基于实时数据和历史查询分布的时空索引新方法
2017-05-24孟学潮叶少珍
孟学潮 ,叶少珍,2
(1.福州大学 数学与计算机科学学院, 福州 350108; 2.福建省医疗器械与医药技术重点实验室,福州 350002) (*通信作者电子邮箱yeshzh@fzu.edu.cn)
基于实时数据和历史查询分布的时空索引新方法
孟学潮1,叶少珍1,2*
(1.福州大学 数学与计算机科学学院, 福州 350108; 2.福建省医疗器械与医药技术重点实验室,福州 350002) (*通信作者电子邮箱yeshzh@fzu.edu.cn)
在大数据时代,数据具有体量大、时空复杂性明显、对实时性要求较高等特点,而传统基于树形结构对大规模时空数据进行索引的方法存在存储空间浪费和查询效率较低的问题。为了解决该问题,提出了一种基于数据和历史查询记录分布建立时空索引的新方法HDL-index。该算法一方面根据数据在空间上的分布,通过空间划分的思想建立索引网格;另一方面考虑到查询在时间上的延续性,对查询记录对象进行密度聚类后抽象出查询代表模型,然后根据模型的坐标位置和其查询粒度对整体查询区域进行分割。两部分所得到的索引网格都采用Geohash编码,最终合并得到最优的索引编码。HDL-index在考虑数据分布的同时充分考虑用户查询行为,使得频繁查询区域上的索引更加细化。在真实航空数据集上与同类方法进行比较测试的结果表明,其创建索引的效率提高了50%;同时在数据均匀分布的情况下对热点区域的查询效率可提高75%以上。
时空索引;大数据;GeoHash编码;密度聚类;热点区域查询
0 引言
近来随着时空数据的价值在各个领域逐渐凸显,尤其在商业航空领域行业,客机使用全球定位系统(Global Positioning System, GPS)进行高频率的信息采集产生大量的数据;同时时空数据本身具有高维度性、轨迹连续性,使时空数据在实际应用面临查询效率上的挑战。
目前国内外在这个方面都有很多研究,基于B-tree,尤其是在R-tree[1]和R*-tree[2]上的变形和发展最多。这是因为对较大规模数据进行索引,如采用非平衡的树形索引结构很难满足查询效率的要求,即使如此面对现有的大规模数据其依然在查询效率上存在很大的问题。TPR-Tree[3]、TPR*-Tree[4]和HTPR*-tree[5]就是基于两者的重要变形,它们致力于减小索引规模,同时提高索引的查找和维护效率,如TPR-Tree引入类似最小边界矩形(Minimum Bounding Rectangle, MBR) 的速度边界矩形(Velocity Bounding Rectangle, VBR) 的概念,用于减小索引的重叠区域进而提高查找效率,但VBR不断地移动会增加算法的复杂性,难以满足现在系统对实时性的要求。
同时面对海量时空数据,树形结构的索引方法存在大量闲置的内部节点,占用了大部分的索引空间,而且存在难以用并行化方式进行索引管理的问题[6]。近些年,采用空间划分并编码以实现索引的思想逐渐受到重视并用于图像空间和地理空间的检索[7-9],其中文献[6]提出的D-Tree实质上是一个虚拟的无内部节点的树,它以一定的编码方式对包含数据的叶子节点进行编码。D-Tree避免了对内部节点的存储,同时也剪除了空的叶子节点,降低了存储成本,一定程度上提高了查询效率。然而D-Tree完全根据数据分布进行区域划分,面对频繁大量的数据插入时,每次都需在所有数据上重新建立索引,这在高频写入的实时系统中将耗费大量的时间和空间资源。
针对上述问题,本文提出了HDL-index (Hybrid spatio-temporal data indexing based on data and query-log distribution, HDL-index)索引方法。HDL-index对实时数据采用空间划分的思想,使数据平均分布在所划分的单元格内;同时有效利用历史查询记录,将在查询热点区域上进行查询的历史记录聚类后抽象出查询模型,然后根据模型的坐标位置和其查询粒度对整体查询区域进行分割从而建立索引。最终基于GeoHash编码进行两部分索引的合并[10],同时对数据采用在时间维度上的多层存储方式进行存储。
1 HDL-index整体思想
本文提出的索引机制结合实时数据和历史查询记录两个部分进行索引的建立。对于实时数据部分,HDL-index算法根据数据分布进行区域划分,尽量均衡划分得到的每个子区域所包含数据的个数,而且在区域划分的同时对划分得到的子区域进行GeoHash 编码。对于历史查询记录部分,HDL-index算法采用贪心策略抽象出历史查询记录的代表模型[11],然后根据这些模型的分布,将于之对应区域内默认粒度的索引单元格迭代四分到小于等于模型的粒度,本文称之为四分基准化。同样对得到的索引单元格进行GeoHash编码,最终将两部分索引合并作为新的索引待查,具体流程如图1所示。
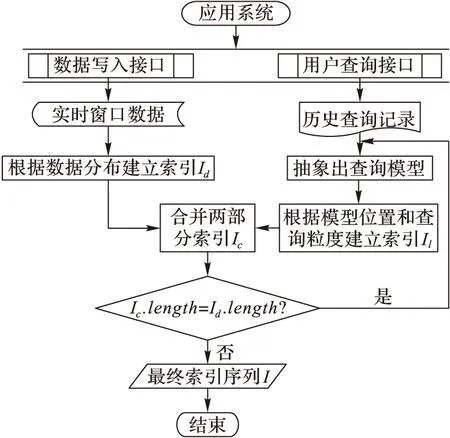
图1 建立HDL-index索引流程
对于图1中历史查询记录是指在系统应用的空间范围内进行区域查询的记录,而对于每一个查询记录对应的查询区域本文都将其用一个能覆盖它的最小矩形表示,以便实际应用中方便操作。
在空间数据的类型上,为了应对更加复杂的应用要求,例如对于运送危险化学物品的车辆,按照交通规定需要距离人群、住宅区、加油站一定距离行驶停放,这里就要求对整个车辆进行处理。本文将时空数据类型从点对象扩展到非零面积对象,对非零面积对象采用上面处理查询区域的方式以矩形表示。这时考虑到数据的一致性,在处理空间点数据对象时将它当作一个矩形处理。例如:任意一个空间点PX=(x,y),则它的矩形形式为RX=(PLL,PRU),PLL=PRU=PX(PLL为左下角坐标,PRU为右上角点坐标,下文同),但在实际存储时只存储PX,这样不但解决了数据结构不统一的问题,而且没有占用额外的存储空间。
按图1中的流程最终合并得到的索引I将为下一批数据到来之前的查询提供索引。在数据存储方面,海量时空数据的存储压力大多来自数据密集区域。根据HDL-index建立的思想,在数据密集区域内,图1中属于Id索引的每个索引单元格的数据条数约等于按数据分布进行空间划分时设置的每个单元格所能包含数据量的最大阈值Nmax;同时在存储每个索引单元格包含的数据之前,需采用2个长整型记录,分别记录索引编码值和数据总长度,以及用两个时间戳存储这些数据中的最小和最大的时间值共32个字节的标识信息,数据的实际存储形式如图2所示。
为了对图2给出的数据存储方式进行形式化的定义,假设每条数据大小为Rsize字节,每个磁盘块大小为Bsize字节,每个磁盘页有k个磁盘块,则可定义用于存储图1中属于Id的单个索引单元格包含数据所需的磁盘页个数Dpage为:
(1)
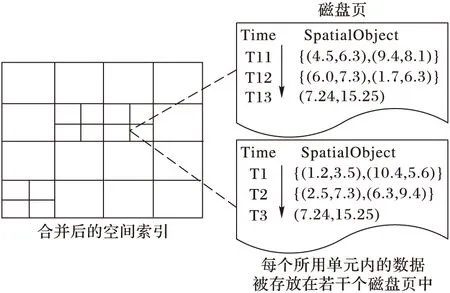
图2 数据的实际存储形式
图1中Id和Il两部分索引都是对相关区域进行4等分建立起来的,但由于数据并非绝对均匀分布,因而在Id和Il合并得到I时也就不可能将Id中需要细化的单元格内的数据绝对4等分,所以可定义存储图1中属于I的单个索引单元格内的数据所需磁盘页的个数D为:
D≈Dpage/4p;p∈N
(2)
在按图2的进行数据存储时,对不同应用可以根据Rsize设置Bsize的大小;同时图2所示的存储结构为每个批次的数据分配若干个独立的磁盘页,将数据按时间顺序进行连续存储, 这样可有效地解决时间维度上的查询问题。
2 HDL-index的结构与算法
2.1 面向实时数据的索引建立
对于当前时间窗口的实时数据,本文采用空间划分的方式,将整个二维的数据区域沿两个维度的中线分成4个子矩形区域,然后按这种方法进行递归划分,最终使每个子矩形内的数据量尽量相当。为了使每个子矩形内的数据量相近,D-tree在进行区域划分时,需判断区域内数据的个数,使其小于等于给定的阈值Nmax,但对于涉及多个对象的大规模实时数据系统,同一个坐标点在窗口时间内的不同时刻很可能产生多个数据。假设这个数值为nr,当nr≥Nmax时递归将不能完成,为此需要添加一个参数Lmin,限制子区域最小边长。另外,由于本文将数据类型推广到二维对象,当出现非零面积数据大面积交叠时递归同样不能完成,所以需要在划分中判断划分的四个子区域两两对角区域内的数据量较其父区域是否减少,如果两个对角区域都未减少,则说明存在重叠区域不必再继续划分。具体划分过程如算法1。
算法1 实时数据的划分(AreaDiv)。
输入:初始矩形Rinit,Nmax,Lmin,数据集合D,初始矩形编码Cinit。
输出:CRes:Tuplet=(Code,Entry-Set)。
1)
Lside← float:GetRecSide(Rinit);
2)
subRecs← QuadRec(Rinit);
3)
Define arrayDsubrecord data set in thesubRecs
exit← NumberLE(D,subRecs,Nmax,Dsub);
5)
IFLside≤Lminorexitis true THEN
6)
Add the data that contained inRinitinto Entry-SetEcurrent;
7)
Instance a newt=(Cinit,Ecurrent), add it intoRes;
8)
远程监测平台主要实现对集装箱的在线管理和实时监测,远程监测平台采用B/S结构[14-15],使用最新的C#技术进行开发,建立ASP.NET MVC应用程序,数据库采用MySql[16],根据“低耦合、高内聚”的模块划分原则将平台划分实时环境监测、实时位置监测、历史数据查询、历史轨迹查询、电子挂锁管理等模块。监测管理平台界面如图8所示。
RETURNCRes;
9)
END IF
10)
Csub←Cinit+"00";
11)
AreaDiv (subRecs[0],Nmax,Lmin,Dsub[0],Csub);
12)
Csub←Cinit+"01";
13)
AreaDiv (subRecs[1],Nmax,Lmin,Dsub[1],Csub);
14)
Csub←Cinit+"10";
15)
AreaDiv (subRecs[2],Nmax,Lmin,Dsub[2],Csub);
16)
Csub←Cinit+"11";
17)
AreaDiv (subRecs[3],Nmax,Lmin,Dsub[3],Csub);
在算法1中,调用的函数NumberLE主要是进行区域内数据个数是否小于等于Nmax的判断,用以解决上面提到的数据位置重叠的问题。Entry-Set中每个实体都代表一个空间数据对象,具体形式为(TraID,ObjPointer),其中TraID为空间对象一次移动过程的轨迹编号,ObjPointer指向数据地址。算法1中,在区域划分的同时进行GeoHash编码,GeoHash的具体编码方式如图3所示。
采用这样的方式进行编码,可以通过所提供的经纬度值快速定位到其所对应的索引编号,继而根据其他查询条件获得最终结果,同时这样的编码方式对任意给定位置的邻近查询操作也是非常高效的。当所查找的相邻区域和给定位置处于同一级别的编码时,可直接获取索引编码;当两者不在同一级别时,由于GeoHash是前缀编码,所以依然能顺利得到所要的索引编码。
假设要查询图3(b)中,与索引编码IC=1100所包含的某个空间对象相距LQ(单元格的边长为LU,假设此时LQ=LU)的符合某些条件的空间对象。以查找IC正下方索引为例,只需取IC奇数位置上的值,与LQ/LU所得整部分值的二进制形式作二进制的减法运算,然后用所得结果替换IC对应位置的值即可得到要查找的索引编码1001,对照图3(b)可以看到1001正是IC正下方索引编码。按照这样的计算方法,结合表1给出的不同查找方位的操作列表即可求得其正上方、正左方和正右方的索引编码。
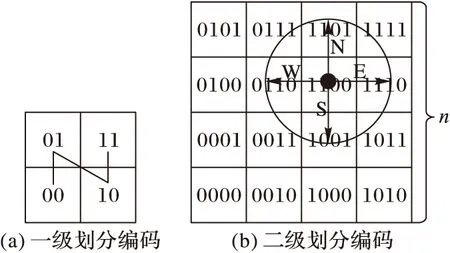
图3 GeoHash编码方式示例

查询方向涉及编码值的位置操作(N=floor(LQ/LU))右偶数位+N下奇数位-N左偶数位-N上奇数位+N
表1中操作列中的值因二进制无法直接表述,因此采用的是十进制表述。在实际操作中需统一转化为二进制再进行运算。对于其他四个对角线方向的邻近查找可通过正方向间接计算出来,其中N=(2n/2-1)≤(n-1),确保运算可正确进行。
2.2 面向历史查询记录的索引建立
只面向数据通过空间划分的方式建立索引,在每次数据更新时都需要对所有有效数据重新进行划分。在大数据时代,面对频繁和大量的数据更新,如果采用上述的办法,将耗费很长的时间用于索引的建立;同时,只面向数据建立的索引只能体现数据的分布,并不一定能提供较好的查询效果,即数据的分布和查询的分布并不是总是一致的。在网络拓扑等相关研究中,利用查询记录辅助索引建立方面国内外学者已经有不少研究[12-14],同样的本文将历史查询记录分布作为构成索引的一部分,用以快速建立索引并提高查询效率。
对于时空数据的查询从空间角度可分为区域查询和点查询。本文将区域查询所覆盖的范围用其形心代表,这样可以将查询统一表示为元组〈PQ,RQ〉,其中PQ为区域查询的形心或者查询点,RQ为查询半径,对于区域查询设置其值为能覆盖查询区域最小正方形边长的1/2,对于点查询RQ=0。在面向历史查询记录建立索引时,首先需要对所有PQ采用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[15]进行聚类,使得的每个cluster内每两个相邻的PQ的距离不大于r(r为根据具体数据情况给定的经验值),这样做的目的是为了使接下来抽象出查询模型能尽可能大地覆盖其代表的各个查询区域的面积,即保证模型尽量真实。然后在对每个cluster内的元组进行模型抽象时,采用改进的DBSCAN算法获取最近邻点的算法依次获取Qmodel,它是以某个确定PQ为圆心Pmodel,以r为半径圆的外接正方形,并且能尽可能多地包含PQ。再用统计的方式获取Qmodel中PQ对应的出现比例为prate的RQ值为Rrate。最后构造一个以Pmodel为中心,以Lc=2(Rrate+r)为边长的正方形作为查询代表模型,这样在给定prate的情况下,使抽象出的模型可以覆盖其所代表的绝大部分历史查询区域。这个具体过程如算法2所示。
算法2 抽象查询代表模型(CreateModel)。
输入:clusterTupletc=〈PQ,RQ〉集合S,r,prate。
输出:MRes:Tupletm=(Center-Point,Side-Length)。
1)
IF the number oftcinSis equal 0 THEN
2)
RETURNMRes;
3)
END IF
4)
IF the number of〈PQ,RQ〉inSpercent is equalprateTHEN
5)
Instance a newtm=(PQ,2(RQ+r)) and add it intoMRes;
6)
RETURNMRes:
7)
END IF
8)
Create a setSrto keep rest oftcafter GreedyModel(Sr,r);
9)
Sr←S;
10)
Instance a newtm← GreedyModel(Sr,r);
11)
AddtmintoMRes;
12)
CreateModel(Sr,r);
算法2中函数GreedyModel(Sr,r)主要实现贪心策略以获取能代表最多历史查询的代表模型。HDL-index将所有抽象得到的查询代表模型记录在Json文件中,这样以配置文件的形式进行下面索引建立的操作,有助于索引的并行化。
在根据代表模型进行空间划分上,首先需要根据系统设置将整个查询区域按照2.1节的方法划分成若干区域,作为默认查询粒度为Ld的索引单元格。然后将所有的查询模型对应到查询空间上,检查各个查询代表模型的边长Ld与Lc的大小关系。如果Ld>Lc,则采用2.1节的方法将相关默认粒度的索引单元格进行递归划分,直至Ld≤Lc。由于划分的思想相似,只是面向历史查询记录的索引建立不涉及数据,只需要判断Ld和Lc的关系,不需要其他限制条件,在此就不再进行累述。最后将得到的结果同样采用GeoHash的编码方式进行编码,以便进行Id和Il两部分索引的合并。
2.3 索引的合并和更新策略
2.1和2.2节完成了图1中Id和Il两部分索引的建立,按照HDL-index的整体思想,需要将两部分索引合并成最终索引。由于采用同样的编码方式为完成合并提供了前提,在合并过程中有以下三种情况:
1)对应区域内Id和Il的编码相同,说明它们代表完全相同的查询区域,由于只有Id对应实际数据,只需要保留Id;
2)对应区域内Id的编码是Il的编码的前缀,说明Id的查询粒度是Il的m倍(m为正整数),这时需要将Id的编码对应的数据,对应到以Id的编码为前缀的Il中相应的索引区域内并保存Il;
3)对应区域内Il的编码是Id的编码的前缀说明Il查询粒度较大,保存Id即可。
在合并中第2)种情况要对Id进行四分划分,划分后得到的索引数量必然呈4倍量级地增长,从而产生更多的索引编码,但是Il代表查询的热点,所以此时小粒度的索引将大幅度提高查询效率。由于HDL-index具有较简单数据结构,在此是用较小空间换取了较高的时间效率。
经过上面的合并可以得到最终的索引,对于索引更新的基本策略如下:
1)在系统初始化时,由于没有历史查询记录,HDL-index只采用Id作为最终索引,等待第一批查询记录到来;
2)当查询记录到来时,按照HDL-index的思想进行索引的建立得到完整索引,然后当实时窗口数据再次到来时,停止Il的建立,只将Id与完整索引合并;
3)当步骤2)不断合并过程中,上面合并操作第1)种情况和第3)种情况合并掉的编码总数量,等于步骤2)中Il的编码的数量时,回到步骤2)。
对于HDL-index基本更新策略中步骤3)触发条件实质上是指由于数据的不同和数据整体分布的改变使得查询热点变化,因而目前的索引已不能很好地适应当前的查询需求,所以需要对索引进行全部重建。由于最终索引结构与D-tree类似可采用相同的操作进行轨迹数据的删除,具体算法可参考文献[6],不同的由于HDL-index采用时间分层存储,所以可以对无时效性的数据进行批量删除。
3 HDL-index性能评估与实验
为了评估HDL-index的性能,本文采用国内某航空公司百万兆字节级别的真实数据进行各项性能的测试。近数千万条的数据分布在我国中东部地区和东南亚地区,这些数据是该航空公司采用GPS以1s为频率采集的,实验是针对在E114°~E116°和N21°~N23°区域内的数据进行的,大致为深圳、香港及其沿海周边空运繁忙地区为重点实验区域,同时经分析发现这些数据是在以边长为1经纬度的区域内聚集分布的。
为了更清楚体现HDL-index性能的优缺点,本文选取上文提到的D-tree作为比较对象,因为两者都采用空间编码的方式建立索引。本文的实验在一台2.20GHzIntelCoreDuoCPU,2GBRAM计算上机进行,同时采用同样数据集和相关参数设置。
3.1 索引空间性能评估
为了进行占用空间大小评估,定义了下面一系列参数以方便计算。
M:占用空间总大小;
S:总数据量
L:划分得到的索引单元格个数;
C:索引单元格的最大容量;
p:一个指针的大小;
d:一个双精度浮点数的大小;
i:一个整数的大小。
对于HDL-index和D-tree虽然采用不同的编码方式,但由于都是对空间数据进行研究,两者具有相同的索引数据形式,每个索引单元格由一个(Code,Entry-Set)元组(其中Code整数编码;Entry-Set为数据实体集合)表示,Entry-Set中每个实体一个(TraID,ObjPointer)元组(其中TraID为整数组合编码,由设备号和唯一时间标识组成;ObjPointer为指针,指向数据)表示。所以两者空间占用大小M可以统一表示为:
M=L*p*(C+1)+S*(p+8*d)
(3)
在同样的实验数据下在表达式(3)中,两者只有L和C两个参数不同,本文进一步将参数C取相同值,则决定两者占用空间大小只有参数L。由于D-tree直接采用Hash表的方式进行索引存储,而HDL-index采用时间分层的索引存储方式。实验将系统置于较大压力下运行,即每个批次的实时数据在划分后,都能使每个索引单元格达到其最大容量C,此时在k次数据到达后,则有LD-tree=kLHDL-index,图4展示了数据批次数(每批约100 000条数据)和索引空间的关系。
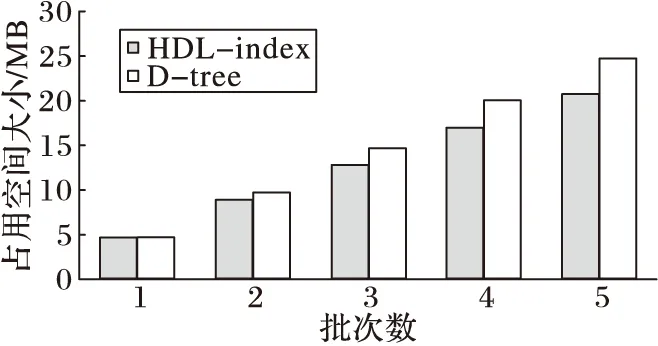
图4 批次数与索引空间大小的关系
由于HDL-index是由Id和Il两个部分合并得到的,而合并后的索引单元格会增加,但是由于数据量远大于查询记录提取得到查询代表的个数,合并过程中索引单元格个数只会少量增加,所以LD-tree的值会小于kLHDL-index。
3.2 时间性能评估
在索引的建立上D-tree只从数据考虑方面,通过空间划分使得每个索引单元格内所包含的数据个数尽量均衡在Nmax左右。按照这样策略进行索引的建立时,由于D-tree采用的是递归方法,所以D-tree耗费的时间t与数据量的个数是正相关的。HDL-index由于采用了在时间维度上的多层存储结构,使得HDL-index只需要对当前窗口数据进行划分。对于稳定系统的当前窗口数据,可以认为不同批次数据量是大致相同的,所以在HDL-index第一部分索引建立时间耗费上基本是一定的;同时由于HDL-index第二部索引只需读取Json配置文件,然后与默认查询粒度比较建立索引,这过程几乎不耗费时间。所以与D-tree相比,HDL-index建立索引的时间呈大致水平状态。图5给出了数据量与索引建立耗费时间的关系的平均实验结果。
由图5可以看到,只有在数据量较少时HDL-index两部分索引建立并合并的时间会大于D-tree。当数据量持续增大时,两者变化趋于稳定,但由于某些批次新增数据分布情况存在较大的变化对应地导致时间上的一定变化。
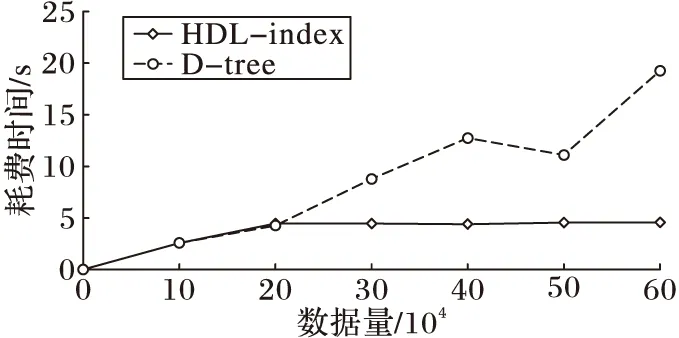
图5 数据量与索引建立耗费的时间的关系
3.3 查询性能评估
由于HDL-index和D-tree都是采用编码思想建立索引的,所以在设置相同的Nmax值时,两者在一般区域查询的效率基本一样。只需要通过查询条件计算出对应索引编码,再根据其他条件进行筛选,具体可参见文献[6]。但在热点区域查询方面,由于 D-tree只面向数据进行索引的建立,而HDL-index将历史查询记录考虑进来,在热点区域HDL-index根据查询将该区域进行更细粒度的划分,虽然会产生更多索引编码,但是对于时空应用绝大多数的查询都发生在热点区域,因此热点区域细粒度的索引不但大幅度提高该区域的查询效率,而且也提高了系统的平均查询效率。
对于热点区域划分得到索引单元格的个数和粒度,取决于抽象出的查询代表模型的位置和查询粒度(即模型的边长),而它们分别受算法2中r和prate两个参数影响。由本章开始所给出的数据分布和聚集特点,实验在所提到的相对较小的数据密集区域生成10 000个窗口查询,这些查询的查询半径在0.053 75~0.515 57,同时经分析发现数据聚集区域间隔在0.2经纬度左右,所以r的取值要小于0.2以保证每个聚类在同一个数据聚集区域内完成,具体r和prate对热点区域抽象模型的两方面影响如图6所示。
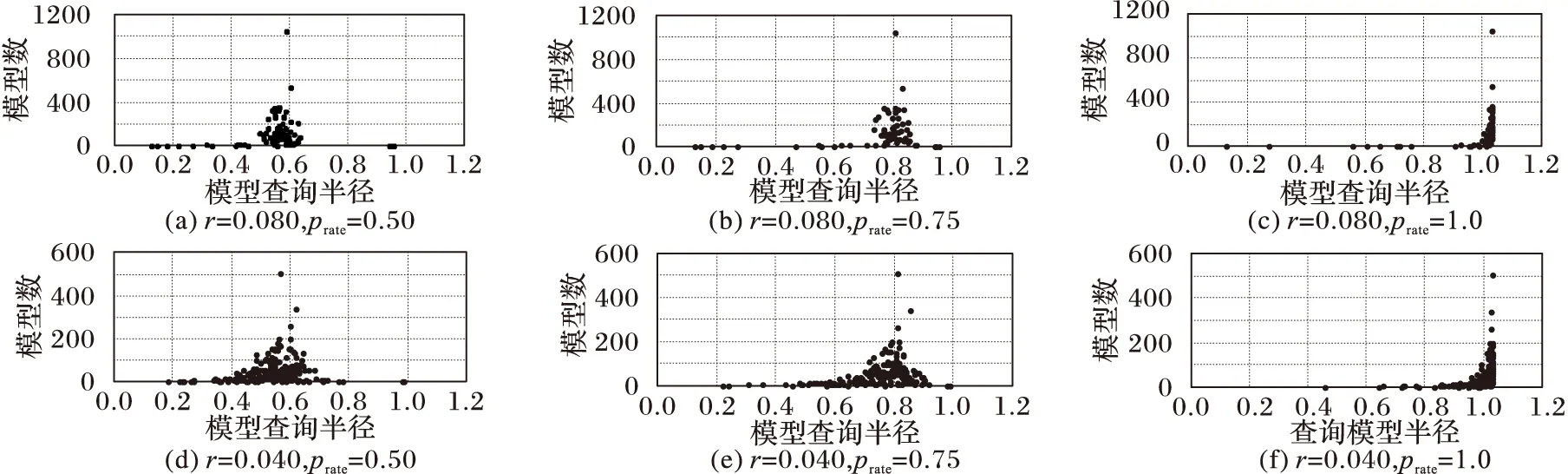
图6 不同参数情况下查询模型的抽取情况
由图6中横向子图间对比可以发现,prate只影响模型的查询边长,当r值相同时,模型的位置和每个模型覆盖的查询个数相同(r=0.08时,模型个数为77;r=0.04时,模型个数为183);同时,由图6中纵向子图间对比可以发现r影响模型所覆盖的查询个数,此时在相同prate位置上的半径也因为其所覆盖的查询记录集合不同而不同,而本文使用贪心的方法去选取中心点,这种方法只关注所覆盖的查询数量,所以在实际实验结果中对应模型的位置也有稍微的偏移。
根据上面的分析,只要r<0.2时就能得到合理的模型,但是实验证明r值与最终得到的模型个数成反比,所以要根据应用数据设置r的大小,本文选取r=0.08和prate=0.75以进行下面的热点区域的查询实验,根据数据分布设置Lmin=1,同时由于数据覆盖率较大结合实际划分发现将Nmax设置为数据总量的8%左右时,能保证数据较好地平均到各个索引单元格内,然后进行不同热点区域查询实验得到平均查询时间,具体实验结果如图7所示。由图7可以看出,HDL-index的查询性能明显优于D-tree。这是由于选择图6(b)的设置进行历史查询的模型生成,获得模型的查询粒度在0.1~0.92,而本文设置Lmin=1,最终使得HDL-index在相关热点区域的查询粒度比D-tree精确了2~16倍,同时对于热点区域查询数据量越大HDL-index的查询性能优势明显。
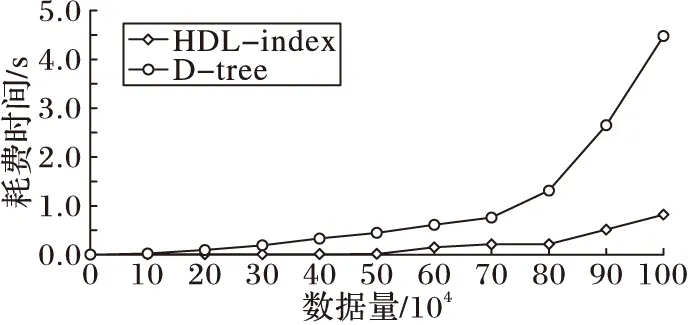
图7 热点区域查询耗费时间与数据量之间的关系
4 结语
本文在已有的索引思想上,对大规模时空数据的索引进行了研究。HDL-index的提出将目前在研究时空索引上所忽略的查询记录,这一现成且具有实际意义的数据考虑进来,解决了已有时空索引方式存在的空间浪费和热点区域查询效率低的问题。本文经过理论分析和实验证明了HDL-index的可行性和有效性,但在处理大规模移动时空数据的轨迹相似性查询时还有较大不足。对此下一步准备引入超图对索引编码进行组织,以便能更好地处理这类查询, 同时超图的引入也能更加清晰直观地展示不同轨迹之间的关系。
致谢 在这里由衷地感谢清华大学数据科学研究院——工业大数据研究中心陆薇常务副主任提供的良好交流学习环境和实验设备,也特别感谢中心张硕博士在选题和研究过程中精心指导及建议。
)
[1]GUTTMANA.Adynamicindexstructureforspatialsearching[J].ACMSIGMODRecord, 1984, 14(2): 47-57.
[2]BECKMANNN,KRIEGELH-P,SCHNEIDERR,etal.TheR*-tree:anefficientandrobustaccessmethodforpointsandrectangles[J].ACMSigmodRecord, 1990, 9(2): 322-331.
[3]BOKKS,YOONHW,SEODM,etal.Indexingofcontinuouslymovingobjectsonroadnetworks[J].IEICE—TransactionsonInformationandSystems, 2008,E91-D(7): 2061-2064.
[4]TAOY,PAPADIASD,SUNJ.TheTPR*-tree:anoptimizedspatio-temporalaccessmethodforpredictivequeries[C]//Proceedingsofthe29thInternationalConferenceonVeryLargeDataBases.Berlin:VLDBEndowment, 2003, 29: 790-801.
[5]FANGY,CAOJ,WANGJ,etal.HTPR*-tree:anefficientindexformovingobjectstosupportpredictivequeryandpartialhistoryquery[C]//Web-AgeInformationManagement,LNCS7142.Berlin:Springer, 2012: 26-39.
[6]HEZ,WUC,LIUG,etal.Decompositiontree:aspatio-temporalindexingmethodformovementbigdata[J].ClusterComputing, 2015, 18(4): 1481-1492.
[7] 陈建华,王卫红,苗放.基于Ex-Dewey前缀编码与R树的GML空间数据索引机制[J].地球信息科学学报,2010,12(2):186-193.(CHENJH,WANGWH,MIAOF.GMLspatialdataindexmechanismbasedonEx-DeweyprefixencodingandR-tree[J].JournalofGeo-InformationScience, 2010, 12(2): 186-193.)
[8] 骆歆远,陈刚,伍赛.基于GPU加速的超精简型编码数据库系统[J].计算机研究与发展,2015,52(2):362-376.(LUOXY,CHENG,WUS.AGPU-acceleratedhighlycompactandencodingbaseddatabasesystem[J].JournalofComputerResearchandDevelopment, 2015, 52(2): 362-376.)
[9]LIY,WANGH.Spatialindexstudyformulti-dimensionvectordatabasedonimprovedquad-treeencoding[EB/OL]. [2016- 02- 09].http://xueshu.baidu.com/s?wd=paperuri%3A%2836fe3b793cc15fbceb06230d1c65a4b4%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fproceedings.spiedigitallibrary.org%2Fproceeding.aspx%3Farticleid%3D790968&ie=utf-8&sc_us=16220466832006650551.
[10] 金安,程承旗,宋树华,等.基于Geohash的面数据区域查询 [J].地理与地理信息科学,2013,29(5):31-35.(JINA,CHENGCQ,SONGSH,etal.Regionalqueryofareadatabasedongeohash[J].GeographyandGeo-InformationScience, 2013, 29(5):31-35.)
[11]GUDMUNDSSONJ,LEVCOPOULOSC,NARASIMHANG.Improvedgreedyalgorithmsforconstructingsparsegeometricspanners[J].SIAMJournalonComputing, 2002, 31(5): 1479-1500.
[12]BAEZA-YATESR,SAINT-JEANF.Athreelevelsearchengineindexbasedinquerylogdistribution[M]//StringProcessingandInformationRetrieval,LNCS2857.Berlin:Springer, 2003:56-65.
[13]LAMHT,PEREGOR,SILVESTRIF.Onusingquerylogsforstaticindexpruning[C]//Proceedingsofthe2010IEEE/WIC/ACMInternationalConferenceonWebIntelligenceandIntelligentAgentTechnology.Washington,DC:IEEEComputerSociety, 2010: 167-170.
[14]GURAJADAS,SREENIVASAKP.Indextuningforquery-logbasedon-lineindexmaintenance[C]//Proceedingsofthe20thACMConferenceonInformationandKnowledgeManagement.NewYork:ACM, 2011: 1997-2000.
[15]ESTERBM,KRIEGELHP,SANDERJ,etal.Adensity-basedalgorithmfordiscoveringclustersinlargespatialdatabaseswithnoise[EB/OL]. [2016- 02- 05].http://www.dblab.ntua.gr/~gtsat/collection/dbscan.pdf.
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61502106),theRegionalSpecialMajorScienceandTechnologyProjectofFujianProvince(2014H4015).
MENG Xuechao, born in 1989, M.S. candidate. His research interests include large data storage and processing, spatio-temporal database index optimization.
YE Shaozhen, born in 1963, Ph. D., professor. Her research interests include intelligent analysis and processing of medical information, E-commerce.
New spatio-temporal index method based on real-time data and query log distribution
MENG Xuechao1, YE Shaozhen1,2*
(1.CollegeofMathematicsandComputerScience,FuzhouUniversity,FuzhouFujian350108,China; 2.FujianKeyLaboratoryofMedicalInstrumentationandPharmaceuticalTechnology,FuzhouFujian350002,China)
In the era of large data, the data has the characteristics of large volume, obvious spatio-temporal complexity, high real-time requirement, and etc. However, the traditional method of indexing large-scale spatio-temporal data based on tree structure has the problem of low utilization of storage space and low efficiency of query. In order to solve this problem, a new method named HDL-index was proposed to establish the spatio-temporal index based on the distribution of data and historical query records. On the one hand, the whole area was partitioned based on the spatial distribution of the data. On the other hand, taking into account the continuity of query, the query-models were obtained after density-based clustering on historical query objects, and then based on the model coordinates and query granularity of the overall query area segmentation, the two indexes were merged based on their GeoHash codes, and finally the optimal index coding was obtained. HDL-index takes better account of the data distribution and users’ queries, making the index on the frequent query area more refined. Compared with the efficiency of the similar method, the efficiency of the index creation is improved by 50%, and the query efficiency of the hotspot region can be increased by more than 75% when the data is evenly distributed in the real aeronautical data set.
spatio-temporal index; big data; GeoHash encoding; density clustering; hotspot region query
2016- 08- 15;
2016- 10- 03。
国家自然科学基金资助项目 (61502106);福建省区域重大科技专项资助项目 (2014H4015)。
孟学潮(1989—),男,河南驻马店人,硕士研究生,主要研究方向:大数据存储与处理、时空数据库索引优化; 叶少珍(1963—),女,福建福州人,教授,博士,CCF高级会员,主要研究方向:医学信息智能分析与处理、电子商务。
1001- 9081(2017)03- 0860- 06
10.11772/j.issn.1001- 9081.2017.03.860
TP
A
