基于MAP+CMLLR的说话人识别中发声力度问题
2017-05-24黄文娜彭亚雄
黄文娜,彭亚雄,贺 松
(贵州大学 大数据与信息工程学院,贵阳 550025) (*通信作者电子邮箱yxpeng68 @163.com)
基于MAP+CMLLR的说话人识别中发声力度问题
黄文娜,彭亚雄*,贺 松
(贵州大学 大数据与信息工程学院,贵阳 550025) (*通信作者电子邮箱yxpeng68 @163.com)
为了改善发声力度对说话人识别系统性能的影响,在训练语音存在少量耳语、高喊语音数据的前提下,提出了使用最大后验概率(MAP)和约束最大似然线性回归(CMLLR)相结合的方法来更新说话人模型、投影转换说话人特征。其中,MAP自适应方法用于对正常语音训练的说话人模型进行更新,而CMLLR特征空间投影方法则用来投影转换耳语、高喊测试语音的特征,从而改善训练语音与测试语音的失配问题。实验结果显示,采用MAP+CMLLR方法时,说话人识别系统等错误率(EER)明显降低,与基线系统、最大后验概率(MAP)自适应方法、最大似然线性回归(MLLR)模型投影方法和约束最大似然线性回归(CMLLR)特征空间投影方法相比,MAP+CMLLR方法的平均等错率分别降低了75.3%、3.5%、72%和70.9%。实验结果表明,所提出方法削弱了发声力度对说话人区分性的影响,使说话人识别系统对于发声力度变化更加鲁棒。
说话人识别;发声力度;最大后验概率;最大似然线性回归;约束最大似然线性回归
0 引言
发声力度是一个随着说话人与收听者之间交流距离远近变化的主观生理量,在人们的日常交流中,不可能一直使用同一发声力度[1]。例如,人们试图隐藏说话内容(耳语);交流距离较大,情况紧急(高喊)[2]。不同发声力度下的语音,其声学特征及发音方式存在极大的差异。然而,现在的说话人识别研究中,通常使用正常发声力度下的语音训练说话人模型,所以,当测试语音来自不同发声力度时,训练语音与测试语音便会产生失配,从而导致说话人识别系统识别性能下降[3]。文献[4-5]中,将发生力度由低到高分为5个量级:耳语(whisper)、轻声(soft)、正常(normal)、大声(louder)、高喊(shouted)。
自2010年美国国家标准与技术研究院(National Institute of Standards and Technology, NIST)在说话人识别评测的语料中加入了发声力度的变化后,说话人识别中发声问题逐渐得到关注与研究。文献[5]中提出了基于不同发声力度语音特征,通过语音识别器将耳语与其他语音进行分类,使得耳语在其专门的模型上测试,而其他发声力度语音在同一个模型上测试,但是由于识别器的误差以及其他语音的混杂测试,得到的识别结果不甚理想;文献[6]在说话人识别模型训练阶段,通过使用卷积变换(Convolutional Transformation, ConvTran)等方法训练了一个针对于耳语语音的通用高斯背景模型(Universal Background Model, UBM),使系统性能有了一定提高;文献[7]中,通过使用联合密度高斯混合模型(Gaussian Mixture Model, GMM)映射法补偿梅尔倒谱系数(Mel Frequency Cepstral Coefficient, MFCC)特征,一定程度上改善了高喊语音对说话人系统性能的影响;文献[8]中提出的使用不同的频谱分析计算MFCC特征,但是实验结果表明不同频谱分析方法之间性能差距较小,对说话人识别系统性能提升也不够明显。
与上述研究仅侧重模型层面或特征层面不同,本文将同时从模型与特征着手,基于对不同发声力度下语音的声学特性以及模型分布与偏倚情况的分析,提出了不同发声力度语音可以看作特殊子空间的假设,使用最大后验概率(Maximum A Posteriori, MAP)+约束最大似然线性回归(Constraint Maximum Likelihood Linear Regression, CMLLR)的方法更新模型、投影转换特征,从而解决训练与测试语音失配的问题,提高说话人识别系统性能。
1 不同发声力度下语音信号分析
1.1 正常、耳语、高喊语音声学特性分析
2010年,NIST说话人评测提供给参赛单位的Tarball数据库中,包括了低发声力度、正常发声力度、高发声力度三种情况下的语音,结合在文献[4-5]中对耳语(whisper)、轻声(soft)、正常(normal)、大声(louder)、高喊(shouted)五种量级语音的声学特性的分析以及文献[5]中的说话人识别的结果,本文仅讨论耳语(whisper)、正常(normal)、高喊(shouted)三个量级的语音。
不同发声力度下的正常、耳语、高喊语音其发音方式各有不同。正常语音是通过声带的周期性振动,使声门处的空气流入咽部、口腔、鼻腔产生;耳语语音产生时,声带虽然保持着打开状态但并不发生振动;高喊语音产生时,增加了肺部用力,继而声带产生快速的周期性振动并且带有明显的声音激励[7];同时,由于不同发声力度下的语音其声压、频率、频谱各有不同,从而导致不同发声力度下的语音音量分贝也各有不同[9]。所以从直观角度来看,通过发声方式确定发声力度与通过音量分贝确定发声力度存在着一定的联系。
本文使用同一个人在不同发声力度下对同一句话的演绎,分析正常、耳语、高喊语音的部分声学特征,其宽带语谱与共振峰如图1所示。
首先,由图1可知,耳语语音因其独特的发音方式,不存在基频结构[6];而高喊语音较与正常语音相比,其基频结构向高频位置发生了一定的偏移[10]。其次,频谱能量按照高喊、正常、耳语的顺序由强变弱,且具有耳语、正常、高喊语音频谱能量分别主要分布在高频段、低频段、均匀分布的特点。最后,不同发声力度下的语音共振峰也发生了明显的变化,高喊语音的基频(F0)与第一共振峰(F1)相比正常语音向高频处产生了偏移[6];耳语语音的第一共振峰(F1)和第二共振峰(F2)相比正常语音也向高频处产生了偏移且带宽变宽[11]。
1.2 模型分布可视化
在说话人识别中,特征通过一定的算法被训练为模型。由于在基于高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model, GMM-UBM)的说话人识别系统中,GMM的均值向量最能体现特征在特征空间上的分布特性,所以本文中将采用t-分布邻域嵌入(t-Stochastic Neighbor Embedding,t-SNE)降维算法,将某一高斯混合的均值向量从高维空间按照最大区分的方向,投影到低维度的二维空间上,从而可以直观地观察到同一说话人不同发声力度语音模型均值向量的位置分布以及它们之间相对位置的偏移情况,继而体现出说话人区分性信息的变化。图2是三种语音模型均值向量在二维空间的分布示意图,其中三种语音均取同一个高斯混合进行降维,二维空间的均值向量用(X,Y)表示,nor表示正常语音模型均值向量,wh表示耳语语音模型均值向量,sh表示高喊语音模型均值向量。

图1 三个量级语音的宽带语谱与共振峰
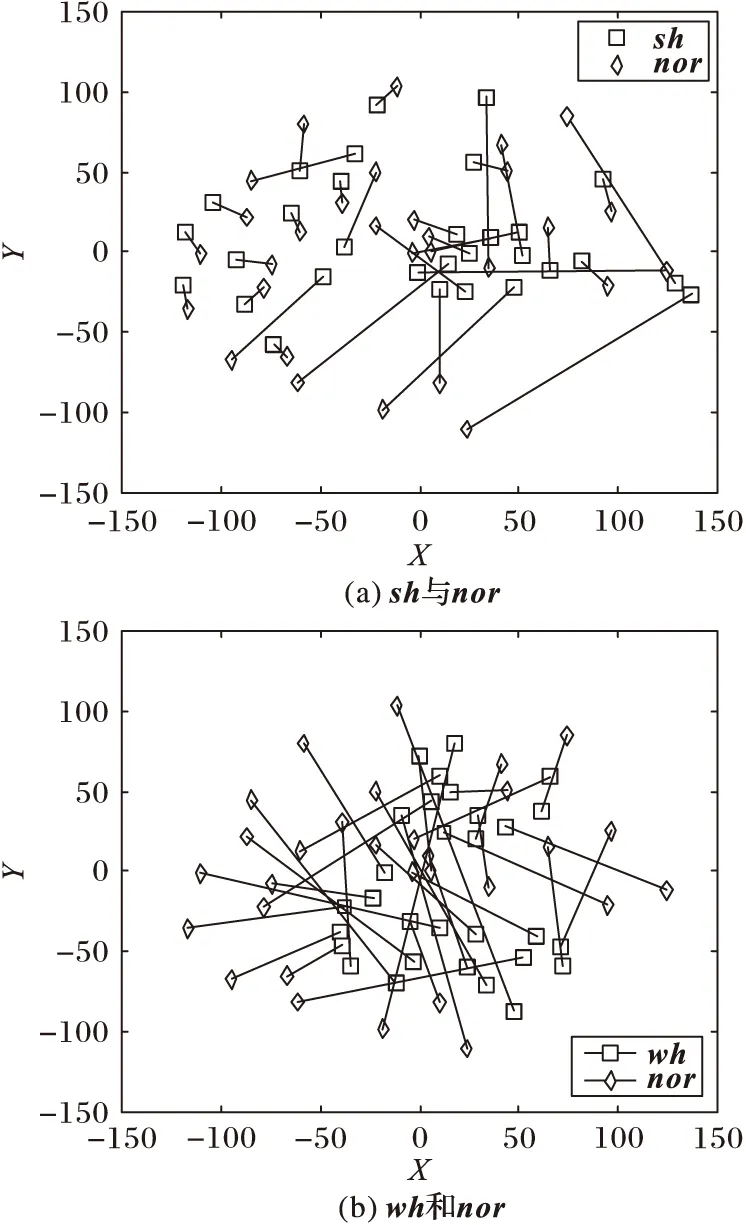
图2 语音模型均值向量在二维空间的分布示意图
图2中,同一个人的不同类型语音模型的均值向量之间由一根直线进行连接,这个线条的长短表示了模型之间的位置的偏移。耳语语音与高喊语音模型分别与正常语音模型存在明显的偏移,且耳语语音与高喊语音模型分别与正常语音模型相互穿插,严重混淆了正常语音的模型分布,使得说话人的区分性降低。
通过对正常、耳语、高喊语音声学特性以及t-SNE降维后三种语音模型位置与相对位置偏移的可视化分析,充分说明了正常、耳语、高喊语音之间存在明显差异。所以,本文提出耳语语音与高喊语音的特征可以看作相对独立且稳定的特殊特征子空间的假设,通过使用模型更新或特征投影转换的方法,学习或削弱耳语、高喊语音的区分性信息,减少耳语、高喊语音区分性信息对说话人区分性的影响。
2 最大后验概率
MAP是一种贝叶斯方法,它引入了模型参数分布的先验信息,利用有限的数据,以模型参数后验概率最大为准则对模型参数进行重新估计。在GMM-UBM框架中,由于参数中均值向量对识别结果的影响最大,所以,在此仅对均值进行重新估计[12]。
(1)
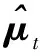
此方案使用前提为训练语音中除了正常语音数据外,还存在少量的耳语、高喊语音数据。MAP自适应方法利用少量的耳语、高喊语音更新了正常语音训练的说话人模型,使更新后的模型学习到了耳语、高喊语音带有的区分性信息,能改善训练与测试语音数据的失配。MAP自适应方法的测试方案如图3所示。

图3 基于MAP自适应方法的说话人识别
3 (约束)最大似然线性回归
假设耳语语音与高喊语音的特征都是一个特殊的独立子空间,并且与原始的正常语音特征空间存在着一定的对应关系,那么就可以用一组与耳语、高喊语音相关的线性变化来使耳语语音与高喊语音分别与正常语音的特征空间相互投影,互相学习之间的区分性信息。最大似然线性回归(MaximumLikelihoodLinearRegression,MLLR)方法最早由剑桥语音小组提出,该方法可以用较少的训练数据学习出两组数据之间的差异得到转换矩阵,从而改善数据之间的偏移。在GMM-UBM框架中,不同混合中的均值向量最能体现说话人的区分性,所以在MLLR的方法中,仅考虑了均值向量的变化,保持协方差矩阵不变。
根据文献[13-14]可知MLLR方法:
μm=Aμ+b=Wξm
(2)
其中:μm代表第m个高斯分量的均值向量,ξm是扩展的均值向量,W是涉及偏移的三角矩阵。用最大似然方法来优化W,得到如下计算公式:
(3)
(4)
(5)
其中:τ代表时间,oi(τ)是在τ时刻特征向量的第i个元素,γm(τ)是oi(τ)属于第m个高斯分量的概率,σm(i)是第m个分量的标准差向量的第i个元素。
该方法使用时,训练语音中无需存在耳语、高喊语音。若MLLR转换矩阵训练有效,那么由正常语音训练说话人模型经过投影转换后,将会学习到耳语、高喊语音的区分性信息,从而改善训练与测试语音的失配问题。MLLR训练测试如图4所示。

图4 基于MLLR模型投影的说话人识别
CMLLR(ConstraintMLLR)方法在MLLR方法的基础上增加一定的约束条件,以实现对说话人模型均值与方差同步更新[15]。CMLLR的学习过程类似于MLLR,但特别的是,由于CMLLR方法认为说话人模型均值与方差共享同一转换矩阵,所以,对模型的转换相当于在特征空间对特征进行转换。若CMLLR转换矩阵有效,那么经过投影转换后的测试语音中的耳语、高喊的区分性信息将会被削弱,所以该方法同样改善了训练与测试语音之间的失配问题。CMLLR方法的测试方案如图5所示。
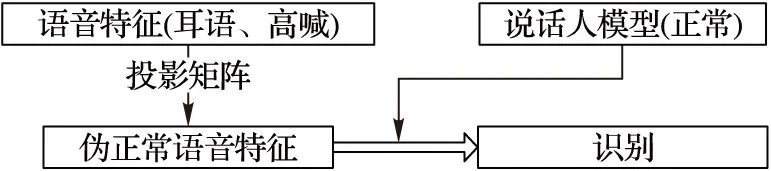
图5 基于CMLLR特征空间投影的说话人识别
4 最大后验概率+约束最大似然线性回归
MAP自适应方法充分使用训练语音中存在的少量耳语和高喊语音数据来更新正常语音训练的说话人模型,使更新后的说话人模型带有耳语、高喊语音的区分性信息,从而改善训练语音与测试语音的失配;而CMLLR特征空间投影方法则是利用较少的包含正常语音、耳语、高喊的训练语音数据学习出两两数据之间的差异,从而生成一个通用的投影矩阵,经过该投影矩阵转换后的耳语、高喊测试语音其带有的耳语、高喊区分性信息将会被削弱,同样实现了改善训练语音与测试语音的失配问题。
虽然MAP自适应方法与CMLLR特征空间投影方法看似是一个相互抵消、矛盾的过程,但实际上这两种方法结合起来共同作用,相当于共同向着削弱与学习耳语、高喊语音区分性信息中间的一个平衡点靠拢,当学习到耳语、高喊语音区分性信息的模型与削弱了耳语、高喊语音区分性信息的测试语音特征达到一个平衡点时,两者相互制衡,说话人区分性信息将得以突出,说话人识别系统性能势必得以提升。将这一方法称为MAP+CMLLR方法, 其方案如图6所示。

图6 基于MAP+CMLLR的说话人识别
5 实验及分析
5.1 基线系统
本实验数据库共由30个人录制,其中男女各15人,包含正常、耳语、高喊三种类型语音,每种语音各22句话。录音环境为安静的实验室环境。说话人识别系统基于经典的GMM-UBM设计,特征为13维的MFCC加上其一阶导数和二阶导数一共39维,并采用倒频谱平均值和方差归一化来减少信道、背景噪声等对识别造成的不良影响。
在整个实验中遵循着同一组实验采用同一组测试数据、同一个基线系统的原则。本实验基线系统以耳语和高喊语音作为测试语音提取其13维的MFCC加上其一阶导数和二阶导数一共39维,分别在正常语音训练的GMM-UBM模型上进行测试。由于不同实验的测试数据的组织不同,导致基线系统性能不同。关于不同的数据组织,将在每组实验前说明。
5.2MAP自适应方法
在MAP自适应方法性能测试实验中,选取全数据库30人,以正常语音(12句)训练说话人模型,正常、耳语、高喊语音(各8句)作为测试语音,耳语、高喊(各2句)作为自适应数据。经过识别打分后,用等错误率(EqualErrorRate,EER)来衡量系统性能,结果如表1所示,更新后模型可视化如图7所示,其中所有模型均值向量取自同一高斯混合,使用t-SNE方法降维到二维空间的均值向量以(X,Y)表示,nor1、nor2表示正常语音模型均值向量,wh表示耳语语音模型均值向量,sh表示高喊语音模型均值向量,MAPwh表示经耳语语音通过MAP自适应方法更新后的正常语音模型均值向量nor2,MAPsh表示经高喊语音通过MAP自适应方法更新后的正常语音模型均值向量nor2。

表1 MAP自适应方法测试性能
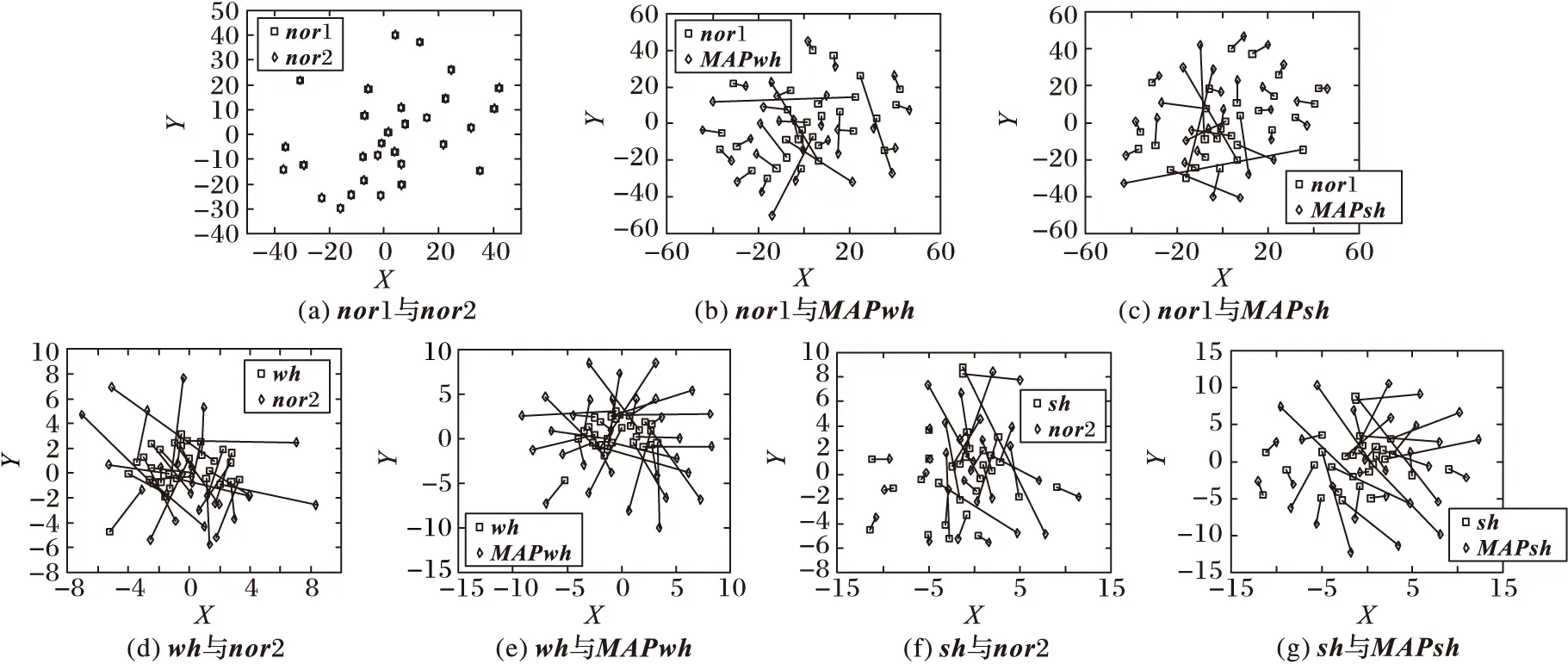
图7 更新后模型可视化
由表1可以明显观察到,当训练语音中存在少量耳语、高喊语音(1条自适应语音)的前提下,MAP自适应方法使得说话人识别系统EER明显降低;并且,随着自适应数据(2条自适应语音)的增多,系统性能稳步提升,体现了MAP自适应方法良好的渐进性。
同时,图7显示了经过更新后模型的均值向量在低维度的二维空间的位置分布,两种语音模型的均值向量之间连接线条的长短表示了模型之间的位置的偏移。由图(b)、(c)分别与图(a)对比可见,耳语语音或高喊语音通过MAP自适应方法更新后的正常语音模型与原正常语音模型之间位置发生了明显的偏移,模型之间相互混杂。由此说明了经过耳语语音或高喊语音MAP自适应更新后的正常语音模型学习到了耳语、高喊语音的区分性信息,从而与原正常语音模型产生了偏移。由图(d)与图(e)、图(f)与图(g)对比可以直观看到,经过耳语语音或高喊语音通过MAP自适应方法更新后的正常语音模型与原耳语、高喊语音模型不再相互混杂,且更新后的正常语音与耳语、高喊语音模型之间的平均距离偏移减小。说明经过耳语语音与高喊语音通过MAP自适应更新后正常语音模型学习到了耳语、高喊语音的区分性信息,从而分别与耳语语音模型、高喊语音模型之间的偏移得到了明显改善。
5.3MLLR、CMLLR及MAP+CMLLR方法
为了满足存在少量耳语、高喊语音情况,此处统一选择耳语、高喊语音各2条作为自适应语音数据,针对全数据库30人,分别选用10人、14人、20人作为开发集,10人作为评估集(12条正常语音训练说话人模型;三个量级各8条语音作测试)。经过识别打分后,用EER来衡量系统性能,测试性能如表2所示。
由表2可知,首先,MLLR方法与CMLLR方法的单独使用均对说话人识别系统有着一定的提升。特别的是,在不同开发集下,CMLLR方法改善效果均优于MLLR方法,并且随着开发集人数增加,MLLR与CMLLR方法改善系统性能效果也逐渐提升。当开发集人数达到20人时,CMLLR方法使得测试语音为耳语、高喊情况下说话人识别系统分别提高了16.6%和12.6%。其次,使用MAP+CMLLR方法对说话人识别性能的提升优于单独使用MAP与CMLLR方法,但是,耳语与高喊使用MAP+CMLLR方法所需开发集人数不同,当开发集人数为14人时,高喊语音使用MAP+CMLLR的方法取得了最佳效果,使其EER比基线降低了85.6%;当开发集人数为20人时,耳语语音使用MAP+CMLLR方法取得了最佳效果,使其EER比基线降低了64.9%。究其原因是因为在发声方式、声学特性等方面,高喊语音相比耳语语音与正常语音更为接近,当对模型更新的自适应语音数据固定时,高喊语音能够通过使用较少开发集人数的转移矩阵达到MAP+CMLLR方法改善性能最优的平衡点。最后,MAP+CMLLR虽然比CMLLR方法性能提升明显,但相比MAP自适应方法提升不是很大,究其原因是MAP自适应方法通过使用测试者语音预留时少量的耳语、高喊语音数据,学习到了丰富的耳语、高喊语音的区分性信息,而且MAP自适应方法具有良好的渐进性,可以使得更新后的正常语音模型非常近似于耳语或高喊语音模型。然而CMLLR方法采用的是与测试者无关的开发集训练的投影转换矩阵对测试语音的耳语或高喊区分性信息进行削弱,其学习与削弱能力不及MAP自适应方法的学习能力。MAP+CMLLR方法是在MAP自适应更新模型的同时利用CMLLR方法对测试语音进行投影转换,使用MAP+CMLLR方法后的说话人识别系统可以看作是一个削弱了一定程度的耳语或高喊语音区分性信息的耳语或高喊测试语音在学习到了丰富耳语或高喊区分性信息的正常语音模型上测试,所以才会出现MAP+CMLLR方法相比MAP自适应方法提升不大,相比CMLLR方法提升明显的现象。

表2 EER性能测试结果对比
6 结语
本文基于对不同发声力度下正常、耳语、高喊语音的声学特征以及其在低维空间中模型分布、模型之间相对位置偏移的分析,讨论了MAP自适应方法、MLLR模型投影方法、CMLLR特征空间投影方法在改善说话人识别系统性能上的使用前提与效果,提出了使用MAP+CMLLR方法实现对说话人模型更新的同时对测试语音进行投影转换。实验结果表明,可以充分利用训练语音中存在少量耳语、高喊语音数据,使用MAP+CMLLR方法,该方法对说话人系统性能改善效果优于单独使用MAP、CMLLR方法,从而使说话人识别系统更具有鲁棒性。
)
[1]TRAUNMÜLLERH,ERIKSSONA.Acousticeffectsofvariationinvocaleffortbymen,women,andchildren[J].TheJournaloftheAcousticalSocietyofAmerica, 2000, 107(6): 3438-3451.
[2] 黄庭.情感说话人识别中的基频失配及其补偿方法研究[D].杭州:浙江大学,2011:136-139. (HUANGT.Researchonpitchmismatchanditscompensationmethodsinemotionalspeakerrecognition[D].Hangzhou:ZhejiangUniversity, 2011: 136-139.)
[3]BRUNGARTDS,SCOTTKR,SIMPSONBD.Theinfluenceofvocaleffortonhumanspeakeridentification[C]//INTERSPEECH2001:Proceedingsofthe7thEuropeanConferenceonSpeechCommunicationandTechnology, 2ndINTERSPEECHEvent. [S.l.]:ISCA, 2001: 747-750.
[4] 晁浩,宋成,彭维平.基于发音特征的声效相关鲁棒语音识别算法[J].计算机应用,2015,35(1):257-261. (CHAOH,SONGC,PENGWP.Robustspeechrecognitionalgorithmbasedonarticulatoryfeaturesforvocaleffortvariability[J].JournalofComputerApplications, 2015, 35(1): 257-261.)
[5]ZHANGC,HANSENJHL.Analysisandclassificationofspeechmode:whisperedthroughshouted[C]//INTERSPEECH2007:Proceedingsofthe8thAnnualConferenceoftheInternationalSpeechCommunicationAssociation. [S.l.]:ISCA, 2007: 2289-2292.
[6]FANX,HANSENJHL.Acousticanalysisandfeaturetransformationfromneutraltowhisperforspeakeridentificationwithinwhisperedspeechaudiostreams[J].SpeechCommunication, 2013, 55(1): 119-134.
[7]HANILÇIC,KINNUNENT,SAEIDIR,etal.Speakeridentificationfromshoutedspeech:analysisandcompensation[C]//ICASSP2013:Proceedingsofthe2013IEEEInternationalConferenceonAcoustics,Speech,andSignalProcessing.Piscataway,NJ:IEEE, 2013: 8027-8031.
[8]POHIALAINENJ,HANILCIC,KINNUNENT,etal.Mixturelinearpredictioninspeakerverificationundervocaleffortmismatch[J].IEEESignalProcessingLetters, 2014, 21(12): 1516-1520
[9] 熊子瑜.Praat语音软件使用手册[EB/OL].[2016- 09- 09].http://www.doc88.com/p-943562730984.html. (XIONGZY.Themanualofpraatspeechsoftware[EB/OL]. [2016- 09- 09].http://www.doc88.com/p-943562730984.html.)
[10]THOMASIB.Perceivedpitchofwhisperedvowels[J].TheJournaloftheAcousticalSocietyofAmerica, 1969, 46(2B): 468-470.
[11] 王琰蕾.基于JFA的汉语耳语音说话人识别[D].苏州:苏州大学,2010:25-28. (WANGYL.SpeakeridentificationinChinesewhisperedspeechbasedonsimplifiedjointfactoranalysis[D].Suzhou:SoochowUniversity, 2010: 25-28.)
[12]LEEC-H,LINC-H,JUANGB-H.AstudyonspeakeradaptationoftheparametersofcontinuousdensityhiddenMarkovmodels[J].IEEETransactionsonSignalProcessing, 1991, 39(4): 806-814.
[13]LEGGETTERCJ,WOODLANDPC.MaximumlikelihoodlinearregressionforspeakeradaptationofcontinuousdensityhiddenMarkovmodels[J].ComputerSpeech&Language, 1995, 9(2): 171-185.
[14]GALESMJF,WOODLANDPC.MeanandvarianceadaptationwithintheMLLRframework[J].ComputerSpeech&Language, 1996, 10(4): 249-264.
[15]GALESMJF.MaximumlikelihoodlineartransformationsforHMM-basedspeechrecognition[J].ComputerSpeech&Language, 1998, 12(2): 75-98.
ThisworkispartiallysupportedbytheSocialResearchPlanofGuizhouProvince(20133015),theEngineeringTechnologyResearchCenterConstructionProjectofGuizhouProvince(20144002).
HUANG Wenna, born in 1990, M. S. candidate. Her research interest include speaker recognition.
PENG Yaxiong, born in 1963, associate professor. His research interests include signal processing.
HE Song, born in 1970, M. S., associate professor. His research interests include signal processing.
Vocal effort in speaker recognition based on MAP+CMLLR
HUANG Wenna, PENG Yaxiong*, HE Song
(CollegeofBigDataandInformationEngineering,GuizhouUniversity,GuiyangGuizhou550025,China)
To improve the performance of recognition system which is influenced by the change of vocal effort, in the premise of a small amount of whisper and shouted speech data in training speech data, Maximum A Posteriori (MAP) and Constraint Maximum Likelihood Linear Regression (CMLLR) were combined to update the speaker model and transform the speaker characteristics. MAP adaption method was used to update the speaker model of normal speech training, and the CMLLR feature space projection method was used to project and transform the features of whisper and shouted testing speech to improve the mismatch between training speech and testing speech. Experimental results show that the Equal Error Rate (EER) of speaker recognition system was significantly reduced by using the proposed method. Compared with the baseline system, MAP adaptation method, Maximum Likelihood Linear Regression (MLLR) model projection method and CMLLR feature space projection method, the average EER is reduced by 75.3%, 3.5%, 72%, 70.9%, respectively. The experimental results prove that the proposed method weakens the influence on discriminative power for vocal effort and makes the speaker recognition system more robust to vocal effort variability.
speaker recognition; vocal effort; Maximum A Posteriori (MAP); Maximum Likelihood Linear Regression (MLLR); Constraint Maximum Likelihood Linear Regression (CMLLR)
2016- 07- 22;
2016- 09- 17。
贵州省社会攻关计划项目(黔科合SY字[2013]3105 号);贵州省工程技术研究中心建设项目(黔科合G字[2014]4002号)。
黄文娜(1990—),女,贵州赤水人,硕士研究生,主要研究方向:说话人识别; 彭亚雄(1963—),男,贵州遵义人,副教授,主要研究方向:信号处理; 贺松(1970—),男,贵州贵阳人,副教授,硕士,主要研究方向:信号处理。
1001- 9081(2017)03- 0906- 05
10.11772/j.issn.1001- 9081.2017.03.906
TP391.4
A
