面向流数据的分布式时序同步系统的设计与实现
2017-04-14黄伟健胡怀湘
黄伟健,胡怀湘
面向流数据的分布式时序同步系统的设计与实现
黄伟健,胡怀湘
(华北计算技术研究所,北京 100083)
针对目前分布式流数据管理方案的不足,本文从实际的业务需求出发,结合雷达流数据的单消息体规模大、消息流压力大以及流量波动明显的特征,采用主从式的分布式结构,利用Akka异步通信框架,设计并实现了一个面向流数据的分布式时序同步系统。该系统可扩展性强,容错性好,同时也是后续的分布式流数据实时计算系统和实时存储系统能够正常运行的重要前提。本文首先分析了系统使用的关键技术,然后结合实际背景设计了系统的整体框架,接着从消息类型、数据结构和主从节点的处理流程三个方面详细剖析了系统的实现细节,最后通过实验进一步验证了系统设计的可行性。
流数据管理;Akka;时序同步;分布式系统
0 引言
近年来,在通信领域、交通领域、金融领域、工业监控领域等领域,出现了一种新的数据类型,这类数据来自传感器采集信息、交通监控数据、实时交通信息等,通常被称为流数据(streaming data)[1],它们是一组顺序、大量、快速、连续到达的数据序列,一般情况下,可被视为一个随时间延续而无限增长的动态数据集合。不同类型的流数据也具有不同的特征。雷达流数据除了具有持续不断到达、潜在规模无限等一般性的流数据的特征之外,还具有如下特征:(1)数据流有明显的波峰波谷阶段,而且各个阶段的界限较为清晰;(2)单个消息体的大小一般为10MB左右,每一批次的数据流包含的消息体个数相对固定;(3)数据流分成多路,数据到达各个数据接入服务器的时间相差不大。在雷达流数据的实际处理场景中,流数据经过产生、预处理、时序同步、缓存、实时计算等过程。其中,时序同步的环节是顺利进行实时计算的重要前提。
本文从实际业务需求出发,针对目前流数据管理系统的种种不足[2][3],结合雷达流数据自身的多个特征,采用主从式分布式架构,利用Akka异步通信框架,设计并实现一个可扩展性强、容错性好的面向流数据的分布式时序同步系统。
1 关键技术
1.1分布式系统架构
目前分布式系统主要有两种主流的分布式结构:主从结构和P2P对等结构[4]。不同的分布式结构有着不同的特点,在面对不同的场景时设计的难度和系统的性能有着很大的差距,因此在实际应用中需要根据不同的业务需求选择合适的结构。
主从结构如图1所示,包含一个主节点和若干个从节点。其中主节点一般扮演着管理者的角色,协调管理各个从节点的信息,并保存系统整体的元数据。主从结构的系统设计较为简单,有着更强的可控制性,但是主节点的性能往往会影响整个系统的运行,容易成为系统的瓶颈。采用主从结构的系统有很多,典型例子有:Hadoop[5],Storm,Spark等。

图1 分布式系统主从结构图
P2P对等结构如图2图所示,该结构的系统中每个节点的地位是对等的,所起到的作用也是类似的。这种结构的系统不存在单点故障的问题,但是每个节点必须向系统中的其他节点广播自己的信息,使得每个节点都知晓系统的整体状况,这种设计方案也造成了系统有较大的通信开销。采用P2P对等结构的系统也很常见,典型例子有:Redis[6],OceanStore,Past等。
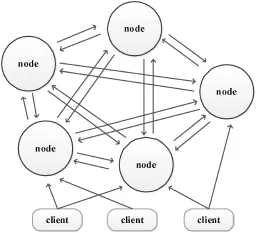
图2 分布式系统P2P结构图
1.2并发处理框架Akka
Akka[7]是一个开发库和运行环境,可以用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。
1.2.1 Akka的Actor模型
Actor模型并不是最近才出现的概念,早在上世纪70年代早期,Carl Hewitt就已经提出这一模型,目的是为了解决分布式系统中一系列的编程问题[8]。维基百科这样定义Actor模型——在计算科学领域,Actor模型是一个并行计算模型,它将Actor作为并行计算的基本元素来对待:为了快速响应一个外部发送来的消息,一个Actor能够根据既定的规则,自己选择作出某种决策,例如发送更多的响应消息,或创建更多处理逻辑的Actor,或确定以何种方式去响应接收到的下一个消息。Actor模型是一种分布式系统中的高级抽象方式,也是Akka系统中最核心的概念,它封装了状态和行为。另外,Actor之间也可以通过交换消息的方式来相互通信。每个Actor都具有自己的Mailbox来接收其他Actor发送过来的消息。通过Actor的抽象,可以明显简化锁和线程管理的工作,而且可以非常容易地开发出逻辑复杂的并发系统。
1.2.2 Akka Cluster
Akka Cluster提供了一个容错、去中心化、基于P2P的集群服务,而且不会出现单点故障问题。Akka基于分布式系统的Gossip协议[9],实现集群广播服务,而且能够快速检测失败情况。
一个Akka集群由若干个成员节点组成,其中每个成员节点的唯一标识是hostname:port:uid,同时所有成员节点之间是完全解耦合的。一个Akka应用程序是分布式的,它具有一个Actor的集合S,而且每个节点可以集合S的一部分Actor,而非全集S。由于Akka集群是基于Gossip协议实现的,所以如果有一个新的成员节点准备加入到原来的Akka集群中,只需要在集群中任意一个成员节点上执行Join命令,集群中其他节点将会获知该成员节点加入的消息。
Akka集群中各个成员节点之间的状态关系,如图3所示。
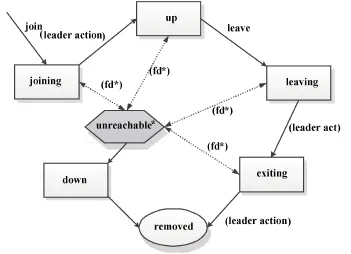
图3 Akka集群节点的状态关系图
基于Gossip协议收敛过程得到的确定性结果,Akka集群中任何一个成员节点都有可能成为集群的Leader,而且这个过程是透明的。Leader仅仅扮演一种临时的角色。因为在各轮Gossip收敛过程中,Leader是可以变化的,它负责管理各个成员节点进入和离开集群。一个成员节点加入后,开始处在joining状态,当所有其他节点因为广播消息的原因,都看到了该新成员节点,则Leader会将该节点的状态修改为up。如果一个节点顺利地离开原来的Akka集群,它可以预先将其自身的状态改为leaving。当Leader看到该节点变化为leaving状态之后,会将该节点的状态进一步修改为exiting,然后经过一段时间,当所有其他节点都已经看到该节点状态变为exiting,则Leader将该节点移出集群,其状态被修改为removed。如果一个节点处在unreachable状态,基于Gossip协议的定义,Leader无论通过任何办法来执行操作,系统都是无法收敛到该节点的,所以当节点处于unreachable状态,它必须被外界执行某些操作来进行强制性改变,使其状态变成reachable或者down。如果该节点在离开集群之后,如果想重新加入到原来的Akka集群,必须经过重启并经过若干个步骤加入到集群。
2 系统设计
本文构建的面向流数据的分布式时序同步系统采用主从结构,不仅能够很好解决多路流数据同步问题,而且具有良好的可扩展性,同时降低了系统的设计难度。本文设计的系统整体架构如图4所示。整个系统分为消息控制节点和数据同步节点,其中消息控制节点是系统的主节点,只有一个;数据同步节点是系统的从节点,也就是系统中的数据接入服务器。其中,主节点并不处理到来的流数据,只负责保存各个从节点发送过来的同步信息,以及根据数据目前的到达情况和是否超时来决定向各个从节点下达数据发送的命令。各个从节点负责接收上游的数据,并发送一批数据初次到达服务器以及一批数据完全到达服务器的消息给系统的主节点,并根据主节点返回的命令做进一步的处理。主节点与从节点之间通过消息进行通信交互。同步过后的数据经过复制,成为两份,一份流向实时计算系统,另外一份流向持久化存储系统。

图4 面向流数据的分布式时序同步系统架构图
3 系统实现
3.1消息类型
本系统使用Akka作为分布式组件之间的通信工具。Akka是一个基于Actor模型的异步消息框架,Actor与Actor之间相互独立,使用队列的机制收发消息。本系统可以抽象出4种Actor,这4种Actor分别为:主节点接消息Actor(MasterMsgActor),主节点定时Actor(MasterTimerActor),从节点接数据包Actor(SlaveDataActor),从节点接消息Actor(SlaveMsgActor)。Actor之间的通信是通过Akka封装的消息来完成,本系统涉及到以下5种消息类型(约定如下:<>中的字段为消息内容,ActorA –> ActorB表示消息是从ActorA发送给ActorB):
(1)
(2)
(3)
(4)
(5)
3.2数据结构
本文构建的面向流数据的分布式时序同步系统采用典型的主从结构,主节点和从节点分别扮演不同的角色。雷达流数据只在从节点进行缓存,而不需要经过主节点。主节点主要负责从节点之间的协调与控制。系统中的主节点与从节点,分别使用不同的数据结构对数据和消息进行组织和管理。这种设计方案达到了“移动计算,不移动数据”的目的,大大减少了系统的通信开销,提高了系统的响应速度。
主节点的数据结构为:MasterList(LinkedList< MasterTable>)。MasterList是主节点维护的链表,用于记录所有从节点数据包到达的情况。其中,每一项是自定义的类MasterTable。MasterTable类中包含以下几项:

表1 MasterTable详细定义
从节点的数据结构有两个:
(1)PackageList(LinkedList

表2 Package详细定义
(2)DeletedGroupSet(Set
3.3处理流程
本文构建的面向流数据的分布式时序同步系统分成主节点和从节点,两者有着截然不同的处理逻辑。由于系统的整体框架都是基于Akka的消息驱动机制建立的,所以当主节点和从节点接到不同的消息或者数据时,将会启动不同的处理流程。下面分别从主节点和从节点两个角度来阐述系统的处理流程。
3.3.1 主节点处理流程
第一种情况,主节点接消息进程接到首次消息FIRST后,处理流程如图5所示,具体步骤如下:
(1)首先检查MasterList是否为空。
(2)如果为空,添加GroupID到MasterList,并同时启动定时进程MasterTimerProc。
(3)否则,遍历MasterList,如果能找到GroupID,则判断是否超时。
(4)如果超时,则下达SEND命令给各个从节点,然后删除对应项。
(5)否则,不执行任何动作。
(6)如果遍历MasterList之后没有找到相同的GroupID,则添加GroupID进去,并启动定时进程MasterTimerProc。

图5 系统主节点接到FIRST消息
第二种情况,主节点接消息进程接到完成消息LAST后,处理流程如图6所示,具体步骤如下:
(1)首先遍历MasterList,查找传入的GroupID。
(2)找到以后,判断是否超时。
(3)如果超时,则下达SEND命令给各个从节点,然后删除对应项。
(4)否则,更新FinishNum,然后判断FinishNum是否等于从节点的个数。
(5)如果相等,说明各个从节点的该组数据已经全部到达,下达SEND命令给各个从节点,然后删除对应项。
(6)否则,不执行任何动作。
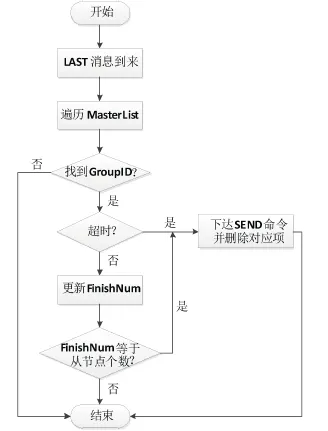
图6 系统主节点接到LAST消息
第三种情况,主节点接消息进程接到主节点定时线程的唤醒消息AWAKE后,处理流程如图7所示,具体步骤如下:
(1)首先遍历MasterList,查找传入的GroupID。
(2)如果能够找到,则下达SEND命令给各个从节点,然后删除对应项。
(3)否则,向主节点定时进程返回MasterList头部的GroupID以及剩余定时时间。
第四种情况,主节点定时线程接到主节点接消息进程的定时消息SLEEP后,处理流程如图8所示,具体步骤如下:
(1)休眠传入的定时时间。
(2)立即返回传入的GroupID。
3.3.2 从节点处理流程
从节点不仅接收数据,缓存数据,还根据主节点的反馈信息,执行发放数据到实时计算集群和持久化存储集群的动作。
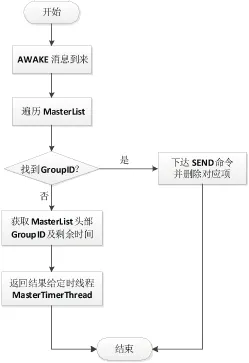
图7 系统主节点接到AWAKE消息
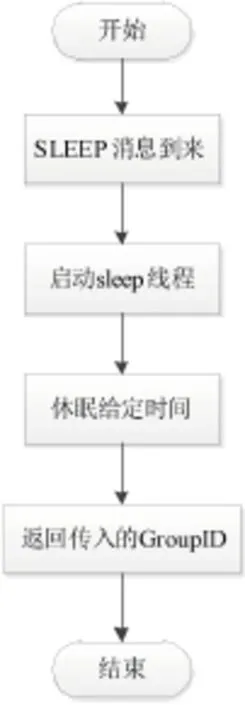
图8 系统主节点定时线程接到SLEEP消息
第一种情况,从节点接到新到达的数据newData后,处理流程如图9所示,具体步骤如下:
(1)首先检查DeletedGroupSet是否为空或者DeletedGroupSet中是否不含有newData的GroupID,记为条件1。
(2)如果满足条件1,然后判断PackageList是否为空,记为条件2。
(3)如果满足条件2,则添加newData到PackageList,并发送FIRST消息给主节点。
(4)然后判断newData的该组所有个数totalNum是否为1,记为条件3。
(5)如果满足条件3,则发送LAST消息给主节点。

图9 系统从节点接到新数据newData
(6)如果不满足条件2,则遍历PackageList,查找是否有GroupID等于newData的GroupID,记为条件4。
(7)如果满足条件4,则在GroupID所在位置插入newData,同时count加一。
(8)然后判断count是否等于newData的totalNum,记为条件5。
(9)如果满足条件5,则发送LAST消息给主节点。
(10)如果不满足条件4,则插入newData到PackageList的末尾,并发送FIRST消息到主节点。
(11)判断条件3,如果满足,转入(5)。
第二种情况,从节点接到主节点返回的SEND命令,处理流程如图10所示,具体步骤如下:
(1)添加GroupID到DeletedGroupSet,标记该GroupID已经被删除。
(2)遍历PackageList,找到GroupID对应的该组所有数据,发送到下游的系统。
(3)删除该组数据。

图10 系统从节点接到SEND命令
4 实验验证
本实验采用64位的Ubuntu作为服务器的操作系统,Akka版本为2.4.16。本实验构建了一个面向流数据的分布式时序同步系统,共使用11台服务器,其中5台作为数据发射器,5台作为与数据发射器一对一的数据接入服务器,同时也是时序同步系统的从节点,另外1台作为时序同步系统的主节点。实验主要针对分布式时序同步系统进行功能测试,验证在不同的流速下,各个从节点服务器之间能否完成同批数据的同步操作。测试方式是在流数据发射器分别发送100 MB/s、200 MB/s、300 MB/s、400 MB/s、500 MB/s的数据包,观察主节点控制台显示的信息。如果每个从节点服务器能够对到来的每一批流数据成功完成同步操作,主节点将会及时给各个从节点发送命令,将这一批次的数据发送到下游系统,而且该信息将在主节点的控制台打印出来。如果同步失败,主节点也将打印同步失败的信息。
图11显示的是当流数据流速为500MB/s时,主节点控制台打印出来的信息,从图中显示的信息可以看出,时序同步系统的运行结果正常,达到了预期的同步效果。其他流速下的结果也类似,系统同样运行正常,验证了系统在时序同步方面的正确性。

图11 流数据流速为500 MB/s时的实验结果图
5 结论
本文从实际的业务背景出发,结合雷达流数据的具体特征,借鉴当前分布式系统的设计思想,利用Akka作为异步通信工具,设计并实现了面向流数据的时序同步系统。该系统具有可扩展性强、容错性好的优点,不仅可以实现雷达流数据的时序同步功能,也可以很好地应用到其他流数据的管理系统中。
[1] BL Golab, MT Özsu. Issues in data stream management[J] ACM Sigmod Record, 2003,32(2), 4-14.
[2] 马凯航, 高永明, 吴止锾, 李磊. 大数据时代数据管理技术研究综述[J]. 软件. 2015(10)
[3] 周昭, 林昭文. 基于OpenFlow的数据流管控系统的研究与实现[J]. 软件. 2013(12)
[4] 华镕. 谈谈分布式系统[J]. 软件. 2007(06)
[5] 陆嘉恒. 分布式系统及云计算概论[M]. 北京: 清华大学出版社. 2011.
[6] Redis home page: https://redis.io/
[7] Gupta, Munish. Akka essentials. Packt Publishing Ltd, 2012.
[8] Tasharofi S, Dinges P, Johnson R E. Why do scala developers mix the actor model with other concurrency models? [C]. European Conference on Object-Oriented Programming. Springer Berlin Heidelberg, 2013: 302-326.
[9] Fetahi Wuhib, Rolf Stadler, Mike Spreitzer. A gossip protocol for dynamic resource management in large cloud environments. IEEE transactions on network and service management, 2012.
Design and Implementation of the Distributed Timing Synchronization System for Stream Data
HUANG Wei-jian, HU Huai-xiang
(North China Institute of Computing Technology, Beijing 100083, China)
In view of the shortcomings of the current distributed data management scheme, this paper starts from the actual business demand, combines the characteristics of the radar flow: large single message body, large message flow pressure and obvious fluctuation of the traffic flow, takes the master-based distributed structure and Akka, and finally designs and implements a distributed timing synchronization system. The system is highly scalable and fault-tolerant, and it is also an important prerequisite for the subsequent operation of the distributed real-time computing system. This paper first analyzes the key technology used in the system, and then designs the overall framework of the system, and then analyzes the details of the system from three aspects: the message type, the data structure and the processing flow of the master and subordinate nodes. Finally, And the feasibility of the system is verified by the test.
Stream data management; Akka; Timing synchronization; Distributed system
TP391
: A
10.3969/j.issn.1003-6970.2017.02.022
黄伟健,男,硕士研究生,研究方向为大数据处理及分布式存储;胡怀湘,男,研究员级高级工程师,研究方向为计算机网络装备和网络存储技术。
本文著录格式:黄伟健,胡怀湘. 面向流数据的分布式时序同步系统的设计与实现[J]. 软件,2017,38(2):105-111
