基于VSM的文件密级检测系统设计与实现
2017-04-13张明星邓时滔李海怒
张明星,邓时滔,李海怒
(中国核动力研究设计院,四川 成都 610005)
基于VSM的文件密级检测系统设计与实现
张明星,邓时滔,李海怒
(中国核动力研究设计院,四川 成都 610005)
基于科研单位内部系统向外导出文件的实际情况,针对人工在对文件密级判定过程中存在效率低、易失误等方面的局限,分析了向量空间模型、相似度算法和分词技术,设计了一套基于VSM的文件密级检测系统,将涉密文件资源库中的文件转化为向量从而构建涉密文件向量集。系统运行时,将待检测文件转化为文件向量,并与向量集中的文件向量进行余弦相似度计算,判断待检测文件密级,从而在一定程度上实现了基于内容的密级检测功能。实验结果表明,系统能够在较短时间内完成对文件密级的检测,正确率较高,系统的应用能够有效提高密级文件管理的安全性和智能性。
向量空间模型;密级检测;信息安全
0 引言
目前,政府机构、科研单位、大型企业的内部信息系统大多采用与国际互联网等外部系统隔离的方式来确保内部敏感信息的安全。在实际业务工作中,内部与外部系统文件交换频度高,在内部文件信息向外部导出的过程中,如果依靠人工来判断文件的密级,往往效率低下,而且由于文件多,存在人为判断失误导致涉密数据泄露的风险,造成文件涉密内容知悉范围的扩大。此外,如果密级文件的密级标识被删除,就需要人工对文件内容进行审查,无疑增大了文件密级判定的难度。因此,通过计算机信息化手段建立基于内容的文件密级自动检测系统,已成为防止内部数据外泄的研究重点,也是保障内部系统数据安全的关键。
基于科研单位由内向外导出文件的实际需求,内部系统中的文件导出前,通过与当前领域的涉密文件进行相似度比对,对文件密级进行检测,相似度越大,说明文件相似程度越高,密级就类似,反之就越低。本文设计了一套涉密文件自动检测系统,通过分词算法对文件进行分词,采用空间向量模型对文件进行重构,建立涉密文件向量集,根据计算文件向量之间的夹角余弦相似度完成对文件密级的检测。
1 向量空间模型
向量空间模型(Vector Space Model,简称VSM)是一个关于文献表示的统计模型,广泛用于文本检索、自动文摘、文本分类和搜索引擎等信息检索领域中[1]。根据向量空间模型的基本思想,将当前涉密文件资源库中全部m个涉密文件中所有词条构成一个n维向量空间V(t1、t2、t3...tn),其中n为词条的总个数。对于文件资源库中的每一个文件i(i=1,2,3,...,m),定义向量Vi=(wi1,wi2,wi3,...,win),其中win表示词条tk(1≤k≤n)在文件i中的重要程度,即权重。权重的计算方法采用tf-idf公式[2-3]:
(1)
式(1)中,tfik表示词条tk在涉密文件i中出现的次数,即特征词频率,tfik越高意味着tk对于文件i越重要;dfk表示整个文件集合中包含词条tk的文件个数,即特征词的文件频率;N表示全部文件数量,分母为归一化因子。idfk=log(N/dfk)为逆向文件频率,idfk越高意味着词条tk对于涉密文件的区别作用越大,权重也就越高。
对于待检测的文件同样需要被处理转换为向量,并用与涉密文件向量集相同的方式表示,即n维向量,q=(wq1,wq2,wq3,...wqn)。待检测的文件向量采用布尔框架进行向量化,如果待检测文件中包含词条tk则权重为1,否则为0。
在涉密文件和待检测文件向量化表示的基础上,待检测文件与各涉密文件之间的相似度通过对应的向量在n维向量空间中的相对位置来确定,即通过计算两个文件向量夹角的余弦函数确定文件的相似度[4],如式(2)所示:
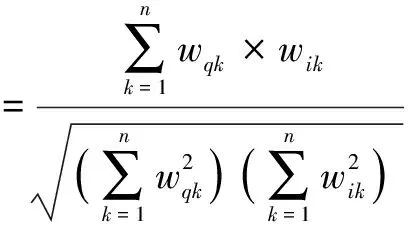
(2)
2 系统设计
本文提出的基于VSM的文件密级检测系统原理如图1所示。
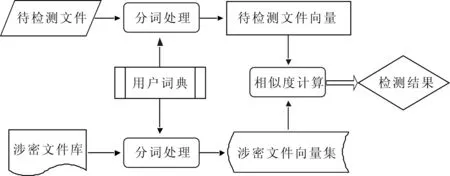
图1 基于VSM的涉密文件检测系统原理
系统主要流程为:
(1)文件预处理及涉密文件向量集建立。将当前领域内的所有涉密文件进行汇总,形成文件库。由于文件中包含有图片、图表等非文本信息,因此需对文件进行预处理,即对文件进行纯文本提取。纯文本提取主要将涉密文件库中不同格式的文件转化为统一的文件格式,去除文件中的图像、标点等非文本信息,以便能够正确识别文件内容并进行下一步的分词处理。本检测系统主要涉及的文件格式为word格式,通过纯文本提取技术将文件转化为txt格式的文件。
由于中文语义的多样性和领域中存在专业词汇,分词算法难以对一些词汇进行正确区分,从而影响分词效果。因此需要建立用户词典,收集特定语义的词汇和专业词汇,在文件分词过程中将涉及的相关词汇加以正确区分。
通过向量空间模型算法建立涉密文件向量集是密级检测系统的关键部分,式(1)在计算词汇的权重时没有考虑词条在文档中的位置对权重的影响[5]。一般而言,出现在封面和前言中词条的重要程度高于出现在正文中的词条,出现在封面中词条的重要程度高于出现在前言中的词条。因此,为有效提高文件相似度计算算法的精度,本文对传统的向量空间模型权重计算方式进行了改进,引入了词条在文件中出现的位置因素。根据实际应用情况,本系统将词条出现的位置分为3种:封面、前言和正文。根据词汇在文件中出现的不同位置,采用式(3)对词条的权重进行加权:
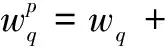
(3)
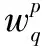
(2)待检测文件向量建立。对于待检测文件,系统通过上述方法完成纯文本提取、分词,通过布尔框架建立待检测文件向量。
(3)相似度计算。根据式(2)中的算法,密级检测系统将待检测文件向量与涉密文件向量集的文件向量逐一进行相似度计算,按照相似度大小排序,设置一定的阈值将相似度较小的文件过滤,给出与待检测文件相似的涉密文件名称及密级,作为判断待检测文件涉密程度的参考。
3 系统实现
3.1 技术路线
本文设计的密级检测系统基于WindowsXP操作系统,以Sun公司的Java作为开发语言,并在MyEclipse平台上实现,系统采用经典的B/S架构和JSP+Servlet技术。
(1)文件读取技术。本系统针对的文件为word格式文件,通过导入Java包完成对文件的读取,代码如下:
importorg.textmining.text.extraction.WordExtractor;
FileInputStreamfileN=newFileInputStream(newFile(wordT)); // 创建输入流读取word文件
WordExtractorextractor=null;
StringtxtFile=null;
extractor=newWordExtractor();// 创建WordExtractor
txtFile=extractor.extractText(fileN); // 对word文件进行提取
(2)分词技术。中文分词主要采用中国科学院计算技术研究所汉语词法分析系统ICTCLAS[6],它是目前最好的中文分词工具并广泛使用于中文分词领域。它提供了用户词典的接口,可以动态地增加、删除用户词典中的词从而调节分词效果,这样就保证了本文涉及的特定领域中的专业词汇能够作为用户词典的词参与分词过程,从而提高系统对专业词汇分词的正确性。
(3)相似度计算实现。本系统根据式(2)实现待检测文件与涉密文件向量集的文件向量进行余弦相似度计算,Java代码如下所示。代码中的“e:javaFileSource”为涉密文件库中的文件,通过纯文本提取、分词等处理后,以txt文本格式存放在计算机硬盘中的路径,vect0、vect为Java语言中的Vector变量,分别存放检测文件、涉密文件中的词条及权重等值。
FilefileDir=newFile("e:javaFileSource"); //FileSource为分词后的密级文件资源库
File[]files=fileDir.listFiles();
for(inti= 0;i {Vectorvect=getFileVect(files[i],"e:javaFileSource"); doublesum=0,b=0,c=0; //相似度计算代码 for(intn= 1;n { doubled=Double.parseDouble(vect0.get(n).toString()) *Double.parseDouble(vect.get(n).toString()); sum=sum+d; b=b+Double.parseDouble(vect0.get(n).toString()) *Double.parseDouble(vect0.get(n).toString()); c=c+Double.parseDouble(vect.get(n).toString()) *Double.parseDouble(vect.get(n).toString()); } doubleres=sum/(Math.sqrt(b*c)); if(res>Keydor) //Keydor为阈值 {System.out.println(" 与检测文件密级相似的文件为" +vect.get(0).toString()+ " 相似度" +res); } } 3.2 实验效果 目前本系统已完成原型系统开发,在系统测试中选取了数百份涉密文件资料,完成分词并建立了上万维的向量空间,构建了涉密文件向量集。在实验中通过检测文件向量与涉密文件向量集进行相似度计算并设置了相似度阈值,系统运行结果返回了与检测文件相似的涉密文件,并对检测文件的密级进行确定。通过对上百份文件进行检测,系统的正确率为83.4%,完成一份文件检测的平均时间为15.7s。实验结果表明,本系统能够方便、快捷、准确地对文件的密级进行检测和判断。 为有效避免涉密文件向外部系统导出存在的风险,本文运用计算机信息化手段,将向量空间模型应用于文件密级检测系统,通过待检测文件与文件库中的涉密文件进行相似度比对,判断文件的密级。根据对向量空间模型的分析和原型系统实验效果可知,本系统针对文件内容的密级检测是有效可行的。 [1] 焦玉英,宋晓晴.基于VSM的文档信息检索改进[J].情报理论与实践,2007,30(1):97-104. [2] 蔡玮,黄陈蓉.一种基于向量空间模型的主观题批改算法[J].计算机与现代化,2008(12):88-90. [3] 张成伟,郑诚.基于改进VSM的文本信息检索研究[J].计算机技术与发展,2009,19(1):71-73. [4] 郝祥根,杨思春,高远飙,等.基于向量空间模型的中文问答系统研究与实现[J].苏州科技学院学报:自然科学版,2009,26(1):76-80. [5] 谢翠香.基于改进向量空间模型的学术论文相似性辨别系统设计[J].电脑知识与技术,2009.5(19):5103-5105. [6] 郑魁,疏学明,袁宏永.网络舆情热点信息自动发现方法[J].计算机工程,2010,36(3):4-6. (责任编辑:孙 娟) 张明星(1985-),男,四川广安人,硕士,中国核动力研究设计院工程师,研究方向为数据库软件系统设计开发;邓时滔(1988-),男,四川安岳人,硕士,中国核动力研究设计院工程师,研究方向为计算机网络技术;李海怒(1986-),重庆人,硕士,中国核动力研究设计院工程师,研究方向为软件工程。 10.11907/rjdk.162562 TP309 A 1672-7800(2017)003-0156-044 结语
