笔迹样本提取专家知识库的实践应用探析
2017-04-14黄李彦
黄李彦
笔迹样本提取专家知识库的实践应用探析
黄李彦
(福建警察学院刑事科学技术系,福建 福州 350007)
为解决笔迹样本提取专家系统无法解析生僻字、繁体字以及系统所输出的设计文稿质量不够理想等问题,我们需要对原有的专家知识库进行升级。具体做法是从笔迹样本提取流程、汉字库、汉字特征库入手,对笔迹专家知识库进行重新构建。实践证明,升级完知识库的笔迹样本提取专家系统对汉字的解析能力更强,输出文稿质量更高,更具实用性和拓展性。
笔迹鉴定;样本提取;专家系统;知识库
1 引言
笔者曾于2014年研发了一套笔迹鉴定样本提取专家系统V 1.0(下面简称笔迹专家系统),系统主界面如图1所示,该系统主要包含笔迹样本提取专家知识库(下面简称笔迹知识库)、笔迹样本提取业务逻辑库以及智能推理机等模块,系统可以实现对待检验笔迹内容按偏旁、笔画、固定搭配等特征进行分解,并按照检材文稿格式生成笔迹样本提取文稿[1]。
该系统的主要用户包括公检法系统的工作人员、司法鉴定机构的工作人员及公安、司法类院校开设文件检验相关课程的师生。通过使用该系统,用户可以自行完成当事人设计笔迹样本的提取。经过两年多的实践应用,笔者陆续收到用户的一些反馈,有褒有贬,下面笔者将用户反馈的主要问题进行归纳,并探析相应的改进方案。
图1 主界面Fig.1 The main interface
2 原有系统知识库问题分析
用户所反馈的问题,大致可以归纳为以下几类:
(1)生僻字无法分析
在用户反馈中,生僻字无法解析所占的比重比较大,诸如“犇”、“焺”、“燚”、“珄”、“贇”、“菥”、“媺”、“鰆”等字都曾有人反馈过,而且这些字是出现在人名当中,正是笔迹鉴定的重点对象。
(2)繁体字无法分析
也有很多用户反馈繁体字无法解析,这些字主要出现在两个地方:一是和台资企业、台胞来往的文件,几乎全是繁体;二是一些老人家书写的文书,里头也有大量的繁体字,甚至还有很多异体字。比如“墙”字,有写“墻”的,有写“牆”的,还有写“廧”的。
(3)笔画分析不够细致
对笔画特征的分析不够深入、细致,比如“力”的第一个笔画、“月”字的第二个笔画,都解析为“横折钩”,但是在笔形上前者更准确的说应该是“横撇钩”,后者应该是“横竖钩”;相同偏旁不同单字也可能出现笔形的区别,比如“玥”、“情”字,虽然都有“月”,解析笔画也一致,但是前者的“月”的第一笔画在笔形上是“撇”,后者的“月”的第一笔画则是“竖”。
(4)固定搭配分析不全面
对汉字的构件拆分方法比较单一,比如“戴”字,系统把它分解为“異”,但实际上它还可以分解为“田共”、“土田八戈”,再比如“糊”字,系统把它分解为“米胡”,但实际上它还可以分解为“米古月”、“米十口月”。
(5)没有考虑间架结构
系统缺乏对汉字间架结构的归类解析,在实践中,很多书写者曾练习过书法,并阅读过《间架结构摘要九十二法》、《结字三十六法》、《黄自元书法间架结构九十二法》、《大字结构八十四法》之类的书籍,其笔迹在间架结构上有明显特征,但是系统之前没有考虑到。
3 系统知识库改进方案分析
3.1原因分析
笔者之前在设计系统时采用的是用户界面层、业务逻辑层及数据库层三层分开的系统架构[2],如图2所示,在整套系统中,处于数据库层的知识库是整套系统运行的基础。由此可见上述问题之所以会出现,其根本原因是当时设计知识库时考虑不够全面,和实践应用存在一定的脱节,另外所填充的数据也不够完善。因此,想解决用户反馈的那些问题,只有一个方案,那就是对原有的笔迹知识库进行更新换代。
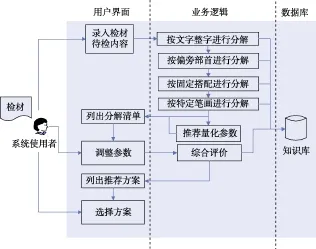
图2 系统架构Fig.2 The structure of system
3.2改进思路
要想完成笔迹知识库的更新换代,首先需要全面查阅专业书籍、网站及相关文献,重新收集、归纳笔迹样本提取的方法,同时联系一批在一线工作的笔迹鉴定专家、从业人员,进行实地调研,全面分析、归纳提取笔记样本的流程、要点以及操作技巧。在此基础上,再从汉字的数量、使用频率、偏旁部首、外观结构、异体字、字体、书写习惯等方面入手,重新分析、归纳汉字的特征。在完成上述两项工作的前提下,召集计算机编程方面的专家进行研讨,重新设计专家知识库的数据库模型及数据库表结构,并设计出自动、人工构建专家知识库所需要的方法、流程及辅助工具,最终完成专家知识库的升级、改进。
3.3数据来源
笔者通过大量调研,最终选定以下四个网站作为本次专家知识库升级的主要数据来源:
(1)HTTPCN
该网站网址为http://www.httpcn.com/,网站有一个汉语字典功能,可提供汉字在拼音、简繁体、异体字、部首、笔画、笔顺、首尾分解查字、汉字部件构造等方面的信息查询。
(2)汉典
该网站网址为http://www.zdic.net/,网站有一个汉字条目查询及拆分功能,可提供汉字在拼音、部首、字形分析、异体字、笔顺、汉字结构、构件等方面的信息查询。
(3)国学大师
该网站网址为http://www.guoxuedashi.com/,网站有一个汉字条目查询功能,可提供汉字在拼音、部首、总笔画数、笔顺、异体字等方面的信息查询。
(4)911查询
该网站网址为http://www. 911cha.com/,网站有一个新华字典功能,可提供汉字在拼音、简繁体、异体字、部首、总笔画数、笔顺、汉字结构等方面的信息查询。
3.4升级方案
笔迹专家知识库的升级由数据抽取、数据转换及数据加载三个步骤组成[3],如图3所示,其中数据抽取步骤负责将来自不同网站的异构数据抽取到临时数据区;数据转换步骤负责将临时数据区中的数据进行验证、替换、补缺、拆分、清洗、规范化以及合并汇总;数据加载步骤负责将转换后的数据完整的存储至知识库[4]。
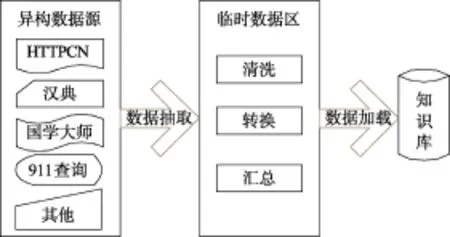
图3 知识库升级Fig.3 Knowledge base upgrade
4 新系统知识库改进效果分析
通过实施上述改进方案,笔者成功构建了一套新笔迹专家知识库,并对用户发布了数据库升级包,用户通过安装升级包便可完成笔迹专家系统知识库升级[5]。
表1是笔迹专家系统在知识库升级前后的主要指标对比。
从升级用户反馈的情况来看,升级完知识库后的专家系统明显比升级之前更好用,主要表现在对汉字的解析能力增强,输出文稿质量提高以及更具实用性和拓展性等方面。
4.1对汉字解析能力增强
旧知识库仅采集GB2312中所包含的6763个简体汉字的信息,而新知识库由于选定了四大专业研究汉字的网站作为数据来源,可采集81408个字的信息,基本克服了生僻字、繁体字无法解析的现象。升级知识库前的系统大概只能解析实践中70%左右的检材,而升级后至今还未出现无法解析的检材,可见,知识库的升级使系统在检材的解析能力方面得到了大幅度提升。事实上,从新知识库的字库覆盖程度来看,系统对汉字检材的解析能力已经接近100%。
4.2输出文稿质量提高
实践中,笔迹检材字数往往不多,比如常见的签名笔迹鉴定,仅2-4个汉字,鉴定难度大;样本质量对鉴定工作是至关重要的,样本必须包含一定数量的检材相同字或偏旁部首,但如果样本文稿设计的过于简单,比如完全采用检材一样的字或者相同的偏旁部首,就容易引起样本书写者的注意而导致伪装现象频繁出现。专家系统的设计理念是既要保证样本文稿中检材特征部位的出现率,又要保证样本文稿的隐蔽性。
使用旧知识库的专家系统虽然可以从单字的偏旁、笔画、固定搭配对汉字进行解析,但是由于对笔画的解析没有考虑笔形变化,对固定搭配的设置也很有限,所以整体上对汉字的解析能力不强。用户反馈的意见是,实践中基本上只能用偏旁进行汉字解析,如果检材中汉字特征出现在某个笔画上,需要人为对输出文稿进行调整,无形中增加了用户设计文稿的难度。使用新知识库的专家系统由于增加了从间架结构、笔形以及多种构件对汉字进行归类、分解的功能,系统对汉字的解析能力增强了[6],对书写者书写特征出现次数、概率、分布位置的设计更加全面、隐蔽、科学,设计思路更加接近人类专家[7],因此系统所给出的推荐文稿质量比升级前有明显提升,基本不用再做人工干预、修改即可直接投入使用。

表1 系统功能对比Tab.1 Function comparison of systems
4.3更具实用性和拓展性
用户使用笔迹专家系统来设计文稿的目的是为提取书写者的设计笔迹样本服务。在实践中,通常由样本提取者采用不同的语速朗读设计文稿,书写者把听到的文稿内容书写在指定的纸张上。在听写过程中,设计文稿可能出现朗读者自己也不认识的字,按照以前的做法是要去查字典,有时候这些字还不太容易查找到。为此,新知识库特地增加了对汉字的拼音标注功能,并附带了相应的语音文件,这个功能不仅可以解决实践中工作人员由于不认识生僻字难以读稿所带来的尴尬局面,未来还可以作为电脑语音自动播报的支撑[8],系统比原来更具实际操作性和拓展性。
5 小结
笔迹专家知识库是笔迹专家系统的基础,由于之前在设计知识库时考虑不够全面,导致笔迹专家系统在实践应用中出现了一些问题,为此,笔者从笔迹样本提取流程、汉字库、汉字特征库入手,对笔迹专家知识库进行了全面升级,升级完知识库的笔迹专家系统无论是功能、还是性能都得到了大幅度提升,普遍得到了用户的认可,整套系统具有更高的实用价值、更广阔的推广空间。
[1] 黄李彦, 笔迹样本提取专家系统及其应用研究[J]. 福建警察学院学报, 2014(5): 20-24.
[2] 葛管库. MVC 模式下程序设计[J]. 软件, 2013, 34(2): 49-51.
[3] 操牡丹, 基于知识库的企业异构数据集成[D]. 北京: 北京邮电大学, 2010.
[4] 赵健, 冯乔生, 何娟娟. 面向汉字识别的新特征及其提取方法[J]. 软件, 2015, 36(3): 31-36.
[5] 刘超, 张明安. 基于Oracle数据库系统的备份与恢复技术研究[J]. 软件, 2014, 35(3): 125-128.
[6] 谢辉程, 郭莉. 小型汉字字库设计与查询算法分析[J]. 软件, 2014, 35(10): 43-45.
[7] 曾霖. 基于Web数据库的数据库挖掘技术探究[J]. 软件, 2013, 34(2): 58-60.
[8] 曾谁飞, 王仁波. 语音合成技术在智能语音播报系统中的应用探析[J]. 电信科学, 2010(3): 64-68.
Study on Practical Application of Knowledge Base for Expert System of Handwriting Sample Collection
HUANG Li-yan
(Criminal Science Technology Department of Fujian Police Academy, Fuzhou 350007, China)
In order to solve the problems that expert system of handwriting sample collection cannot analysis rarely-used Chinese characters, traditional Chinese characters and the quality of system output is poor. We need to upgrade the original expert knowledge base. The specific working means is to reconstruct the knowledge base starting from the process of handwriting sample collection, the Chinese character library and the Chinese character database. Practice has proved that after the upgrade of the knowledge base, the analytical ability of Chinese characters is stronger, the quality of output is higher, and the expert system has more practicability and expansibility.
Handwriting identification; Sample collection; Expert system; Knowledge base
D918.92
A
10.3969/j.issn.1003-6970.2017.02.005
福建省教育厅中青年教师教育科研项目(JA15565)
黄李彦(1982-),女,副教授,硕士研究生,研究方向:文件检验。
黄李彦(1982-),福建警察学院刑事科学技术系。
本文著录格式:黄李彦. 笔迹样本提取专家知识库的实践应用探析[J]. 软件,2017,38(2):19-22
