MOOC学习结果预测指标探索与学习群体特征分析
2017-05-30牟智佳武法提
牟智佳 武法提
摘要:高辍学率与低参与度是MOOC面临的一个主要问题。根据学习结果预测,及时开展有效的教学干预是改善此问题的途径之一。当前基于MOOC学习行为数据进行结果预测主要以次数分析为主,较少探索其他行为指标;在预测算法上以回归分析为主,缺少不同预测算法效果的比较分析。以edX平台上一门MOOC课程的学习行为数据为研究对象进行的探索研究发现:学习结果预测的主要参照行为指标组合为视频学习次数、文本学习次数、评价参与时长、評价参与次数和论坛主题发起数;学习次数的预测效果要好于学习时长,并与学习时长和学习次数结合后的预测效果接近; BP神经网络预测准确率要优于决策树和朴素贝叶斯网络,且预测准确率与样本数量呈正相关;而在课程学习模块的预测比较上,评价模块和文本模块的学习行为数据预测率较高,互动模块预测率最低。研究还发现,MOOC学习群体包含三类,分别是以视频学习和学习评价为主、以互动交流为辅的学习群体;以视频学习和文本学习为主、以评价参与为辅的学习群体,以及以文本学习和学习评价为主、以互动交流为辅的学习群体。
关键词:MOOC;学习行为数据;学习结果预测;预测指标;学习群体特征
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2017)03-0058-10 doi10.3969/j.issn.1009-5195.2017.03.008
一、研究缘起
当前国内外越来越多的高校参与MOOC课程建设并发布各自的特色课程,学习者在课程内容上有了更多的选择权,但高辍学率和低参与度仍是当前MOOC课程所面临的一个主要问题(Hew et al.,2014)。而基于学习者前期和中期的课程学习行为数据进行学习结果预测,并依据分析结果调整教学策略和教学内容以开展有效的教学干预,可以改善学习参与度和学习结果。与此同时,学习分析研究已经由初期的理论探讨逐步走向实践探索和成果转化。在学习分析研究中,基于学习行为数据进行学习结果预测是学习分析和教育数据挖掘研究学术群体中关注的一项重要议题(Li?án et al.,2015)。而在数据的选择上,学习分析研究正从关注大数据转向有意义数据的探索(Merceron et al.,2016)。如何抓取到学习活动信息流中的关键行为数据并解析出学习者的个性学习行为特征是今后研究中要解决的一个问题(U.S. Department of Education,2015)。MOOC广泛的学习参与群体和多样化的学习行为数据使其成为学习分析研究的一个重要对象。如何基于MOOC学习行为数据有效预测学生的学习结果,并依据学习群体特征提供差异化的学习服务以改善学习参与度成为亟待解决的问题。本研究基于edX平台的一门MOOC课程学习行为数据,探索能够有效预测学习结果的数据类型和行为指标,并分析学生的群体学习特征,为学习结果预测分析和教学干预提供指导和参照。
二、文献综述
国内关于MOOC学习行为研究主要集中在学习行为影响因素分析、基于学习行为数据分析学习效果、学习成绩预测、学习行为评价等方面。比较有代表性的研究有:贾积有等以Coursera平台上的6门北京大学MOOC课程学习行为数据为分析对象,探索在线时间、观看视频和网页次数、浏览和下载讲义次数、论坛发帖数与学习成绩之间的关系(贾积有等,2014)。李曼丽等以“学堂在线”平台的“电路原理”课程数据为基础,对MOOC学习者的课程学习动机、课程参与度、课程注册时间与课程完成度等进行分析(李曼丽等,2015)。郝巧龙等用Clementine 构建MOOC 成绩预测,并依托智慧树平台“数据结构”课程的行为数据通过回归分析验证模型的有效性(郝巧龙等,2016)。
国外关于MOOC学习行为的研究包括MOOC学习成败和保留率的影响因素分析、学习动机和学习行为对MOOC完成度的影响、学习表现预测研究、学习情境在MOOC学习中的重要性分析等。如:Laxmisha Rai等从学习者角色、个人支持和人为干预、高困难度和自我动机、学习环境、职业需求、教师和学校声望、实时反馈等方面分析了MOOC学习成败的因素(Rai et al.,2016)。Bart Pursel等基于MOOC学习者的人口学数据、学习行为和课程互动数据,采用逻辑斯回归分析探索这些数据变量如何表征课程完成度(Pursel et al.,2016)。Paula Barba等以Coursera平台上的“宏观经济学”课程学习者为研究对象,分析以个人兴趣、掌握方法目标与应用价值为主的学习动机和以视频点击与测评提交数为测量方式的学习参与在学习表现预测上的重要性(Barba et al.,2016)。在学习者参与MOOC学习的数量变化上,研究表明第一周课程教学之后,学习者参与的数量会急剧下降(Hill,2013),因此Suhang Jiang等研究者以学习者第一周的MOOC课程作业表现和社交互动数据为分析对象,并使用逻辑斯回归作为分类器,预测学习者获得课程证书的概率(Jiang et al.,2014)。
从国内外已有研究可以看出,研究者已经基于MOOC常见的学习行为数据进行学习成效分析,探索课程学习成败的内在和外在因素,并对学习者最终学习表现进行预测。然而,在数据分析和预测上还存在以下几方面的不足:(1)学习行为数据中以次数分析为主,应用时间分析较少,两者之间未统一在一个学习分析层面上,对于各自的预测效果还尚不清晰;(2)在预测算法上以回归分析为主,而采用机器学习模式的预测方法较少,且缺少不同预测算法效果的比较分析;(3)对有效预测学习结果的行为指标探索较少,学习行为数据较多,需要找到反映学习结果的关键行为指标为学习分析提供参照。针对上述问题,本研究以MOOC课程学习模块为分类依据,以学习行为数据指标为中心,探索学习时长和学习次数的预测效果、课程学习模块的预测效果、有效学习结果预测指标的提取及其计算方程、学习者的群体学习行为特征等内容,试图为基于MOOC的学习行为分析和教学设计提供有益的启示。
三、研究设计
1.研究问题
当前MOOC平台能够记录学习者的鼠标点击流数据,而在这些数据中时长和次数是两项重要的数据类型。基于学习过程行为数据探索能够反映学习结果的有效数据类型,分析指标和群体行为特征有助于开展针对性的学习干预,改善学习者参与度并降低辍学率。因此,本研究的问题包括以下三方面:(1)在学习行为数据中,学习时长和学习次数统计哪种方式更能较为准确地预测学习结果?哪类课程学习模块数据预测效果较好?(2)各类学习行为数据与学习结果有怎样的相关性?哪些行为指标能够较好地预测学习结果?基于有效学习指标如何得出可计算的学习结果预测计算方程?(3)在课程内容学习上,学习者可以分为哪几类学习群体?这些群体表现出怎样的学习行为特征?
2.研究样本与方法
研究选取edX上的一门MOOC课程“Introduction to Engineering and Engineering Mathematics”为研究对象。该课程是由University of Texas at Arlington大学工程学院Pranesh B. Aswath教授发起,由Alan Bowling、Panos Shiakolas、William E. Dillon、R. Stephen Gibbs等研究者参与讲授的一门工程类基础专业课程。该课程于2015年5月12号在edX平台上线发布,并于同年8月10号结束授课,课程持续14周。该课程的设计目标是为高中学生和大学新生提供工程领域的梗概,以帮助他们在工程学上决策自己的职业生涯。课程授课语言是英语,免费向世界范围内学习者开放。课程成绩评价方式包括每周练习测验(占总成绩40%)、课后作业(占总成绩40%)、综合期末考试(占总成绩20%)。练习测验主要是选择题,由系统平台自动评阅打分,课后作业和综合期末作业由同伴互评和教师评阅打分确定。在课程数据的使用权上,已获得University of Texas at Arlington机构审核委员会(Institutional Review Board,IRB)的使用批准和课程负责人授权,准许使用剔除学生个人信息的数据。
在数据选取上,研究基于edX平台上记录的鼠标点击流数据抽取与行为分析指标有关的时长和次数统计数据。由于平台上涵盖微视频、文本学习材料、互动论坛、学习评价等学习模块和材料,因此学习者的行为活动数据也涉及上述学习活动模块。而在学习行为数据上除时长和次数等较为常见数据外,还有倍速播放、跳帧观看、停留轨迹等信息。这些数据是学习者为获取所需知识和理解内容产生的附属行为,反映的是学习风格和学习偏好行为特征,其对学习结果是否产生普遍影响尚不确定。此外,这些数据在量化计算上缺少统一标准,因此暂不纳入预测分析指标中。综上所述,提取的学习行为指标包括视频学习时长(VD)、视频学习次数(VF)、文本学习时长(TD)、文本学习次数(TF)、互动参与时长(ID)、互动参与次数(IF)、评价参与时长(ED)、评价参与次数(EF)、论坛发帖数(PC)、主题发起数(TC)、回复数(RC)、点赞数(VF)等。在数据预处理上,研究者对学习时长设定一个阈值,即超过该阈值的被认定为离开学习任务,处于非学习状态。设定该值的原因是考虑到学习者在网络学习中的认知行为习惯,即在某一具体知识点中通常不会较长时间一直停留不动,而学习时间较长可能是由于学习者离开学习任务进行其他网络活动以及学习者关掉浏览器但未注销账号造成。在时间阈值设定和估计上,Grabe和Sigler使用多种启发式探索进行时间估计,所有超过3分钟的学习行为时间将被替换成2分钟,在选择题的操作行为时间上最高设定为90秒,每一个模块最后活动时间被估计成60秒(Grabe et al.,2002)。Ryan Baker将超过80秒的活动时间认定为脱离活动行为时间(Baker,2007)。Vitomir Kovanovic等通过对不同时间估计进行对比分析,认为短时间的时间估计和阈值设定对分析结果并没有产生显著影响,反而会对长时间学习者的活动行为分析进行干扰,进而影响分析结果;通过实际对比分析发现将单周模块时间估计阈值设定为1800秒可以在不影响分析结果的前提下尽可能还原学习者的行为状态,发现学习者之间的行为差异(Kovanovi? et al.,2015)。因此,本研究将每周模块学习行为时间阈值设定为1800秒,超过该时间的学习活动时间将被替换。
在有效数据的提取上,研究采用两种方式采集数据样本:一是選取实际参与学习模块的学习者行为数据,剔除在各项学习活动中数据均为0的样本,最终获得8804条大样本数据;二是选取各个学习模块中均有学习者参与活动的数据样本,获得1631条小样本数据。通过大小样本数据的分析,比较不同预测算法的准确率。在研究方法上,分别采用预测分类算法、属性选择、多元回归分析和聚类方法对数据进行分析。其中预测分类算法用于分析学习时长和学习次数在学习结果上的预测准确率;属性选择用于选取能够预测学习结果的有效学习行为分析指标;多元回归分析用于计算有效学习行为指标与学习结果之间的回归系数;聚类分析用于探索学习者的群体行为特征。在研究工具上,选择机器学习分析工具Weka,采用有监督学习方式对数据集进行预测分析;SPSS对数据样本进行显著性差异分析和多元回归分析。
3.研究过程
整个研究过程包括以下6步:(1)采用R工具对edX平台上记录的原始数据进行格式化,并提取不同学习模块中的学习时长、学习次数和论坛互动数。(2)对每周课程内容的学习时长进行处理,超过设定阈值的样本数据将被替换成1800秒,最后统计学习者的学习时长总和。(3)选择决策树、朴素贝叶斯网络和BP神经网络等三种具有代表性的预测分类算法,比较学习时长和学习次数在学习结果预测上的准确率,并分析不同预测分类算法的效果;在此基础上分析不同学习模块在学习结果预测上的效果。(4)采用属性选择,分析不同学习行为分析指标在学习结果预测上的权重顺序以及准确预测学习结果的有效指标组合。(5)采用多元回归分析有效学习结果预测指标的回归系数,并生成学习结果预测计算方程。(6)采用聚类方法分析学习行为的群体特征,探索不同群组学生的学习表现和行为特征。
四、研究结果分析
1.学习时长与学习次数的预测比较
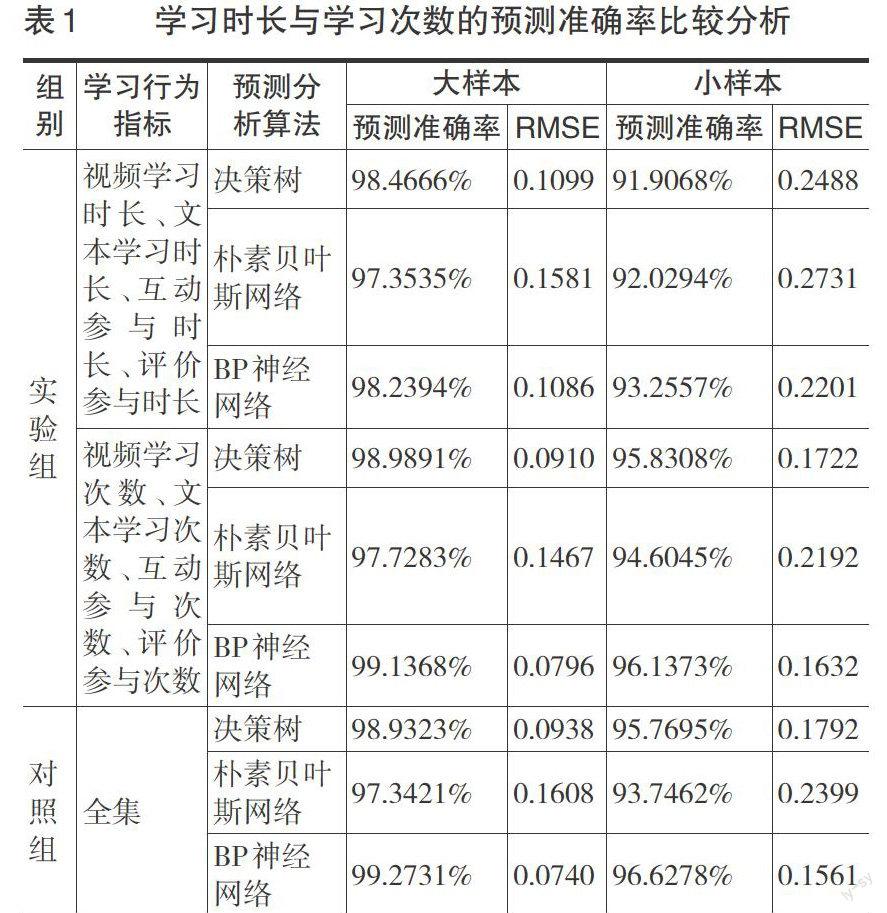
如前所述,学习时长和学习次数是MOOC学习行为活动中的两种主要数据类型,本部分主要分析哪种数据类型更能有效预测学习结果以及不同预测分类算法的预测效果。在学习结果的评判上,由于预测分析算法是以标称型属性作为预测的类别变量,因此这里以学习者是否获得课程证书作为最终成绩判定。在样本均值的差异比较上,因时长数值远高于次数值,故这里不作两种类型指标的显著性差异分析。为了了解不同数据类型独立和综合预测效果,在分析学习时长和次数的预测准确率时,对所有行为指标进行分析以作为参照,预测评估策略选择十折交叉验证,分析结果见表1。预测准确率的误差通过均方根误差值(Root Mean Squared Error,RMSE)来评判。该值通过样本离散程度来反映预测的精密度,其值越小表示测量精度越高。在预测准确率上,大样本预测值要高于小样本预测值,说明预测准确率与样本数量呈正相关,各指标的RMSE值介于0.0740~0.1608,测量精度较高。在数据类型的预测准确度上,学习次数的预测效果要好于学习时长,特别是在小样本分析条件下,平均预测准确率较高,且RMSE值较低。学习时长和学习次数的整体预测效果与学习次数较为接近。在预测分析算法的比较上,尽管小样本分析条件下朴素贝叶斯网络在学习时长的预测准确率要高于决策树,但整体而言BP神经网络预测准确率最高,决策树的预测效果要好于朴素贝叶斯网络。
2.课程学习模块的预测比较分析
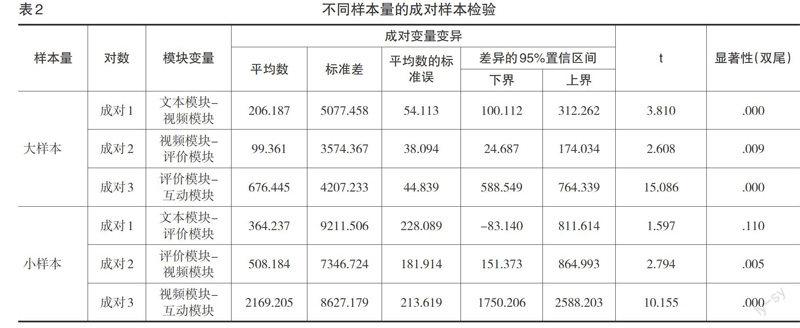
MOOC教学设计者为学习者提供了不同类型的学习材料和支持服务。为了了解不同学习模块在学习结果预测上的效果,研究按学习者参与的活动模块划分学习行为数据。由于不同模块中涵盖的指标类型数据一样,因此在进行预测分析之前需要检验各模块样本数据之间是否存在显著性差异。通过对大样本的均值统计分析可知,各模块均值由高到低排序为文本、视频、评价和互动,而小样本均值排序为文本、评价、视频和互动。在显著性差异比较上,采用相依样本t检验对不同样本量下的模块变量进行分析,结果见表2。在大样本分析情境下,各模块变量差异的95%置信区间未包含0这个数值,应拒绝虚无假设H1:μ1=μ2,接受对立假设H0:μ1≠μ2,且显著性检验概率值p<0.05,表示模块之间有显著性差异存在。在小样本分析情境下,文本模块和评价模块的置信区间涵盖0,显著性检验概率值p=0.110>0.05,表示两者之间无显著性差异存在。整体而言,除小样本中的文本和评价模块无显著性差异之外,各模块变量均有显著性差异,适合对其进行学习结果预测分析。
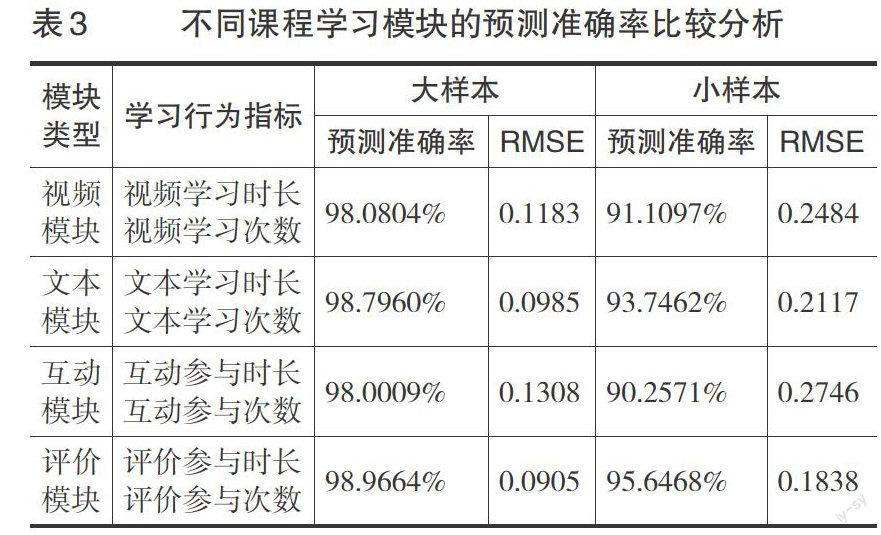
在预测算法选择上,由于BP神经网络算法的学习速度较慢且训练失败的可能性较大,基于前面比较分析结果采用决策树作为预测分析算法,分析结果见表3。在整体预测准确率上,大样本要高于小样本数据,这一结果与前面分析一致。在大样本分析条件下,尽管各学习模块之间的预测准确率相近,区分度较低,但评价模块和文本模块的学习行为数据预测率较高,互动模块预测率最低。在小样本分析条件下,各模块的预测准确率区分度较大,从数值大小对比上,预测准确率顺序与大样本一致。在RMSE值上,评价和文本模块均低于其他模块,说明测量精度较高。可以看出,尽管视频是MOOC网络学习平台中的重要学习材料,但视频学习并不是最能有效预测学习结果的模块,评价模块和文本模块能够较好地预测学习结果。从知识建构视角看,视频学习侧重知识传递,文本学习和学习评价侧重学习者的知识内化,而学习结果测量的是学习者课程知识内化的程度(Pr?itz,2010)。
3.學习结果预测指标的权重与有效组合分析
(1)学习结果预测指标的权重分析
尽管学习行为活动数据有多种类型,但每种行为数据在学习结果上的预测重要程度可能存在差异。我们采用属性排名方法对所有学习行为数据进行权重分析,以验证学习行为指标在预测贡献上的差异性。学习行为数据包括学习活动时长、次数以及论坛互动数在内的12项数据,评估器和搜索方法分别是InfoGainAttributeEval和Ranker,分析结果见表4。在指标权重排序上,大样本和小样本的排序结果基本一致,仅在视频学习次数与文本学习次数、主题发起数和回复数两方面有所交换,评价参与次数、文本学习次数和评价参与时长是两种样本数据下认定的共同重要指标。从两种样本数据的权重比例上看,参与评价、文本学习和视频学习所占的权重比例较高,说明学习者侧重知识内容学习和课程评价,参与互动交流较少。
(2)学习结果预测指标的有效组合分析
前面分析的学习行为指标权重结果说明了各指标在学习结果预测上的贡献度存在差异。在属性组合分析上,有过滤器和包装方法两种方式。前者用低计算开销的启发式方法衡量属性子集的质量;后者通过构建和评估实际的分类模型来衡量属性子集的质量,计算开销大但分析性能较好。这里将应用这两种分析方式对指标进行评估。为了进一步验证筛选后的指标是否提高预测准确率,在进行属性组合分析之后采用决策树预测分类算法对不同属性子集进行预测分析。在样本数和属性子集比较上,同样采用大小样本和全集进行对比参照分析,各项结果见表5。
在大样本分析条件下,采用CfsSubsetEval评估器和GreedyStepwise搜索方法,得到评价参与次数(EF)和发帖数(PC)两个有效行为分析指标组合。采用WrapperSubsetEval评估器和Bestfirst搜索方法得到视频学习次数(VF)、文本学习次数(TF)、评价参与时长(ED)、评价参与次数(EF)、主题发起数(TC)等有效指标组合。在小样本分析条件下,分别采用上述两种方式得到评价参与次数(EF)和主题发起数(TC)组合以及文本学习次数(TF)、评价参与时长(ED)、评价参与次数(EF)与回复数(RC)组合。在评估器类型的比较分析结果上,尽管两种评估器所得到的子集组合存在个别差异,但分类组合结果数量和内容比较接近。CfsSubsetEval评估器侧重选择与目标属性相关性较强的属性子集,同时筛选的子集之间无强相关性,而WrapperSubsetEval评估器综合与目标属性的相关性和筛选子集之间的关联性进行分析,故筛选指标数量多于前者。在评估器的预测准确率上,包装方法(WrapperSubsetEval评估器)在大小样本条件下的预测效果均优于过滤方法(CfsSubsetEval评估器),且筛选后的有效行为分析指标预测准确率要高于所有行为分析指标组合。因此,这里将WrapperSubsetEval评估器在大样本分析条件下所得出的属性子集作为预测学习结果的主要参照行为指标组合,即包括视频学习次数、文本学习次数、评价参与时长、评价参与次数和论坛主题发起数。
4.有效学习结果预测指标的回归方程模型分析
前面采用不同的样本类型和分类器选取有效的学习结果预测指标,尽管筛选的属性子集有所区别,但从内容上能够得出关键行为指标。为了进一步了解各有效组合指标与学习结果之间的回归系数,以便于将学习结果的预测理论分析转变成具有可操作性和可计算性的应用实践,这里将基于有效指标组合与学习结果数据进行多元回归分析。为使分析结果具有可迁移性和应用性,这里选取前面分析得出的有效组合指标作为分析依据,并使用学习成绩作为学习结果评判依据。在回归分析方法上,采用强迫进入变量法的解释型回归分析进行探索,分析结果见表6。由多元回归系数可知,5个预测变量共同解释学习结果变量65.4%的变异量。在显著性分析上,由于预测变量是基于前面属性选择得出的有效行为指标,因此各变量均达到显著性。在共线性统计量上,允差值愈接近于0,说明变量间有线性重合问题,而方差膨胀系数大于10时,则说明变量间有线性重合问题(吴明隆,2010)。上述5个变量的允差值介于0.1~0.5,方差膨胀系数均在5以下,未大于评价指标值10,说明进入回归方程式的自变量间未存在明显的多元共线性问题。在标准化回归系数上,各值均为正数,说明其对学习结果的影响均为正向。从数值大小上看,β系数值越大,表示其对因变量有较高解释力,其排列顺序与前面指标权重分析结果大致相同。基于β系数值我们可以得出标准化回归方程模型:学习结果=0.241×评价参与次数+0.146×评价参与时长+0.119×文本学习次数+0.043×视频学习次数+0.036×主题发起数。依据该方程模型可以为实现MOOC平台自动化预测学生的学习结果提供设计依据。
5.基于学习行为指标的学习群体特征分析
尽管参与MOOC学习的学生群体较多,但基于学习内容习惯和偏好可以将其进行分类,为不同学习群体提供差异化的互动学习材料和实时反馈。这有助于提高学习者参与度(Freitas et al.,2015)。本部分将采用聚类方法对学习行为数据进行族群探索和分析。在样本数上,采用大样本分析以产生显著差异的群体类别。在行为指标选择上,为了全面了解学习行为偏好,将所有行为指标作为分析对象,学习成绩采用数值型属性进行分析。在聚类算法上,采用常用的K均值算法进行分析,该算法接受输入值K,之后将数据划分成指定个数的簇。形成簇的条件是同一簇中对象相似度较高,不同簇中对象相似度较低。为了找到合适的分类群体数量,这里通过设定不同簇个数探索分类数及其百分比,分析结果见表7。可以看出,当簇个数为4时,迭代次数第一次达到最大值,同时平方误差值较低且比较稳定。当簇个数大于4时,得到的分类数及其百分比之间存在相近的类别数,在解释度上比较低。因此,选择簇个数为4的聚类分析结果作为学习群体划分的标准。
对学习行为指标进行聚类分析,结果见表8,各指标中的数值为平均值,其高低反映学习者的投入度。由于互动论坛中的发帖数、主题发起数、回复数、点赞数等数值远低于时长和次数统计,因此在判断互动论坛的投入度时采用相对评价方式,将时长、次数统计与互动论坛数统计分开比较,同时查看互动论坛数的相对值以了解学习群体参与度。由分析结果可知,聚類2和聚类4在学习模块表现上较为相近,可将其合并为一种类型;聚类1和聚类3的互动参与时长和回复数相对其他两类群体较高,因此可将其作为一个参照行为特征。基于上述分析,我们可以将学习群体分为以下三种类型:(1)以视频学习和学习评价为主、以互动交流为辅的学习群体;(2)以视频学习和文本学习为主、以评价参与为辅的学习群体;(3)以文本学习和学习评价为主、以互动交流为辅的学习群体。可以看出,不同的学习群体侧重不同的学习模块,视频学习和学习评价是学习者主要参与的模块,尽管有两类群体参与互动交流,但仅将其作为辅助学习模块,这些学习偏好在一定程度上反映了学习者不同的学习风格。从学习群体的成绩表现来看,优秀学习群体能够积极参与视频学习、文本学习、互动交流和学习评价,且积极参与互动交流的学习群体成绩要高于参与互动交流较低的学习群体,这在一定程度上说明互动交流能够支持学习者的知识建构与内化(Yap et al.,2010)。
五、研究结论
本研究以edX上的一门MOOC课程学习行为数据为分析对象,对不同数据类型、学习活动模块、有效学习行为指标、学习群体特征等进行了探索分析,得出以下6方面的主要结论:(1)在学习结果预测的数据类型上,学习次数的预测效果要好于学习时长,并与学习时长和学习次数结合后的预测效果接近,因此,可通过观察学习次数或综合学习时长与次数来评测学习结果。(2)在预测算法的比较上,BP神经网络预测准确率要优于决策树和朴素贝叶斯网络,但由于各算法在处理能力、噪声容错能力、计算量等方面存在差异,因此需依据不同的应用情境和样本量选择合适的算法分析。在数据样本量的比较上,预测准确率与样本数量呈正相关。(3)在课程学习模块的预测比较上,评价模块和文本模块的学习行为数据预测率较高,互动模块预测率最低。(4)在学习结果有效指标的组合分析上,综合不同评估器和搜索方法的分析结果,视频学习次数、文本学习次数、评价参与时长、评价参与次数、论坛主题发起数是预测学习结果的主要参照行为指标组合。(5)基于WrapperSubsetEval分类器得出的有效组合指标和多元回归分析,得出标准化的学习结果预测回归方程模型为:学习结果=0.241×评价参与次数+0.146×评价参与时长+0.119×文本学习次数+0.043×视频学习次数+0.036×主题发起数。(6)基于K均值算法得出三种类型的学习活动群体:以视频学习和学习评价为主,以互动交流为辅的学习群体;以视频学习和文本学习为主、以评价参与为辅学习群体;以文本学习和学习评价为主、以互动交流为辅的学习群体。
六、研究局限与展望
本研究虽然基于MOOC学习行为基础数据进行了学习结果预测的比较分析,探索了有效学习数据类型、学习行为指标组合、学习结果预测计算方程和群体学习特征,但还存在以下两方面的不足:
(1)當前只应用一门edX上的MOOC课程数据进行分析,研究结论的信度有待进一步验证。今后将选取不同MOOC学习平台以及多学科课程数据作为分析对象进行横向比较和验证分析,探索不同课程学习数据在结果分析上是否有显著差异,以提高研究结论的可靠性。
(2)本研究选取的学习行为数据指标还比较有限,而影响学习结果预测的因素比较复杂。今后将探索其他学习行为数据对学习结果预测的影响,如学生个人的人口学信息数据、学习情感数据等。通过综合多种不同类型的学习活动行为数据进行学习结果预测分析,以找到反映学习结果的关键行为数据和学习行为特质。
参考文献:
[1]郝巧龙,魏振钢,林喜军(2016).MOOC学习行为分析及成绩预测方法研究[J].电子技术与软件工程,(7):167-168.
[2]贾积有,缪静敏,汪琼(2014).MOOC学习行为及效果的大数据分析——以北大6门MOOC为例[J].工业和信息化教育,(9):23-29.
[3]李曼丽,徐舜平,孙梦嫽(2015).MOOC学习者课程学习行为分析——以“电路原理”课程为例[J].开放教育研究, (2):63-69.
[4]吴明隆(2010).问卷统计分析实务——SPSS操作与应用[M].重庆:重庆大学出版社:390-391.
[5]Baker, R. S. J.(2007). Modeling and Understanding Students' Off-Task Behavior in Intelligent Tutoring Systems[A]. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems[C]. New York: Association for Computing Machinery: 1059-1068.
[6]Barba, P. G, Kennedy, G. E., & Ainley, M. D.(2016). The Role of Students' Motivation and Participation in Predicting Performance in a MOOC Motivation and Participation in MOOCs[J]. Journal of Computer Assisted Learning, 32(3):218-231.
[7]Freitas, S. I., Morgan, J., & Gibson, D.(2015). Will MOOCs Transform Learning and Teaching in Higher Education? Engagement and Course Retention in Online Learning Provision[J]. British Journal of Educational Technology, 46(3): 455-471.
[8]Grabe, M., & Sigler, E.(2002). Studying Online: Evaluation of an Online Study Environment[J]. Computers & Education, 38(4): 375-383.
[9]Hew, K. F., & Cheung, W. S.(2014). Students' and Instructors' Use of Massive Open Online Courses (MOOCs): Motivations and Challenges[J]. Educational Research Review, 12(6): 45-58.
[10]Hill, P.(2013). Emerging Student Patterns in MOOCs: A Graphical View[DB/OL]. [2013-03-10]. http://mfeldstein.com/erging-student-patterns-in-moocs-a-revised-graphical-view/.
[11]Jiang, S., Warschauer, M., & Williams, A. et al.(2014). Predicting MOOC Performance with Week 1 Behavior [A]. Proceedings of the 7th International Conference on Educational Data Mining[C]. Worcester: Worcester Polytechnic Institute:273-275.
[12]Kovanovi?, V., Ga?evi?, D., & Dawson, S. et al.(2015). Does Time-on-Task Estimation Matter? Implications on Validity of Learning Analytics Findings[J]. Journal of Learning Analytics, 2(3): 81-110.
[13]Li?án, L. C., & Pérez, ?. A. J.(2015). Educational Data Mining and Learning Analytics: Differences, Similarities, and Time Evolution[J]. International Journal of Educational Technology in Higher Education, 12(3): 98-112.
[14]Merceron, A., Blikstein, P., & Siemens, G.(2016). Learning Analytics: From Big Data to Meaningful Data[J]. Journal of Learning Analytics, 2(3): 4-8.
[15]Pr?itz, T. S.(2010). Learning Outcomes: What Are They? Who Defines Them? When and Where Are They Defined?[J]. Educational Assessment, Evaluation and Accountability, 22(2): 119-137.
[16]Pursel, B. K., Zhang, L., & Jablokow, K. W. et al.(2016). Understanding MOOC Students: Motivations and Behaviours Indicative of MOOC Completion[J]. Journal of Computer Assisted Learning, 32(3): 202-217.
[17]Rai, L., & Chunrao, D.(2016). Influencing Factors of Success and Failure in MOOC and General Analysis of Learner Behavior[J]. International Journal of Information and Education Technology, 6(4): 262-268.
[18]U.S. Department of Education(2015). Ed Tech Developer's Guide[R].Washington, D.C.:64-65.
[19]Yap, K. C., & Chia, K. P.(2010). Knowledge Construction and Misconstruction: A Case Study Approach in Asynchronous Discussion Using Knowledge Construction Message Map (KCMM) and Knowledge Construction Message Graph (KCMG)[J]. Computers & Education, 55(4): 1589-1613.
收稿日期 2017-01-03 責任编辑 汪燕
