基于多层网络流量分析的用户分类方法
2017-05-24陈松健
穆 桃,陈 伟,陈松健
(南京邮电大学 计算机学院, 南京 210023) (*通信作者电子邮箱chenwei@njupt.edu.cn)
基于多层网络流量分析的用户分类方法
穆 桃,陈 伟*,陈松健
(南京邮电大学 计算机学院, 南京 210023) (*通信作者电子邮箱chenwei@njupt.edu.cn)
对用户进行准确分类对提高客户定制服务的质量具有重要作用,但用户出于隐私保护的考虑,经常不配合网络服务商,拒绝提供个人信息,如地理位置信息、兴趣爱好等。为解决这一问题,在保护用户隐私的前提下,通过分析网络层、应用层等多层网络流量,然后利用K-means聚类、随机森林算法等机器学习方法,预测出用户的地理位置类型(比如公寓、校园等)和兴趣爱好,并分析地理位置类型与用户兴趣爱好的关系,以提高对用户分类的准确性。实验结果表明,此方案可以自适应地划分用户所属用户类型和地理位置类型,通过关联用户的地理位置类型和用户类型提高了用户行为分析的准确性。
流量分类;地理位置;用户偏好;K-means聚类;随机森林
0 引言
日常生活中,人们越来越习惯利用无线网络上网,产生的上网流量也日益增多。用户的网络流量主要应用于两方面:一方面利用网络流量来检测网络中可能存在的入侵行为[1]和检测恶意软件[2]等网络异常行为[3];另一方面是通过网络流量的分类,利用机器学习方法来预测地理位置和分析用户网络行为[4-5]。目前越来越多的服务倾向于利用用户的上下文信息(比如位置类型)来预测用户的偏好[6],但由于在基于用户真实地理位置所提供的服务中,服务商需要分享用户的隐私信息,这往往让用户认为是一种对个人隐私的威胁。
在现实生活中,仅仅依据用户的位置类型来推断用户的偏好是不充分的,不能因为用户所在的位置类型而认为该位置类型的用户的网络偏好是一样的。为解决这一问题,在对于用户的网络流量[7-8]的分析后,需要进一步研究用户对每个应用程序类别的兴趣程度。通过对用户的历史网络访问数据进行分析,并根据用户兴趣将用户分成不同类型用户。将用户的地理位置和用户类型结合用于分析用户偏好,可以主动向用户提供感兴趣的内容。
本文首先利用被动方式监测用户的网络流量并对网络流量进行数据预处理,建立用户设备指纹集,将一个或多个IP地址对应到某一确定的用户身份。然后使用随机森林算法分析网络层统计信息,用来预测用户地理位置类型。之后利用应用层的统一资源定位符(Uniform Resource Locator, URL)类别信息通过K-means将用户分成8种用户类型。最后,通过对用户地理位置类型和用户类型之间的联系,发现通过地理位置和用户类型相结合,比文献[9]更准确地为用户提供服务。
本文的主要工作有:
1)通过分析网络协议(Internet Protocol, IP)地址、IMEI(International Mobile Equipment Identity)、用户账号信息(userid)和推送服务信息(appid),建立了用户设备指纹集,在分析用户类型前,可以确定唯一用户;
2)通过网络层信息和应用层URL分类信息分别确定了用户的地理位置类型和用户类型;
3)将用户地理位置类型和兴趣爱好相结合,提高了用户分类的准确性。
1 相关工作
对网络流量分类的目的是为了检测和分析网络中的应用程序和用户的行为。Zhang等[10]提出了在短时间内不用管理员身份就可以通过流量分析正确推断出用户在线活动的分层分类系统。文献[11]也通过设计一个基于位置的熵值法的网络流量分析平台将用户聚成固定用户组和静态用户组,并分别利用智能时分法和基于时间的马尔可夫法来对这两组用户进行预测。文献[12]利用网络流量创建了一个APP_URL表来记录该网络中所有应用程序与远程恶意服务器连接过的日志。通过日志所建立的黑名单,可以检测到恶意的应用程序。在提高分类算法的性能上,文献[13]使用将相关信息与分类过程结合的无参流量,提出了即使在非常少量训练集的极端情况下,依然能够有效提高性能的分类方法。这些研究工作与本文都是利用网络流量来监测和分析网络流量。
传统的基于地理位置向用户发送服务是在用户允许的情况下,通过GPS(Global Positioning System)等技术分享用户的实际地理位置实现的,但是,通常情况下用户并不乐意分享个人的隐私信息。机器学习方法利用网络流量信息来预测用户的地理位置类型可以解决这个问题。通过被动检测方式获得用户的网络流量,用户不需要分享自己的地理位置就可以获得服务。文献[9]提出了利用这种方法并以较高的准确率预测住宅区、餐厅、校园和机场旅游四类地理位置类型,但是,即使预测了用户所属的地理位置类型,并不能仅以地理位置直接推断用户的网络偏好,因此,本文通过网络层统计信息预测用户所在的地理位置类型,并通过应用层URL分类信息聚类出8种用户类型。将用户的地理位置类型和用户类型相结合,能更可靠地推断出用户偏好。
通过网络层和应用层的特征属性[14],例如,流的总数、传输控制协议(Transmission Control Protocol, TCP)数目、应用程序的URL等,可以尽可能地准确统计出用户的网络行为特征。最后利用机器学习算法可以更加直观地了解用户在网络中的行为特性。目前,对网络流量分析所使用的机器学习方法主要是两类:第一类是无监督机器学习[15]方法,比如文献[16]和文献[17]所提出的K-means和Autoclass;第二类是C4.5[18]、随机森林[19]、K最近邻算法和神经网络等监督机器学习方法。
2 框架设计
本文工作主要是利用网络流量中多层信息推断用户类型,其中包括使用网络层统计信息和应用层URL分类信息来预测用户的位置类型和用户类型。图1为系统架构。
数据预处理 为了后续工作中能够更加方便地利用捕获到的数据,本文将得到的数据进行预处理,例如提取用户IP地址、URL信息等,并存储到数据库中。
用户设备指纹集 在长时间数据捕获的过程中,由于动态主机配置协议(Dynamic Host Configuration Protocol, DHCP)的原因,有可能某一个用户使用不同的IP地址来上网。为了增强对用户的行为的分析,需要将用户所使用过的IP地址通过本文建立的用户设备指纹集来找到,并将用户的数据进行整合。
网络流量分类 通过将网络流量按照网络层特征统计和应用层URL分类两种方法进行特征提取。网络层特征统计包括每个用户的所有数据包的多个特征。应用层URL类别按照应用程序的类别(比如,游戏、教育、社交网络等)进行分类。
地理位置类型预测和用户类型聚类 类似文献[9]的方法,利用网络层的统计信息通过随机森林分类方法来预测用户的位置类型,得到了85%的预测率。依据用户访问的各应用程序的类别百分比通过K-means聚类方法将用户分成多种类型。根据对应用程序的偏好将相似用户归为一类,有利于分析多个用户的偏好。在预测出用户所在的位置类型后,通过分析用户的类型,能有针对性地向用户推送服务。
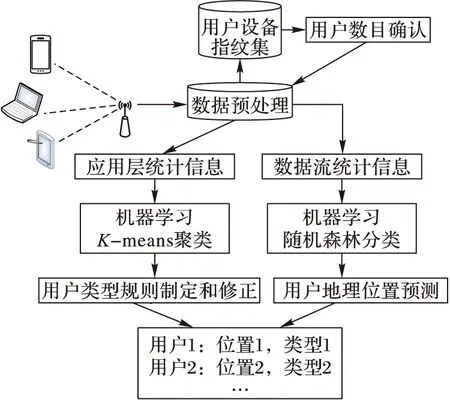
图1 根据用户网络流量信息分别预测地理位置类型和聚类用户类型
3 用户设备指纹集
3.1 数据包捕获和预处理
1)在Linux平台下利用tshark和aircrack-ng捕获网络流量数据并以.cap格式存储。通过在校园、火车站、餐厅、宿舍四种位置类型20天的采集,获取了大概70 GB的数据。
2)获取数据包中〈捕获时间,基本服务设置号(Basic Service Set Identifier, BSSID),服务设置号(Service Set Identifier, SSID),媒介访问控制(Media Access Control, MAC)地址,源IP地址,源端口,目地IP地址,目的端口,协议,数据包长度,URL〉信息。其中BSSID、SSID和用户MAC地址为可选项,其他信息必须存在,否则视为无效信息。
3.2 用户设备指纹的收集方法
在无线网络中,由于DHCP,用户使用过的IP地址不固定,无法获得用户全部网络流量。在内网与外网交接处,由于网络地址转换(Network Address Translation, NAT)协议将用户内部IP地址映射到外部IP地址,用户的IP地址无法确定。
基于以上原因,通过移动设备国际识别码IMEI 、userid和推送服务中的appid建立的用户设备指纹集确定用户设备。通过用户设备所具有的以上特征就能确定用户所使用过的IP地址。
IMEI是手机的唯一标识,通过对比用户的IMEI,即使用户使用的IP地址不唯一,也可以将用户长时间所使用的多个IP地址与用户对应起来。在本文收集的IMEI信息中,IMEI有三种存在形式:
1)原始形式,由15位数字组成;
2)采用MD5对原始15位数字进行加密;
3)由字母数字和其他特殊符号组成的多位字符串。
userid是指用户登录各种应用软件所使用的账号。例如捕获的数据包中存在以”cntaobao”开头经过UTF8编码过的淘宝账号名称。通过检测相同的userid是否存在于不同的IP地址中,就可以确定这些IP地址是否为相同用户。
appid是指推送服务中对用户设备相应软件的独立标识。 通过检测推送服务器向设备中应用程序所发送的服务信息中的appid,可以确定此用户的移动设备上是否安装过相应软件。
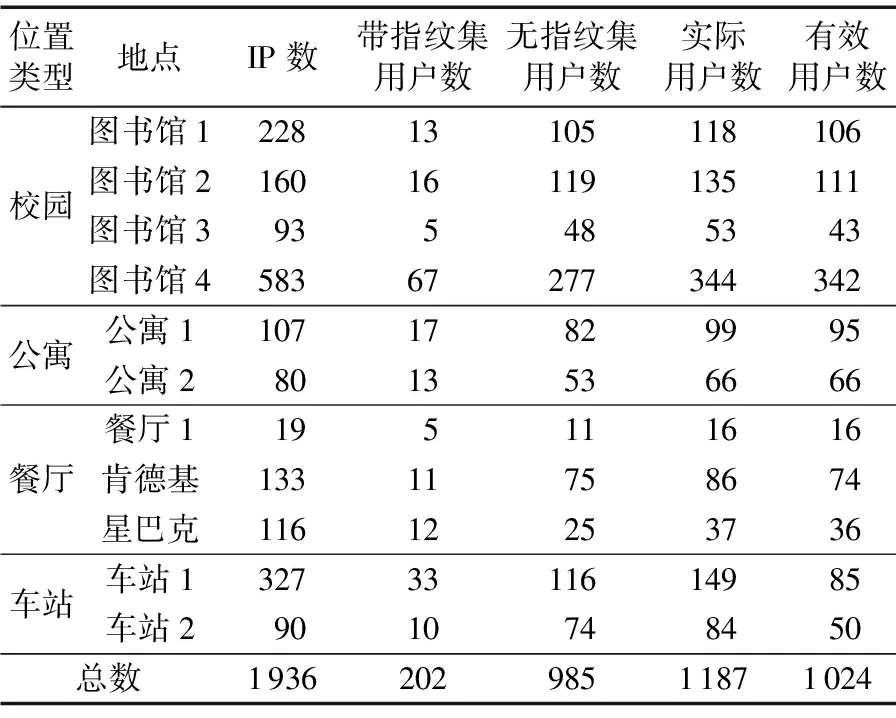
表1 不同地理位置类型的用户数据
表1列出了在不同地理位置类型中用户数目的获取情况。可以看到通过202个带有设备指纹集的用户将总共1 936个IP地址缩减到1 187个IP地址,即将1 936个IP地址对应到实际的1 187个实际用户。对于没有设备指纹集的IP地址,通过〈捕获时间,IP地址〉标识为一个用户。另外,利用有效流量信息(网络层信息和应用层URL信息)对实际用户过滤,最终得到1 024个有效用户。
4 多层网络信息提取与处理
多层网络信息提取内容分为两种:提取用户网络层的统计信息和对每个用户的应用层URL信息进行分类统计。
4.1 网络层统计特征
本文将用户的网络层流量特征分为粗粒度层、协议层、流层和数据包层四个层次[9],总共52个特征值。表2介绍了网络层统计特征提取的具体内容,其中流定义为五元组〈源IP地址,源端口号,目的IP地址,目的端口号,协议〉,并用〈最小值,最大值,平均值,中值,标准差,偏态,峰态〉来统计流层和数据包层里的特征。式(1)、(2)为此次实验偏态和峰态所使用的计算公式:

(1)
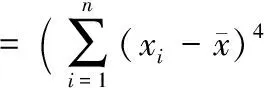
(2)
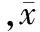

表2 网络层统计特征分类
4.2 应用层URL信息特征
1)关键字提取。通过对URL中应用程序对应关键字(例如微信在URL中对应的关键字为”weixin”)进行过滤,总计得到了5 602个不同的URL,650个关键字。
2)关键字分类。将应用程序对应的关键字分为20个类别,每个类中的关键字个数如表3所示。不需要了解到用户的具体偏好,只需了解用户对不同类别是否感兴趣。在统计关键字过程中,在不失去原有类别特性的前提下通过关键字相同部分将多个关键字归为同一关键字。比如“邮件”中,可能出现”gmail””hotmail”和”qqmail”等不同的电子邮件服务商,归为邮件类别中关键字”mail”。
3)计算URL类别。将每个类别中关键字出现的总次数占总类别的百分比作为这个类别的特征值进行提取。

表3 应用层URL分类
4.3 多层网络信息处理
4.3.1 用户地理位置分类
与文献[9]相似,利用随机森林分类算法通过网络层统计信息来预测用户地理位置。随机森林通过自主法(boot-strap)[20]重采样技术,不断生成训练样本和测试样本,由训练样本生成多个分类树组成随机森林。也因此称随机森林为包含多个决策树的分类器。通过随机森林算法利用用户的网络层统计信息将用户进行聚类,其优点是随机森林能够在不用特征选择的前提下处理高维度的数据,并且快速处理大量的离散型数据集或者连续型数据集。
随机森林的处理流程如下:
1)从原始训练集N中应用boot-strap法生成K个新的自助样本集,每个自助样本集是每棵分类树的全部训练数据。
2)每个自助样本集生长为单个分类树。在树的每个节点处,假设有M个特征变量,则在每个节点处随机挑选m个特征变量(m≤M)。按照节点不纯度从m个特征变量中选择一个特征进行节点分裂。
3)对每棵树不作任何剪枝,根据生成的多个树分类器对新的数据进行预测,分类结果按树分类器的投票多少而定。
对于只有一个IP地址的用户,可以直接计算上述52个特征值作为此用户的网络层统计特征;而对于包含多个IP地址的用户,通过用户所属的位置类型(宿舍、餐厅等)不同来区别此用户的位置,最终通过用户的IP地址标识每个用户。通过用户地理位置类型的预测,可以推测该用户的短期或长期偏好。例如,如果预测用户是在车站或餐厅这种短时间逗留的位置类型,那么在一段时间内,可以向用户推送与车站或者餐厅相关的服务。另外,如果用户是在长期活动的位置类型(校园或公寓),那么用户可能长期对校园或公寓相关的服务感兴趣。
4.3.2 用户类型聚类
在对应用层URL信息特征处理中,为对用户进行全面分析,本文将用户所有的IP地址中的应用层URL信息都统计起来并利用K-means聚类算法将用户分成8种不同的用户类型。然后根据每种用户类型中每个应用层URL类别百分比范围,通过时间段划分人工校正错误的用户类型。如果每种用户类型的URL类别所占的百分比各不相同,说明用户对不同类别的应用程序的感兴趣程度也不相同。例如,假设在类型1中社交网络和教育方面所占的比重较大,说明该类型用户对社交网络和教育比较感兴趣。将用户分类的原因在于在对用户的网络流量统计之后,凭据大量的、零碎的实验数据无法直接有效地去评估用户的兴趣、爱好,这给本文对所有用户进行全面、广泛的统计带来很多不便。通过K-means算法利用用户的网络流量将用户进行分类,利用系统、模型化的方式去统计用户所属的类型,有利于更直观地研究用户的兴趣爱好。K-means算法[21]是将样本基于欧氏距离聚成多个分类,聚成速度快且使用简单。具体算法流程如下:
1) 随机取得k个初始中心点μ1,μ2,…,μk∈Rn;
2) 重复下面两步直到收敛
对于每个点i,计算欧氏距离,划分进相应的簇
ci:=argmin‖xi-μj‖2
对每个类j,重新计算中心点
其中:样本数据集为X={xi|i=1,2,…,m};k为样本最后聚类数;ci=j表示点i到类别j的距离最短,即属于类别j(j∈k);μj代表每次迭代后重新产生的中心点。
通过对应用层URL信息的提取将用户分成多个类别,并且当这些类别有很明显的用户兴趣偏向时,一方面可以全面了解用户的所有网络涉猎范围,另一方面,可以在对真实用户的预测中有效判断用户的偏好。另外,只通过用户的地理位置类型判断用户的偏好会只关注用户的短期兴趣而忽略了长期兴趣,并且只依据地理位置而判断用户的偏好依据不足。根据用户对应用软件类型的偏好将用户划分为不同的用户类型,可以在预测用户地理位置类型之后,进一步了解到用户的长期兴趣,因此,通过分析用户地理位置类型与用户类型之间的关系(比如不同地理位置类型中用户类型的百分比不同),并结合两者信息,可以提高对用户的服务质量。
5 实验与分析
本章对用户地理位置类型进行预测和用户类型聚类,并分析两者之间的相关性得出实验结果。
5.1 用户地理位置类型预测
通过随机森林算法将用户根据网络层统计特征分成四种不同的地理位置类型,得到的每个用户类型预测概率和混淆矩阵如表4和表5所示。

表4 地理位置类型预测结果
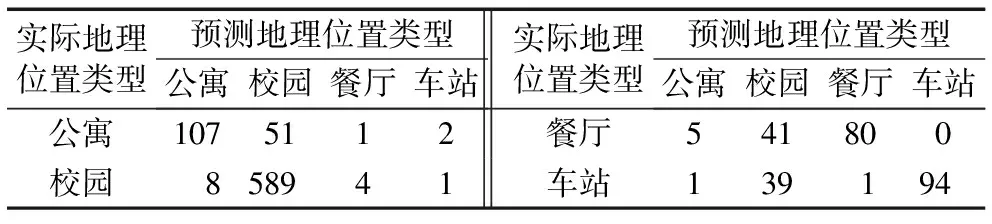
表5 地理位置类型预测混淆矩阵
表4中每列参数含义如下:
1)TPRate(True Positive Rate):真正率。是指在原始真样本中最后被正确预测为真样本的概率。其计算公式为:
TPRate=TP/(TP+FN)
(3)
其中:TP表示样本的真实类别为真时,最后预测得到的结果也为真;FN表示样本的真实类别为真时,最后预测得到的结果却为假。
2)FPRate(False Positive Rate): 假正率。是指在原始假样本中最后被预测为真样本的概率。其计算公式为:
FPRate=FP/(FP+TN)
(4)
其中:FP表示样本的真实类别为假时,最后预测得到的结果却为真;TN表示样本的真实类别为假时,最后预测得到的结果也为假。
3)Precision:预测正确率。是指在预测结果中,预测为真的样本中,预测结果为真的概率。其公式如下:
Precision=TP/(TP+FP)
(5)
4)ROC Area(Receiver Operating Characteristics Curve):ROC曲线描述的是每个测试类别样本中的真正率和假正率的变化。在ROC曲线中横轴表示假正率,纵轴表示真正率。曲线下的区域面积是对预测模型有效性的一个评估,取值范围为[0,1]。ROC区域的面积越大,预测模型的有效性越高。理想情况下,ROC区域的值为1。
表5中每行代表用户实际地理位置类型,每列代表用户预测的地理位置类型。最终能够在1 024个用户中正确预测到870个用户,预测率为85%。
5.2 用户类型划分
在对用户的网络流量进行统计、分析后,需要更详细地分析用户的兴趣爱好。通过对用户类型进行分析和研究,得出不同用户的偏好。
5.2.1 用户类型聚类
在对用户网络流量的分析基础上,通过多次实验,最后利用聚类速度较快的K-means将上述使用URL分类后的用户聚类成8个类型。
表6中列出了在每个类型中百分比为前10的URL类别。对于每一个用户类型,作了以下分析:
类型1 社交学习型用户(Social network and Education, SE)。这种类型的用户主要访问的是社交网络和教育,分别所占百分比约为36%和20%。说明这类用户的兴趣爱好相对比较集中,可能是利用社交网络交友和通过文件共享、技术学习等方式学习。
类型2 社交分享型用户(Social network and File-Sharing,SF)。该类型用户主要访问的是图像和社交网络,分别所占百分比约为52%和26%,其他类型访问量不多。这类用户可能通过图像软件拍摄大量照片,然后通过社交网络分享这些照片。年龄段可能集中于热爱自拍或者摄影的青年人群。
类型3 游戏交友型用户(Games and Social network,GS)。该类型用户特别爱好游戏这类,所占百分比约为46%,同时社交网络所占百分比约为27%,另外购物和快餐访问量也比较多。这类用户可能比较喜欢室内游戏,并可能通过快餐和购物来订购外卖和购物,同时通过金融类别中的相应软件来付款。
类型4 学习型用户(Education,Ed)。该类型用户主要访问教育类别,所占百分比约为52%。这类用户可能大部分时间通过访问教育性网站来获取信息,有可能是学生或者老师这类人群。
类型5 事业型用户(Job-Searching,JS)。这类用户非常关注科技技术方面的公司,技术所占百分比约为56%,同时在新闻和事业方面所占百分比约为12%,说明这类用户也对时事新闻和工作有所偏好。这类用户可能从事的行业可能为IT方面并正在找工作。另外,用户访问量第二大的是游戏类别,所占百分比约为6%,说明该类用户热衷游戏。
类型6 社交型用户(Social Network,SN)。这类用户爱好比较单一,偏向社交网络这一类。该类型用户可能在数据收集的这段时间或长时间中比较悠闲,用户上网的目的只是用来聊天交友,放松自己;或者这类用户偏爱社交网络,对其他类型的兴趣不大。
类型7 健康生活型用户(Health and Lifestyle,HL)。这类用户并不完全集中于某一类型的访问,在生活方式、旅游和社交网络等方面都有访问。在生活方式和快餐方面有所关注,说明用户比较关心日常生活需求;同时对旅游和健康方面也有所喜爱,说明这类用户有足够的经济基础来支持现有的生活,比较注重健康,甚至短期有出游的打算。该类型年龄层次可能为中老年人。
类型8 娱乐学习型用户(Entertainment and Education,EE)。娱乐在这类用户访问量中占55%左右,用户在教育和文件分享学习方面所占的百分比分别约为13%和6%。这类用户对于学习和娱乐两者兼顾,但是上网的内容比较侧重于娱乐放松。
5.2.2 用户类型规则制定
通过对表6中所有用户聚类类别的分析,在表7中,规定了每个用户类型中多个URL类别的具体范围。

表6 各用户类型中URL类别所占百分比 %
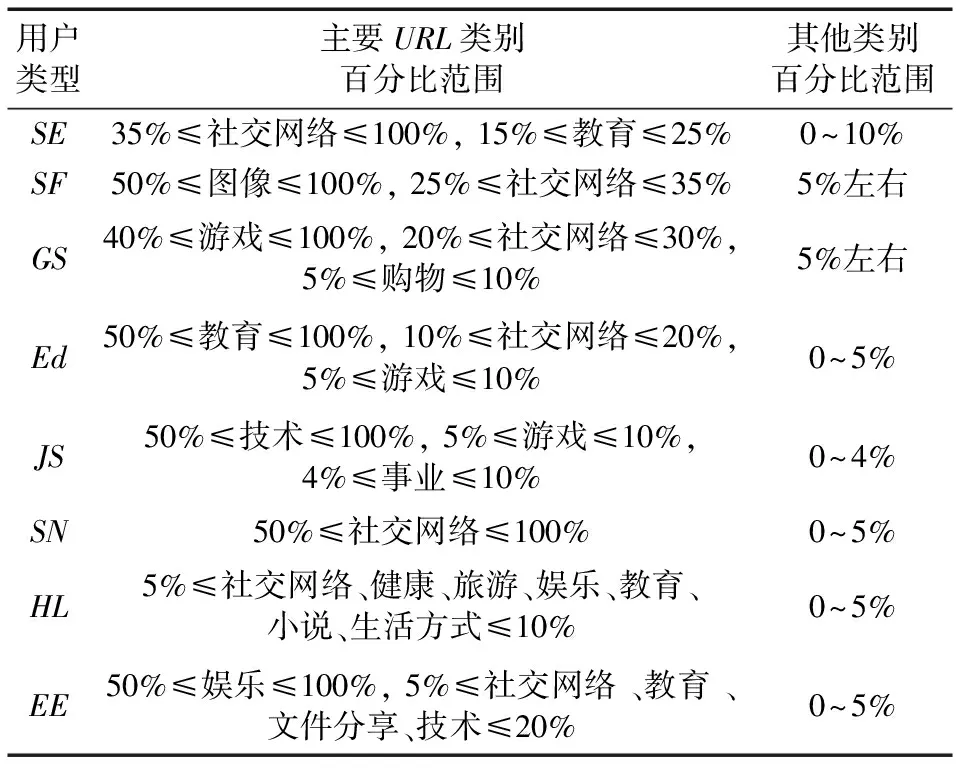
表7 用户类型中不同URL类别百分比范围制定
5.2.3 用户类型校正和确认
用户所在的类别并不是一成不变的。用户上网的内容可能与用户在某一时间段所处的环境、遇到的问题等有关;同时,用户的年龄、阅历、交际范围、工作性质都有可能对用户某一时间段或长期的上网的内容有关。基于这些原因,本文利用上述用户聚类的规则,将用户的URL访问类别根据时间段进行划分和统计,用户在每个时间段中所属的用户类型可能会有所不同,因此,将用户在总时间段中出现次数最多的用户类型作为该用户所属的类型,即对用户的长期兴趣进行预测,当用户的长期兴趣与用户的实际的偏好不同时,应该根据用户最近的短期偏好或者用户的地理位置预测类型向用户推送服务(此次实验选取的时间段为15 min。)
表8表明了利用K-means聚类算法所聚成的8个类别的百分比和在通过人工判别修改后每个类别所占的百分比。其中改变较大的是HL类型,该类型的用户数占总用户数目从3.8%增长到了11.9%;其次是Ed类型中用户数目百分比下降了7.7%;SE类型用户数却增长了5.6%;其余的类型变化不大,SN类型用户数目没有改变。
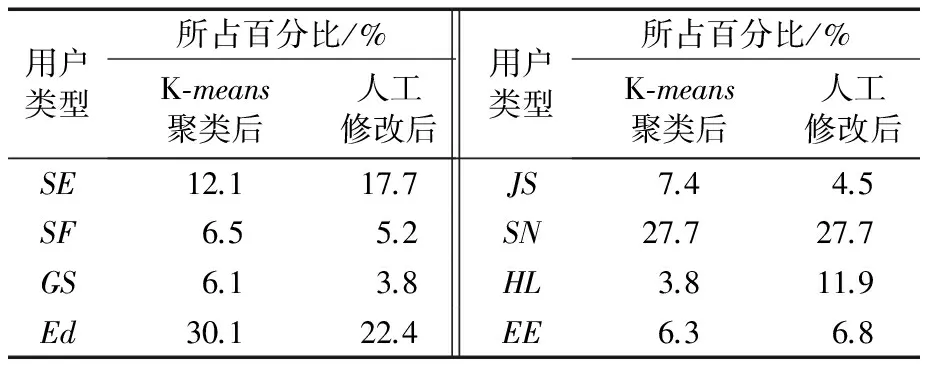
表8 用户聚类并人工修改后的用户类型百分比
5.3 地理位置类型与用户类型相关性
仅通过地理位置类型去判断用户偏好,会将用户都统归为四种基于地理位置类型的用户。比如,推测出用户位于车站,只对用户推送旅游、天气等与车站相关的服务,这并不能为用户提供高质量服务。同样,只对用户推送与公寓、校园和餐厅相关的服务无法满足用户的实际需求。
通过表9可以看到,在对用户分类后,用户的用户类型分布与用户所在的地理位置类型是有关系的。比如在校园中ED类型的用户占比率最大;因为校园中大部分用户可能是学生和老师群体,他们更倾向于利用无线终端设备来学习;同时发现SN、ED和SE用户类型在公寓、学校和餐厅中比重都在用户类型中的前三位,只是在顺序上有变化;主要原因是用户在利用无线网络上网的过程中更加倾向于娱乐休闲、聊天和学习这三个方面。而在车站中,HL型用户比重仅次于SN型用户占百分比;说明在车站中大部分偏爱社交软件,但有很多用户对于车站类型的相关服务(比如旅游软件、天气查询等)也很感兴趣。
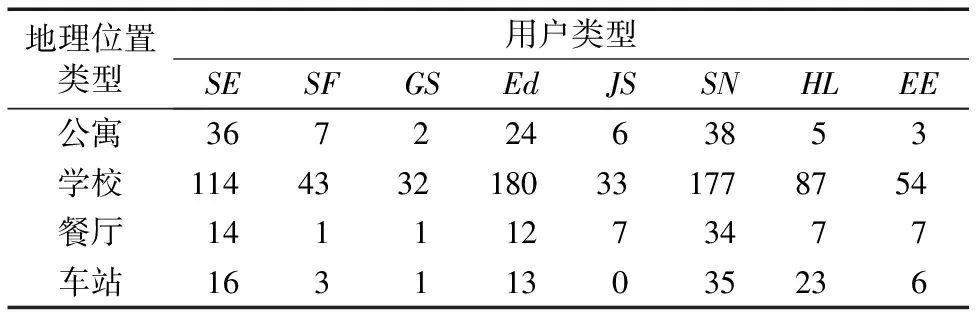
表9 地理位置分类预测结果中不同用户类型的人数
另外,在同一地理位置类型中的用户是属于不同类型的用户。比如,在公寓中,用户类型比重从大到小前三位的分别是SN、SE和ED,在学校中比重较大的三种用户类型依次是ED、SN和SE,在餐厅中比重较大的前三位用户类型依次是SN、ED和SE,在车站中用户类型数目前三位分别是SN、HL和ED。说明在同一位置类型中,用户的偏好与地理位置类型相关程度不一样,因此,仅根据地理位置类型来判断用户的偏好是不够的。
用户的偏好在同一地理位置类型中是存在差异性的,相同的用户类型在不同的地理位置类型中所占的比重也不一样。地理位置类型与用户类型的结合,为用户的偏好提供了更准确的判断。
6 结语
本文通过对用户的多层网络信息的提取,能够以85%的准确率预测出用户的地理位置类型,并对用户以兴趣爱好进行划分,在现实中能够将用户的地理位置和用户类型相结合,进而提供更准确的个性化服务。然而,今后还有很多工作要做。首先在用户设备指纹集方面,将继续挖掘其他可以确定用户的“指纹”识别信息;其次,将提高在地理位置类型中数量较少的用户类型对用户偏好的预测率;最后,本文中的用户大部分是在校园里,这也跟用户使用无线终端设备上网的方式有关,今后将考虑更多其他位置类型的用户。
References)
[1] AHMED M, MAHMOOD A N. Network traffic analysis based on collective anomaly detection [C]// Proceedings of the 2014 IEEE 9th Conference on Industrial Electronics and Applications. Piscataway, NJ: IEEE, 2014: 228-237.
[2] BEKERMAN D, SHAPIRA B, ROKACH L, et al. Unknown malware detection using network traffic classification [EB/OL]. [2016- 01- 12]. https://www.researchgate.net/publication/304605520_Unknown_malware_detection_using_network_traffic_classification.
[3] LAI Y, CHEN Y, LIU Z, et al. On monitoring and predicting mobile network traffic abnormality [J]. Simulation Modelling Practice and Theory, 2014, 50: 176-188.
[4] XIA N, MISKOVIC S, BALDI M, et al. GeoEcho: inferring user interests from geotag reports in network traffic [C]// Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies. Washington, DC: IEEE Computer Society, 2014, 2: 1-8.
[5] FUKUDA K, ASAI H, NAGAMI K. Tracking the evolution and diversity in network usage of smartphones [C]// Proceedings of the 2015 ACM Conference on Internet Measurement Conference. New York: ACM, 2015: 253-266.
[6] TANG H, LIAO S S, SUN S X. A prediction framework based on contextual data to support mobile personalized marketing [J]. Decision Support Systems, 2013, 56(4): 234-246.
[7] 蔡君,余顺争.基于复杂网络社团划分的网络流量分类[J].计算机科学,2011,38(3):80-82.(CAI J, YU S Z. Internet traffic classification based on detecting community structure in complex network [J]. Computer Science, 2011, 38(3): 80-82.)
[8] AL KHATER N, OVERILL R E. Network traffic classification techniques and challenges [C]// Proceedings of the 2015 10th International Conference on Digital Information Management. Piscataway, NJ: IEEE, 2015: 43-48.
[9] DAS A K, PATHAK P H, CHUAH C N, et al. Contextual localization through network traffic analysis [EB/OL]. [2016- 02- 04]. http://spirit.cs.ucdavis.edu/pubs/conf/infocom14.pdf.
[10] ZHANG F, HE W, LIU X, et al. Inferring users’ online activities through traffic analysis [C]// Proceedings of the 4th ACM Conference on Wireless Network Security. New York: ACM, 2011: 59-70.
[11] HE H, QIAO Y, GAO S, et al. Prediction of user mobility pattern on a network traffic analysis platform [C]// Proceedings of the 10th International Workshop on Mobility in the Evolving Internet Architecture. New York: ACM, 2015:39-44.
[12] ZAMAN M, SIDDIQUI T, AMIN M R, et al. Malware detection in Android by network traffic analysis [C]// Proceedings of the 2015 International Conference on Networking Systems and Security. Piscataway, NJ: IEEE, 2015: 1-5.
[13] ZHANG J, XIANG Y, WANG Y, et al. Network traffic classification using correlation information [J]. IEEE Transactions on Parallel and Distributed Systems, 2013, 24(1): 104-117.
[15] 刘建伟,刘媛,罗雄麟.半监督学习方法[J].计算机学报,2015,38(8):1592-1617.(LIU J W, LIU Y, LUO X L. Semi-supervised learning method [J]. Chinese Journal of Computers, 2015, 38(8): 1592-1617.)
[16] BAKHSHI T, GHITA B. User traffic profiling [C]// Proceedings of the 2015 Internet Technologies and Applications. Piscataway, NJ: IEEE, 2015: 91-97.
[17] ANGELOV P, KANGIN D, ZHOU X, et al. Symbol recognition with a new autonomously evolving classifier autoclass [C]// Proceedings of the 2014 IEEE Conference on Evolving and Adaptive Intelligent Systems. Piscataway, NJ: IEEE, 2014: 1-7.
[18] 徐鹏,林森.基于C4.5决策树的流量分类方法[J].软件学报,2009,20(10):2692-2704.(XU P, LIN S. Traffic classification method based on C4.5 decision tree [J]. Journal of Software, 2009, 20(10): 2692-2704.)
[19] WANG Y, XIANG Y, ZHANG J. Network traffic clustering using random forest proximities [C]// Proceedings of the 2013 IEEE International Conference on Communications. Piscataway, NJ: IEEE, 2013: 2058-2062.
[20] 屠金路,金瑜,王庭照.bootstrap法在合成分数信度区间估计中的应用[J].心理科学,2005,28(5):1199-1200.(TU J L, JIN Y, WANG T Z. The application of bootstrap method in the estimation of synthetic fractional reliability [J]. Psychological Science, 2005, 28(5): 1199-1200.)
[21] 汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):299-304.(WANG Z, LIU G Q, CHEN E H.K-means algorithm for optimizing initial center point [J]. Pattern Recognition and Artificial Intelligence, 2009, 22(2): 299-304.)
This work is supported by the National Natural Science Foundation of China (61202353, 61272084).
MU Tao, born in 1992, M. S. candidate. Her research interests include wireless network security, user privacy protection .
CHEN Wei, born in 1979. Ph. D., professor. His research interests include wireless sensor network, network security.
CHEN Songjian, born in 1992. M. S. candidate. His research interests include wireless network security, user privacy protection.
User classification method based on multiple-layer network traffic analysis
MU Tao, CHEN Wei*, CHEN Songjian
(SchoolofComputerScience&Technology,NanjingUniversityofPostsandTelecommunications,NanjingJiangsu210023,China)
Accurate classification of users plays an important role in improving the quality of customized services, but for privacy considerations users, often do not meet the network service providers, refusing to provide personal information, such as location information, hobbies and so on. To solve this problem, by analyzing the multi-layer network traffic such as network layer and application layer under the premise of protecting user privacy, and then using machine learning methods such asK-means clustering and random forest algorithm to predict the user’s geographic location types (such as apartments, campuses, etc.) and hobbies, and the relationship between geographic location types and the user interests was analyzed to improve the accuracy of user classification. The experimental results show that the proposed scheme can adaptively partition the user types and geographic location types, and improve the accuracy of user behavior analysis by correlating the user’s geographic location type and the user type.
traffic classification; geographic localization; user preference;K-means clustering; random forest
2016- 08- 01;
2016- 10- 19。
国家自然科学基金资助项目(61202353, 61272084)。
穆桃(1992—),女,湖南临湘人,硕士研究生,主要研究方向:无线网络安全、用户隐私保护; 陈伟(1979—),男,江苏淮安人,教授,博士,CCF会员,主要研究方向:无线传感器、网络安全; 陈松健(1993—),男,江苏苏州人,硕士研究生,主要研究方向:无线网络安全、用户隐私保护。
1001- 9081(2017)03- 0705- 06
10.11772/j.issn.1001- 9081.2017.03.705
TP393.08
A
