基于纠删码的细粒度云存储调度方案
2017-05-24薛广涛钱诗友李明禄
廖 辉,薛广涛,钱诗友,李明禄
(上海交通大学 计算机科学与工程系,上海 200240) (*通信作者电子邮箱gt_xue@sjtu.edu.cn)
基于纠删码的细粒度云存储调度方案
廖 辉,薛广涛*,钱诗友,李明禄
(上海交通大学 计算机科学与工程系,上海 200240) (*通信作者电子邮箱gt_xue@sjtu.edu.cn)
针对云存储系统中数据获取时延长以及数据下载不稳定的问题,提出了一种基于存储节点负载信息和纠删码技术的调度方案。首先,利用纠删码对文件进行编码存储以降低每份数据拷贝的大小,同时利用多个线程并发下载以提高数据获取的速度;其次,通过分析大量存储节点的负载信息确定影响时延的性能指标并对现有的云存储系统架构进行优化,设计了一种基于负载信息的云存储调度算法LOAD-ALGORITHM;最后,利用开源项目OpenStack搭建了一个云计算平台,根据真实的用户请求数据在云平台上进行部署和测试。实验结果表明,相比于现有的工作,调度算法在数据获取时延方面最高能减少15%的平均时延,在数据下载稳定性方面最高能降低40%的时延波动。该调度方案在真实的云平台环境下能有效地提高数据获取速度和稳定性,降低数据获取时延,达到更好的用户体验。
云存储系统;纠删码;调度算法;平均时延;稳定性
0 引言
随着云计算技术的发展,云存储服务也受到越来越多行业的关注和使用。云存储[1]是一个数据存储模型,数据被存储在一个逻辑存储池中,实际的物理存储则由多台物理服务器组成,通常情况下,这些物理环境由企业或公司进行管理。云存储系统拥有灵活、易维护、可扩展等特性,并提供数据存储的可靠性保证。用户可以在任何地点通过网络非常方便地访问云存储服务,完成数据存储和获取等操作。而且,相对于传统的存储服务,它具有成本低、便捷性好的优点。毫无疑问,云存储已经成为了当前最流行的在线数据存储方案。目前,国外最流行的云存储服务包括Dropbox、Google Driver、Microsoft One Driver、Apple iCloud,国内的有百度云盘、腾讯微云、华为云盘、360网盘等。
同样,大数据这个概念近年来也在越来越多的场合被越来越多的人提及,并且经常是和云计算联系在一起。大数据无疑将给人类社会带来巨大的价值,科研机构可以通过大数据业务协助进行研究探索,如环境、资源、能源、气象、航天、生命等领域的探索,那么云计算和大数据之间到底是什么关系呢?概括而言,没有互联网就没有云计算模式,没有云计算模式就没有大数据处理技术。然而,云计算同样对大数据处理技术提出了新的挑战,这主要反映在传统的关系数据库不能满足大数据处理的要求,比如海量用户的高并发读写、海量数据的高效存储和访问、系统的高可用性和高扩展性等。为此,业界一些厂商先后研发了一批包含分布式数据缓存、分布式文件系统、非关系型数据库和新关系型数据库等新技术来解决上述问题。同样,由于海量数据的大数据量和分布性的特点,使得传统的数据处理技术不适合于处理海量数据。这对海量数据的分布式并行处理技术提出了新的挑战,开始出现以MapReduce为代表的一系列新处理技术,像数据并行处理技术、增量处理技术、流式计算技术等。云计算时代会有更多的数据存储于计算中心。数据是资产,云是数据资产保管的场所和访问的渠道。大数据的处理和分析必须依靠云计算提供计算环境和能力,挖掘出适合于特定场景和主题的有效数据集。比如,《纽约时报》用云计算转换了1851年到1922年超过40万张扫描的图片,通过把任务分配给几百台电脑,这项工作在36 h内就完成了;信用卡公司Visa计算两年的纪录,包括730亿笔交易、高达36 TB的数据,处理时间用传统方法需要1个月,而采用基于Hadoop的处理技术只要13 min[2]。所以说,大数据和云计算其实是相辅相成的,而大数据也将在云计算技术等的支撑下被发掘出更多的价值。
在云存储系统中,通常使用两种方式来提高数据容错和防灾备份能力,以及保证数据的可用性。一是通过简单的冗余备份技术[3-4],对原始数据进行多份拷贝并分别保存在多个不同的存储节点中。二是通过纠删码(Erasure Code, EC)技术[5-7],将原始数据经过一定编码分成若干较小的数据块并保存在多个不同的存储节点中。对于一个(n,k)纠删码(n>k),原始数据先被等分成k个大小相同的数据块,再将k个数据块经过一定编码生成n个数据块,并保存在n个不同的存储节点中,每次只需从n个数据块中任意获取k个数据块并进行解码即可恢复原始数据。对于任意(ni,ki)纠删码(i=1,2,…),只需满足最大距离可分码(MaximumDistanceSeparablecode,MDS)[8],即可使用纠删码对文件进行编码存储。目前,存储云基本都使用多种不同纠删码对文件进行编码存储,从而来保证数据的可靠性。如,Facebook数据仓库集群[9]对频繁访问的数据简单地使用3份拷贝进行存储,而对一些较少访问的数据利用(14,10)纠删码进行保存。一些主流的开源云存储平台也开始支持纠删码技术并利用多种不同的纠删码进行数据存储,如OpenStack的Swift服务[10]和HDFS-RAID[11]。
相比于简单的对原始数据进行冗余备份,利用纠删码对数据进行编码存储能够更高效地利用存储空间,并能降低数据获取时延。对云存储系统而言,一个重要设计准则就是实现数据的快速获取。据Amazon、Microsoft和Google等企业的相关报道,即使轻微的时延增加也会导致企业出现实质性的收益降低。由于纠删码技术能比较有效地降低时延,所以目前被广泛地运用在企业或一些开源的云平台中。对于使用(n,k)纠删码进行存储的文件,通常利用L个线程并行下载k个已编码的数据块(k≤L≤n),只要任意k个数据块下载结束,通过对该k个数据块进行解码即可恢复原始数据。相对于下载整个原始数据,由于每个数据块小于原始数据,因此大幅度降低了数据获取时延。然而,线程调度策略会对数据获取时延产生影响,因此,目前最关键的问题是如何优化线程调度以降低数据获取时延?
本文基于存储节点的负载信息提出了一种新的调度策略和调度算法。通过对大量存储节点的负载信息进行分析,包括内存利用率、磁盘利用率、CPU利用率、硬盘读写次数和收发的数据包等,找出可能影响时延的性能指标,根据这些指标设计更细粒度的调度策略,并实现对应的调度算法。本文利用多种不同的纠删码对大量文件进行编码存储,在用户请求到达满足不同分布的情况下进行测试,包括真实的用户请求数据[12]和用户请求到达满足韦伯分布[13]两种情况。最后,利用开源项目OpenStack[14]搭建了一个真实的云计算平台进行测试,通过大量的实验结果证明,本文设计的调度策略和算法不仅能够有效地降低数据获取时延,还能保证不同用户的数据下载时延趋于一致。本文创新点在于根据存储节点的负载信息实现反向指导代理节点进行线程调度,利用最小生成树中的普里姆算法[15]思想解决调度过程中出现的问题,并基于真实云计算平台和用户数据进行实验。本文的主要工作包括:
1)对大量存储节点的负载信息进行分析,确定影响数据获取时延的性能指标。
2)优化云存储系统现有调度策略,根据存储节点的负载信息反向指导代理节点进行线程调度,并基于负载信息设计一种新的调度算法。
3)利用OpenStack搭建真实的云计算平台,并通过多种不同的纠删码对大量文件进行编码存储,基于真实的云存储平台和用户请求到达数据验证调度算法的有效性和性能。
1 系统架构
一般而言,云存储系统包含一个代理节点和多个存储节点。用户通过API或用户接口与代理节点进行交互,用户请求可能包含get、put、delete等操作,在本文中只关注get操作,即文件获取操作。代理节点将每个用户请求转化成k(k≥1)个数据块下载任务,每个任务利用一个线程与存储节点建立TCP连接进行数据下载。当k个任务都完成后,代理节点进行解码并恢复用户所请求的文件,最后将成功获取的文件返回用户。代理节点一般拥有固定大小的线程池用于维持与存储节点的TCP连接,每个任务需要消耗一个线程,当线程池中无空闲线程时,剩余任务需要等待直到有任务完成并出现新的空闲线程,代理节点对等待队列中的任务进行调度后,新的任务才开始工作。
在本文中,云存储系统同样采用了以上所描述的体系架构,同时,在此基础上新增了一个性能监测节点用于保存每个存储节点的性能负载信息,为代理节点提供调度依据,如图1所示。
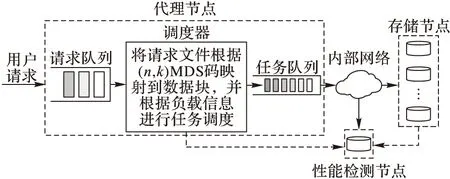
图1 云存储系统架构
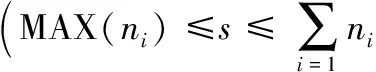
2 存储节点负载信息分析
本文中从存储节点的负载信息出发,分析并确定存储节点中可能会对调度产生影响的性能指标。在之前的系统架构中提到,这些负载信息被保存到性能监测节点,文中保存了一些具有代表性的性能指标,具体字段如表1所示。本文最初的设计将负载信息保存在代理节点,为了实时跟踪各个存储节点的负载变化,本文将数据采集的时间间隔设置在5s以内,但考虑到较高的负载信息采集频率对代理节点调度产生影响,这里单独设置一个性能监测节点来保存云存储系统中各个存储节点的负载信息。由于云存储内部网络属于高速网络,而且代理节点和存储节点处于同一局域网,所以本文有理由相信,当进行线程调度时,代理节点从性能监测节点获取负载信息的通信开销远低于将负载信息保存在代理节点中频繁通信带来的开销,从而减少其他因素对代理节点调度产生的干扰,降低对文件获取时延产生的影响。

表1 负载信息采集表
通过对多个存储节点的大量负载信息进行分析,本文发现有些性能指标对文件获取时延可能存在一定影响。从图2(a)可以看出,无论时延曲线如何波动,CPU利用率、内存利用率、磁盘利用率等曲线基本保持平稳状态,对于throughput_recv、disk_percent、disk_write等指标也得出相似的结果,曲线之间基本没有关联性,所以本文初步确定文件获取的平均时延基本不受这几个指标的影响。为了进一步验证该设想,本文在存储节点中单独部署了两个应用,分别用于提高存储节点的CPU利用率和内存利用率,发现随着内存利用率或CPU利用率的提高,文件平均下载时延并不随之变化,而是保持平稳状态,所以本文有理由认为以上几个性能指标基本不会对文件获取时延产生影响。
从图2(b)可以发现,throughput_send曲线与时延曲线可能存在一定程度上的关联性,初步确定文件获取时延可能受到每个存储节点吞吐量的影响。因为,数据传输时延=发送时延+传播时延+等待时延,当吞吐量增高时,一方面意味着更多数据需要传输,从而造成数据在等待队列中的排队时间更长,导致等待时延的增加;另一方面高吞吐量会造成丢包率的升高,从而导致更多的数据包需要进行超时重传。所以本文认为存储节点的吞吐量是影响文件获取时延的一个重要因素,在之后的章节中也会通过大量的实验结果来验证。
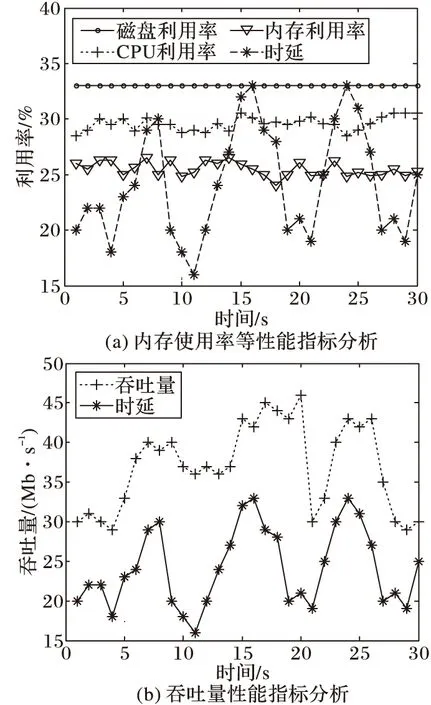
图2 存储节点性能指标分析
由于文件下载需要从存储节点的磁盘读取数据块并发送给代理节点,假设每次磁盘读操作读取的数据大小相同,为d字节,那么在理想情况下,只要发送速度足够快,throughput_send=disk_read*d,可以看出每秒发送的字节数和每秒读取次数存在线性关系,所以本文使用吞吐量作为调度依据而不使用每秒磁盘读操作。
当存储节点吞吐量升高,说明代理节点中有更多的线程用于与该存储节点建立连接并进行数据传输,当多个文件下载请求同时到达时,代理节点可能将过多任务的调度到某个存储节点,从而导致该节点负载过高。文中之前提到过高负载可能造成高时延,以及不同用户获取数据时延的不稳定,为了避免这种情况产生的负面影响,在本文之后的内容中,通过优化现有调度策略,即基于存储节点吞吐量的负载情况进行调度,设计了一种新的调度算法
3 云存储调度算法
根据以上分析,本文使用单位时间内发送的数据(为了书写方便,本文之后都使用表1中throughput_send表示)作为调度依据,并以此设计调度算法。算法优化的目标是尽量使各存储节点的throughput_send负载程度相同,从而避免单个存储节点负载过高影响文件获取速度。本文针对两种用户请求的情况进行分析,第一种是每次单个请求到达的情况,第二种是每次有多个请求到达的情况。
问题1描述 有1个用户请求到达,获取文件j(j=1, 2,…),这里用filej表示,该文件采用(nj,kj) 纠删码。假设经过编码后的数据块映射到nj个存储节点中,storage[1, 2, …,nj]表示每个存储节点的信息,chunk[j]表示filej对应的数据块信息。需要解决的问题是:如何从nj个存储节点中选出kj个进行数据块下载,使storage[1, 2, …,nj]每个存储节点的负载程度基本相同?
思路 当每次有用户请求到达时,选择负载最小的一些存储节点进行下载。假设用户请求文件filej,该文件使用(nj,kj) 纠删码,且已编码的数据块保存在nj个存储节点,那么只需利用简单的贪心算法,将各存储节点按throughput_send从小到大进行排序,并从对应的nj存储节点选择较小的前kj个节点,建立TCP连接进行数据块下载任务,具体如算法1所示。
算法1 单用户请求调度算法。
输入:用户文件请求filej。
输出:数据块下载任务队列chunk_task[1-kj]。
1)
storage[1 tonj].throughput_send← 从负性能监测节点中获取当前每个存储节点的吞吐量并初始化storage数组
2)
storage[1 tonj].ip← 当前存储节点的ip
3)
根据filej使用的(nj,kj)纠删码,将文件请求映射到数据块的下载,并初始化chunk数组
4)
chunk[j].n←nj,文件j包含的数据块个数
5)
chunk[j].k←kj,恢复文件j需要的数据块个数
6)
fori← 1 tonj
7)
chunk[j].ips[i] ← 保存所有数据块的存储节点,利用storage[i]进行初始化
8)
endfor
9)
对chunk[j].ip[1 tonj])按throughput_send信息从小到大进行排列
10)
fori← 1 toki
11)
chunk_task.push(chunk[j].ips[i])
12)
endfor
对于算法1,1)~2)行初始化数组storage,保存每个存储节点当前吞吐量以及IP地址。3)行根据请求文件使用的(nj,kj)纠删码,将文件请求任务映射到对应的已编码数据块下载任务。4)~8)行,保存数据块信息,包括nj、kj以及数据块所在存储节点的信息。9)行根据throughput_send对storage从小到大进行排序。10)~12)行选取throughput_send最小的前kj个存储节点进行任务调度,并返回这些存储节点信息。因为每次都选择吞吐量最低的几个节点进行调度,所以负载较为平均地分摊到各个存储节点,不会造成某些节点负载过高。可以得出结论,当每次只有一个请求时,使用贪心策略,该算法接近最优。
实际上,在云存储系统中,每秒往往有多个用户请求到达。当同时有多个请求到达时,由于算法1总是选择负载最低的几个存储节点进行调度,可能导致与代理节点建立的数据连接都集中在一部分存储节点,从而造成这些节点吞吐量负载增高,影响文件获取速度。考虑同时有多个请求到达的情况,如果对请求一个一个进行调度,前一个请求的调度结果会改变某些存储节点的吞吐量,从而对下一个请求的调度产生影响,所以在这种情况下算法1不能达到最优,它未考虑到请求之间的关联性。现在的问题是,当有多个请求同时到达时,如何进行调度才能使每个存储节点的负载基本相同?
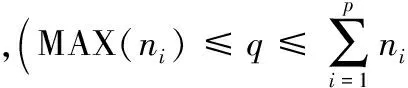
思路 传输一个数据块chunk[i],需要发送chunk[i].size字节的数据,即造成throughput_send提高chunk[i].size。本文假设需要下载所有文件的所有数据块n1,n2,…,np,则需要发送chunk[1].size+chunk[2].size+,…,+chunk[p].size字节的数据。本文将下载这些数据块导致负载提高的信息更新到现有的存储节点storage[1,2,…,p]中。文中使用类似于最小生成树中的普里姆算法思想,对所有存储节点按throughput_send信息进行排序,然后每次从throughput_send最高的存储节点中删除一个数据块,由于小数据块对于吞吐量影响不大,在这里每次删除最大的数据块并更新当前节点的throughput_send,重复操作,直到所有文件的数据块数目分别等于k1,k2,…,kp,具体如算法2所示。
算法2 多用户请求调度算法:LOAD-ALGORITHM。
输入:用户文件请求队列file_list[1,2,…,p]。
1)
storage[1 toq].disk_read← 利用性能监测节点中记录的负载信息,初始化storage数组
2)
storage[1 toq].ip← 当前存储节点的ip
3)
fori← 1 top:
4)
根据file_list[i]使用的(ni,ki)纠删码,将文件请求映射到数据块下载任务,初始化chunk数组
5)
chunk[i].size← 文件块的大小
6)
chunk[i].k←ki,恢复文件i需要的数据块个数
7)
chunk[i].n←ni,文件i包含的所有数据块个数
8)
chunk[i].ips[1 toni] ← 保存文件i对应的所有数据块的所在存储节点信息,这里用storage[i]进行初始化
9)
endfor
10)
fori← 1 toni
11)
更新storage[1-q]信息。假设需要下载文件的所有数据块,利用chunk[i]信息更新所在存储节点的throughput_send
12)
endfor
13)
while !(chunk[i].k==chunk[i].n)(i=1,2,…,p)
14)
对storage[1,2,…,q]按throughput_send从大到小排序
15)
从throughput_send最大的存储节点,即storage[1],找出最大的数据块chunk[j],并从存储节点中删除该数据块并更新storage[1],storage[1].throughput_send←storage[1].throughput_send-chunk[j].size
16)
将该存储节点从chunk[i].ips中删除
17)
chunk[i].n←chunk[i].n-1
18)
end while
19)
fori← 1 top
20)
chunk_task.push(chunk.ips[1-ki])
21)
endfor
算法2中1)~2)行利用性能监测节点中保存的存储节点负载信息初始化storage数组。3)~9)行将文件i请求根据使用的(ni,ki)纠删码映射到对数据块的下载任务,利用ni、ki以及数据块所在的存储节点信息初始化chunk数组。10)~12)行,假设需要下载所有数据块(n1+n2+…+np),则将下载这些数据块影响的吞吐量负载信息更新到storage数组。13)~18)行,每次从storage数组中选出throughput_send最大的节点并从中删除最大的数据块,直到所有文件剩余的数据块数目分别等于k1,k2,…,kp。19)~21)利用剩余的数据块以及对应的存储节点信息初始化任务队列chunk_task,进行数据块下载任务。该算法借鉴了普里姆算法的思路,使负载信息较为平均地分摊到各个存储节点,可以看出,当同时有多个请求到达时,该算法接近最优。
4 实验结果与分析
实验基于真实的云计算平台和用户请求数据,进行大量的测试来验证文中所提出的调度算法,从实践的角度证明算法的可行性和有效性,并将实验结果与相关文献的工作进行对比。
4.1 实验环境
首先,本文利用开源项目OpenStack搭建了一个多节点的云计算平台,每个节点配置一个千兆网卡,代理节点和所有存储节点都处于同一个局域网。为了进行测试,在云平台中申请了12台虚拟机用于模拟文件的下载,10台用于普通的存储节点,1台用于性能监测节点,1台用于代理节点。在存储节点中本文保存了大量的文件数据,每个文件都通过纠删码进行编码。
其次,根据文献[16]的相关研究,在一个云存储系统中,大部分文件都相对比较小,而这些小文件通常只占用很小一部分存储空间。根据统计结果,大概90%的文件小于4MB,99%的文件小于16MB,而小于4MB的文件大概占用10%的存储空间,小于16MB的文件大概占用20%的存储空间。本文按照文献[16]中给出的结论对存储节点进行部署,在系统中保存大量的数据文件。
本文采取了多种不同的纠删码进行对文件进行编码。这里利用四种不同纠删码对文件进行编码,分别为:1)(2,1)纠删码;2)(4,2)纠删码;3)(6,3)纠删码;4)(10,4)纠删码。
对于性能监测节点,它会定时采集各个存储节点的负载信息。本文将监测节点与存储节点的之间的交互频率定义为一秒一次,因为负载信息的数据量非常小,可以认为,这些数据的传输基本不会对存储节点的性能产生影响,也就是说对实验结果不会产生干扰。
代理节点用于部署调度算法,同时拥有L=20大小的线程池。在用户请求分别符合两种到达的情况下,测试调度算法的性能。第一种情况是用户请求到达满足韦伯分布[13],第二种情况用户请求基于真实的用户请求到达数据[12]。
最后,在相同的实验情况下,将本文的算法LOAD-ALGORITHM与SERPT-R算法[17]和FCFS-R算法[18](算法细节如第5章所述)进行对比,得出相关的结论。
4.2 算法性能
图3为用户请求到达满足韦伯分布得出的结果。横坐标表示用户请求的总次数,本文测试了10,20,50,100,200,500几组数据,纵坐标表示完成所有请求所需的时延。文中使用4种不同的纠删码对文件进行编码,如图3所示。从图3可以看出,相比之前的工作,在请求量比较少的情况,存储节点负载相对比较低,所以平均时延大致相同。而当请求比较多时,可能会出现单个节点负载较高从而影响文件获取的情况,本文设计的算法可以很好地避免这一点;即使文件使用不同编码,在一定程度上都能降低文件获取的总时延。从图3可以看出,本文提出的LOAD-ALGORITHM算法比SERPT-R算法降低10%~15%数据获取的平均时延,相比FCFS-R算法降低20%~30%的平均时延。
图4为用户请求到达满足真实用户请求数据下得出的结果。横坐标表示用户请求的总次数,纵坐标表示所有请求完成所需的时延。同样,这里使用了与图3相同的几组数据进行测试以及相同的四种纠删码对文件进行编码。可以看出,本文提出的LOAD-ALGORITHM算法比SERPT-R算法完成所有请求所需的时间更短,降低10%~15%数据获取的平均时延,相比FCFS-R算法降低20%~30%的平均时延。
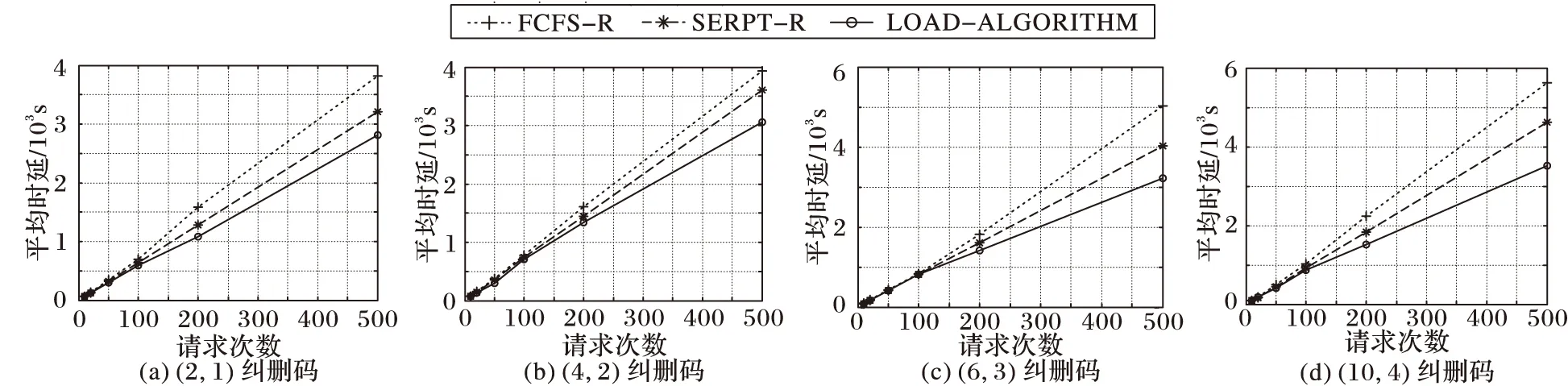
图3 用户请求到达服从韦伯分布时平均时延
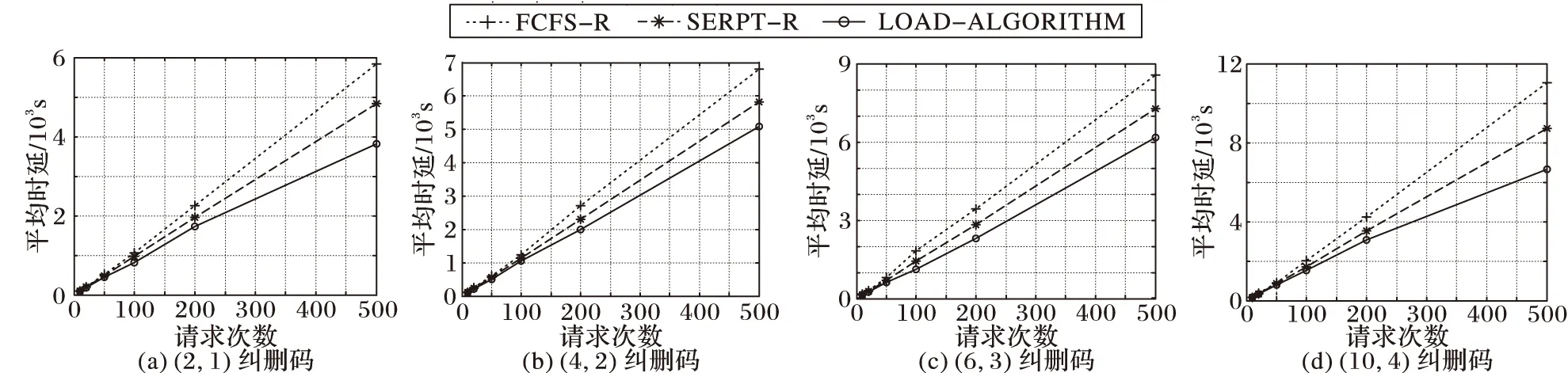
图4 用户请求到达服从真实的用户请求时平均时延
在云存储系统中,数据获取时延的稳定性也是决定用户体验的重要因素。为了进一步验证算法的性能,本文分析了算法对时延波动的影响。文中利用方差来体现数据获取时延的离散程度,D(X) =E{[X-E(X)]2}。根据概率论相关知识,方差越大,表示数据离散程度越高,稳定性越差。稳定性验证的实验中同样使用了纠删码 (4, 2)、(6, 3)、(10,4)对文件进行存储,并在用户请求服从韦伯分布和真实用户请求数据情况下,与SEPRT-R算法进行比较。实验结果如图5所示,横坐标表示不同的纠删码,纵坐标表示时延方差。从图5中可以明显看出,本文提出的算法在两种用户请求到达情况下对数据获取时延的方差都有着比较明显的改善,相比于SEPRT-R算法,降低30%~40%的时延方差。也就是说,在长时间内,数据获取时延更加稳定,不会出现剧烈波动即时延过高或过低的情况,从而影响用户体验。根据实验结果可得出结论,本文提出的调度算法对数据获取时延的稳定性也有着明显的改善。
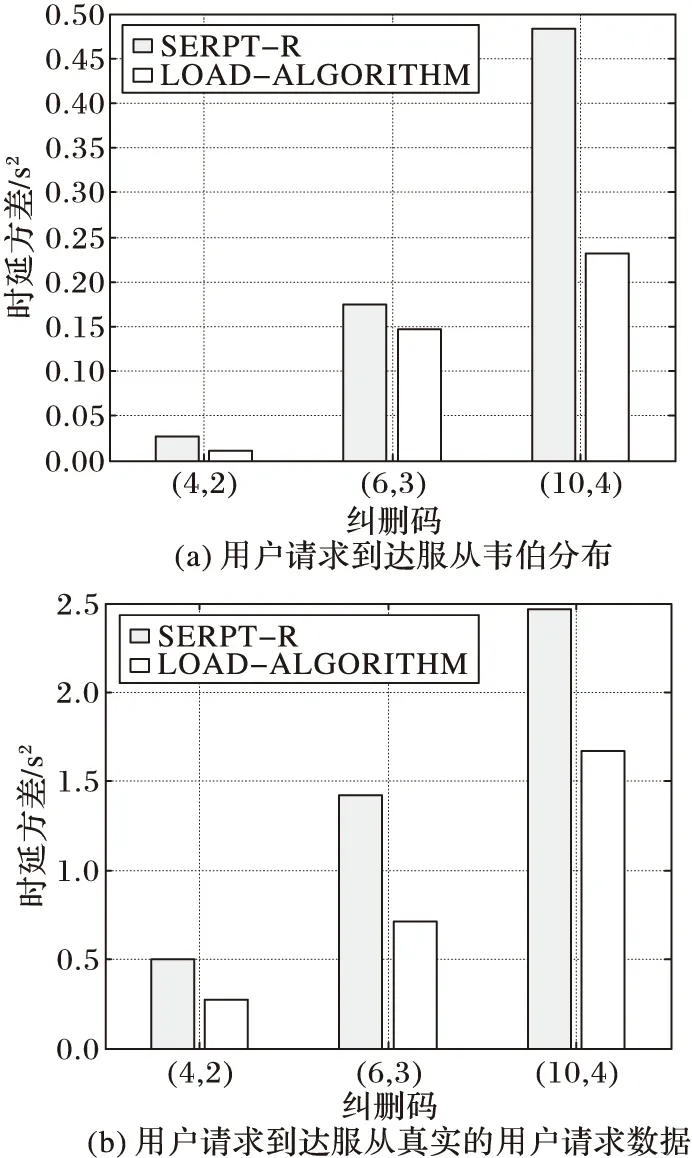
图5 调度算法对稳定性的影响
5 国内外相关研究
目前,国内外已经有很多关于云存储方向的相关研究。文献[3,19]主要介绍分布式存储系统中的存储方案,对原始文件数据进行简单的冗余备份,将一份文件的多个拷贝保存在不同的存储节点中。文献[5]介绍了云存储系统中的存储方案,使用纠删码技术对原始文件进行编码,将文件编码成等长的几个数据块进行存储,由于编码后的数据块小于原始文件,所以相对于对原始文件进行冗余备份,纠删码技术在文件获取过程中能够比较好地降低时延。文献[9-10,20]介绍了当前一些主流的企业和云存储平台,包括如Facebook、Microsoft、OpenStack中的Swift存储服务,它们都使用了基于纠删码进行文件存储的方案。文献[17]介绍了代理节点中的调度问题,对于使用(n,k)纠删码,只使用k个线程对文件对应的k个数据块进行下载,而不使用n个冗余线程下载所有数据块,同时利用剩余的线程进行其他文件下载任务,每个文件占用与其编码k相同大小的线程数,直至所有的可用线程都使用完,文章从理论上证明调度方案的优越性。文献[18]介绍了云存储系统中代理节的任务调度问题,利用先到先服务(FirstComeFirstServed,FCFS)策略,对于每个到达的请求,利用冗余线程来进行文件下载任务。文献[21]介绍了代理节点中新的排队模型,并论证了系统只包含单个存储节点和下载时间满足指数分布的前提下,利用冗余线程进行任务下载能够很好地降低时延。文献[22]提出了一种动态调整纠删码的方案,通过监控等待队列和线程使用情况来判断当前系统负载,在低负载情况下编码成较小数据块对进行文件保存,高负载情况下编码成较大数据块对进行文件保存。文献[23]对比和分析了现有的纠删码技术,给出了不同纠删码在容错能力与磁盘要求、空间利用率、编码效率、更新效率、重构效率等方面的不足和可能的改进见解。文献[24]针对云存储系统的扩展性和数据容错问题,给出了一种可容3列随机删除错数据的布局方法;利用校验数据位与信息数据位之间的对应关系找到一种具有低计算复杂度的数据重构算法。文献[25]针对Hadoop分布式文件系统(HadoopDistributedFileSystem,HDFS)的多副本存储技术提出了改进,引入编码和编译模块,对系统中的block进行编码分解,生成更多数量的数据分片,并随机分散保存到集群当中,替代原有系统的多副本容灾策略,在容灾效率、负载均衡、存储成本以及安全性上对HDFS作了相应的优化。文献[26]针对单服务器的纠删码算法在用户量大的访问情况下容易导致效率低下的问题,提出了一种基于分散式服务器的算法,并通过对原数据进行分割编码来实现数据块的冗余存储。文献[27]研究了纠删码技术在云文件系统中的应用,并从编码类型、编码对象、编码时机、数据更改、数据访问方式和数据访问性能等6个方面对云文件系统中纠删码的设计进行了探究,证明了纠删码能有效地保障云文件系统的数据可用性,并且节省存储空间。基于以上的研究,本文利用纠删码进行文件保存,并根据存储节点的负载信息,从更细粒度层面进行任务调度,优化现有的调度方案。
6 结语
在云存储系统中,本文基于纠删码技术,根据存储节点的负载信息反向指导代理节点,从更细粒度层面进行数据下载任务的调度。本文通过分析大量存储节点的负载信息,找出影响文件获取速度的性能指标,并基于该指标设计了新的调度算法。为了验证算法的性能,利用开源项目OpenStack搭建了一个真实的云计算实验平台,通过多种纠删码方案对大量文件进行编码存储,在真实的云存储环境下模拟不同用户请求到达的情况,进行大量的实验。实验结果表明,在云存储系统中,本文提出的调度算法不仅能够有效地降低数据获取时延,还能保证不同用户的数据下载时延趋于一致,提高数据获取的稳定性,从而提供更好的用户体验,在一定程度上优化现有的调度策略。
)
[1]Wikipedia.Cloudstorage[EB/OL]. [2016- 06- 10].https://en.wikipedia.org/wiki/Cloudstorage.
[2] 华为.大数据和云计算[EB/OL]. [2016- 07- 19].http://e.huawei.com/zh/publications/cn/ict_insights/hw_366755/horizons/HW_366714. (Huawei.Bigdataandcloudcomputing[EB/OL]. [2016- 07- 19].http://e.huawei.com/zh/publications/cn/ict_insights/hw_366755/horizons/HW_366714.)
[3]GHEMAWATS,GOBIOFFH,LEUNGST.Thegooglefilesystem[C]//Proceedingsofthe19thACMSymposiumonOperatingSystemsPrinciples.NewYork:ACM, 2003: 29-43.
[4]SHVACHKOK,KUANGH,RADIAS,etal.TheHadoopdistributedfilesystem[C]//Proceedingsofthe2010IEEE26thSymposiumonMassStorageSystemsandTechnologies.Washington,DC:IEEEComputerSociety, 2010: 1-10.
[5]HUANGL,PAWARS,ZHANGH,etal.Codescanreducequeueingdelayindatacenters[C]//Proceedingsofthe2012IEEEInternationalSymposiumonInformationTheory.Piscataway,NJ:IEEE, 2012: 2766-2770.
[6]LIANGG,KOZATUC.Fastcloud:pushingtheenvelopeondelayperformanceofcloudstoragewithcoding[J].IEEE/ACMTransactionsonNetworking, 2014, 22(6): 2012-2025.
[7]SHAHNB,LEEK,RAMCHANDRANK.TheMDSqueue:analysinglatencyperformanceofcodesandredundantrequests[EB/OL]. [2016- 01- 07].http://people.eecs.berkeley.edu/~nihar/publications/The_MDS_Queue.pdf.
[8]ROSENTHALJ,SMARANDACHER.Maximumdistanceseparableconvolutionalcodes[J].ApplicableAlgebrainEngineering,CommunicationandComputing, 1999, 10(1): 15-32.
[9]RASHMIK,SHAHNB,GUD,etal.Asolutiontothenetworkchallengesofdatarecoveryinerasure-codeddistributedstoragesystems:astudyonthefacebookwarehousecluster[C]//Proceedingsofthe5thUSENIXConferenceonHotTopicsinStorageandFileSystems.Berkeley,CA:USENIXAssociation, 2013: 8.
[10]Openstack.Swiftservice[EB/OL]. [2016- 06- 10].https://wiki.openstack.org/wiki/Swift/.
[11]HadoopWiki.HDFS-RAID[EB/OL]. [2016- 06- 10].http://wiki.apache.org/hadoop/HDFS-RAID.
[12]ZHANGB,IOSUPA,POUWELSEJ,etal.Thepeer-to-peertracearchive:designandcomparativetraceanalysis[C]//ProceedingsoftheACMCoNEXTStudentWorkshop.NewYork:ACM, 2010:ArticleNo. 21.
[13]YEUNGKH,SZETOCW.OnthemodelingofWWWrequestarrivals[C]//Proceedingsofthe1999InternationalWorkshopsonParallelProcessing.Piscataway,NJ:IEEE, 1999: 248-253.
[14]Wikipedia.Openstack[EB/OL]. [2016- 06- 10].https://en.wikipedia.org/wiki/OpenStack.
[15]Wikipedia.Prim’salgorithm[EB/OL]. [2016- 06- 10].https://en.wikipedia.org/wiki/Prim%27salgorithm.
[16]LIUS,HUANGX,FUH,etal.Understandingdatacharacteristicsandaccesspatternsinacloudstoragesystem[C]//Proceedingsofthe2013 13thIEEE/ACMInternationalSymposiumonCluster,CloudandGridComputing.Piscataway,NJ:IEEE, 2013: 327-334.
[17]SUNY,ZHENGZ,KOKSALCE,etal.Provablydelayefficientdataretrievinginstorageclouds[C]//Proceedingsofthe2015IEEEConferenceonComputerCommunications.Piscataway,NJ:IEEE, 2015: 585-593.
[18]JOSHIG,LIUY,SOLJANINE.Onthedelay-storagetrade-offincontentdownloadfromcodeddistributedstoragesystems[J].IEEEJournalonSelectedAreasinCommunications, 2013, 32(5): 989-997.
[19]CHANGF,DEANJ,GHEMAWATS,etal.Bigtable:adistributedstoragesystemforstructureddata[J].ACMTransactionsonComputerSystems, 2008, 26(2): 205-218.
[20]HUANGC,SIMITCIH,XUY,etal.Erasurecodinginwindowsazurestorage[C]//Proceedingsofthe2012USENIXConferenceonAnnualTechnicalConference.Berkeley,CA:USENIXAssociation, 2012: 2.
[21]CHENS,SUNY,KOZATUC,etal.Whenqueueingmeetscoding:optimal-latencydataretrievingschemeinstorageclouds[C]//Proceedingsofthe2014ProceedingsIEEEINFOCOM.Piscataway,NJ:IEEE, 2014: 1042-1050.
[22]LIANGG,KOZATUC.TOFEC:achievingoptimalthroughput-delaytrade-offofcloudstorageusingerasurecodes[C]//Proceedingsofthe2014ProceedingsIEEEINFOCOM.Piscataway,NJ:IEEE, 2014: 826-834.
[23] 罗象宏,舒继武.存储系统中的纠删码研究综述[J].计算机研究与发展,2012,49(1):1-11.(LUOXH,SHUJW.Summaryofresearchforerasurecodeinstoragesystem[J].JournalofComputerResearchandDevelopment, 2012, 49(1): 1-11.)
[24] 蒋海波,王晓京,范明钰,等.基于水平纠删码的云存储数据布局方法[J].四川大学学报(工程科学版),2013,45(2):103-109.(JIANGHB,WANGXJ,FANMY,etal.Adataplacementbasedonlevelarraycodesincloudstorage[J].JournalofSichuanUniversity(EngineeringScienceEdition), 2013, 45(2): 103-109.)
[25] 李晓恺,代翔,李文杰,等.基于纠删码和动态副本策略的HDFS改进系统[J].计算机应用,2012,32(8):2150-2158.(LIXK,DAIX,LIWJ,etal.ImprovedHDFSschemebasedonerasurecodeanddynamical-replicationsystem[J].JournalofComputerApplications, 2012, 32(8): 2150-2158.)
[26] 葛君伟,李志强,方义秋.云存储环境下基于分散式服务器的ErasureCode算法[J].计算机应用,2011,31(11):2940-2942.(GEJW,LIZQ,FANGYQ.Erasurecodealgorithmbasedondistributedserverincloudstorageenvironment[J].JournalofComputerApplications, 2011, 31(11): 2940-2942.)
[27] 程振东,栾钟治,孟由,等.云文件系统中纠删码技术的研究与实现[J].计算机科学与探索,2013,7(4):315-325.(CHENGZD,LUANZZ,MENGY,etal.Researchandimplementationonerasurecodeincloudfilesystem[J].JournalofFrontiersofComputerScienceandTechnology, 2013, 7(4): 315-325.)
ThisworkispartiallysupportedbytheNationalHighTechnologyResearchandDevelopmentProgram(863Program)ofChina(2015AA01A202).
LIAO Hui, born in 1991, M. S. candidate. His research interests include cloud computing and big data.
XUE Guangtao, born in 1976, Ph. D., professor. His research interests include mobile and wireless computing, social network, distributed computing, wireless sensor network, cloud computing and big data.
QIAN Shiyou, born in 1977, Ph. D., assistant professor. His research interests include cloud computing and big data.
LI Minglu, born in 1965, Ph. D., professor. His research interests include vehicular Ad Hoc network, wireless sensor network, cloud computing and big data analysis.
Fine-grained scheduling policy based on erasure code
LIAO Hui, XUE Guangtao*, QIAN Shiyou, LI Minglu
(DepartmentofComputerScienceandEngineering,ShanghaiJiaoTongUniversity,Shanghai200240,China)
Aiming at the problems of long data acquisition delay and unstable data download in cloud storage system, a scheduling scheme based on storage node load information and erasure code technique was proposed. Firstly, erasure code was utilized to improve the delay performance of data retrieving in cloud storage, and parallel threads were used to download multiple data copies simultaneously. Secondly, a lot of load information about storage nodes was analyzed to figure out which performance indicators would affect delay performance, and a new scheduling algorithm was proposed based on load information. Finally, the open-source project OpenStack was used to build a real cloud computing platform to test algorithm performance based on real user request tracing and erasure coding. A large number of experiments show that the proposed scheme not only can achieve 15% lower average delay but also reduce 40% volatility of delay compared with other scheduling policies. It proves that the scheduling policy can effectively improve delay performance and stability of data retrieving in real cloud computing platform, achieving a better user experience.
cloud storage system; erasure code; scheduling algorithm; average delay; stability
2016- 09- 21;
2016- 10- 18。
国家863计划项目(2015AA01A2020)。
廖辉(1991—),男,江西南丰人,硕士研究生,主要研究方向:云计算、大数据; 薛广涛(1976—),男,山东济南人,教授,博士,CCF会员,主要研究方向:移动和无线计算、社交网络、分布式计算、无线传感网、云计算、大数据; 钱诗友(1977—),男,江苏连云港人,助理研究员,博士,主要研究方向:云计算、大数据; 李明禄(1965—),男,重庆人,教授,博士,CCF会员,主要研究方向:车辆自组网、无线传感器网络、云计算、大数据分析。
1001- 9081(2017)03- 0613- 07
10.11772/j.issn.1001- 9081.2017.03.613
TP391.9
A
