基于卷积神经网络的人脸识别算法
2017-04-13李辉,石波
李 辉,石 波
(1.河南理工大学 物理与电子信息学院;2.河南理工大学 电气工程与自动化学院,河南 焦作 454000)
基于卷积神经网络的人脸识别算法
李 辉1,石 波2
(1.河南理工大学 物理与电子信息学院;2.河南理工大学 电气工程与自动化学院,河南 焦作 454000)
针对卷积神经网络(Convolutional Neural Network,CNN)在人脸图像识别中面对训练规模较大的图像集数据时收敛速度慢、效率低以及在复杂情况下识别率不高的问题,提出一种优化改进的CNN图像识别方法。该方法首先利用不含标签的图像训练一个稀疏自动编码器,得到符合数据集特性、有较好初始值的滤波器集合,然后对CNN的卷积核初始化赋值,从而大大提高其整体上使用BP算法进行训练的收敛速度,其次使用多类别SVM分类器(Multiclass Support Vector Machine)代替传统的Softmax分类器,对目标图像进行识别,在ORL和FERET等人脸图像库上的实验结果显示,所提算法与采用传统PCA+SVM算法及传统CNN算法相比,在人脸图像识别中有更好的识别效果。
深度学习;卷积神经网络;稀疏自编码器;人脸识别;非监督预训练
0 引言
人脸识别作为一种重要的生物信息鉴别方法,在信息安全领域有着很重要的应用价值,是模式识别与计算机视觉领域研究的热点。几何特征方法是人脸识别研究中最早提出的方法之一,Carnegie Mellon大学的Kanade[1]提出基于距离比例的总特征提取方法,该方法使用投影法来确定人脸图像的局部特征,如眼睛、鼻子、嘴部等区域,并计算出由不同特征点组成的距离、角度、面积等参数值,作为目标的特征向量,用于人脸图像的比较,在小样本人脸库中识别率达到了45%~75%。贝尔实验室的Harmon,Goldst等[2]研究出一个基于特征比较的交互式人脸图像识别系统,该系统所用的参数向量包含了21个特征值,系统识别效果较好,但特征点的选择还需人工进行。Turk和Pentland等[3]首次将PCA(Principal components analysis)方法用于人脸图像识别,该方法能够较快地识别出待识别目标,但该方法易受光照、尺度、旋转等因素影响,同时当待识别人脸图像出现偏移、图像背景不同以及表情不同时,其识别准确率也将降低。
卷积神经网络[4]对平移、缩放、倾斜和其它形式的形变具有高度的不变性优点,并且具有深度学习能力,可以通过网络训练获得图像特征,不需要人工提取特征,在图像样本规模较大的情况下,对图像有较高的识别率,因此被广泛用于图像识别。
本文提出一种基于改进的卷积神经网络算法用于人脸图像识别,该算法首先构造一个稀疏自动编码器[5],利用稀疏自动编码器对卷积神经网络的滤波器进行非监督预训练,然后对误差进行最小化重构,获得待识别图像的隐层表示,进而学习得到含有训练数据统计特性的滤波器集合,其次采用多类别SVM[6]代替传统的Softmax分类器,通过在ORL人脸库和FERET人脸库的实验表明,本文算法比传统的CNN算法在人脸识别中有更好的识别性能和更高的识别率。
1 非监督预训练
通过构建一个稀疏自编码器模型对原始图像进行特征提取,并将其训练好的滤波器用于卷积神经网络的卷积核初始化,解决传统卷积神经网络滤波器随机初始化问题。
稀疏自编码器是一种无监督学习模型,通过隐藏层学习一个数据的表示或对原始数据进行有效编码,从而学习得到数据的特征,其网络结构如图1所示。
L1表示输入层,L2表示隐藏层,L3表示输出层,每一个圆圈代表一个神经元,X1、X2、X3、X4代表一组数据的输入,通过限制隐藏层神经元数量或加入一些限制条件,迫使自动编码器隐藏层对输入数据进行压缩,重构出输入数据的特征,这些特征就是想要获得的卷积神经网络的卷积核,具体过程如下:

图1 自动编码器的网络结构
首先稀疏自编码器隐藏层的输出层由列向量与对应权重加权融合并加上偏置项后通过一个非线性函数得到,该过程称为前向传播,公式如下:
(1)

为了保证输出值尽可能等于输入值,需要对式(1)的权重和偏置进行参数优化,方法是最小化目标函数:
(2)
该目标函数是一个方差代价函数,采用梯度下降法[7-8]进行优化,对于维数较高的输入数据,针对其目标函数收敛慢、计算复杂度高的问题,在该函数中引入稀疏约束,构成稀疏自动编码器,为了保证隐藏层的稀疏性,自动编码器的代价方程加入了一个稀疏性惩罚项:
(3)
其中,后一项是KL距离,具体表达式为:
(4)
隐含节点输出平均值表达式如下:
(5)
上述表达式说明,如果隐含层节点输出均值接近0.05,则达到稀疏目的。
最后通过网络迭代训练得到网络权值,公式如下:
(6)
其中α是学习速率,利用反向传播算法[9-11]对上述两个公式后两项的倒数项进行计算,不停迭代更新直到参数收敛后整个网络训练完毕,得到特征参数W、b。为了更形象地理解网络学习的特征,对自编码器学到的特征进行可视化。
假设有100张10*10的图像,这样就有100个像素,因此输入层和输出层的节点数就是100,取隐藏层节点为25,这样就迫使隐藏层节点学习得到输入数据的压缩表示方法,用25维数据重构出100维数据,这样就完成了学习过程,得到25个8*8的滤波器,可视化后效果如图2所示。

图2 滤波器可视化效果
2 卷积神经网络
卷积神经网络是一种非全连接的多层神经网络,一般由卷积层、下采样层和全连接层组成,原始图像首先通过卷积层与滤波器进行卷积,得到若干特征图,然后通过下采样层对特征进行模糊,最后通过一个全连接层输出一组特征向量,用于分类器分类识别,卷积神经网络的网络结构如图3所示。
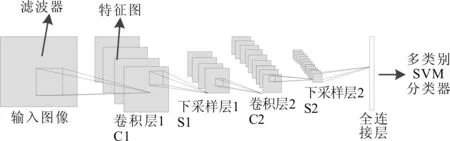
图3 CNN的网络结构
2.1 卷积层(Convolution Layers)
卷积过程:输入图像与卷积核卷积后加上偏置通过一个激活函数,就得到了第一层输出的特征图,表达式为:
(7)

2.2 下采样层(Sub-sampling Layers)
下采样过程:每领域n2个像素求和变为1个像素,通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个缩小n2倍的特征映射图,公式如下:
(8)
其中,down(.)表示一个下采样函数。
2.3 CNN工作原理
卷积神经网络的隐藏层是由卷积层和下采样层交替组成,在上图中,输入目标图像通过与N个卷积核进行卷积,得到具有N个特征图的C1层;然后对特征图中的图像进行池化,池化尺度的大小可根据不同的需要设定,于是得到具有N个池化后的特征图S2层,S2层中的特征图再经过卷积得到C3层,产生S4的方法与产生S2的方法一致;最后,通过全连接层获得用于识别图像的特征,用多类别SVM对获得的特征进行分类,最终得到人脸图像的识别率。
3 基于改进卷积神经网络的人脸识别
本算法在传统CNN算法的基础上作出改进:①通过稀疏自编码器预训练出适合图像训练集的滤波器,代替传统的滤波器随机初始化问题,提高了网络训练效率和识别效果;②通过多类别支持向量机代替传统的Softmax分类器,提高了分类性能和识别率。算法流程如图4所示。
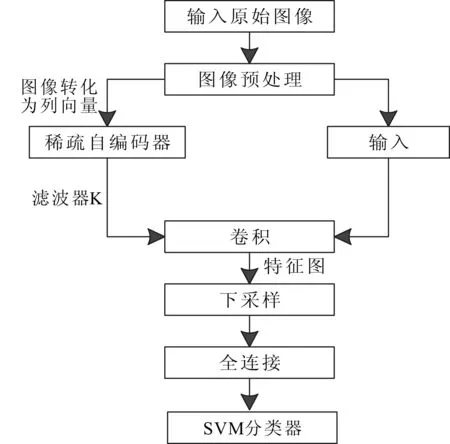
图4 算法流程
算法步骤如下:①对目标图像进行预处理,使图像符合网络训练的要求;②对①中图像进行随机采样,获得适量的数据集,通过稀疏自编码器非监督预训练得到CNN初始化滤波器的权值;③将②中获得的滤波器与①中的训练集图像进行卷积,获得预定数量的特征图;④将③中获得的特征图通过式⑧进行最大化采样,得到泛化后的图像;⑤用同样的方法对④中输出的特征图进行二次卷积,二次下采样,获得所需的特征图;⑥将⑤中的所有特征图转化为一个列向量,作为全连接层的输入,计算识别结果和标记的差异,通过反向传播算法自顶向下调节更新网络参数;⑦输入图像测试集,利用训练得到的网络参数集合和全连接网络权重参数对测试图像进行分类,通过多类别SVM分类器得到图像的识别结果。
4 仿真实验及分析
为了验证本算法的优越性,本文分别选取ORL人脸库和FERET人脸库作为实验的数据集。实验环境:计算机处理器主频3.8GHz内存8GMATLAB2012a下仿真。
4.1 数据集介绍
ORL人脸库包括40个不同人脸,每人10幅图像,共400幅,每幅原始图像为256个灰度级,分辨率为112*92,它包含了表情变化、微小姿态变化、10%以内的尺度变化,图5是ORL库中部分人脸图像。FERET人脸库共1 400幅图像,包括200个人,每人7幅图像,每幅原始图像为256个灰度级,分辨率为80*80,对应不同的姿态、表情和光照条件,图6是FERET人脸库中部分人脸图像。
4.2 实验结果与分析
根据图4步骤进行试验,首先对原始图像进行全局对比度归一化和ZCA白化预处理[12-13],去掉数据之间的相关度,消除数据冗余性,然后对网络参数进行设置。
实验1:对ORL数据集进行试验,每人分别取5张图片作为训练集,5张作为测试集,采用传统CNN算法和本文算法进行分组试验:

图5 ORL人脸库中部分人脸图像
图6 FERET人脸库中部分图像
第一组实验:从数据集中随机抽取200张图片,通过稀疏自编码器训练出六组滤波器,用于卷积神经网络的卷积核初始化,分类器采用多类别SVM分类器,网络参数设置为6c-2s-12c-2s,迭代次数为10次,学习率为0.1,通过训练,测试得出结果。第二组实验:卷积核采用随机化赋值,分类器采用softmax分类器,其它参数和第一组实验一样,对网络进行训练、分类,最后得出结果,如表1所示。

表1 数据集分类结果
实验2:对FERET数据集进行试验,将子集fa作为训练集,子集fb作为测试集,网络结构和实验1一样。第一组实验:从数据集中随机抽取500张图片,通过稀疏自编码器训练出16组滤波器,用于卷积神经网络的卷积核初始化,分类器采用多类别SVM分类器,网络参数设置为:16c-2s-48c-2s,迭代次数为20次,学习率为0.1,通过训练,测试得出结果,第二组实验:卷积核同样采用随机化赋值,分类器采用softmax分类器,其它参数和第一组实验一样,对网络进行训练、分类,最后得出结果,如表1所示。
从表1可以看出,本文算法要比传统CNN算法识别率高,同时也可以看出PCA+SVM算法与本文两种算法相比,在识别效果上有一定的差距,在样本数据较少时,提取的特征分类能力不是太强,当训练样本数据增加时,提取的特征分类能力有所增加,识别率有所提高。
为了测试本文算法在效率上的优势,对每次试验的训练时间和测试时间进行统计,如表2所示。

表2 数据集训练时间和测试时间
从表2可以看出,本文算法在网络训练阶段训练时间明显比传统CNN算法消耗时间短,因为本文算法在滤波器初始化时采用训练好的滤波器赋值,极大提高了训练效率。综上述,无论是识别效果还是识别效率,本文算法都要优于传统CNN算法,从而验证了本文算法的优越性。
5 结语
本文针对卷积神经网络在人脸识别中的应用,提出优化改进的深度卷积神经网络算法,该算法通过网络训练自动提取图像特征,并结合多分类SVM的优点对人脸图像进行分类识别,在ORL和FERET人脸数据库上的对比测试实验表明,该方法有更高的效率和更好的识别率。
[1] T KANDE.Picture processing by computer complex and recognition of human faces[D].Kyoto:Kyoto University,1973.
[2] A J GOLDSTEIN,L D HARMON,ALESK.Identification of human faces[J].Proc.IEEE,1971(59):748-760.
[3] R BRUNELLI,TPOGGI.Face recognition:feature versus templates[J].IEEE Transon Pattern Analysis and Machine Intelligence,1993,15(10):1042-1052.
[4] Y LECUN,L BOTTOU,YI BENGIO,et al.Gradient based learning applied to document recognition[J].Proceedings of the IEEE,2012:2278-2324.
[5] CHANG CHINCHEN,YUTAIXING.Sharing a secret gray images in multiple images[C].Shen Yang:Proceedings of First International Symposium Cyber,2002.
[6] 彭中亚,程国建.基于独立成分分析和核向量机的人脸识别[J].计算机工程,2010,36(7):193-194.
[7] 曲景影,孙显,高鑫.基于CNN模型的高分辨率遥感图像目标识别[J].国外电子测量技术,2016(8):45-50.
[8] 张春雨,韩立新,徐守晶.基于栈式自动编码的图像哈希算法[J].电子测量技术,2016(3):46-49,69.
[9] GLOROTX,BENGIO Y.Understanding the difficulty of training deep feedforward neural networks[C].International Conference on Artificial Intelligence and Statistics,2010:249-256.
[10] BENGIO Y.Learning deep architectures for AI[J].Foundations and Trends in Machine Learning,2009,2(1):1-127.
[11] 杨丽芬,蔡之华.BP神经网络优化算法研究[J].软件导刊,2007(5):106-108.
[12] 王利卿,黄松杰.基于多尺度卷积神经网络的图像检索算法[J].软件导刊,2016(2):38-40.
[13] 林妙真.基于深度学习的人脸识别研究[J].大连:大连理工大学,2013.
(责任编辑:孙 娟)
河南省基础与前沿技术研究计划项目(152300410103);河南省教育厅科学技术研究重点项目(13A510330)
李辉(1976-),男,河南林州人,博士,河南理工大学物理与电子信息学院教授、硕士生导师,研究方向为无线通信、信号处理、模式识别与人工智能;石波(1987-),男,河南林州人,河南理工大学电气工程与自动化学院硕士研究生,研究方向为模式识别与人工智能、机器学习与机器视觉。
10.11907/rjdk.162621
TP312
A
1672-7800(2017)003-0026-04
