网络教育资源中的跨语言知识管理研究
2017-04-12徐昊李慧君秦玥
徐昊+李慧君+秦玥
摘 要:近年来,随着互联网与教育的不断融合,以MOOC为代表的网络教育平台在世界范围内纷纷涌现。本文应用文本数据的获取与挖掘的技术,对MOOC教育资源的跨语言知识管理方法进行研究,最后实现知识点的跨语言检索和学习笔记的推荐功能,对基于开放数据的跨语言教育资源共享平台的构建具有重要意义。
关键词:跨语言;知识管理;MOOC;文本挖掘
G40-057
大型开放式网络课程(MOOC)自2011年上线以来就倍受人们瞩目,它在时间和空间上拓展了教育的范围,教学形式较为新颖,对学习者来说,MOOC可以激发他们的求知欲、学习积极性和自主性[1]。MOOC的优势在于便捷和开放,能提供课程的相关学习资源,如讲义、笔记、学习小组、论坛等。还有一些英语课程配备了中文字幕,可以帮助中国学习者进行学习。这些在一定程度上提高了学习者的学习效率,促使学习者更快融入在线学习中,最后完成整个课程。
但是我们发现,在线学习也存在一些不完善的地方。以学习资源中的笔记为例,笔记通常按照记录时间顺序显示,还存在着很多与课程内容无关的信息,这导致学习者不能查看某个知识点对应的笔记,还会被无关信息打扰。而且课程中的中英文知识点之间的关联也不能体现。为了改进这些情况,让MOOC平台为学习者提供更好的用户体验,本文研究了如何通过文本挖掘技术和跨语言知识库的构建,管理MOOC学习资源中的知识。
一、研究现状和关键技术
1.跨语言知识管理
WordNet是由美国普林斯顿大学开发的大规模的汇总英语词汇知识的在线资源库。它是一个由普通的词典内容与计算机科学、心理学成功结合的基于认知语言学的词典,主要按照词汇的意义而不是字母顺序而组成的“词汇网络”[2]。经过20年的研究工作的进展,WordNet已经发展成为国际上非常有影响的英语词汇知识库,为知识管理做出了卓越的贡献。近年来,随着单一语言知识库的飞速发展和各语言信息多样性的增加,跨语言知识管理以及规模性跨语言知识库的建设将成为必然的趋势,具有研究价值。UKC (Universal Knowledge Core) 就是这样一个典型例子。
UKC是一个由意大利特伦托大学开发的扩展的多语种版的WordNet,包括几十万个概念。UKC扮演的角色是世界上所有的自然语言的中心枢纽,对于每种语言,都存在一个独立的LKC (Local Knowledge Core)。每个LKC都有一个源语言(目前为英文)和一个目标语言(世界上任何一种语言),可以独立发展并且与UKC同步。事实上,LKC是一个本土化进程,通过UKC,所有LKC可以均衡协作、互相使用,多种语言可以得到匹配。
UKC的基本组成部分是词语,义项,同义词集和概念[3]。它们的含义如下:同义词集是一组拥有一个共有的含义的词语;概念是可以表示一个同义词集含义的一句描述性质的话;义项是一个词语的含义;注释是一个同义词集的简短描述。此外,UKC中还有词目和词性这两个
元素。
2.关键技术
近半个世纪以来,随着计算机技术的成熟与发展,人们的生活中大量产生着社交媒体中的文本数据、通讯数据、GPS位置信息、传感器数据甚至还有图片和视频,信息的种类和数量有了爆炸式的增加。但是人们目前面临的严峻的问题是数据丰富而信息贫乏,只是把海量数据存储起来并不会带来任何价值,还需要对其进行分析,并从中获得有用的信息[10]。数据分析基本上都经历了数据获取、预处理(清洗)、选择分析算法、展示结果、评估这一流程。本文的研究基于文本数据的处理与分析,包括文本数据的获取、清洗、信息挖掘和数据可视化。
获取数据是数据挖掘的初始步骤。对分析者而言,外部数据比内部数据更容易获取,获取外部数据可以通过搜索引擎、开放数据、在聚合数据平台上购买或下载专业数据集、网络爬虫、调查问卷等方式。目前应用较多的外部数据的采集方式的主要有两种:商业化工具与网络爬虫,我们的研究就基于Python爬虫程序来获取网络课程的笔记。
文本挖掘是数据挖掘的一个分支,也是一个由机器学习、统计学、数学、自然语言处理等多种学科交叉而成的领域。顾名思义,就是从大量文本数据中抽取隐含的、未知、可能有用的信息,并对这些数据进行分析,挖掘其中潜在的知识信息[4]。文本挖掘的数据主要是指非结构化文档和邮件、网页内容等半结构化数据,常见的算法有关联规则算法,聚类算法 和分类算法。
数据可视化是指将身居分析的结果以图形或表格的形式展现出来,以便进一步分析和报告数据的特征以及数据之间的关系。它的首要任务是准确地展示和传达数据所包含的信息,并用直观、容易理解和操纵的方式呈现出来。它的基本流程是:將信息映射成可视形式,选择合适的图表,删去不突出的对象或属性,最终呈现出关键属性的明显特征。
二、跨语言知识管理的应用
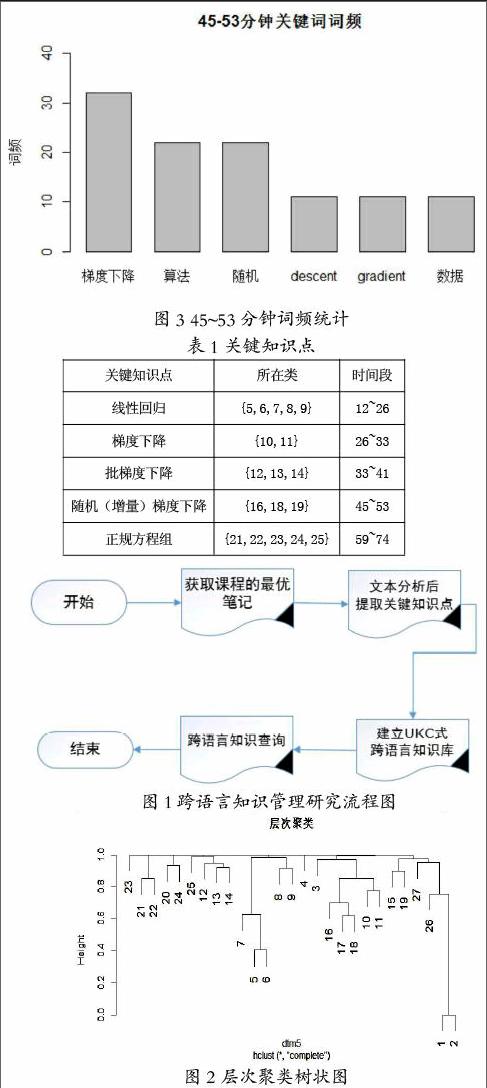
我们研究的数据来自网易公开课中斯坦福大学开设的计算机系课程《机器学习》。首先使用Python爬虫程序获取最优笔记内容作为实验数据,然后用R语言分析文本数据、提取关键词,模仿UKC构建跨语言知识库,最后实现学习课程时对感兴趣的知识点的查询功能。跨语言知识管理研究的流程如图1所示。
数据获取与关键知识点提取
首先,利用编写的Python爬虫程序从网易公开课的课程页面获取前30页最优笔记,获得的数据保存成文本格式。
关键知识点提取是研究的核心部分,是文本分析算法的具体实现部分,此部分使用R语言完成,步骤如下:
第一步:读入待处理的文件,对数据进行清理和格式转换之后,经过排序,得到了共380条可用的笔记;
第二步:由于课程讲授是具有连续性的,而且为了方便统计,这里人为地将笔记按每3分钟为一段进行分段统计。然后对文本进行分词,然后全部去除文本中包含的标点、数字、多余的空格和停用词,生成语料库;
