社交网络中的用户行为分析
2017-04-14海昕
海 昕
社交网络中的用户行为分析
海 昕
(北京邮电大学 数学专业,北京 海淀 100876)
近年来,国内人民的生活水平在不断的提高,互联网迅速的发展起来,并且出现在人们生活的各个领域中,导致网络用户的数量大大增加。本文通过对网络用户的行为进行分析,运用信息检索的方式来对网络用户进行分类,进而分析网络用户的行为特征。采用CHI特征选择算法对特征进行提取,通过整合特征词将网络用户分类,然后采用TF-IDF算法对特征进行加权运算,分析了算法的不足并为相关的特征词分配了适当的权重,然后对这些网络的身份进行识别。最后本文进行扩展,通过特殊举例用户的网络数据,用余弦定理进行相似度比较,这样可以了解这些用户之间拥有多少相同的话题和爱好,大大增加了彼此之间成为好友的可能性。这种方法在以后也可以应用在用普通的文本搜索相似的文章中。
特征词;CHI算法;TF-IDF算法;余弦定理
0 引言
网络用户行为分析涉及到对用户进行分类,尽管网络信息具有多种多样的形式,但文本信息仍然占有很重要的地位,糅杂在这些千千万万信息中有部分有效且对于自己有用的信息,要如何精确的对这部分信息进行筛选和定位,是本文研究的重点的目的。根据文本的相关内容确定文本所在的位置是常用的文本分类方法,这种方法在解决一些方面的问题具有重要的作用和意义,例如对于用户所需要的信息可以准确定位和分类。目前文本分类技术通过使用自动文本分类方法,人们的生活得到了大大的改善,人们在网络中可以通过整个方法迅速准确地对繁冗复杂对信息分类,从中寻找出自己真正所需求地信息。而在这个自动文本分类方法中,特征选择和特征加权就作为了重要地技术,这些技术可以排除很多无意义地关键词和一些无关特征,使得最后生产地文本表示出地模型更加简洁,这样下来,分类的性能得到了大大的提升,分类的效果和准确率也得到了突飞猛进的改进。文章运用信息检索的方式来对网络用户进行分类,进而分析网络用户的行为特征,在进行了相关的数据预处理的基础上对相关网络用户的特征和喜好加以分析。分析采用了CHI特征选择法,非常有效地去分类和规整相关的网络用户,在提取特征时采用了TF-IDF算法,这样能够保证数据在权重分配相当的基础上有效的识别网络身份。本文主要研究TF-IDF这个经典的特征加权方法,通过阅读文献查阅资料,分析了这个算法的一些缺陷。本文最后在用户分类方面受到了启发,利用余弦定理这个新闻相关搜索的方法对用户进行相似性比较,从而可以通过使用余弦定理帮助这些用户寻找出彼此之间有多少共同的话题和爱好,在以后也可以应用在用普通的文本搜索相似的文章中。
1 主要算法介绍
1.1卡方统计量(CHI)特征提取算法
x2统计量(Chi-square Statistic,简记为CHI)的概念来自列联表检验(Contingency Table Test),这种方式对于t、c的相关性能够给出一个比较明确的表示,这样即能够实现去验证理论值是否正确。首先在运用这种方法时我们在对照了理论值和实验值的基础上,充分的去探究其存在的差异并得出验证结果。识别网络用户的身份时c指代用户,t是这些用户的相关特征,t与c关系满足一阶自由度2x分布,运用数学规律计算对相关程度进行检验,相关程度与成正比,即相关程度高时该值则更大,同时,(t)=max x2(t,c)也越大,t和c分别表示i特征和类别,(t)=max x2(t,c)表示该特征所携i带的信息。
CHI卡方统计量方法可以由以下公式表示:
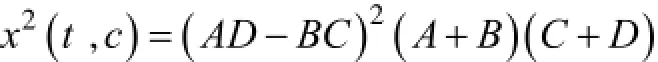
其中,A,B,C,D分别表示不同的样本数。在这些样本ABCD中,只有AC属于用户c,AB包含特征t。CHI(t ,c)表示用户c与该特征t的关联程度。CHI(t ,c)=0时,二者属于独立关系;而当CHI(t ,c) ≠0时,二者即相关,相关性是在CHI(t ,c)的增大的情况下变强的,因此,根据CHI(t ,c)的大小,可以对特征t于用户c的关系密切程度排序,按照高低顺序,则能够比较直接的了解哪些特征与用户相关。
特征出现次数多少可以在应用卡方统计进行量算的时候忽略,不过我们需要对相关的特征展开其他的加权计算才能够对其在用户识别过程中具体发挥的作用和功效进行评估。我们一般采用TF-IDF函数来进行加权运算。
1.2TF-IDF算法
1.2.1 TF-IDF算法介绍
TF-IDF这种统计方法经常见于对一个字、词或者文集在一个文件中重要与否,重要程度是多少的评估计算中。所需要评估的字词出现次数越多,那么其在文章中就越重要,不过其在语料库出现频率则会与其出现次数呈负相关。在搜索引擎中应用这种统计方式能够对使用相关搜索引擎的用户查询文件的相关程度大小进行评估。TF-IDF主要包含两个方面:
(1)TF(term frequency),单文本词频
1. 设N为查询项中关键词的个数,1W,2W…,, WN,它们在一个特点网页中的词频分别是:TF2,TF2,…,TFN,那么这个查询的相关性就是:TF1+TF2+…+TFN;
2. TF漏洞:例如“北邮的学生”,词“的”对查询几乎无用,称为“停止词”,在度量相关性时不应考虑它们的频率;
3. 忽略停止次后,查询的相关性变成“北邮”(专业词),“学生”(通用词),需要给予权重。
(2)IDF(inverse document frequency),逆文本频率
1. 在信息检索中,使用最多的权重是IDF,公式:logD/Dw,其中D是全部文本数,Dw数越大,IDF值越小,权重就越小,反之;
2. 利用IDF,由原先词频的简单求和变成了加权求和,即:

3. TF-IDF的经典计算公式为:

其中TFti表示特征ti在文档d中的频度TF,用tfi(d)来计算。
1.2.2 TF-IDF算法的缺陷
TF-IDF函数能够比较好的显示出相关特征项重要与否,与特征项的重要性相关的两个重要因素是词频TF(单文本频率)和IDF(逆文本频率)。特征项出现于相关文本中的次数可以代表其出现的频率,在根据相关的词频计算函数就能够展开相关的计算。常用的TF因子主要有原始TF因子,对数TF因子,二元TF因子等,大规模测试表明,对数TF因子的效果最好。
虽然上述这种TF-IDF算法在操作方面比较容易,不过这种传统的函数计算方法在某些比较特定的计算中就会展露出其缺陷,例如C类中包含了t特征的文本,文本数为m,设包含该特征的文本总数是n,即在计算中s是m和n的总和。从结论中我们可以看出m和s是成正向相关的,通过计算我们发现当m和s的数值都比较大的时候IDF值小,自然的TF-IDF的值也会缩小,在这种情况下相关词语t的类别区分能力就比较弱。但是在实际情况中m数值大还意味着t在C这个文本当中出现的次数比较多,比较能够说明C文本的属性,也就是要应该被赋予较高地权重。从另一个角度来看,t在比较稀有的情况下,包含该特征的文本数s值小,那么相应的IDF和TF-IDF值相对较大,那么t则具有强的区分能力,不过要排除t均匀分布与各间类的情况。如果是均匀分布的情况下那么t对于文档属性仍然不能很好的区分,可能大部分文件中都含有t特征,并且t作为了一个无用词,所以此时t应该被赋予较小的权重。
该问题的发生几率很大程度上使取决于IDF部分对相关的特征在类间具体分部的情况反映是否充分。
当m很大,s很小的时候,就说明特征t在C类内大量出现,而在其它类别中很少出现,因为此时n很小,显然这种特征项具有很强的类别区分能力,算是类别的独特特征词,应该被赋予较高的权重。但是根据IDF的定义以及运算公式可知,若特征项在较多的文档中出现,则IDF的值很小,导致此时TF-IDF的数值变小,理论上特征t要被赋予较小的权重。
而这种不合理的情况时由于IDF没有考虑特征在类内的分布情况所导致的。
2 拓展和假设
论文的最后提出了一种假设,在网页中浏览新闻的时候,往往会出现一系列新闻,这些新闻都有一个共同点,那就是它们包含了你所搜索或者关注的一些特征词,这样它们有可能会成为你喜欢的或者来说可能感兴趣的新闻。
在新闻检索中会出现相似信息的这种方法,称之为数学中的余弦定理。在此基础上我们可以做出大胆假设,在日益盛行的社交网络平台中,可以利用这种方法来寻找适合自己的网友,这样彼此之间会拥有更多相同的爱好和话题。比如收集一些陌生网民固定数量的微博博文,提取特征词,然后利用余弦定理进行运算,以此结果来判断以后成为好友的可能性,。下面将为大家做出这种假设,虽然存在不足,但是我们可以通过假设在日后进行研究,使其完善。
举一个简单的例子:有A和B两个人,发了两条微博。
A:我喜欢打篮球,不喜欢打羽毛球;
B:我不喜欢打篮,也不喜欢打羽毛球。
第一步,提取特征词,进行分词:我,喜欢,打,篮球,羽毛球,不,也;
第二步,计算词频:
A:1,2,2,1,1,1,0,
B:1,2,2,1,1,2,1;
第三步,写出词频向量:
A:[1,2,2,1,1,1,0],
B:[1,2,2,1,1,2,1]。
很多文献和资料通过严谨的数学证明,已经发现余弦定理定理同样适用于N纬的向量空间,因此我们可以放心大胆的使用。通过计算得到上面例子中句子A和句子B夹角的余弦为0.938,而余弦值越接近1,夹角越接近0度,这就表示出两向量越相似,我们称之为“余弦相似性”。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。由此,我们就得到了“找出相似”的一种算法。这种算法不仅可以应用到社交网络中寻找相同话题的网友,也可以应用在用普通的文本搜索相似的文章。归纳出简要步骤一般为:
第一步,使用TF-IDF算法,找出两篇文章的关键词;
第二步,每篇文章各取出若干个关键词,合并成一个集合,计算这个集合的词相对应各自文章的词频;
第三步,生成两篇文章各自的词频向量;
第四步,计算两个向量的余弦相似度,数值越大就表示越相似。
3 总结
本文通过对网络用户的行为进行分析,运用信息检索的方式来对网络用户进行分类,进而分析网络用户的行为特征。在此过程中,先采用CHI特征选择算法对特征进行提取,通过整合特征词将网络用户分类,然后采用TF-IDF算法对特征进行加权运算。本文着重分析了算法的不足,日后进行优良的改进,使其完善。本文的最后提出了一些想法和假设,余弦定理是新闻检索中应用的寻找相似信息的方法,在日益盛行的社交网络平台中,不仅可以利用这种方法来寻找和自己拥有相同话题和爱好的网友,也可以应用在用普通的文本搜索相似的文章中。
[1] 任文君. 基于网络用户行为分析的问题研究. [学位论文]北京, 北京邮电大学, 2013.
[2] 赵小华, 马建芬. 文本分类算法中词语权重计算方法的改进[J]. 电脑知识与技术, 2009, 5(36):10626-10628.
[3] 路永和, 李焰峰. 改进TF-IDF算法的文本特征项权值计算方法[J]. 国书情报工作, 2013, 57(3): 90-95.
[4] DENG Z H, TANG S W, YANG D Q, et al. A Linear Text Classification Algorithm Based on Category Relevance Factors[C]. International Conference on Asian Digital Libraries: People, 2002, 2555:88-98.
[5] HOW B C, NARAYANAN K. An Empirical Study of Feature Selection for Text Categorization Based on Term Weightage[C]. IEEE WIC ACM International Conference on Web Intelligence, 2004, 599-602.
[6] BERGER A, CARUANA R, COHN D, et al. Bridging the Lexical Chasm: Statistical Approaches to Answer Finding. International Acm Sigir Conference on Research and Development in Information Retrieval, 2002, 192-199.
[7] SHANG W, QU Y, ZHU H, et al. An Adaptive Fuzzy KNN Text Classifier Based on Gini Index Weight[C]. IEEE Symposium on Computers and Communications, 2006, 448-453.
[8] XIN T, LIFSET R. International Copper Flow Network: A Blockmodel Analysis. Ecological Economics, 2007, 61(2-3): 345-354.
[9] DUSTDAR S, HOFFMANN T. Interaction Pattern Detection in Process Oriented Information System, Data&Knowledge Engineering, 2007, 62(1): 138-155.
Analysis of User Behavior in A Social Network
HAI Xin
(College of Mathematics, Beijing University of Posts and Telecommunications, Haidian District, Beijing)
Recently, the people's living standard in China is constantly improving, the Internet is rapidly developed, and in all areas of people’s life, leading to the number of Internet users has greatly increased. This paper based on the analysis of the behavior of network users, using the method of information retrieval to classify some netizens, and then analyzing the behavioral characteristics of Internet users. This paper utilizes the CHI feature selection algorithm to extract the characteristics, then this paper analyze the defects of the TF-IDF algorithm and use the algorithm to carry on the weighted calculation so as to assign proper weights for these characteristic words and recognize these network identities. Finally this paper extends through the network data for netizens and compare with the cosine similarity. Thus it can understand that how much the same topics and interests among these netizens easily and increase the possibility of becoming friends greatly. This method can also be used later in the search for similar articles in plain text.
Feature words; CHI algorithm; TF-IDF algorithm; Cosine theorem
TP391.1
: A
10.3969/j.issn.1003-6970.2017.02.011
国家自然科学基金(11471051);国家自然科学基金(11371362)
海昕(1992-),北京邮电大学研究生。
本文著录格式:海昕. 社交网络中的用户行为分析[J]. 软件,2017,38(2):47-50
