,协同过滤一般可以分为基于用户的方法[10]和基于项目的方法[11]。最近还出现了一些同时综合考虑用户与项目的混合推荐方法[12]。
尽管学者们提出了多种方法,但现有的协同过滤方法依然存在如下两方面的问题:从评分数量上讲,用户评分数据稀少,造成了相似性计算的依据不足,影响了推荐质量。从评分形式上讲,多数网站的评分都是使用1至5这5个整数,使得计算得到的评分结果对用户喜好程度的区分能力有限。
为解决这两个问题,提出了一种基于频繁项集与协同过滤的混合推荐方法。使用频繁项集来发现大多数用户共同喜好的项目,进行评分修订:一方面,补充缺失评分,丰富相似性的计算依据;另一方面,细化用户喜好程度的评分,提高推荐结果的个性化程度。此外,将基于频繁项集的推荐结果作为协同过滤的补充,构建了混合推荐方法。实验结果表明,提出的方法能有效提高推荐质量。
1 混合推荐方法
1.1 整体流程
提出的基于频繁项集与协同过滤的推荐方法RFICF的整体流程示意如图1所示。

Fig.1 Overall flow of RFICF图1 RFICF方法的总体流程
如图1所示,RFICF方法首先从原始数据中挖掘频繁项集,然后将频繁项集与用户的评分向量做匹配,并分已匹配项目和未匹配项目两种情况做评分修订处理。这种处理使得一般只有5个整数的评分分值更加细化,不但可以在一定程度上解决协同过滤的数据稀疏问题,而且修订后的分值可以作为基于频繁项集推荐方法的结果排序标准。最后,按比例将协同过滤和基于项集的方法的结果推荐给用户。
1.2 基于频繁项集的评分修订
为解决协同过滤方法存在的评分稀疏及用户喜好程度区分能力不足的问题,提出了基于频繁项集的评分修订方法。一方面,基于多数用户的评分情况可以补充用户对未评分项目的评分,使得协同过滤的计算依据更加充分;另一方面,针对用户已评分的项目,将5个整数值的评分细化为实数值,从而更好地区分用户的喜好程度。此外,这种处理方式能够得到更长的用户评分向量,有利于解决冷门项目推荐中的长尾效应问题[13]。
设I={i1, i2, …, ip}是项的集合,集合X⊆I称作项集。数据库D={T1, T2, …, Tq}是事务的集合,其中每条事务Tj(1≤j≤q)是项集[14]。频繁项集主要由支持度(support)来评价,其定义如下:

(1)
由式(1)可知,项集X的支持度即为数据库中包含X的事务的数量。给定最小支持度阈值min-sup,频繁项集挖掘就是发现那些支持度不低于min-sup的全部项集。
对推荐系统而言,全部项目的集合即为I,而用户的评分向量的集合则构成了D,通过使用常用的频繁项集挖掘算法[14-15]即可得到用于推荐的频繁项集。
针对目前常用的用1-5这5个整数来表达用户喜好程度的数据集,本节讨论的评分修订分两种情况:一种是补充评分,另一种是增强评分。这两种情况均建立在匹配项集集合的基础上。
定义1 假设USt是目标用户ut的评分向量,FI是全体频繁项集的集合,USt的匹配项集集合定义为MS(ut)={S | S∈FI∧ USt⊂ S}.
由定义1可知,匹配项集集合是由包含目标用户评分向量的频繁项集所组成的集合。
由于频繁项集是全体用户中超过一定比例的用户的共性选择,因此目标用户选择存在于能够与其评分向量相匹配的频繁项集中未评分的项目的概率也较大,故补充这些项目的评分,可以为协同过滤提供更加充分的依据。

(2)
其中:α(ut, ik)称为ut对ik的补充评分系数,定义为:
(3)

根据定义2,我们可以为与目标用户相匹配的频繁项集中的未评分项目,补充一个(3, 5)区间内的实数评分,从而丰富目标用户的评分向量,为协同过滤提供更充分的依据。
对目标用户已评分的不低于3分的项目,可以认为是用户较喜欢的,做评分增强处理,用实数来取代整数,使这种喜好程度更加细化。
定义3 给定目标用户ut及其评分向量USt,项集X∈MS(ut),项目ik∈USt,若ut对ik的评分3≤Rt,k≤5,则ut对ik的增强评分定义:
(4)
其中:β(ut, ik)称为ut对ik的增强评分系数,定义为:
(5)

由定义3可知,通过计算用户较喜欢的评分的增强评分,可以把原来的3、4、5这3个喜好程度细化到(3, 5]区间内的实数值,从而更加精细的表达用户的喜好。
1.3 协同过滤
协同过滤方法假设具有相似评分历史的用户的喜好也相似,一般由用户-项目评分矩阵Rm×n描述,如表1所示。
表1中,每一行代表1个用户对不同项目的评分,每一列代表不同用户对1个项目的评分,每个元素Rp,q代表该行对应的用户up对该列对应项目iq的评分,体现了用户对项目的喜好程度。

表1 用户-项目评分矩阵
用户ua与目标用户ut的相似程度由Pearson相似性计算。
(6)
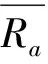
给定目标用户ut,根据式(6)计算使sim(ua,ut)值最大的前K个用户,构成ut的邻居集合NN(ut),目标用户ut对项目ik的预测评分为:
(7)
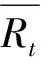
最后,协同过滤方法将根据式(7)计算得到的预测评分最高的一组项目推荐给目标用户。
1.4 基于频繁项集的推荐
在推荐方法RFICF中,频繁项集不但可以作为协同过滤的评分修订方法,还可以与协同过滤一样,作为推荐方法之一。

1.5 算法描述
算法1描述了推荐方法RFICF的流程。需要说明的是,RFICF方法最终的推荐结果由协同过滤和基于频繁项集的推荐结果按比例组成,假设δ(0≤δ≤1)是协同过滤结果的推荐比例,则基于频繁项集结果的推荐比例为(1-δ)。

算法1RFICF推荐方法输入用户⁃项目评分矩阵Rm×n,目标用户ut及其评分向量USt,最小支持度阈值min-sup,最近邻居数K,推荐结果的个数N,协同过滤结果的推荐比例δ输出推荐项目集合1挖掘D中的全部频繁项集FI;2根据定义1计算ut的匹配项集集合MS(ut);3forMS(ut)中的每个频繁项集Xdo4 for集合X-USt∩X()()中每个项目ikdo5 根据式(2)计算补充评分;6 endfor7 forUSt中的每个项目ikdo8 根据式(4)计算增强评分;9 endfor10endfor11在经过评分修订后的用户⁃项目评分矩阵R′m×n上做协同过滤,得到结果集合SCF;12基于频繁项集做推荐,得到结果集合SFI;13取SCF中前N×δ个项目,SFI中前N×(1-δ)个项目推荐给ut.
2 实验验证
2.1 实验数据与评测方法
使用MovieLens(http:∥grouplens.org/datasets/movielens)和豆瓣图书评分(http:∥www.datatang.com/data/42832)两个数据集验证提出的方法。MovieLens数据集包含1 000个用户对1 700部电影的评分记录,每条记录包括4个字段:用户ID、电影ID、1-5评分、时间戳。豆瓣图书评分数据集包括382 033个用户对89 908本书籍的评分记录,每条记录包括3个字段:用户ID、图书ID、1-5评分。每个数据集选择80%的数据作为训练集,其余20%的数据作为测试集,训练集和测试集数据的特性如表2所示。

表2 训练集与测试集数据的特性
我们使用平均绝对偏差(MeanAbsoluteError,MAE)、覆盖率(Coverage)、准确率(Precision)以及综合测度(F-measure)4个参数来评价算法的性能,其定义分别如下:
(8)
其中:{p1, p2, …, pN}是计算得到的用户评分集合,{q1, q2, …, qN}是用户实际的评分集合,N表示评分项目的数量。

(9)

(10)
(11)
其中:US为用户喜好的项目集合,RS为推荐的项目集合。
由于RFICF推荐方法中使用了支持度sup、邻居数量K和协同过滤结果的推荐比例δ这3个需要人为设定的参数,通过实验确定了MovieLens数据集上这3个参数使用的具体值,结果如表3至表5所示。

表3 MovieLens数据集上不同支持度下MAE的变化情况
由表3可以看出,在支持度由50增加到175的过程中,MAE值在支持度取100时,达到了最低值0.921 2,故在MovieLens数据集上RFICF方法的支持度取100。

表4 MovieLens数据集上不同邻居数量下MAE的变化情况
表4给出了MAE值随邻居数变化而变化的情况。可以看出,在最近邻数量由5增加到45的过程中,MAE值呈现出波动的趋势,当最近邻数量为10时,达到了最低值0.889 1,故在MovieLens数据集上RFICF的邻居数量K取10。
2.4 两组患者治疗前后凝血功能指标 治疗前,两组PLT比较,差异无统计学意义(P>0.05),治疗后,治疗组PLT显著下降(P<0.05),对照组PLT无明显降低,两组间比较差异无统计学意义(P>0.05);两组治疗前后PT、APTT比较,差异无统计学意义(均P>0.05)。见表4。

表5 MovieLens数据集上不同协同过滤结果的推荐比例下MAE的变化情况
表5给出了MAE值随RFICF中协同过滤结果的推荐比例的变化而变化的情况。可以看出,当协同过滤结果占全部结果的70%时,MAE取最小值0.878 2,故在MovieLens数据集上RFICF的δ取70%。
采用同样的方法,验证了在豆瓣图书评分数据集上,3个参数的取值分别为:sup=60,K=25,δ=80%。
2.2 与协同过滤方法的比较
将提出的RFICF推荐方法与经典的协同过滤方法[16]进行了比较,结果如表6和表7所示。
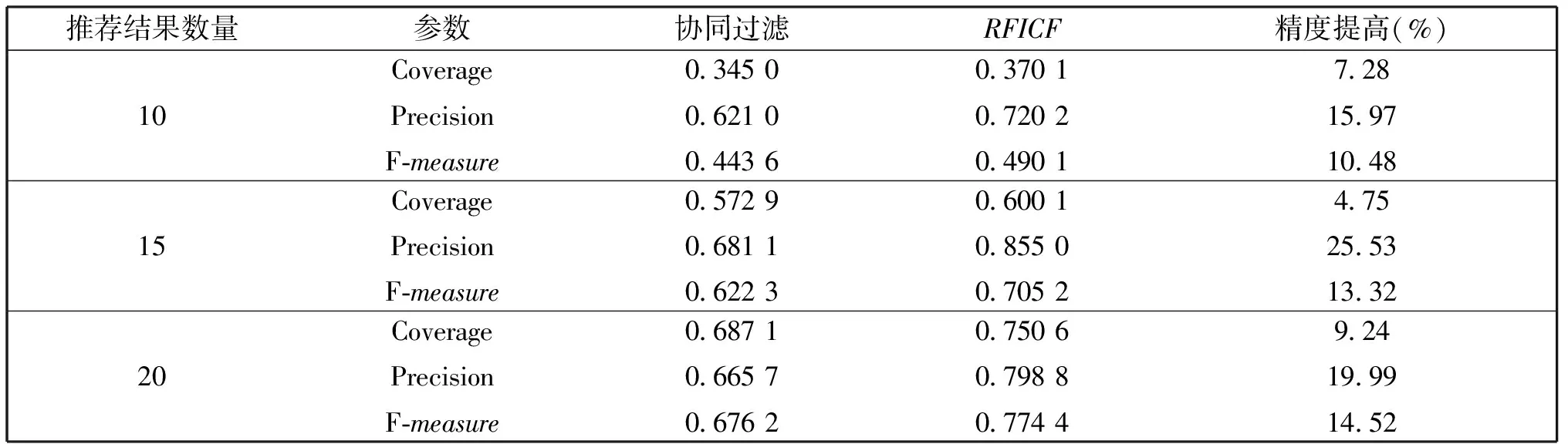
表6 MovieLens数据集上RFICF与协同过滤方法的比较结果
表6给出了推荐不同数量的结果时,RFICF推荐方法与经典的协同过滤方法的性能比较结果,其中:最后1列的“精度提高”的数值由公式(12)计算得到:
(12)
其中:AR和AC分别代表RFICF和对比方法的覆盖率或准确率或综合测度。
表7至表11中最后一列的精度提高同样是由式(12)计算得到的。
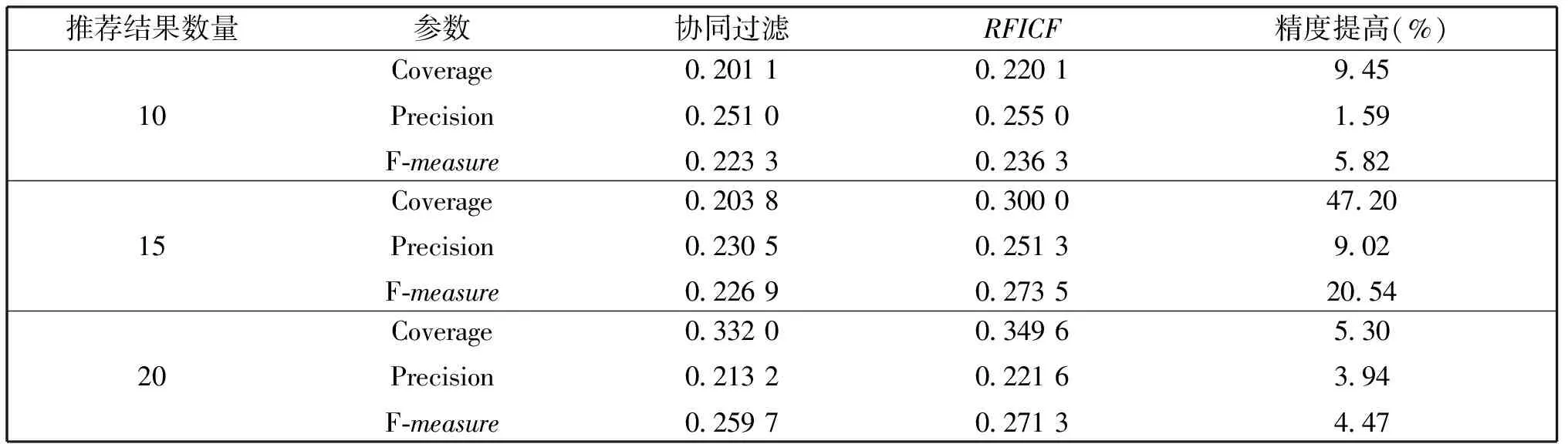
表7 豆瓣图书数据集上RFICF与协同过滤方法的比较结果
由表7可以看出,豆瓣图书数据集上两种方法的覆盖率依然随着推荐结果数量的增加而提高,这点可以由公式(9)得到解释,即推荐的结果越多,其中用户喜好的项目也越多。但与表6的结果不同,综合测度不再满足这样的规律。尽管两种方法的3个参数的结果低于MovieLens数据集上的相应参数的结果,但RFICF推荐方法的性能依然都优于协同过滤方法。由此也可以看出,使用基于频繁项集的推荐方法作为协同过滤方法的补充,的确可以有效提高推荐质量。
2.3 与基于频繁项集的推荐方法的比较
将提出的RFICF推荐方法与经典的基于频繁项集的推荐方法[17]进行了比较,结果如表8和表9所示。

表8 MovieLens数据集上RFICF与基于频繁项集的方法的比较结果
由表8可以看出,在MovieLens数据集上,RFICF推荐方法的推荐效果要明显优于基于频繁项集的推荐方法,如:当推荐结果数量为15时,RFICF的准确率比基于频繁项集的推荐方法的准确率高93.46%。产生这一现象的主要原因在于,尽管基于频繁项集的推荐方法使用了一定比例之上用户的共同选择,但没有考虑用户对不同项目的不同喜好程度,从而导致了其推荐结果的个性化程度有限。

表9 豆瓣图书数据集上RFICF与基于频繁项集的方法的比较结果
由表9可以看出,在豆瓣图书数据集上,当推荐结果数量为10和20时,基于频繁项集的推荐方法的覆盖率优于RFICF方法。这主要是由于,相对于MovieLens数据集,豆瓣图书数据集的评分非常稀疏,使得协同过滤方法中相似性计算的依据不足,而由2.1节可知,RFICF方法中80%的结果恰恰是由协同过滤得到的。尽管如此,表9的结果也可以证实RFICF方法在准确率和综合测度两项指标上,还是明显优于基于频繁项集的方法。
2.4 与其它基于关联规则和协同过滤的混合推荐方法的比较
将提出的RFICF推荐方法与其它基于关联规则和协同过滤的混合推荐方法[18]进行了比较,结果如表10和表11所示。为说明问题方便,我们将比较方法记为RARCF。
由表10可以看出,提出的RFICF推荐方法的覆盖率、准确率和综合测度均优于基于关联规则与协同过滤的混合推荐方法RARCF,而且随着推荐结果数量的增加,综合测度的精度提高也越来越大。其原因在于,RARCF方法中,关联规则的评价依然是基于支持度、置信度和兴趣因子3个参数计算得到的,这3个参数体现的是全体数据的一般统计规律,依然无法反映推荐结果的个性化程度。而提出的RFICF推荐方法则通过补充评分降低了数据的稀疏程度,通过增强评分细化了评分数值,能够有效提高推荐结果的个性化程度。

表10 MovieLens数据集上RFICF与RARCF方法的比较结果

表11 豆瓣图书数据集上RFICF与RARCF方法的比较结果
由表11可以看出,当推荐结果数量为10时,对比的RARCF的性能优于RFICF方法。这主要是由于豆瓣数据集不但比较庞大,而且较为稀疏,因此在推荐结果数量较少时,RFICF方法中基于频繁项集的评分修订的效果不够明显。由2.1节可知,豆瓣数据集上RFICF的10条推荐结果中有2条是基于频繁项集产生的,而这2条的效果影响了RFICF方法的整体性能。而当推荐结果数量为15和20时,RFICF方法则全面优于RARCF方法。此外,豆瓣图书数据集上的结果还表明,RFICF方法的综合测度在推荐结果数量为15时达到最优。其原因在于,豆瓣图书数据集上用户间评分向量的长度差别比较大,导致推荐数量过多或过少都会影响推荐质量。
3 结论
提出了一种基于频繁项集与协同过滤的混合推荐方法。针对评分缺失及评分程度过粗的问题,使用频繁项集分别定义了补充评分和增强评分,用于修订原始用户-项目评分矩阵的值。分别描述了协同过滤与基于频繁项集的推荐方法,并给出了混合方法的算法描述。通过在公开的数据集上与相关工作的实验比较分析,验证了方法的有效性。
[1]JannachD,ZankerM,FelfernigA,et al.RecommenderSystems:AnIntroduction[M].Cambridge:CambridgeUniversityPress,2010.
[2] 杨博,赵鹏飞.推荐算法综述[J].山西大学学报(自然科学版),2011,34(3):337-350.DOI:10.13451/j.cnki.shanxi.univ(nat.sci.).2011.03.001.
[3]LiuY,ZhaoP,ShengVS,et al.RPCV:RecommendPotentialCustomerstoVendorsinLocation-BasedSocialNetwork[C]∥Proceedingsofthe16thInternationalConferenceonWeb-AgeInformationManagement,2015:272-284.DOI:10.1007/978-3-319-21042-1-22.
[4]JiangS,QianX,MeiT,et al.PersonalizedTravelSequenceRecommendationonMulti-SourceBigSocialMedia[J].IEEETransactionsonBigData,2016,2(1):43-56.DOI:10.1109/TBDATA.2016.2541160.
[5]DascaluMI,BodeaCN,MihailescuMN,et al.EducationalRecommenderSystemsandTheirApplicationinLifelongLearning[J].Behaviour & IT,2016,35(4):290-297.DOI:10.1080/0144929X.2015.1128977.
[6]Hoic-BozicN,DlabMH,MornarV.RecommenderSystemandWeb2.0ToolstoEnhanceaBlendedLearningModel[J].IEEETransactionsonEducation,2016,59(1):39-44.DOI:10.1109/TE.2015.2427116.
[7]BecchettiL,BergaminiL,ColesantiUM,et al.ALightweightPrivacyPreservingSMS-BasedRecommendationSystemforMobileUsers[J].KnowledgeandInformationSystems,2014,40(1):49-77.DOI:10.1007/s10115-013-0632-z.
[8]GongY,WeiL,GuoY,et al.OptimalTaskRecommendationforMobileCrowdsourcingWithPrivacyControl[J].IEEEInternetofThingsJournal,2016,3(5):745-756.DOI:10.1109/JIOT.2015.2512282.
[9]NajafabadiMK,MahrinMN.ASystematicLiteratureReviewontheStateofResearchandPracticeofCollaborativeFilteringTechniqueandImplicitFeedback[J].ArtificialIntelligenceReview,2016,45(2):167-201.DOI:10.1007/s10462-015-9443-9.
[10]LiY,ZhaiCX,ChenY.ExploitingRichUserInformationforOne-ClassCollaborativeFiltering[J].KnowledgeandInformationSystems,2014,38(2):277-301.DOI:10.1007/s10115-012-0583-9.
[11]WangW,YangJ,HeL.AnImprovedCollaborativeFilteringBasedonItemSimilarityModifiedandCommonRatings[C].Proceedingsofthe2012InternationalConferenceonCyberworlds,2012:231-235.DOI:10.1109/CW.2012.40.
[12] 宋威,陈利娟.基于直接评分与间接评分的协同过滤算法[J].计算机工程与设计,2015,36(5):1228-1232.DOI:10.16208/j.issn1000-7024.2015.05.022.
[13] 印桂生,张亚楠,董红斌,等.一种由长尾分布约束的推荐方法[J].计算机研究与发展,2013,50(9):1814-1824.
[14]AgrawalR,SrikantR.FastAlgorithmsforMiningAssociationRulesinLargeDatabases[C]∥Proceedingsofthe20thInternationalConferenceonVeryLargeDataBases,1994:487-499.
[15]SongW,YangBR,XuZY.Index-BitTableFI:AnImprovedAlgorithmforMiningFrequentItemsets[J].Knowledge-BasedSystems,2008,21(6):507-513.DOI:10.1016/j.knosys.2008.03.011.
[16]SchaferJB,FrankowskiD,HerlockerJ,et al.CollaborativeFilteringRecommenderSystems[M].TheAdaptiveWeb,Springer-Verlag,2007:291-324.
[17]ChoYS,MoonSC.WeightedMiningFrequentItemsetsUsingFP-TreeBasedonRFMforPersonalizedU-CommerceRecommendationSystem[C]∥FTRA4thInternationalConferenceonMobile,Ubiquitous,andIntelligentComputing,2013:441-450.DOI:10.1007/978-3-642-40675-1-66.
[18] 郭晓波,赵书良,牛东攀,等.一种解决稀疏数据和冷启动问题的组合推荐方法[J].中国科学技术大学学报,2015,45(10):804-812.DOI:10.3969/j.issn.0253-2778.2015.10.002.
Hybrid Recommendation Method Based on Frequent Itemset and Collaborative Filtering
SONG Wei1,2,LIU Peng1
(1.SchoolofComputerScienceandTechnology,NorthChinaUniversityofTechnology,Beijing100144,China;2.BeijingKeyLaboratoryonIntegrationandAnalysisofLarge-ScaleStreamData,Beijing100144,China)
There are two problems in the field of collaborative filtering,among which one is rating sparsity, and the other is the poor ability to reflect users' different preference. To solve these two problems, a hybrid recommendation method based on frequent itemset and collaborative filtering, named RFICF, is proposed. Based on frequent itemset, complement rating and enhanced rating are defined, which expanding the number of rating and detailing the rating score. Then, recommendation method based on frequent itemset and collaborative filtering are exploited respectively, and their results are displayed according to certain portion.The proposed method is compared with collaborative filtering, frequent itemset-based recommendation and related hybrid recommendation methods.The experimental results show that the overall performance of RFICF is good on the three parameters of coverage, precision andF-measure.
recommender system;frequent itemset;collaborative filtering;rating revision
10.13451/j.cnki.shanxi.univ(nat.sci.).2017.01.006
2016-11-20;
2016-12-03
北京市自然科学基金(4162022);北京市科技计划项目(D161100005216002);北京市优秀人才青年拔尖个人项目(2015000026833ZK04)
宋威(1980-),男,辽宁抚顺人,教授,博士,主要研究方向为数据挖掘、推荐系统,E-mail:songwei@ncut.edu.cn
TP393
A
0253-2395(2017)01-0035-09
