深层次分类中候选类别搜索算法
2017-05-24张忠林刘述昌江粉桃
张忠林,刘述昌,江粉桃
(兰州交通大学 电子与信息工程学院,兰州 730070) (*通信作者电子邮箱l15117014316@163.com)
深层次分类中候选类别搜索算法
张忠林,刘述昌*,江粉桃
(兰州交通大学 电子与信息工程学院,兰州 730070) (*通信作者电子邮箱l15117014316@163.com)
针对深层次分类中分类准确率低、处理速度慢等问题,提出一种待分类文本的候选类别搜索算法。首先,引入搜索、分类两阶段的处理思想,结合类别层次树的结构特点和类别间的相关联系等隐含的领域知识,进行了类别层次权重分析和特征项的动态更新,为类树层次结构的各个节点构建更具分类判断力的特征项集合;进而,采用深度优先搜索算法并结合设定阈值的剪枝策略缩小搜索范围,搜索得到待分类文本的最优候选类别;最后,在候选类别的基础上应用经典的K最近邻(KNN)分类算法和支持向量机(SVM)分类算法进行分类测试和对比分析。实验结果显示,所提算法的总体分类性能优于传统的分类算法,而且使平均F1值较基于贪心策略的启发式搜索算法提高了6%左右。该算法显著提高了深层次文本分类的分类准确度。
深层文本分类;类别层次;类别层次树;深度优先搜索;候选类别
0 引言
随着信息技术和社交媒体的快速发展,世界已进入网络化的大数据(Big Data, BD)时代[1]。据著名国际数据公司(International Data Corporation, IDC)的统计,2011年全球存储的数据总量达到1.8 ZB(10的21次方), 传感网和物联网的蓬勃发展以及实时采集的巨量流媒体数据又推动了大数据的进一步发展。面对指数级增长的大规模数据,人们渴望更加有效的工具对所拥有的数据信息进行快速准确分类,提取出实时、精炼、对商业分析有价值的知识,并且做到对网络和信息的安全管理与控制。
为了更加有效地组织和管理大规模的文本信息,一般是按照主题类别或一个概念将这些文本信息构建成类树层次目录,以便更好地存储、管理和检索、查询这些文本资源信息得到最新的重要资讯。目前国内关于大规模多层次文本分类的研究还处于初级阶段,文献[2]对大规模多层次文本分类问题的定义、求解方法进行了系统详细的论述及评价比较,并且结合实际应用需求和问题研究现状概括了大规模多层次文本分类未来的研究方向;文献[3]利用类别层次体系中隐含的语义信息,提出了几种基于类别层次结构的大规模多层次文本分类样本扩展策略,从而扩展较少类别的训练样本,取得了第二名的参赛成绩(2014年大规模中文新闻分类评测);文献[4]将监督学习与无监督学习相结合,提出了一种基于分层聚类和重采样技术的支持向量机(Support Vector Machine,SVM)算法,来解决大规模数据的分类问题,其分类性能比随机采样更优。国外学者对大规模多层次的分类研究相对较早,例如,Sun等[5]提出了基于类别相似性和类别间相关距离来判别待分类文本类别属性的方法,此方法还支持部分深层类别分类和全深层类别分类;Liu等[6]用数学分析的方法验证了层次式SVM分类方法在大规模多层次分类中的学习时间是可以接受的,优于平面式的分类方法。本文在已有研究进展的基础上,对大规模多层次文本分类中的深层类别属性判定问题进行了更深入具体的研究,结合主流的两阶段分类思想,根据类别层次树的特点和类别间的相关联系,引入类别层次权重分析和特征项的动态更新策略,为类树层次结构的各个节点构建更具分类判断力的特征项集合,搜索得到待分类文本的最优候选类别,在此基础上采用K最近邻(KNearest Neighbor,KNN)分类算法进行分类准确率的测试,并与已有算法比较评价。
本文的主要工作有以下几点:
1) 结合大规模多层次分类的类别层次结构特点,使用类别层次信息和隐含的语义信息,分析各层次类别的相关联系,给出类别层次权重的计算方法;引入概率论知识求得特征项的类别区分度,实现深层类别分类中特征项权重的动态更新。
2) 在更新后的特征集基础上,采用深度优先搜索算法搜索待分类文本的候选类别集合,结合本文的阈值定义,在设置合适阈值的情况下找到待分类文本的最优候选类别集合。
3) 对本文提出的算法进行测试并与已有候选搜索算法比较,结果数据表明,本文提出的算法使分类结果的F1值提高了约6%,证明该算法的搜索过程是有效的,且显著提高了深层次文本分类的分类准确度。
1 相关工作
深层分类是对给定的待分类文本,首先应用搜索算法寻找其最优候选类别集合;然后在候选类别集合上构建更加精准的分类器来判定待分类文本的类别属性。
在大规模多层次分类中,类别层次有较深的深度,而深层类别的分类就是类别层次相关中的精确分类,而且随着层次深度的增加,具有兄弟关系的类别间的相似度增强,判别待分类文本的类别属性就更加地困难。对此文献[7]提出化繁为简的分类策略,该策略包括搜索和分类两个阶段,首先搜索待分类文本的候选类别集合,然后建立平面分类器对文本进行最终类别属性的判定,而且在分类阶段可以使用平面分类算法训练分类模型,获得了很好的分类效果;然而文献[8]并未结合类别层次结构及深层分类的类别特点对候选搜索方法进行深入研究;而文献[9]虽然对候选搜索问题的计算复杂性进行了分析,证明了该问题是非确定多项式(Non-Deterministic Polynomial, NP)难解的,但是其对候选类别集合的搜索是在平面分类的基础上更新特征权重矩阵G获得局部最优选择,也未结合类别层次相关性及类别层次权重来动态更新类别特征项的权值。
候选搜索方法分为基于实例的候选搜索和基于类别的候选搜索方法两种。由于基于实例的候选搜索方法需要与所有样本进行比较,时间复杂度比较高, 因此在现有的相关研究中很少采用这种搜索策略;而基于类别的候选搜索方法思考如何根据类别的层次位置为每个内部类别和叶子类别分别构造准确的特征权重集合,也就是形成具有类别层次结构的层级分类器,这也是本文重点讨论的内容,在下一章将会详细的描述。阅读相关文献,本领域学者对特征权重集合的计算作出如下贡献:文献[10]使用词频(TermFrequency,TF)、文档频率(DocumentFrequency,DF)及逆类别频率(InverseClassFrequency,ICF)给不同层次的类别选择不同的特征集合训练分类模型;文献[11]以类别包含所有的文本词频之和作为特征词权重,为类别分别构造类特征向量,进而计算待分类文本与类特征向量间的余弦相似度。本文是基于类别候选搜索方法进行以下的问题分析和验证的。
2 类别层次权重分析和特征项的动态更新
2.1 类别层次权重的计算
大规模多层次分类中,类别被组织成类别层次树结构[12],即所有类别根据相关性被组织成树型结构,每个类别有一个父类别(根节点除外),树的中间节点存储自身的样本数据,待分类文本可以被分到叶子类别,也可以被分到内部类别中。根据树的结构特点,类别节点间的关系可归纳为四种:父子关系、非父上下层级关系、非同父同层关系和同父兄弟关系(简称并列关系),在多层次分类中,并列关系上的准确分类才是分类的关键点,决定下一步分类的走向和是否有“错误传播”问题的发生。对于深层类别的分类问题,随着层次深度的不断增加,具有并列关系类别间的相似性会增强,因此讨论类别层次的相关性、类别层次权重就显得非常有必要了。
设类别集合C={c1,c2,…,cn},关于类别层次相关性的系列概念参照文献[13]中的描述,这里不再赘述。在此对类别层次权重的计算进行详细的说明,在大规模多层次分类中对内部节点ci建立分类器时,其训练样本包括类别ci自身的训练样本和类别ci直接子类含有的所有训练样本,如图1所示,类别ci的直接子类是Dsub(ci)={ci1,ci2,…,cik},其自身包含的样本集合为Di,把类别ci自身存储的训练样本加入到其直接子类中并更新,即DSub(ci)={ci0,ci1,…,cik},其中ci0为类别ci的概念节点,则类别层次权重的计算方法如下:

图1 类树层次结构
对类树T的任意一个类别cj:weight(cj)=
(1)
其中:weight(cj)指类别cj的类别层次权重,correlation(ci,cj)[13]53-56指类别ci与cj间的相关性。
通过式(1)进行递归计算可以得到类树中每个类别的权重weight(cj)(1≤j≤n)。
2.2 特征项的动态更新
在大规模多层次分类的类别层次结构中,不同层次的类别具有不同的重要性,而且类别层次结构中内部节点所代表的类别本身也存储一定数量的训练样本,并且在训练过程中,类别ci直接子类所包含的训练样本比其非直接子类所拥有的训练样本更适合于该类的类别判断,因此结合类别的层次权重,要对类别所包含训练样本对特征项区分能力贡献的大小进行区别对待。
设特征项fs,类别ci的训练样本包括ci自身存储的训练样本和其直接子类所包含的训练样本,即有:
(2)
而且对于任何属于DSub(ci)={ci0,ci1,…,cik}中的类别,其所包含的训练样本是不重叠的,但都有可能包含特征项fs。∀cs,ct∈DSub(ci)时,即有:
trains(cs)∩trains(ct)=∅;cs≠ct
(3)
由全概率公式[14]得:
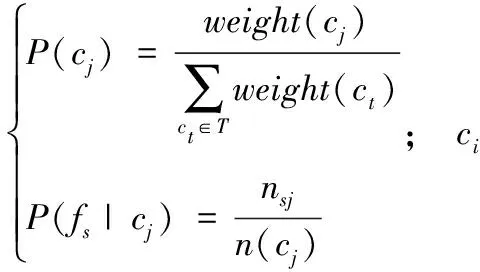
(4)
其中:P(fs|ci)表示特征项fs在DSub(ci)={ci0,ci1,…,cik}类别集合包含所有训练样本中出现的概率,P(fs|cj)表示特征项fs在类别cj自身存储的训练样本中出现的概率。
(5)
其中:nsi表示特征项fs在类别ci自身存储的训练样本中出现的概率,n(ci)表示类别ci自身包含的所有特征项个数。
由式(4)、(5)进行递归计算,就可以获得任意特征项fs在类别ci以及其直接子类cj(cj∈Dsub(ci))中出现的条件概率值P(fs|cj)。
特征项的类别区分能力如下。
引入概率论的知识,用后验概率P(ci|fs)表示特征项fs对任意类别ci的区分度大小,结合全概率式(4),根据贝叶斯定理得:
(6)
其中:P(fs)与P(fs|ci)相等,ni表示类别ci中所有训练样本含有特征项的个数,n表示类别集合C中所有训练样本含有特征项的个数。
在分类过程中,当待分类文本经过类别ci到其直接子类时,结合式(6)则特征项fs对其各个直接子类的区分能力可表示为:
1≤i≤n, 1≤j≤k
(7)
由上述理论可求得特征项fs对类别ci的各个直接子类的区分度deci(cij|fs),并对其按降序进行排序,选择前t个特征项组成样本的特征词集合F={fi1,fi2,…,fit}。而且在大规模多层次文本分类的深层类别分类中,随着类别层次深度的不断增加,具有并列关系类别间的相似性会逐级增强,层次深度越深对文本的准确分类就越困难,而且并列关系上的准确分类才是深层分类的关键点,因此可以根据式(7)的结果在水平方向上动态的更新特征项,例如,适当地降低上层所包含概括性特征项的deci(cij|fs)值,甚至可以删除;也可以适当地提高下层所需具体特征项的deci(cij|fs)值,这样就能突显出具有并列关系类别本身的类别特点,更有利于深层次类别的判定。
3 深层次分类中候选类别搜索算法
3.1 候选类别搜索中阈值的确定
本节内容结合更新后的特征词集合,引入深度优先搜索(DepthFirstSearch,DFS)算法[15]并结合设定阈值的剪枝策略缩小搜索范围,以求解待分类文本的最优候选类别集合。在深度优先搜索过程中,采用经典的K最近邻(KNN)分类算法[16]进行层次文本分类,并结合类别层次结构进行以下讨论。
在内部类别节点ci上用类别集合DSub(ci)={ci0,ci1,…,cik}中包含的所有训练样本训练KNN分类器hi,本文试将此训练样本集合分成三个子集来确定待分类文本从类别ci到其直接子类cij的阈值Tci(cij)(1≤i≤n,1≤j≤k),子集定义如下:
1)S1={dk|dk∈trains(ci)};
2)S2={dk|dk∈trains(DSub(cij))};
3)S3={dk|dk∈trains(DSub(sbe(cij)))};
其中:DSub(cij)表示类别cij本身及其直接子类别集合,sbe(cij)表示除类别cij外的类别ci的其余直接子类。
下面对阈值Tci(cij)的确定过程进行详细的说明,采用经典KNN分类算法的思想,在类别ci上建立分类器hi,在对待分类文本分类时,由分类器hi返回的K个最近邻中属于类别cij的样本数目记为num(d,ci,cij),并有如下定义:
(8)
1) 使用子集S1中的样本训练分类器hi,当待分类文本到达类别ci时,统计其K个最近邻中属于子类别cik的样本数目num(d,ci,cik),只要使阈值Tci(cij)大于属于各个子类别cik的样本数目的最大值TS1,这样对属于类别ci的文本就不会继续向下层分类而只属于ci。
2) 使用子集S2中的样本训练分类器hi,当待分类文本到达类别ci时就会被分到以类别cij为根的子树中去,此时设定阈值Tci(cij)小于num(d,ci,cij)的最小值TS2,这样对属于类别ci及其子树类别的文本就会在以ci为根的分支上继续向下分类。
3) 使用子集S3中的样本训练分类器hi,当待分类文本经过分类器hi后,将会分到类别cij的并列关系类别cik(cik∈sbe(cij))中去,此时设定阈值Tci(cij)大于TS3,这样能使属于类别cij的文本在经过分类器hi后不能被分到其他兄弟类别中去。经过以上过程,取Tci(cij)≥max(TS1,TS3)∩Tci(cij)≤TS2(Tci(cij)∈Z+)的值作为确定的待分类文本从类别ci到其直接子类cij的阈值,就可以为类树T中的每个类别节点求得合适的阈值。
3.2 候选类别搜索算法描述
经过3.1节的讨论就可以为类别层次结构中的每个内部类别节点求得其对各直接子类的阈值。但是当待分类文本经过类别ci到达其直接子类时,可能有多个子类cik满足阈值条件,因此必须对这些子类cik进行分别处理,采用深度优先搜索算法将满足条件的子类分支逐个遍历,就得到了所需的待分类文本的候选类别集合。算法步骤如下:
算法:候选类别搜索算法(CandidateCategorySearchAlgorithm,CCSA)。
输入:类树T,待分类文本d,参数k。
输出:候选类别集合(Candidate Category Set(d),CCS(d))。
Algorithm CCSA(T,d,k){ 初始化T,为T中每个类别计算特征词集合F如果ci是叶子节点且num(d,ci)>Tci(cij)ci加入CCS(d); 否则调用方法DFS(ci,d,k) }
AlgorithmDFS(ci,d,k){ 计算阈值Tci(cij) 如果ci是叶子节点且num(d,ci)>Tci(cij)ci加入CCS(d); 否则{ 计算num(d,ci,cik) 如果num(d,ci,cik)>Tci(cij)cik加入候选序列L(d); 对L(d)中的每个类别ct,调用方法DFS(ct,d,k) }
}
4 实验
选用CWT70th数据集中具有足够训练样本的类别组成类别集合,并构建成二层的类树层次结构,利用Java的开源软件包HTMLParser对解压的网页文件预处理,采用中国科学院最新发布的分词系统包及二次开发Java调用接口对文本数据分词处理,还用到Weka数据挖掘工具的部分功能。实验过程如下。
4.1 特征项的有效性验证
随机抽取9个类别训练样本的2 800篇文档组成类树层次结构且中间节点也存储样本,这符合上文所描述的类树层次结构的特点,用词频逆文档频率(Term-InverseDocumentFrequency,TF-IDF)[17]方法计算特征词的权重,并根据第2章的内容对特征词集合进行删选、动态更新后得到类别ci的特征项集合为Wci={w1,w2,…,wt},为了评价特征项集合对类别的覆盖范围及避免分类时出现偏向的问题,实验中用了如下公式对所选特征项间的相似度进行了衡量。
(9)
在类树结构的第一层分别用第2章描述的特征选取方法、信息增益(InformationGain,IG)和χ2(Chi-square,CHI)统计选取不同数量的特征词并比较特征词间的相似度;在第二层中选择社会科学类构建特征词集合,也分别计算三种方法所得特征词之间的相似度。结果数据如表1所示。
分析表中数据可得,第一层选取的特征词集合中,本文方法与IG方法的相似度比较各有优劣,特征词数目为200、400时,IG方法优于本文方法;当特征词数目逐渐增多时,本文方法优于IG方法,而CHI方法的效果明显不理想。第二层选取的特征词集合中,本文方法优于IG和CHI方法,分析原因,这主要是本文建立的类树层次结构中,中间节点存储有自身的训练样本,在特征词的选择过程中既考虑了类别的层次位置和权重也进行了特征词的动态更新,选取了更有利于深层分类的特征词集合,这也进一步说明了在大规模多层次文本分类中,面对大规模文本数据和高维特征词集合时,本文方法选择的特征词能够较好地覆盖在所在层次的各个类别上,具有解决深层分类问题的优势,为下一步搜索准确的候选类别做好了充分的准备和基础。
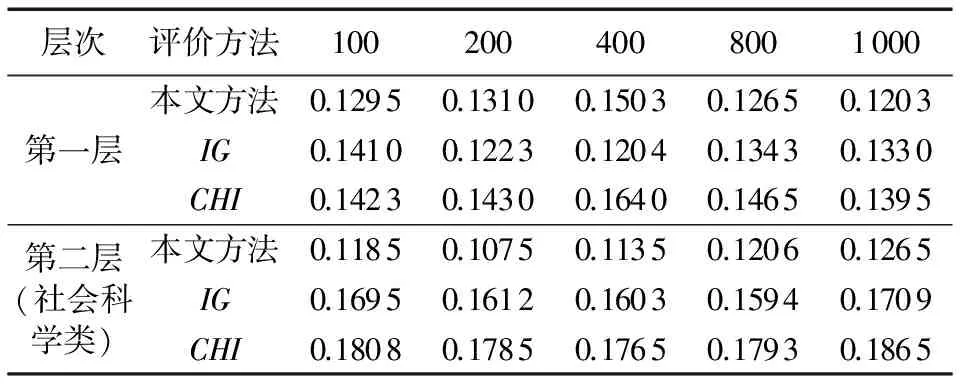
表1 类树结构中第一、二层所选不同数目特征词间的相似度比较
4.2 候选类别搜索算法及分类准确率验证
为了验证第3章提出的候选类别搜索算法的有效性,采用开放式分类目录(OpenDirectoryProject,ODP)[18]的中文数据和20Newsgroups语料库[19]进行实验。基于ODP本身的分类目录结构,本文选择单标签且只有一个父类的文本数据组成深度为5的类树层次结构,其中包括7个大类别组成了类树层次结构的第一层,有商业(5 623)、参考(2 220)、计算机(1 643)、社会(1 554)、艺术(1 031)、科学(923)、健康(747),共选取9 576篇中文样本构成类树层次结构;并且选取20Newsgroups语料库的8 000篇样本数据组成深度为3的类树层次结构,0~2层分别有:288篇、6 756篇和956篇样本,详细情况如表2和表3所示。
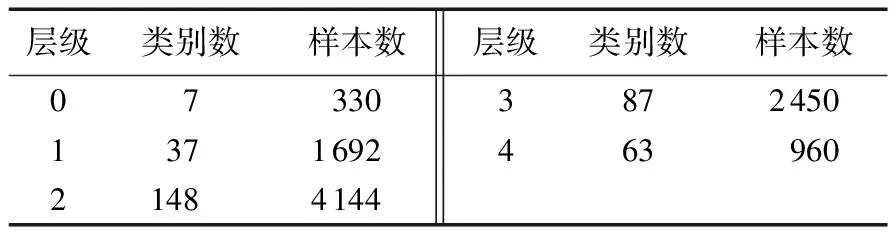
表2 ODP类树层次结构样本分布
将实验数据集分成5份进行交叉验证,并与经典的KNN分类算法和SVM算法进行比较,为了评估整体的分类效果,采用宏平均准确率和召回率评价分类结果。通过多次实验,取K=45、特征词数量为500时分类效果最好。实验数据如表4所示。
由表4的实验数据可得,本文所提出的分类算法要比传统KNN算法和SVM算法的分类效果好很多,根据公式:F1=2*准确率*召回率/(准确率+召回率),数据集ODP取得5次数据的平均F1值分别为0.90、0.84和0.84;数据集20 Newsgroups取得5次数据的平均F1值分别为0.87、0.83和0.81,得到本文算法的总体性能比经典算法的好。
为了讨论在最好实验条件下,加入类别层次信息和特征项动态更新后的候选类别搜索算法的改进效果,在以下实验中,改进的搜索算法和文献[10]45-48中提出的基于贪心策略的启发式搜索算法(Heuristic Learning, HL)进行了比较,为了保证比较的准确性,选择在ODP数据集上进行对比实验,并取HL算法评价标准Vk的最大值,多次实验结果表明在Vk=0.89~0.91时,HL算法的平均F1值达到0.85,本文算法较之提高了大约6%((0.90-0.85)/0.85),结果进一步说明了加入了类别层次信息和特征项动态更新后的候选类别搜索改进算法具有一定的实际应用意义。但是在分类模型的建立和候选类别的搜索阶段,本文算法花费的时间比文献[10]中的HL算法的实验时间多花费约986ms,而且每次都有一定的波动,分析深层原因,在类树层次结构的建立过程中要为每个类别分别构建特征项集合并且当待分类文本到达时,根据其搜索路径要计算路径分支类别各自的阈值,这需要花费大量的时间,影响了算法的总体分类性能。
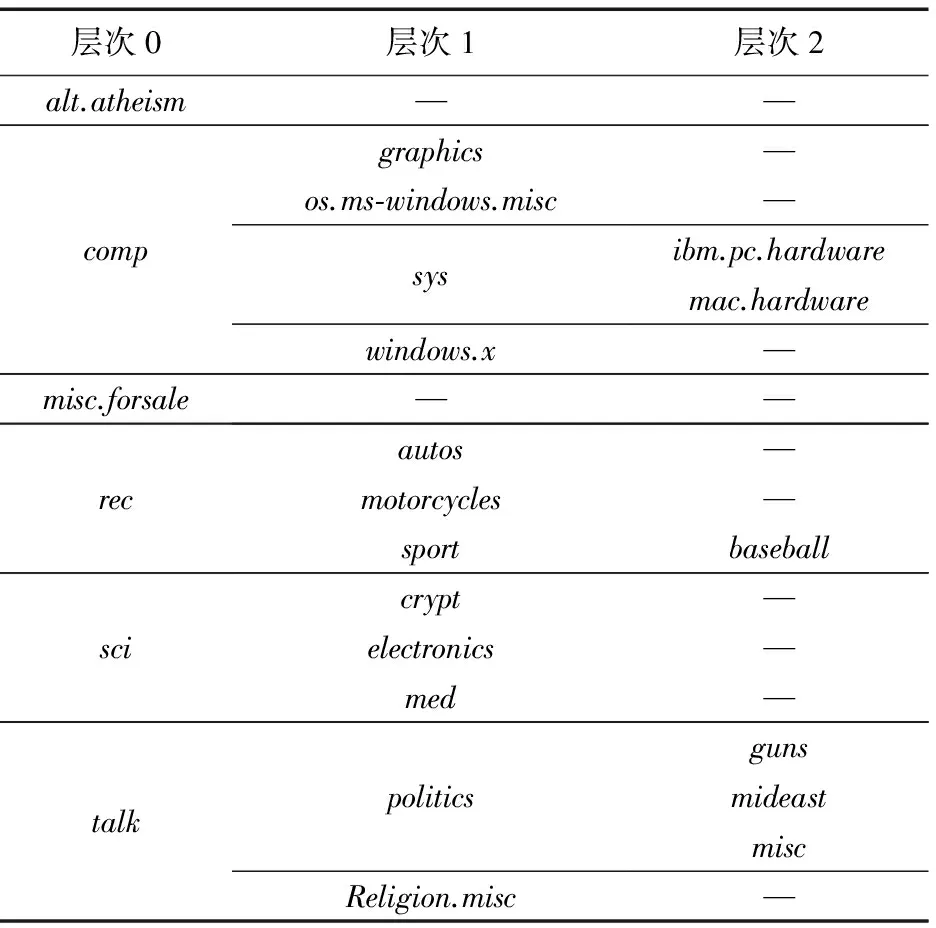
表3 20 Newsgroups类树层次结构样本分布
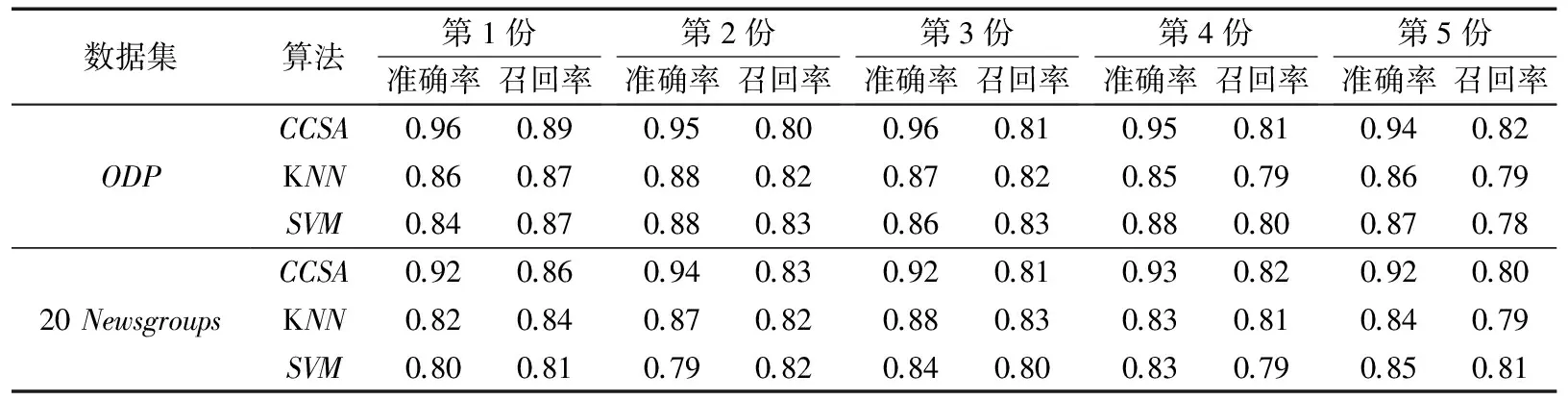
表4 三种分类算法的分类效果比较
5 结语
针对大规模多层次文本分类中的深层类别分类问题,本文结合类树层次结构分析了类别层次相关性及权重计算,在此基础上引入深度优先搜索算法找到待分类文本的最优候选类别集合,最终确定待分类文本的类别属性,相比已有搜索算法使其F1值提高了6%左右;但是本文在实验数据集上有意识地选取训练样本比较充分的大类别,忽略了较少样本的类别和稀有类别,使算法的适用范围有了局限性。对此,在下一步的学习中考虑结合类别层次结构中蕴含的类别名称、描述信息以及类别间的层次结构关系来扩展稀有类别的训练样本,帮助稀有类别的特征学习,提高稀有文本的分类准确率;还有对于大规模的多层次文本分类研究,系统运行时间较长,对计算环境的要求比较高,因此,在后续尝试搭建分布式计算环境,应用当前流行的分布式计算技术进一步提高深层类别分类的准确率和运行效率。
References)
[1] 严霄凤,张德馨.大数据研究[J].计算机技术与发展,2013,23(4):168-172.(YAN X F, ZHANG D X. Big data research [J]. Computer Technology and Development, 2013, 23(4): 168-172.)
[2] 何力,贾焰,韩伟红,等.大规模层次分类问题研究及其进展[J].计算机学报, 2012,35(10):2101-2115.(HE L, JIA Y, HAN W H, et al. Research and development of large scale hierarchical classification problem [J]. Chinese Journal of Computers, 2012, 35(10): 2101-2115.)
[3] 李保利.基于类别层次结构的多层文本分类样本扩展策略[J].北京大学学报(自然科学版),2015,51(2):357-366.(LI B L. Expanding training dataset with class hierarchy in hierarchical text categorization [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2015, 51(2): 357-366.)
[4] 张永,浮盼盼,张玉婷.基于分层聚类及重采样的大规模数据分类[J].计算机应用,2013,33(10):2801-2803.(ZHANG Y, FU P P, ZHANG Y T. Large-scale data classification based on hierarchical clustering and resembling [J]. Journal of Computer Applications, 2013, 33(10): 2801-2803.)
[5] SUN A, LIM E P. Hierarchical text classification and evaluation [C]// Proceedings of the 2001 IEEE International Conference on Data Mining. Washington, DC: IEEE Computer Society, 2001: 521-528.
[6] LIU T-Y, YANG Y M, WAN H, et al. Support vector machines classification with a very large-scale taxonomy [J]. ACM SIGKDD Explorations Newsletter, 2005, 7(1): 36-43.
[7] XUE G-R, XING D, YANG Q, et al. Deep classification in large-scale text hierarchies [C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2008: 619-626.
[8] MALIK H. Improving hierarchical SVM by hierarchy flattening and lazy classification [C]// Proceedings of the Large-Scale Hierarchical Classification Workshop in 32nd European Conference on Information Retrial. Milton Keynes, UK: 〖s.n.〗, 2010: 1-12.
[9] 何力,丁兆云,贾焰,等.大规模层次分类中的候选类别搜索[J].计算机学报,2014,37(1):41-49.(HE L, DING Z Y, JIA Y, et al. Category candidate search in large scale hierarchical classification [J]. Chinese Journal of Computers, 2014, 37(1): 41-49.).
[10] CECI M, MALERBA D. Classifying Web documents in a hierarchy of categories: a comprehensive study[J]. Journal of Intelligent Information System, 2007, 28(1): 37-78.
[11] OH H S, CHOI Y J, MYAENG S H. Combining global and local information for enhanced deep classification [C]// Proceeding of the 2010 ACM Symposium on Applied Computing. New York: ACM, 2010: 1760-1768.
[12] WANG K, ZHOU S, HE Y. Hierarchical classification of real life documents [C]// Proceeding of the 1st SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2001: 33-46.
[13] 祝翠玲.基于类别结构的文本层次分类方法研究[D].济南:山东大学,2011:52-56.(ZHU C L. Research of hierarchical text classification methods based on category structure [D]. Jinan: Shandong University, 2011: 52-56.)
[14] 盛骤,谢式千,潘承毅.概率论与数理统计[M].北京:高等教育出版社,2015:11-65.(SHENG Z, XIE S Q, PAN C Y. Probability and Mathematical Statistics [M]. Beijing: Higher Education Press, 2015: 11-65.)
[15] 许少华.算法设计与分析[M].哈尔滨:哈尔滨工业大学出版社,2011:21-78. (XU S H. Algorithm Design and Analysis [M]. Harbin: Harbin Institute of Technology Press, 2011: 21-78.)
[16] CHAKRABARTI S, JOSHI M, TAWDE V. Enhanced topic distillation using text, markup tags, and hyperlinks [C]// Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2001: 208-216.
[17] ZHU S, LIU Y, LIU M, et al. Research on feature extraction from Chinese text for opinion mining [C]// Proceedings of the 2009 International Conference on Asian Languages Processing. Washington, DC: IEEE Computer Society, 2009: 7-10.
[18] The directory of the Web. The simplified chinese data set of open directory project [EB/OL]. [2016- 05- 01]. http://www.dmoz.org/World/Chinese_Simplified/.
[19] Ken Lang. The data set of 20Newsgroups [EB/OL]. [2016- 09- 07]. http://people.csail.mit.edu/jrennie/20Newsgroups/.
This work is partially supported by the National Natural Science Foundation of China (61662043).
ZHANG Zhonglin, born in 1965, Ph. D., professor. His research interests include intelligent information processing, software engineering.
LIU Shuchang, born in 1989, M. S. candidate. His research interests include data mining.
JIANG Fentao, born in 1991, M. S. candidate. Her research interests include Web data mining.
Candidate category search algorithm in deep level classification
ZHANG Zhonglin, LIU Shuchang*, JIANG Fentao
(SchoolofElectronicandInformationEngineering,LanzhouJiaotongUniversity,LanzhouGansu730070,China)
Aiming at the problem of low classification accuracy and slow processing speed in deep classification, a candidate category searching algorithm for text classification was proposed. Firstly, the search, classification of two-stage processing ideas were introduced, and the weighting of the category hierarchy was analyzed and feature was updated dynamically by combining with the structure characteristics of the category hierarchy tree and the related link between categories as well as other implicit domain knowledge. Meanwhile feature set with more classification judgment was built for each node of the category hierarchy tree. In addition, depth first search algorithm was used to reduce the search range and the pruning strategy with setting threshold was applied to search the best candidate category for classified text. Finally, the classicalKNearest Neighbor (KNN) classification algorithm and Support Vector Machine (SVM) classification algorithm were applied to classification test and contrast analysis on the basis of candidate classes. The experimental results show that the overall classification performance of the proposed algorithm is superior to the traditional classification algorithm, and the averageF1value is about 6% higher than the heuristic search algorithm based on greedy strategy. The algorithm improves the classification accuracy of deep text classification significantly.
deep text classification; class hierarchy; tree-structured class hierarchy; depth first search; candidate category
2016- 09- 18;
2016- 10- 18。
国家自然科学基金资助项目(61662043)。
张忠林(1965—),男,河北衡水人,教授,博士,CCF会员,主要研究方向:智能信息处理、软件工程; 刘述昌(1989—),男,甘肃金昌人,硕士研究生,主要研究方向:数据挖掘; 江粉桃(1991—),女,甘肃定西人,硕士研究生,主要研究方向:Web数据挖掘。
1001- 9081(2017)03- 0635- 05
10.11772/j.issn.1001- 9081.2017.03.635
TP
A
